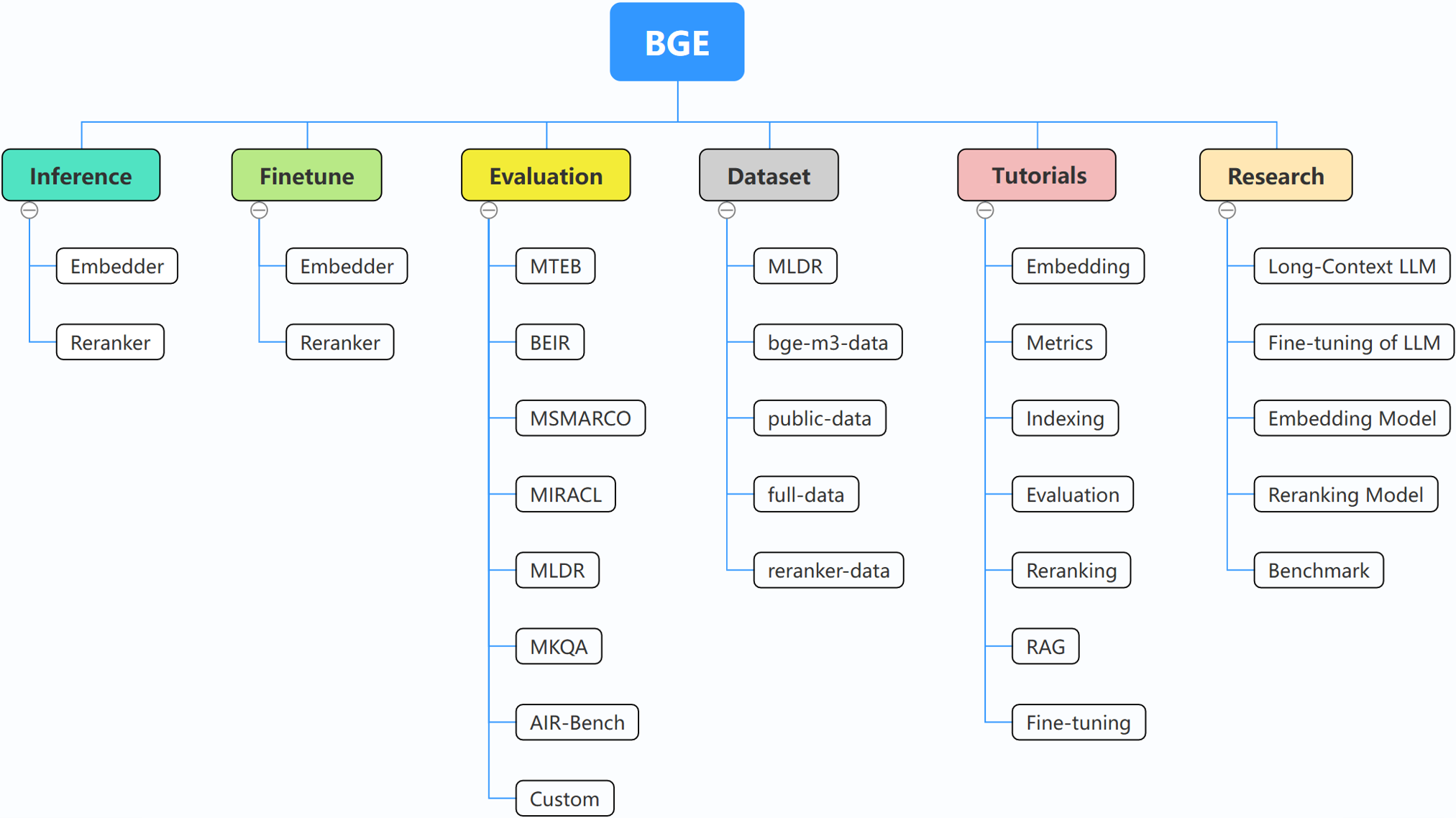
FlagEmbedding
1.3.2


Noticias | Instalación | Inicio rápido | Comunidad | Proyectos | Lista de modelos | Colaborador | Citación | Licencia
Inglés | 中文
BGE (BAAI General Embedding) se centra en LLM con recuperación aumentada y actualmente consta de los siguientes proyectos:
29/10/2024: ? Creamos un grupo WeChat para BGE. ¡Escanea el código QR para unirte al chat grupal! Para recibir un mensaje de primera mano sobre nuestras actualizaciones y nuevos lanzamientos, o si tiene alguna pregunta o idea, ¡únase a nosotros ahora!

22/10/2024: Lanzamos otro modelo interesante: OmniGen, que es un modelo unificado de generación de imágenes que admite diversas tareas. OmniGen puede realizar tareas complejas de generación de imágenes sin la necesidad de complementos adicionales como ControlNet, IP-Adapter o modelos auxiliares como detección de pose y detección de rostros.
10/09/2024: Presentamos MemoRAG , un paso adelante hacia RAG 2.0 además del descubrimiento de conocimiento inspirado en la memoria (repositorio: https://github.com/qhjqhj00/MemoRAG, documento: https://arxiv.org/pdf/ 2409.05591v1)
2/09/2024: Empezar a mantener los tutoriales. El contenido que contiene se actualizará y enriquecerá activamente, ¡estad atentos!
26/07/2024: Lanzamiento de un nuevo modelo de incrustación bge-en-icl, un modelo de incrustación que incorpora capacidades de aprendizaje en contexto, que, al proporcionar ejemplos de consulta-respuesta relevantes para la tarea, puede codificar consultas semánticamente más ricas, mejorando aún más la semántica. capacidad de representación de las incrustaciones.
26/07/2024: Lanzamiento de un nuevo modelo de incrustación bge-multilingual-gemma2, un modelo de incrustación multilingüe basado en gemma-2-9b, que admite múltiples idiomas y diversas tareas posteriores, logrando nuevos SOTA en puntos de referencia multilingües (MIRACL, MTEB-fr y MTEB-pl).
26/07/2024: Lanzamiento de un nuevo reranker liviano bge-reranker-v2.5-gemma2-lightweight, un reranker liviano basado en gemma-2-9b, que admite la compresión de tokens y operaciones livianas por capas, aún puede garantizar un buen rendimiento mientras se ahorra una cantidad importante de recursos.
BAAI/bge-reranker-base y BAAI/bge-reranker-large , que son más potentes que el modelo de incrustación. Recomendamos usarlos/ajustarlos para volver a clasificar los documentos top-k devueltos mediante la incorporación de modelos.bge-*-v1.5 para aliviar el problema de la distribución de similitud y mejorar su capacidad de recuperación sin instrucciones.bge-large-* (abreviatura de BAAI General Embedding), ¡ocupe el primer lugar en las pruebas comparativas MTEB y C-MTEB! ? ?Si no desea ajustar los modelos, puede instalar el paquete sin la dependencia de ajuste fino:
pip install -U FlagEmbedding
Si desea ajustar los modelos, puede instalar el paquete con la dependencia de ajuste fino:
pip install -U FlagEmbedding[finetune]
Clona el repositorio e instala
git clone https://github.com/FlagOpen/FlagEmbedding.git
cd FlagEmbedding
# If you do not want to finetune the models, you can install the package without the finetune dependency:
pip install .
# If you want to finetune the models, you can install the package with the finetune dependency:
# pip install .[finetune]
Para desarrollo en modo editable:
# If you do not want to finetune the models, you can install the package without the finetune dependency:
pip install -e .
# If you want to finetune the models, you can install the package with the finetune dependency:
# pip install -e .[finetune]
Primero, cargue uno de los modelos de incrustación BGE:
from FlagEmbedding import FlagAutoModel
model = FlagAutoModel.from_finetuned('BAAI/bge-base-en-v1.5',
query_instruction_for_retrieval="Represent this sentence for searching relevant passages:",
use_fp16=True)
Luego, introduzca algunas oraciones en el modelo y obtenga sus incrustaciones:
sentences_1 = ["I love NLP", "I love machine learning"]
sentences_2 = ["I love BGE", "I love text retrieval"]
embeddings_1 = model.encode(sentences_1)
embeddings_2 = model.encode(sentences_2)
Una vez que obtengamos las incrustaciones, podemos calcular la similitud por producto interno:
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
Para obtener más detalles, puede consultar la inferencia del incrustador, la inferencia del reranker, el ajuste fino del incrustador, el ajuste final del reranker y la evaluación.
Si no está familiarizado con alguno de los conceptos relacionados, consulte el tutorial. Si no está allí, háganoslo saber.
Para temas más interesantes relacionados con BGE, consulte la investigación.
Mantenemos activamente la comunidad de BGE y FlagEmbedding. ¡Háganos saber si tiene alguna sugerencia o idea!
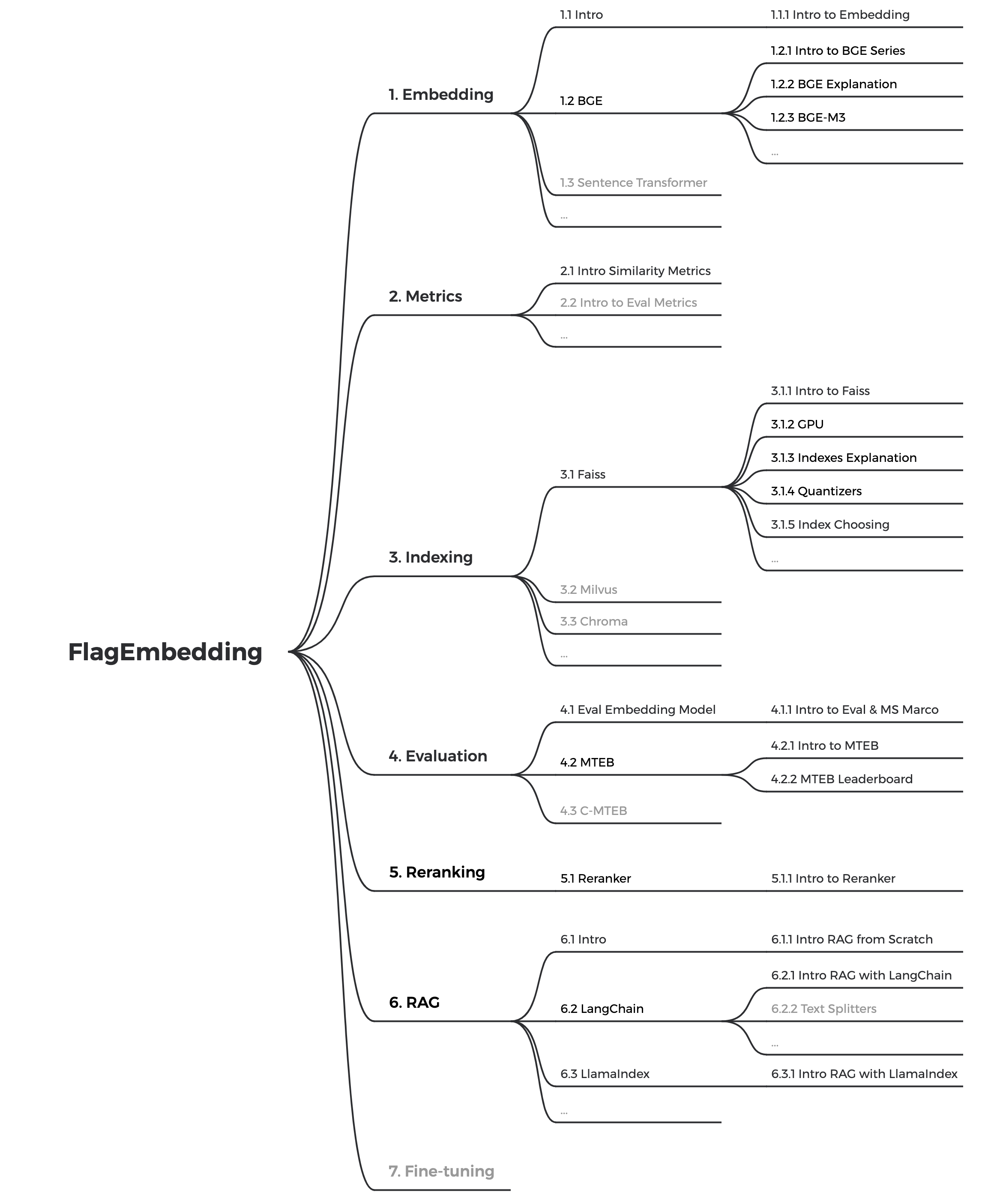
Actualmente estamos actualizando los tutoriales, nuestro objetivo es crear un tutorial completo y detallado para principiantes sobre recuperación de texto y RAG. ¡Manténganse al tanto!
Los siguientes contenidos se lanzarán en las próximas semanas:
bge es la abreviatura de BAAI general embedding .
| Modelo | Idioma | Descripción | instrucción de consulta para recuperación |
|---|---|---|---|
| BAAI/bge-en-icl | Inglés | Un modelo de integración basado en LLM con capacidades de aprendizaje en contexto, que puede aprovechar al máximo el potencial del modelo basándose en algunos ejemplos. | Proporcione instrucciones y ejemplos breves libremente según la tarea asignada. |
| BAAI/bge-multilingüe-gemma2 | Plurilingüe | Un modelo de integración multilingüe basado en LLM, capacitado en una amplia gama de idiomas y tareas. | Proporcionar instrucciones basadas en la tarea asignada. |
| BAAI/bge-m3 | Plurilingüe | Multifuncionalidad (recuperación densa, recuperación escasa, multivector (colbert)), multilingüismo y multigranularidad (8192 tokens) | |
| Cóctel LM | Inglés | Modelos ajustados (Llama y BGE) que se pueden utilizar para reproducir los resultados de LM-Cocktail. | |
| BAAI/llm-incrustador | Inglés | un modelo de integración unificado para respaldar diversas necesidades de aumento de recuperación para LLM | Ver LÉAME |
| BAAI/bge-reranker-v2-m3 | Plurilingüe | un modelo liviano de codificador cruzado, posee sólidas capacidades multilingües, fácil de implementar y con inferencia rápida. | |
| BAAI/bge-reranker-v2-gemma | Plurilingüe | un modelo de codificador cruzado que es adecuado para contextos multilingües, funciona bien tanto en dominio del inglés como en capacidades multilingües. | |
| BAAI/bge-reranker-v2-minicpm-capas | Plurilingüe | un modelo de codificador cruzado que es adecuado para contextos multilingües, funciona bien tanto en inglés como en chino, permite la libertad de seleccionar capas para la salida, lo que facilita la inferencia acelerada. | |
| BAAI/bge-reranker-v2.5-gemma2-ligero | Plurilingüe | un modelo de codificador cruzado que es adecuado para contextos multilingües, funciona bien tanto en inglés como en chino, permite libertad para seleccionar capas, comprimir proporciones y comprimir capas para la salida, lo que facilita la inferencia acelerada. | |
| BAAI/bge-reranker-grande | chino e ingles | un modelo de codificador cruzado que es más preciso pero menos eficiente | |
| BAAI/bge-reranker-base | chino e ingles | un modelo de codificador cruzado que es más preciso pero menos eficiente | |
| BAAI/bge-large-es-v1.5 | Inglés | versión 1.5 con distribución de similitud más razonable | Represent this sentence for searching relevant passages: |
| BAAI/bge-base-es-v1.5 | Inglés | versión 1.5 con distribución de similitud más razonable | Represent this sentence for searching relevant passages: |
| BAAI/bge-small-es-v1.5 | Inglés | versión 1.5 con distribución de similitud más razonable | Represent this sentence for searching relevant passages: |
| BAAI/bge-grande-zh-v1.5 | Chino | versión 1.5 con distribución de similitud más razonable | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-base-zh-v1.5 | Chino | versión 1.5 con distribución de similitud más razonable | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-small-zh-v1.5 | Chino | versión 1.5 con distribución de similitud más razonable | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-large-es | Inglés | Modelo de incrustación que asigna texto a un vector | Represent this sentence for searching relevant passages: |
| BAAI/bge-base-es | Inglés | un modelo a escala base pero con una capacidad similar de bge-large-en | Represent this sentence for searching relevant passages: |
| BAAI/bge-small-es | Inglés | Un modelo de pequeña escala pero con prestaciones competitivas. | Represent this sentence for searching relevant passages: |
| BAAI/bge-grande-zh | Chino | Modelo de incrustación que asigna texto a un vector | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-base-zh | Chino | un modelo a escala base pero con capacidad similar a bge-large-zh | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-pequeño-zh | Chino | Un modelo de pequeña escala pero con prestaciones competitivas. | 为这个句子生成表示以用于检索相关文章: |
¡Agradezca a todos nuestros contribuyentes por sus esfuerzos y dé una calurosa bienvenida a los nuevos miembros para que se unan!
Si encuentra útil este repositorio, considere otorgar una estrella y una cita.
@misc{bge_m3,
title={BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation},
author={Chen, Jianlv and Xiao, Shitao and Zhang, Peitian and Luo, Kun and Lian, Defu and Liu, Zheng},
year={2023},
eprint={2309.07597},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{cocktail,
title={LM-Cocktail: Resilient Tuning of Language Models via Model Merging},
author={Shitao Xiao and Zheng Liu and Peitian Zhang and Xingrun Xing},
year={2023},
eprint={2311.13534},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{llm_embedder,
title={Retrieve Anything To Augment Large Language Models},
author={Peitian Zhang and Shitao Xiao and Zheng Liu and Zhicheng Dou and Jian-Yun Nie},
year={2023},
eprint={2310.07554},
archivePrefix={arXiv},
primaryClass={cs.IR}
}
@misc{bge_embedding,
title={C-Pack: Packaged Resources To Advance General Chinese Embedding},
author={Shitao Xiao and Zheng Liu and Peitian Zhang and Niklas Muennighoff},
year={2023},
eprint={2309.07597},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
FlagEmbedding tiene la licencia MIT.


