chrono_lens
v1.1.1
Este es el repositorio público del proyecto de análisis de cámaras de tráfico publicado en el blog del campus de ciencia de datos de la Oficina de Estadísticas Nacionales como parte de los indicadores más rápidos del coronavirus de la ONS (por ejemplo, actividad de las cámaras de tráfico, 10 de septiembre de 2020) y la metodología subyacente. El proyecto utilizó Google Compute Platform (GCP) para permitir una solución escalable, pero la metodología subyacente es independiente de la plataforma; Este repositorio contiene nuestra implementación orientada a GCP.
A continuación se presenta un ejemplo de resultado producido para el Indicador más rápido de coronavirus.
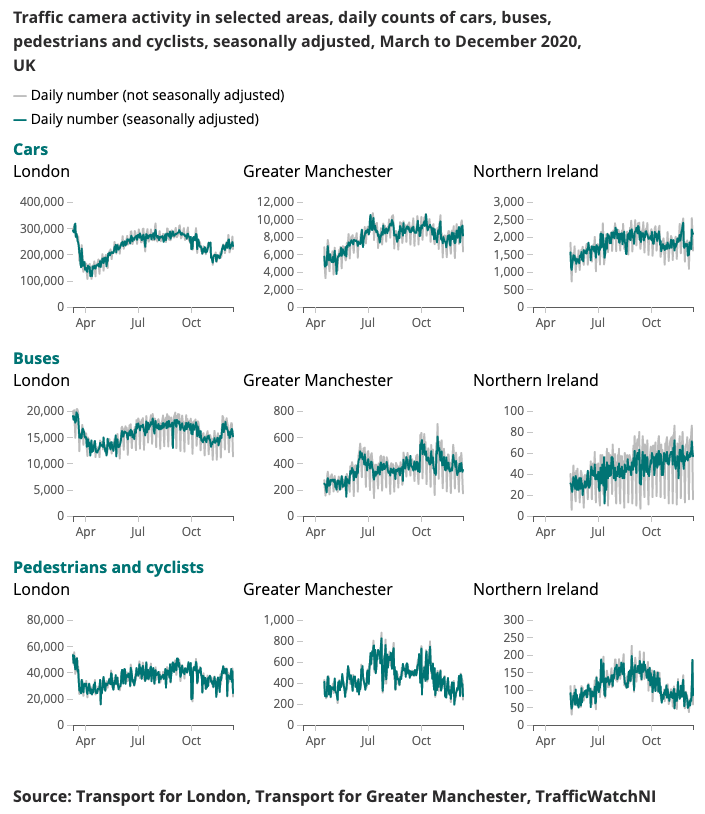
Comprender los patrones cambiantes de movilidad y comportamiento en tiempo real ha sido un foco importante de la respuesta gubernamental al coronavirus (COVID-19). El Data Science Campus ha estado explorando fuentes de datos alternativas que podrían brindar información sobre cómo estimar los niveles de distanciamiento social y rastrear el repunte de la sociedad y la economía a medida que se relajan las condiciones de bloqueo.
Las cámaras de tráfico son una fuente de datos ampliamente disponible públicamente que permite a los profesionales del transporte y al público evaluar el flujo de tráfico en diferentes partes del país a través de Internet. Las imágenes que producen las cámaras de tráfico están disponibles públicamente, son de baja resolución y no permiten la identificación individual de personas o vehículos. Se diferencian de los CCTV utilizados para la seguridad pública y la aplicación de la ley por el reconocimiento automático de matrículas (ANPR) o para monitorear la velocidad del tráfico.
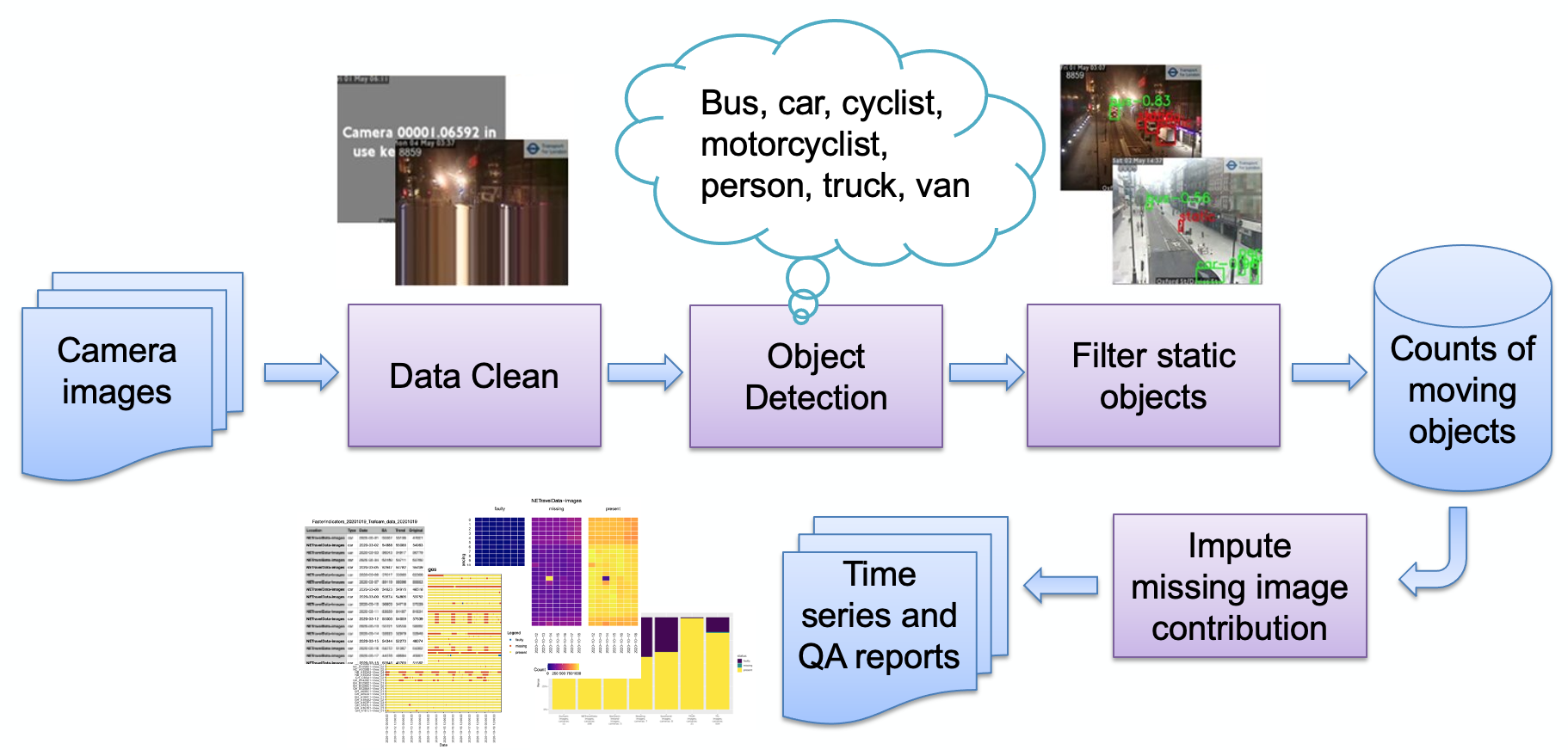
Las principales etapas del proceso, como se describe en la imagen, son:
Ingestión de imágenes
Detección de imagen defectuosa
Detección de objetos
Detección de objetos estáticos
Almacenamiento de los recuentos resultantes.
Los recuentos pueden luego procesarse más (ajuste estacional, imputación de valores faltantes) y transformarse en informes según sea necesario. Revisaremos brevemente las principales etapas del proceso.
El usuario selecciona un conjunto de fuentes de cámara (imágenes JPEG alojadas en la web) y se le proporciona como una lista de URL. Se proporciona un código de ejemplo para obtener imágenes públicas de Transport for London y un código especializado para extraer datos de tráfico NE directamente del Observatorio Urbano de la Universidad de Newcastle.
Las cámaras pueden no estar disponibles por varias razones (fallo del sistema, transmisión desactivada por el operador local, etc.) y estas podrían causar que el modelo genere recuentos de objetos falsos (por ejemplo, una pequeña mancha puede parecer un autobús distante). Un ejemplo de tal imagen es: 
Hasta ahora, todas estas imágenes han seguido un patrón de imagen muy sintética, que consiste en un color de fondo plano y texto superpuesto (en comparación con una imagen de una escena natural). Actualmente, estas imágenes se detectan reduciendo la profundidad del color (juntando colores similares) y luego mirando la fracción más alta de la imagen ocupada por un solo color. Una vez que esto supera un umbral, determinamos que la imagen es sintética y la marcamos como defectuosa. Pueden ocurrir otras fallas debido a la codificación, como por ejemplo: 
Aquí, la transmisión de la cámara se ha detenido y se ha repetido la última fila "en vivo"; Detectamos esto comprobando si la fila inferior de la imagen coincide con la fila superior (dentro del umbral). Si es así, se comprueba que la siguiente fila de arriba coincida y así sucesivamente hasta que las filas ya no coincidan o nos quedemos sin filas. Si el número de filas coincidentes supera un umbral, es poco probable que la imagen genere datos útiles y, por lo tanto, se marca como defectuosa.
Tenga en cuenta que los diferentes proveedores de imágenes utilizan diferentes formas de mostrar que una cámara no está disponible; Nuestra técnica de detección se basa en el uso de pocos colores, es decir, una imagen puramente sintética. Si se utiliza una imagen más natural es posible que nuestra técnica no funcione. Una alternativa es mantener una "biblioteca" de imágenes fallidas y buscar similitudes, lo que puede funcionar mejor con imágenes más naturales.
El proceso de detección de objetos identifica objetos estáticos y en movimiento, utilizando un Faster-RCNN previamente entrenado proporcionado por el Observatorio Urbano de la Universidad de Newcastle. El modelo se entrenó con 10.000 imágenes de cámaras de tráfico del noreste de Inglaterra y el ONS Data Science Campus lo validó para confirmar que el modelo era utilizable con imágenes de cámaras de otras áreas del Reino Unido. Detecta los siguientes tipos de objetos: coche, furgoneta, camión, autobús, peatón, ciclista, motociclista.
Como nuestro objetivo es detectar actividad, es importante filtrar los objetos estáticos utilizando información temporal. Las imágenes se muestrean a intervalos de 10 minutos, por lo que los métodos tradicionales para la detección de fondo en vídeo, como la mezcla de gaussianos, no son adecuados.
Los peatones y vehículos clasificados durante la detección de objetos se establecerán como estáticos y se eliminarán del recuento final si también aparecen en segundo plano. La siguiente imagen muestra resultados de ejemplo de la máscara estática, donde los autos estacionados en la imagen (a) se identifican como estáticos y se eliminan. Un beneficio adicional es que la máscara estática puede ayudar a eliminar falsas alarmas. Por ejemplo, en la imagen (b), el contenedor de basura se identifica erróneamente como un peatón en la detección de objetos, pero se filtra como fondo estático.

Los resultados simplemente se almacenan como una tabla, el esquema registra la identificación de la cámara, la fecha, la hora, los recuentos relacionados por tipo de objeto (automóvil, camioneta, peatón, etc.), si una imagen es defectuosa o si falta una imagen.
Inicialmente, el sistema fue diseñado para ser nativo de la nube, para permitir la escalabilidad; sin embargo, esto introduce una barrera de entrada: es necesario tener una cuenta con un proveedor de nube, saber cómo proteger la infraestructura, etc. Con esto en mente, también hemos adaptado el código para que funcione en una máquina independiente. (o "host local") para permitir que un usuario interesado simplemente ejecute el sistema en su propia computadora portátil. Ambas implementaciones se describen ahora a continuación.
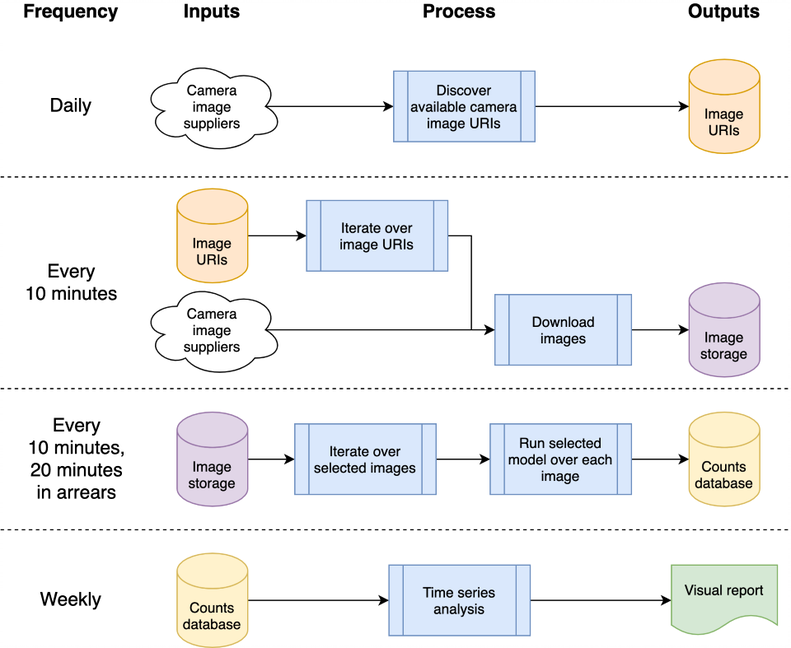
Esta arquitectura se puede asignar a una sola máquina o a un sistema en la nube; Optamos por utilizar Google Compute Platform (GCP), pero otras plataformas como Amazon Web Services (AWS) o Azure de Microsoft proporcionarían servicios relativamente equivalentes.
El sistema está alojado como “funciones en la nube”, que son código independiente y sin estado que se puede llamar repetidamente sin causar corrupción, una consideración clave para aumentar la solidez de las funciones. Las ráfagas de procesamiento diarias y “cada 10 minutos” se organizan mediante el Programador de GCP para activar un tema de publicación/subscripción de GCP de acuerdo con el cronograma deseado. Las funciones de la nube de GCP se registran en el tema y se inician cada vez que se activa el tema.
El procesamiento de las imágenes para detectar vehículos y peatones da como resultado recuentos de objetos que se escriben en una base de datos para su posterior análisis como una serie de tiempo. La base de datos se utiliza para compartir datos entre la recopilación de datos y el análisis de series de tiempo, lo que reduce el acoplamiento. Usamos BigQuery dentro de GCP como nuestra base de datos dado su amplio soporte en otros productos de GCP, como Data Studio para visualización de datos; la implementación del host local almacena CSV diarios en comparación, para eliminar cualquier dependencia de una base de datos particular u otra infraestructura.
El código fuente relacionado con GCP se almacena en la carpeta cloud ; esto descarga las imágenes, las procesa para contar objetos, almacena los recuentos en una base de datos y (semanalmente) produce análisis de series de tiempo. Toda la documentación y el código fuente se almacenan en la carpeta cloud ; Consulte Cloud README.md para obtener una descripción general de la arquitectura y cómo instalar su propia instancia utilizando nuestros scripts en su espacio de proyecto de GCP. El proyecto se puede integrar en GitHub, lo que permite la implementación automática y la ejecución de pruebas automáticamente desde confirmaciones a un proyecto de GitHub local; esto también está documentado en Cloud README.md. El código de soporte de la nube también se almacena en el módulo chrono_lens.gcloud , lo que permite que los scripts de línea de comandos admitan GCP, junto con el código de la función de la nube en la carpeta cloud .
El código independiente de una sola máquina ("localhost") está contenido en el módulo chrono_lens.localhost . El proceso sigue el mismo flujo que la variante de GCP, aunque utiliza una sola máquina y cada archivo de Python en chrono_lens.localhost se asigna a las funciones de nube de GCP. Consulte README-localhost.md para obtener más detalles.
Ahora describimos los diversos pasos y requisitos previos para instalar el sistema, dado que tanto las implementaciones de GCP como de hos locales requieren al menos alguna instalación local.
Se recomienda encarecidamente la creación de un entorno virtual que permita un entorno de trabajo aislado. Ejemplos de buenos entornos de trabajo incluyen conda, pyenv y poerty.
Tenga en cuenta que las dependencias ya están contenidas en requirements.txt , así que instálelo mediante pip:
pip install -r requirements.txt
Para evitar la confirmación accidental de contraseñas, se recomiendan ganchos de confirmación previa que evitan que las confirmaciones de git se procesen antes de que la información confidencial llegue al repositorio. Hemos utilizado los enlaces de confirmación previa de https://github.com/ukgovdatascience/govcookiecutter
La instalación de require.txt instalará la herramienta de confirmación previa, que ahora debe estar conectada a git:
pre-commit install
... que luego extraerá la configuración de .pre-commit-config.yaml .
NOTA: la prueba previa a la confirmación de verificación check-added-large-files tiene su tamaño máximo de kB en .pre-commit-config.yaml y se incrementa temporalmente a 60 Mb al agregar el archivo de modelo RCNN /tests/test_data/test_detector_data/fig_frcnn_rebuscov-3.pb . Luego, el límite se revierte a 5 Mb como límite superior "normal" sensato.
Se recomienda ejecutar un barrido en todos los archivos antes de continuar, solo para asegurarse de que no haya nada presente por error:
pre-commit run --all-files
Esto informará cualquier problema existente, lo que resulta útil ya que, de lo contrario, el enlace solo se ejecuta en archivos editados.
El proyecto está diseñado para usarse principalmente a través de una infraestructura en la nube, pero existen scripts de utilidad para acceso local y actualizaciones de las series temporales en la nube. Estos scripts se encuentran en la carpeta scripts/gcloud y ahora cada script se describe en secciones siguientes independientes. Puede encontrar más información en scripts/gcloud/README.md y su uso mediante una máquina virtual opcional se describe en cloud/README.md .
El uso fuera de la nube es compatible con los scripts en la carpeta scripts/localhost , y los detalles sobre cómo usar el sistema chrono_lens en una máquina independiente se describen en README-localhost.md . Puede encontrar más información sobre el uso de los scripts en scripts/localhost/README.md .
Tenga en cuenta que los scripts utilizan código en la carpeta chrono_lens .
| Versión | Fecha | Notas |
|---|---|---|
| 1.0.0 | 2021-06-08 | Primera versión del repositorio público |
| 1.0.1 | 2021-09-21 | Corrección de errores para imágenes aisladas, mejora de la versión de tensorflow |
| 1.1.0 | ? | Se agregó soporte limitado para una sola máquina independiente. |
Aquí se presentan áreas de posible trabajo futuro; Es posible que estos cambios no se investiguen, pero están aquí para informar a las personas sobre las posibles mejoras que hemos considerado.
En la actualidad, los scripts de bash shell se utilizan para crear la infraestructura de GCP; una mejora sería utilizar IaC, como Terraform. Esto simplifica el cambio de (por ejemplo) configuraciones de funciones de nube sin tener que eliminar manualmente el activador de compilación de nube y volver a crearlo cuando se cambian el entorno de ejecución o los límites de memoria.
El diseño actual surge de su caso de uso inicial de adquirir imágenes antes de que se finalizaran los modelos, por lo que se descargan todas las imágenes disponibles en lugar de solo aquellas que se analizan. Para ahorrar costos de ingesta, el código de ingesta debe compararse con los archivos JSON de análisis y descargar solo esos archivos; Se debe generar una alerta cuando cualquiera de estas fuentes ya no esté disponible o si aparecen nuevas fuentes.
La recarga nocturna de imágenes de NETravelData parece actualizar alrededor del 40% de las imágenes de NETravelData; La ventaja de una actualización regular disminuye si los números solo se requieren diariamente y, por lo tanto, se puede eliminar la función de nube distribute_ne_travel_data .
http async a PubSub El diseño inicial utiliza scripts operados manualmente al probar nuevos modelos, concretamente, batch_process_images.py . Esto informa el éxito (o no) y la cantidad de imágenes procesadas. Para hacer esto, una función en la nube funciona bien ya que devuelve un resultado. Sin embargo, una arquitectura más eficiente sería usar una cola PubSub internamente con las funciones distribute_json_sources processed_scheduled agregando trabajo a las colas PubSub que son consumidas por una única función de trabajo, en lugar de la jerarquía actual de llamadas asíncronas (usando dos funciones adicionales para escalar horizontalmente). ).
El Observatorio Urbano de la Universidad de Newcastle proporcionó el Faster-RCNNN previamente entrenado que utilizamos (una copia local se almacena en /tests/test_data/test_detector_data/fig_frcnn_rebuscov-3.pb ).
Los datos son proporcionados por el Servicio de Datos Abiertos de Control y Gestión del Tráfico Urbano del Noreste, con licencia de Gobierno Abierto 3.0. Las imágenes se atribuyen a Tyne and Wear Urban Traffic Management and Control.
Los datos del noreste son procesados y alojados por el Observatorio Urbano de la Universidad de Newcastle, cuyo apoyo y asesoramiento agradecemos.
Los datos son proporcionados por TfL y están impulsados por TfL Open Data. Los datos tienen licencia bajo la versión 2.0 de la Licencia de Gobierno Abierto. Los datos de TfL contienen datos del sistema operativo © Crown copyright y derechos de base de datos 2016 y Geomni UK Map data © y derechos de base de datos (2019).
En este proyecto se utilizan varias bibliotecas de terceros; estos se enumeran en la página de dependencias, cuyas contribuciones agradecemos con gratitud.


