shap
v0.46.0
SHAP (SHapley Additive exPlanations) es un enfoque de teoría de juegos para explicar el resultado de cualquier modelo de aprendizaje automático. Conecta la asignación óptima de crédito con explicaciones locales utilizando los valores clásicos de Shapley de la teoría de juegos y sus extensiones relacionadas (consulte los artículos para obtener detalles y citas).
SHAP se puede instalar desde PyPI o conda-forge:
forma de instalación de pip o instalación de conda -c forma de conda-forge
Si bien SHAP puede explicar el resultado de cualquier modelo de aprendizaje automático, hemos desarrollado un algoritmo exacto de alta velocidad para métodos de conjuntos de árboles (consulte nuestro artículo de Nature MI). Se admiten implementaciones rápidas de C++ para los modelos de árbol XGBoost , LightGBM , CatBoost , scikit-learn y pyspark :
import xgboost
import shap
# train an XGBoost model
X , y = shap . datasets . california ()
model = xgboost . XGBRegressor (). fit ( X , y )
# explain the model's predictions using SHAP
# (same syntax works for LightGBM, CatBoost, scikit-learn, transformers, Spark, etc.)
explainer = shap . Explainer ( model )
shap_values = explainer ( X )
# visualize the first prediction's explanation
shap . plots . waterfall ( shap_values [ 0 ])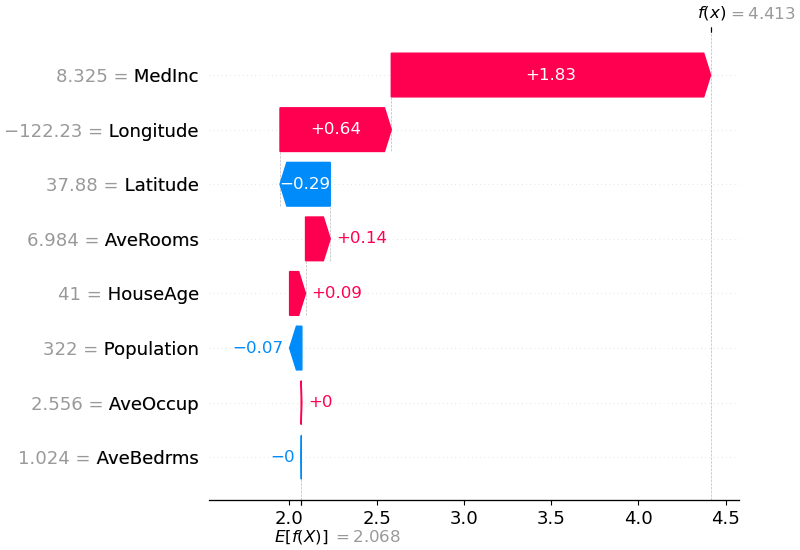
La explicación anterior muestra características que contribuyen a impulsar la salida del modelo desde el valor base (la salida promedio del modelo sobre el conjunto de datos de entrenamiento que pasamos) a la salida del modelo. Las características que empujan la predicción hacia arriba se muestran en rojo, las que empujan la predicción hacia abajo se muestran en azul. Otra forma de visualizar la misma explicación es utilizar un gráfico de fuerza (estos se presentan en nuestro artículo de Nature BME):
# visualize the first prediction's explanation with a force plot
shap . plots . force ( shap_values [ 0 ])
Si tomamos muchas explicaciones de gráficos de fuerza como la que se muestra arriba, las giramos 90 grados y luego las apilamos horizontalmente, podemos ver explicaciones para un conjunto de datos completo (en el cuaderno, este gráfico es interactivo):
# visualize all the training set predictions
shap . plots . force ( shap_values [: 500 ])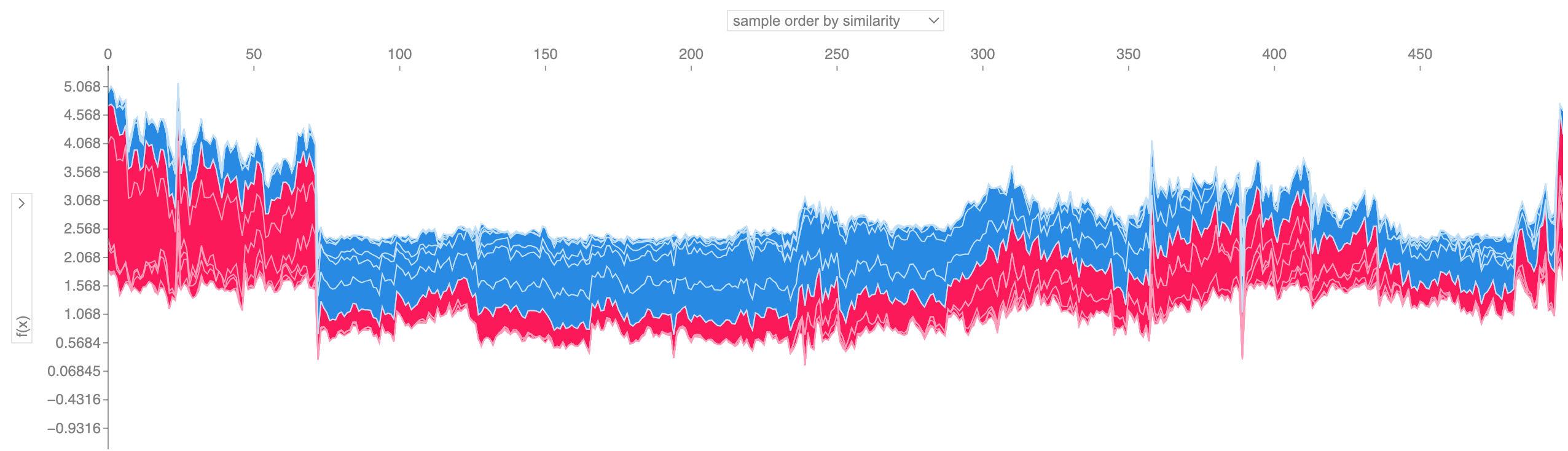
Para comprender cómo una sola característica afecta la salida del modelo, podemos trazar el valor SHAP de esa característica versus el valor de la característica para todos los ejemplos en un conjunto de datos. Dado que los valores SHAP representan la responsabilidad de una característica por un cambio en el resultado del modelo, el siguiente gráfico representa el cambio en el precio de la vivienda previsto a medida que cambia la latitud. La dispersión vertical en un único valor de latitud representa efectos de interacción con otras características. Para ayudar a revelar estas interacciones, podemos colorear según otra característica. Si pasamos todo el tensor de explicación al argumento color , el diagrama de dispersión elegirá la mejor característica para colorear. En este caso elige la longitud.
# create a dependence scatter plot to show the effect of a single feature across the whole dataset
shap . plots . scatter ( shap_values [:, "Latitude" ], color = shap_values )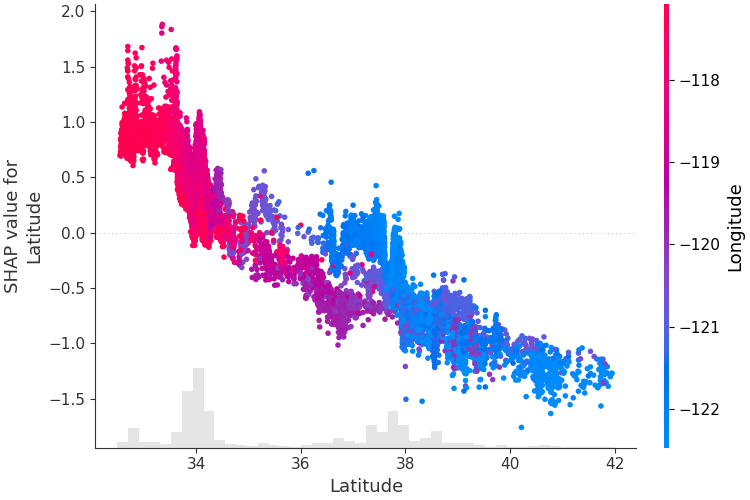
Para obtener una descripción general de qué características son más importantes para un modelo, podemos trazar los valores SHAP de cada característica para cada muestra. El siguiente gráfico clasifica las características por la suma de las magnitudes de los valores SHAP en todas las muestras y utiliza los valores SHAP para mostrar la distribución de los impactos que cada característica tiene en la salida del modelo. El color representa el valor de la característica (rojo alto, azul bajo). Esto revela, por ejemplo, que unos ingresos medios más altos mejoran el precio previsto de la vivienda.
# summarize the effects of all the features
shap . plots . beeswarm ( shap_values )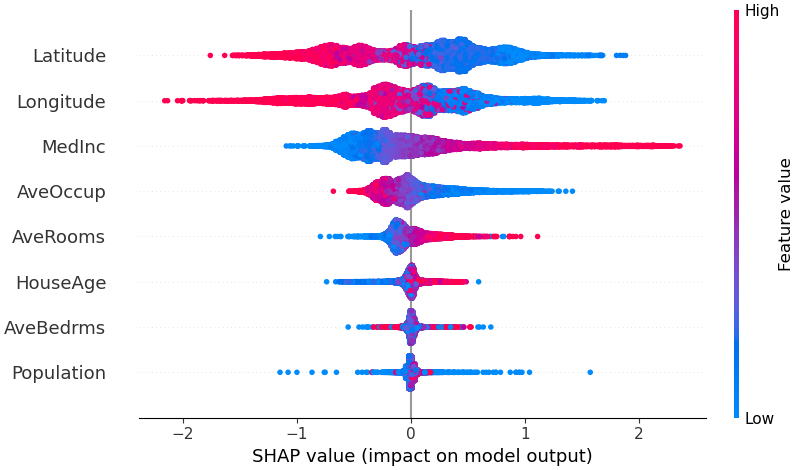
También podemos simplemente tomar el valor absoluto medio de los valores SHAP para cada característica para obtener un gráfico de barras estándar (produce barras apiladas para salidas de múltiples clases):
shap . plots . bar ( shap_values )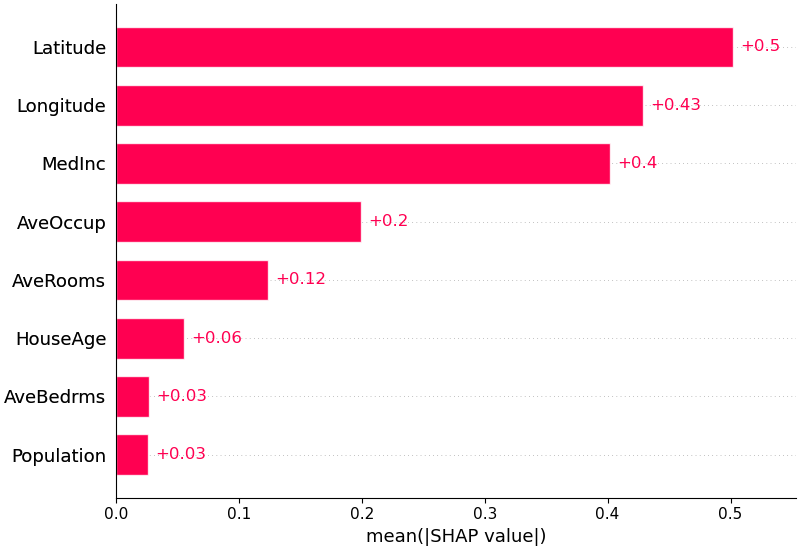
SHAP tiene soporte específico para modelos de lenguaje natural como los de la biblioteca de transformadores Hugging Face. Al agregar reglas de coalición a los valores tradicionales de Shapley, podemos formar juegos que expliquen grandes modelos modernos de PNL utilizando muy pocas evaluaciones de funciones. Usar esta funcionalidad es tan simple como pasar una canalización de transformadores compatibles a SHAP:
import transformers
import shap
# load a transformers pipeline model
model = transformers . pipeline ( 'sentiment-analysis' , return_all_scores = True )
# explain the model on two sample inputs
explainer = shap . Explainer ( model )
shap_values = explainer ([ "What a great movie! ...if you have no taste." ])
# visualize the first prediction's explanation for the POSITIVE output class
shap . plots . text ( shap_values [ 0 , :, "POSITIVE" ])Deep SHAP es un algoritmo de aproximación de alta velocidad para valores SHAP en modelos de aprendizaje profundo que se basa en una conexión con DeepLIFT descrita en el artículo SHAP NIPS. La implementación aquí difiere del DeepLIFT original al usar una distribución de muestras de fondo en lugar de un único valor de referencia y al usar ecuaciones de Shapley para linealizar componentes como max, softmax, productos, divisiones, etc. Tenga en cuenta que algunas de estas mejoras también se han implementado. desde que se integró en DeepLIFT. Se admiten los modelos TensorFlow y Keras que utilizan el backend de TensorFlow (también hay soporte preliminar para PyTorch):
# ...include code from https://github.com/keras-team/keras/blob/master/examples/demo_mnist_convnet.py
import shap
import numpy as np
# select a set of background examples to take an expectation over
background = x_train [ np . random . choice ( x_train . shape [ 0 ], 100 , replace = False )]
# explain predictions of the model on four images
e = shap . DeepExplainer ( model , background )
# ...or pass tensors directly
# e = shap.DeepExplainer((model.layers[0].input, model.layers[-1].output), background)
shap_values = e . shap_values ( x_test [ 1 : 5 ])
# plot the feature attributions
shap . image_plot ( shap_values , - x_test [ 1 : 5 ])El gráfico anterior explica diez resultados (dígitos del 0 al 9) para cuatro imágenes diferentes. Los píxeles rojos aumentan la salida del modelo, mientras que los píxeles azules la disminuyen. Las imágenes de entrada se muestran a la izquierda y como respaldos en escala de grises casi transparentes detrás de cada una de las explicaciones. La suma de los valores SHAP es igual a la diferencia entre el resultado esperado del modelo (promediado sobre el conjunto de datos de fondo) y el resultado del modelo actual. Tenga en cuenta que para la imagen "cero" el medio en blanco es importante, mientras que para la imagen "cuatro" la falta de una conexión en la parte superior hace que sea un cuatro en lugar de un nueve.
Los gradientes esperados combinan ideas de gradientes integrados, SHAP y SmoothGrad en una única ecuación de valor esperado. Esto permite utilizar un conjunto de datos completo como distribución de fondo (en lugar de un único valor de referencia) y permite el suavizado local. Si aproximamos el modelo con una función lineal entre cada muestra de datos de fondo y la entrada actual que se va a explicar, y asumimos que las características de entrada son independientes, entonces los gradientes esperados calcularán los valores SHAP aproximados. En el siguiente ejemplo, explicamos cómo la séptima capa intermedia del modelo ImageNet VGG16 afecta las probabilidades de salida.
from keras . applications . vgg16 import VGG16
from keras . applications . vgg16 import preprocess_input
import keras . backend as K
import numpy as np
import json
import shap
# load pre-trained model and choose two images to explain
model = VGG16 ( weights = 'imagenet' , include_top = True )
X , y = shap . datasets . imagenet50 ()
to_explain = X [[ 39 , 41 ]]
# load the ImageNet class names
url = "https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json"
fname = shap . datasets . cache ( url )
with open ( fname ) as f :
class_names = json . load ( f )
# explain how the input to the 7th layer of the model explains the top two classes
def map2layer ( x , layer ):
feed_dict = dict ( zip ([ model . layers [ 0 ]. input ], [ preprocess_input ( x . copy ())]))
return K . get_session (). run ( model . layers [ layer ]. input , feed_dict )
e = shap . GradientExplainer (
( model . layers [ 7 ]. input , model . layers [ - 1 ]. output ),
map2layer ( X , 7 ),
local_smoothing = 0 # std dev of smoothing noise
)
shap_values , indexes = e . shap_values ( map2layer ( to_explain , 7 ), ranked_outputs = 2 )
# get the names for the classes
index_names = np . vectorize ( lambda x : class_names [ str ( x )][ 1 ])( indexes )
# plot the explanations
shap . image_plot ( shap_values , to_explain , index_names ) Las predicciones para dos imágenes de entrada se explican en el gráfico anterior. Los píxeles rojos representan valores SHAP positivos que aumentan la probabilidad de la clase, mientras que los píxeles azules representan valores SHAP negativos que reducen la probabilidad de la clase. Al usar ranked_outputs=2 explicamos solo las dos clases más probables para cada entrada (esto nos ahorra tener que explicar las 1000 clases).
Kernel SHAP utiliza una regresión lineal local especialmente ponderada para estimar los valores SHAP para cualquier modelo. A continuación se muestra un ejemplo sencillo para explicar una SVM de clases múltiples en el conjunto de datos de iris clásico.
import sklearn
import shap
from sklearn . model_selection import train_test_split
# print the JS visualization code to the notebook
shap . initjs ()
# train a SVM classifier
X_train , X_test , Y_train , Y_test = train_test_split ( * shap . datasets . iris (), test_size = 0.2 , random_state = 0 )
svm = sklearn . svm . SVC ( kernel = 'rbf' , probability = True )
svm . fit ( X_train , Y_train )
# use Kernel SHAP to explain test set predictions
explainer = shap . KernelExplainer ( svm . predict_proba , X_train , link = "logit" )
shap_values = explainer . shap_values ( X_test , nsamples = 100 )
# plot the SHAP values for the Setosa output of the first instance
shap . force_plot ( explainer . expected_value [ 0 ], shap_values [ 0 ][ 0 ,:], X_test . iloc [ 0 ,:], link = "logit" )La explicación anterior muestra cuatro características, cada una de las cuales contribuye a impulsar la salida del modelo desde el valor base (la salida promedio del modelo sobre el conjunto de datos de entrenamiento que pasamos) hacia cero. Si hubiera alguna característica que aumentara la etiqueta de clase, se mostraría en rojo.
Si tomamos muchas explicaciones como la que se muestra arriba, las giramos 90 grados y luego las apilamos horizontalmente, podemos ver explicaciones para un conjunto de datos completo. Esto es exactamente lo que hacemos a continuación para todos los ejemplos del conjunto de pruebas de iris:
# plot the SHAP values for the Setosa output of all instances
shap . force_plot ( explainer . expected_value [ 0 ], shap_values [ 0 ], X_test , link = "logit" ) Los valores de interacción SHAP son una generalización de los valores SHAP a interacciones de orden superior. Se implementa un cálculo rápido y exacto de interacciones por pares para modelos de árbol con shap.TreeExplainer(model).shap_interaction_values(X) . Esto devuelve una matriz para cada predicción, donde los efectos principales están en la diagonal y los efectos de interacción están fuera de la diagonal. Estos valores a menudo revelan relaciones ocultas interesantes, como por ejemplo cómo el mayor riesgo de muerte alcanza su punto máximo para los hombres a los 60 años (consulte el cuaderno de NHANES para obtener más detalles):
Los cuadernos siguientes muestran diferentes casos de uso de SHAP. Mire dentro del directorio de cuadernos del repositorio si desea intentar jugar usted mismo con los cuadernos originales.
Una implementación de Tree SHAP, un algoritmo rápido y exacto para calcular valores SHAP para árboles y conjuntos de árboles.
Modelo de supervivencia NHANES con valores de interacción XGBoost y SHAP : utilizando datos de mortalidad de 20 años de seguimiento, este cuaderno demuestra cómo utilizar XGBoost y shap para descubrir relaciones complejas entre factores de riesgo.
Clasificación de ingresos del censo con LightGBM : utilizando el conjunto de datos de ingresos del censo de adultos estándar, este cuaderno entrena un modelo de árbol de aumento de gradiente con LightGBM y luego explica las predicciones usando shap .
Predicción de victorias de League of Legends con XGBoost : utilizando un conjunto de datos de Kaggle de 180 000 partidos clasificados de League of Legends, entrenamos y explicamos un modelo de árbol de aumento de gradiente con XGBoost para predecir si un jugador ganará su partido.
Una implementación de Deep SHAP, un algoritmo más rápido (pero solo aproximado) para calcular valores SHAP para modelos de aprendizaje profundo que se basa en conexiones entre SHAP y el algoritmo DeepLIFT.
MNIST Clasificación de dígitos con Keras : utilizando el conjunto de datos de reconocimiento de escritura a mano MNIST, este cuaderno entrena una red neuronal con Keras y luego explica las predicciones usando shap .
Keras LSTM para la clasificación de sentimiento de IMDB : este cuaderno entrena un LSTM con Keras en el conjunto de datos de análisis de sentimiento de texto de IMDB y luego explica las predicciones usando shap .
Una implementación de gradientes esperados para aproximar los valores SHAP para modelos de aprendizaje profundo. Se basa en conexiones entre SHAP y el algoritmo de gradientes integrados. GradientExplainer es más lento que DeepExplainer y hace suposiciones de aproximación diferentes.
Para un modelo lineal con características independientes, podemos calcular analíticamente los valores SHAP exactos. También podemos tener en cuenta la correlación de características si estamos dispuestos a estimar la matriz de covarianza de características. LinearExplainer admite ambas opciones.
Una implementación de Kernel SHAP, un método independiente del modelo para estimar los valores SHAP para cualquier modelo. Debido a que no hace suposiciones sobre el tipo de modelo, KernelExplainer es más lento que otros algoritmos específicos del tipo de modelo.
Clasificación de ingresos del censo con scikit-learn : utilizando el conjunto de datos de ingresos del censo de adultos estándar, este cuaderno entrena un clasificador de k vecinos más cercanos usando scikit-learn y luego explica las predicciones usando shap .
Modelo ImageNet VGG16 con Keras : explique las predicciones de la red neuronal convolucional VGG16 clásica para una imagen. Esto funciona aplicando el método Kernel SHAP independiente del modelo a una imagen segmentada de superpíxeles.
Clasificación del iris : una demostración básica utilizando el popular conjunto de datos de especies de iris. Explica las predicciones de seis modelos diferentes en scikit-learn usando shap .
Estos cuadernos demuestran de forma exhaustiva cómo utilizar funciones y objetos específicos.
shap.decision_plot y shap.multioutput_decision_plot
shap.dependence_plot
LIMA: Ribeiro, Marco Tulio, Sameer Singh y Carlos Guestrin. "¿Por qué debería confiar en ti?: Explicando las predicciones de cualquier clasificador." Actas de la 22ª Conferencia Internacional ACM SIGKDD sobre Descubrimiento de Conocimiento y Minería de Datos. ACM, 2016.
Valores de muestreo de Shapley: Strumbelj, Erik e Igor Kononenko. "Explicar los modelos de predicción y las predicciones individuales con contribuciones de características". Sistemas de conocimiento e información 41.3 (2014): 647-665.
DeepLIFT: Shrikumar, Avanti, Peyton Greenside y Anshul Kundaje. "Aprender características importantes mediante la propagación de diferencias de activación". Preimpresión de arXiv arXiv:1704.02685 (2017).
Pregunta II: Datta, Anupam, Shayak Sen y Yair Zick. "Transparencia algorítmica a través de la influencia de la entrada cuantitativa: teoría y experimentos con sistemas de aprendizaje". Seguridad y Privacidad (SP), Simposio IEEE 2016 sobre. IEEE, 2016.
Propagación de relevancia por capas: Bach, Sebastian, et al. "Sobre explicaciones en píxeles para decisiones de clasificadores no lineales mediante propagación de relevancia en capas". PloS uno 10.7 (2015): e0130140.
Valores de regresión de Shapley: Lipovetsky, Stan y Michael Conklin. "Análisis de la regresión en el enfoque de la teoría de juegos". Modelos estocásticos aplicados en negocios e industria 17.4 (2001): 319-330.
Intérprete del árbol: Saabas, Ando. Interpretación de bosques aleatorios. http://blog.datadive.net/interpreting-random-forests/
Los algoritmos y visualizaciones utilizados en este paquete surgieron principalmente de investigaciones en el laboratorio de Su-In Lee en la Universidad de Washington y Microsoft Research. Si utiliza SHAP en su investigación, le agradeceríamos una cita de los artículos correspondientes:
force_plot y aplicaciones médicas, puede leer/citar nuestro artículo de Nature Biomedical Engineering (bibtex; acceso gratuito).

