Sistema de Gestión de Metro
Proyectos del curso de primavera de SUSTech 2024 CS307 - Principles of Database System dirigido por Yuxin MA
Shenzhen-Metro
├── Project1 # part 1 of project (database design and data import)
│ ├── ShenzhenMetroDatabaseDesign
│ │ ├── src
│ │ │ ├── main
│ │ │ │ ├── java # import script in java
│ │ │ │ ├── resources # data in json
│ │ │ │ └── sql # ddl
│ └── ShenzhenMetroDatabaseDesignPython
│ ├── import_script.py # import script in python
│ └── resources # data in json
├── Project2 # part 2 of project (building an api)
│ ├── DataImport # updated data import
│ │ ├── src
│ │ │ ├── main
│ │ │ │ ├── java # updated import script in java
│ │ │ │ ├── resources # updated data
│ │ │ │ └── sql # updated ddl
│ └── ShenzhenMetro # spring boot project
│ ├── src
│ │ ├── main
│ │ │ ├── java # backend logic
│ │ │ │ └── com/sustech/cs307/project2/shenzhenmetro
│ │ │ │ ├── ShenzhenMetroApplication.java # main application driver
│ │ │ │ ├── controller # api route mapping
│ │ │ │ ├── dto # dto between client and server
│ │ │ │ ├── object # orm between database tables and application code
│ │ │ │ ├── repository # interfaces for data access
│ │ │ │ └── service # service layer containing business logic
│ │ │ └── resources # frontend logic
│ │ │ ├── application.properties # configuration file for spring boot application
│ │ │ ├── static
│ │ │ │ ├── assets
│ │ │ │ │ ├── css
│ │ │ │ │ ├── img
│ │ │ │ │ ├── js
│ │ │ │ │ └── vendor
│ │ │ │ │ ├── aos
│ │ │ │ │ ├── bootstrap
│ │ │ │ │ ├── bootstrap-icons
│ │ │ │ │ ├── glightbox
│ │ │ │ │ └── swiper
│ │ │ │ └── index.html # main html
│ │ │ └── templates
│ │ │ ├── buses
│ │ │ │ ├── create_bus.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_bus.html
│ │ │ ├── landmarks
│ │ │ │ ├── create_landmark.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_landmark.html
│ │ │ ├── lineDetails
│ │ │ │ ├── create_line_detail.html
│ │ │ │ ├── index.html
│ │ │ │ ├── navigate_routes.html
│ │ │ │ └── search_line_detail.html
│ │ │ ├── lines
│ │ │ │ ├── create_line.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_line.html
│ │ │ ├── ongoingRides
│ │ │ │ └── index.html
│ │ │ ├── rides
│ │ │ │ ├── create_ride.html
│ │ │ │ ├── filter_ride.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_ride.html
│ │ │ ├── stations
│ │ │ │ ├── create_station.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_station.html
│ │ │ └── users
│ │ │ ├── card.html
│ │ │ └── passenger.html
└── README.md
La primera parte del proyecto trata principalmente de diseñar un esquema de base de datos que satisfaga los principios de las bases de datos relacionales en función de los antecedentes de los datos proporcionados. Una vez completada la fase de diseño, escribimos scripts para importar esos grandes conjuntos de datos. Para garantizar la precisión de los datos importados, tuvimos que realizar algunas declaraciones de consulta y verificar los resultados de la consulta el día de la defensa. Además de eso, también realizamos algunos experimentos con los datos para obtener información maravillosa, como se muestra más adelante.
[Lea los requisitos detallados]
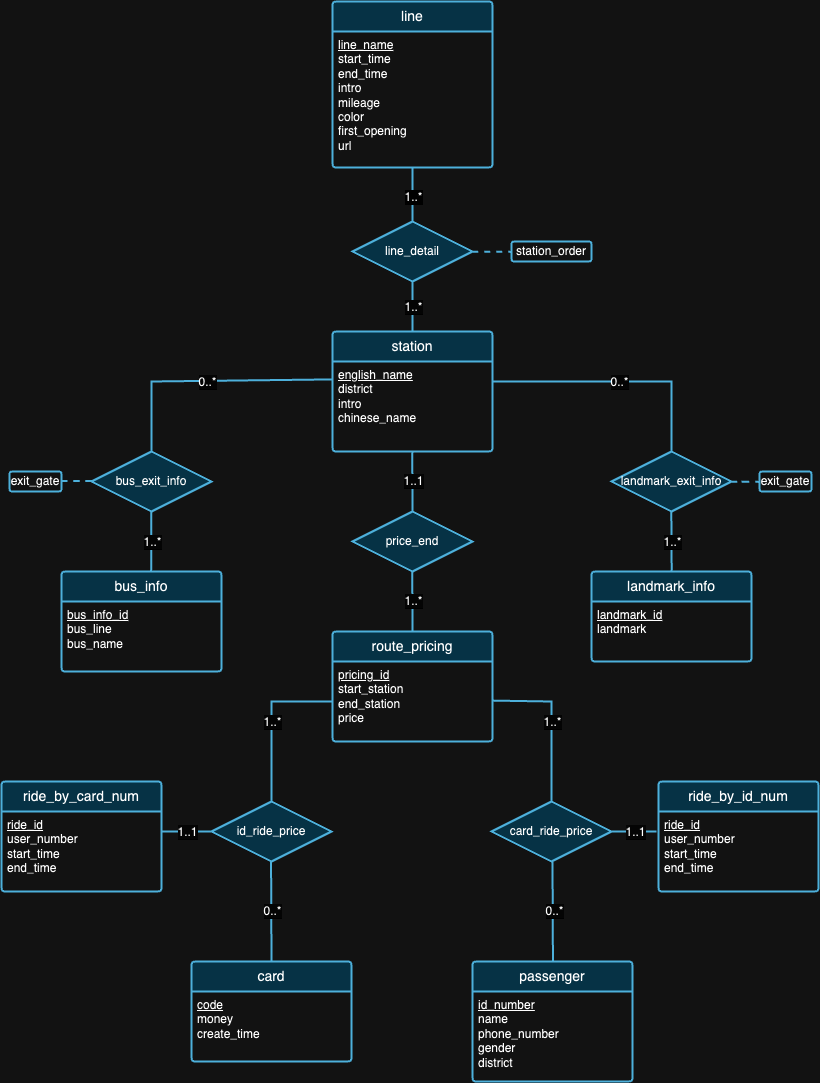
Creemos que ningún diseño de base de datos es perfecto. De hecho, existen fallas en el diseño propuesto por nosotros en el diagrama ER anterior. Después de observar los conjuntos de datos y los antecedentes de cada conjunto de datos, esperamos que pueda intentar detectar fallas de diseño por su cuenta. :)
Nota : Para la interpretación de las figuras,
| IDENTIFICACIÓN | SO | Chip | Memoria | SSD | Herramientas |
|---|---|---|---|---|---|
| 1 | macOS Sonoma 14.4.1 | Apple M3 Pro | 18GB | 1TB | IDEA 2024.1 (CE), PyCharm 2023.3.4 (CE), Datagrip 2024.1 |
| 2 | Windows 11 Inicio 23H2 | Intel(R) Core(TM) i9-12900H de 12.ª generación | 32GB | 1TB | IDEA 2024.1 (CE), Datagrip 2024.1 |
| 3 | Ubuntu 22.04.4 (VM) | Apple M1Pro | 16GB | 512GB | IDEA 2024.1 (CE), Datagrip 2024.1 |
Experiment 1: Different Import Methods Método 1 (script original): este método utiliza la biblioteca java.sql . En primer lugar, establecimos una conexión con nuestro servidor PostgreSQL. Luego leemos todos los datos de los archivos JSON. A continuación, recorrimos cada dato y creamos PreparedStatement para cada declaración de inserción. Por último, llamamos al método executeUpdate() para ejecutar cada declaración individualmente.
Método 2 (script optimizado): este método también utiliza la biblioteca java.sql y emplea el mismo algoritmo de lectura de datos que el Método 1. La diferencia es que ahora utilizamos el método executeBatch() . Así que recorrimos todos los datos, creamos cada declaración de inserción con PreparedStatement y agregamos cada PreparedStatement a un lote para una ejecución por lotes.
Método 3 (ejecutar un archivo .sql): utilizamos un programa Java para generar declaraciones de inserción SQL y las escribimos en un archivo .sql empleando el mismo algoritmo de lectura de datos mencionado anteriormente. Luego ejecutamos el archivo en DataGrip.
Dado que utilizamos el mismo algoritmo de lectura de datos en los tres métodos, utilizaremos un tiempo de ejecución promedio para nuestras pruebas posteriores. Inicialmente reunimos tres tiempos de ejecución diferentes (504 ms, 546 ms y 552 ms) y calculamos un tiempo de ejecución promedio de 534 ms.
| Entorno de prueba | Método | Tiempo promedio de lectura (ms) | Tiempo de escritura (ms) | Tiempo total (ms) | Rendimiento (declaraciones/s) |
|---|---|---|---|---|---|
| 1 | 1 | 534 | 206396 | 206930 | 8636.91 |
| 1 | 2 | 534 | 2114 | 2648 | 97632.92 |
| 1 | 3 | 534 | 13581 | 14115 | 15197.41 |
La Tabla 2 ilustra las distintas métricas de rendimiento entre diferentes métodos: el Método 2 muestra el mayor rendimiento y el Método 1 tiene el tiempo total más lento. Esto convierte al Método 2 en el método de prueba estándar en los próximos experimentos.
Experiment 2: Data Import with Different Data VolumesAdministrar e importar datos de diferentes volúmenes es un aspecto crucial para garantizar el rendimiento, la escalabilidad y la confiabilidad de un sistema de base de datos.
Antes del proceso de importación, notamos que el volumen de datos del 'viaje' era notablemente mayor en comparación con los demás. Basándonos en esta idea, decidimos probar la importación de datos con diferentes volúmenes únicamente en ride.json . Dado que el peso de los datos no es consistente, importar menos volumen para las otras tablas podría generar un problema grave debido a la conectividad entre las tablas.
Inicialmente, comenzamos importando los datos completos (100% del volumen) para todas las demás tablas excepto las tablas rides_by_id_num y rides_by_card_num para garantizar la coherencia de nuestro diseño. Para gestionar esto de forma eficaz, adoptamos una estrategia de importación por fases para los datos ride , comenzando con un subconjunto del 20 % de los datos, lo que equivalía a 20 000 registros. Esta fase inicial nos permitió evaluar el impacto en el rendimiento del sistema y realizar los ajustes necesarios al proceso de importación sin comprometer la estabilidad de la base de datos. Después de una validación exitosa y un ajuste del rendimiento, procedimos a importar el 50 % de los datos y, finalmente, la parte restante para completar la importación del 100 % de los datos. Tenga en cuenta que utilizamos el Método 2 para todas las importaciones, ya que es el más rápido.
| Entorno de prueba | Método | Volumen | Tiempo de lectura (ms) | Tiempo de escritura (ms) | Tiempo total (ms) | Recuento de declaraciones | Rendimiento (declaraciones/s) |
|---|---|---|---|---|---|---|---|
| 1 | 2 | 20% | 507 | 808 | 1315 | 80165 | 99214.11 |
| 1 | 2 | 50% | 521 | 1338 | 1859 | 130849 | 97794.47 |
| 1 | 2 | 100% | 534 | 2114 | 2648 | 203502 | 96263.95 |
Según la Tabla 3, a medida que aumenta el volumen de datos (del 20% al 50% y al 100%), tanto los tiempos de lectura como de escritura tienden a aumentar, lo que resulta en tiempos totales más largos para las operaciones. Sin embargo, estas cifras no dan ningún significado revelador, ya que tuvimos diferentes volúmenes de importación. Si nos fijamos en el número de rendimientos, el rendimiento (declaraciones/s) disminuye gradualmente a medida que aumenta el volumen de datos, lo que indica que el sistema se vuelve menos eficiente en el procesamiento de declaraciones a medida que aumenta la carga de trabajo.
Experiment 3: Data Import on Different Operating SystemsAl probar el proceso de importación de datos en diferentes sistemas operativos, empleamos el método de importación más rápido, que es el Método 2, con un volumen de importación del 100%.
Tenga en cuenta que al ejecutar el script de importación de Java en Linux a través de una máquina virtual, es esencial considerar la desventaja injusta en el rendimiento y la asignación de recursos, ya que la virtualización puede generar gastos generales y afectar la eficiencia del sistema.
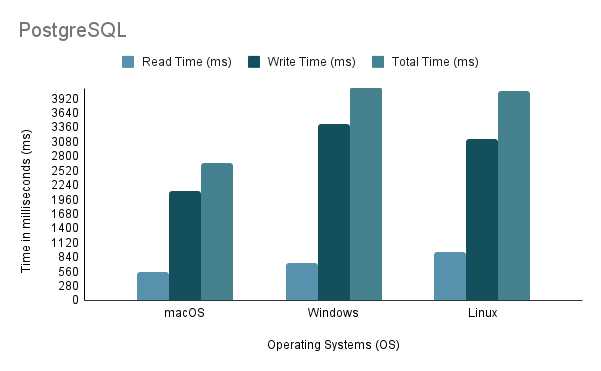
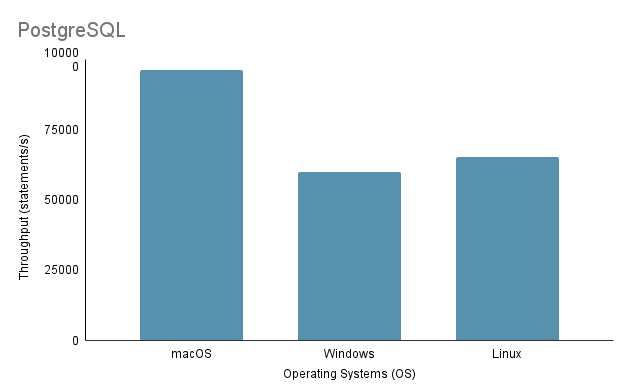
Según el análisis anterior, está claro que el entorno 1 (macOS) muestra el mejor rendimiento con el tiempo total más corto de 2648 ms y el rendimiento más alto con 97.632,92 declaraciones/s. Por el contrario, el entorno 2 (Windows) es el más lento con un tiempo total de 4117 ms y el rendimiento más bajo con 60.669,02 declaraciones/s. Vale la pena señalar que Linux Ubuntu, aunque se ejecuta como una máquina virtual, aún superó a Windows.
Experiment 4: Data Import with Various Programming LanguagesEn este experimento, utilizamos el Método 2 mencionado anteriormente para el código Java ya que es el más rápido. Mientras tanto, para Python, escribimos un método de importación que utilizaba Psycopg2 para comunicarse con el servidor de base de datos PostgreSQL.
| Entorno de prueba | Lenguaje de programación | Tiempo de lectura (ms) | Tiempo de escritura (ms) | Tiempo total (ms) | Rendimiento (declaraciones/s) |
|---|---|---|---|---|---|
| 1 | Java | 534 | 2114 | 2648 | 96263.95 |
| 1 | Pitón | 390 | 7237 | 7627 | 28119.66 |
Los datos de la Tabla 4 muestran que Java superó a Python tanto en velocidad como en rendimiento, lo que indica su eficiencia superior para las operaciones de lectura y escritura.
Experiment 5: Data Import on Different DatabasesDesarrollamos tres métodos de importación diferentes para PostgreSQL y MySQL, pero solo realizamos un experimento con el Método 2, ya que es la elección del desarrollador para importar datos. Tanto PostgreSQL como MySQL tienen un diseño de implementación de base de datos similar (en cuanto a DDL) y un diseño de código de importación similar.
| Entorno de prueba | Método | Base de datos | Tiempo de lectura (ms) | Tiempo de escritura (ms) | Tiempo total (ms) | Rendimiento (declaraciones/s) |
|---|---|---|---|---|---|---|
| 1 | 2 | PostgreSQL | 534 | 2114 | 2648 | 96263.95 |
| 1 | 2 | mysql | 534 | 42315 | 42849 | 4809.22 |
A pesar de que ambas son bases de datos basadas en SQL, PostgreSQL es aproximadamente 16 veces más rápido en lo que respecta al tiempo de escritura. Esto podría deberse a diferencias en la arquitectura del motor de base de datos y la implementación del controlador ( postgresql-42.2.5.jar para PostgreSQL y mysql-connector-j-8.3.0.jar para MySQL).
La parte 2 del proyecto se centra en proporcionar la funcionalidad básica de acceder al sistema de base de datos mediante la creación de una biblioteca backend que expone un conjunto de interfaces de programación de aplicaciones (API). Tenga en cuenta que también es necesario importar un conjunto de datos adicional, por lo que requiere una implementación de base de datos actualizada (se puede encontrar en ./Project2/DataImport ).
[Lea los requisitos detallados]
./Project2/DataImport/src/main/sql/ddl.sql./Project2/DataImport/src/main/java/ImportScript.java./Project2/ShenzhenMetro ) con Maven (se recomienda IntelliJ IDEA IDE)

