Candle es un marco de aprendizaje automático minimalista para Rust centrado en el rendimiento (incluida la compatibilidad con GPU) y la facilidad de uso. Pruebe nuestras demostraciones en línea: susurro, LLaMA2, T5, yolo, Segment Anything.
Asegúrese de tener candle-core instalado correctamente como se describe en Instalación .
Veamos cómo ejecutar una multiplicación de matrices simple. Escriba lo siguiente en su archivo myapp/src/main.rs :
use candle_core :: { Device , Tensor } ;
fn main ( ) -> Result < ( ) , Box < dyn std :: error :: Error > > {
let device = Device :: Cpu ;
let a = Tensor :: randn ( 0f32 , 1. , ( 2 , 3 ) , & device ) ? ;
let b = Tensor :: randn ( 0f32 , 1. , ( 3 , 4 ) , & device ) ? ;
let c = a . matmul ( & b ) ? ;
println ! ( "{c}" ) ;
Ok ( ( ) )
} cargo run debe mostrar un tensor de forma Tensor[[2, 4], f32] .
Una vez instalada candle con soporte Cuda, simplemente defina que el device esté en GPU:
- let device = Device::Cpu;
+ let device = Device::new_cuda(0)?;Para ver ejemplos más avanzados, consulte la siguiente sección.
Estas demostraciones en línea se ejecutan completamente en su navegador:
También proporcionamos algunos ejemplos basados en la línea de comandos utilizando modelos de última generación:
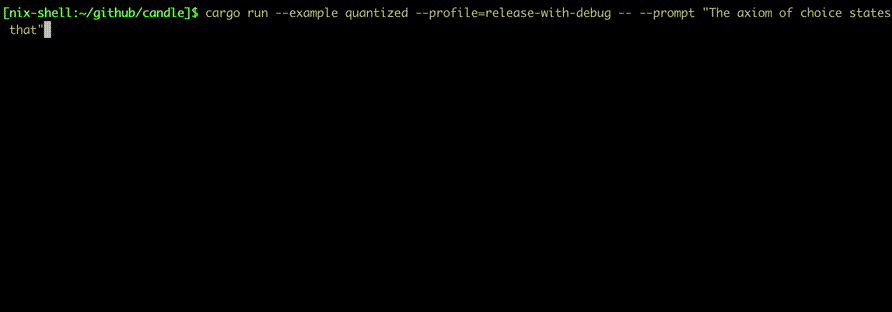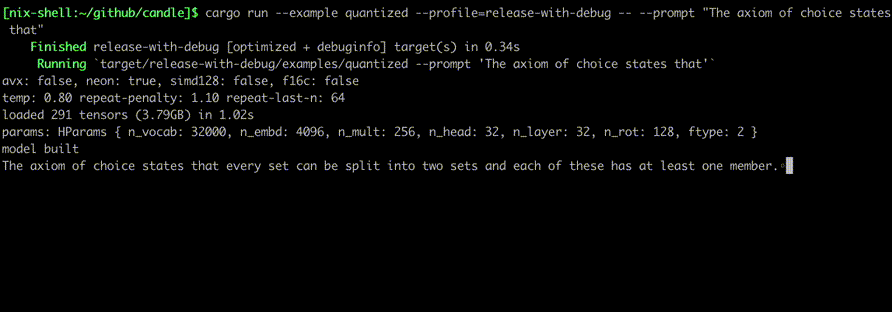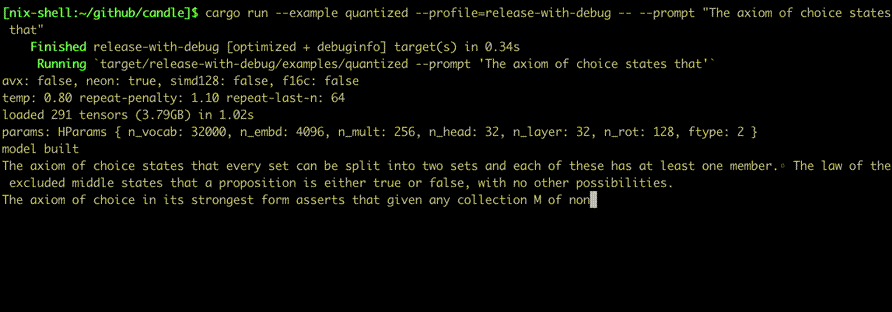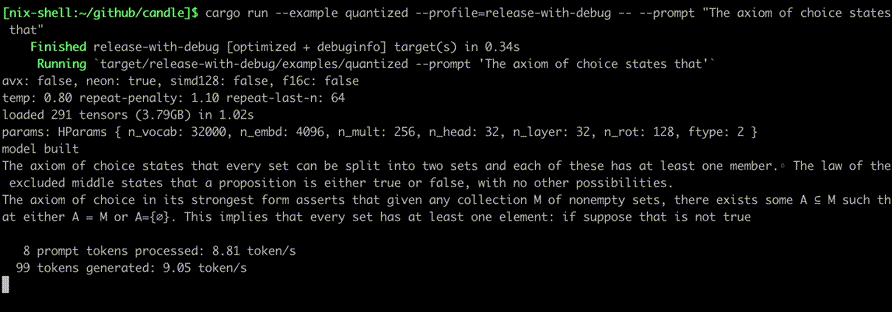





Ejecútelos usando comandos como:
cargo run --example quantized --release
Para utilizar CUDA, agregue --features cuda a la línea de comando de ejemplo. Si tiene cuDNN instalado, use --features cudnn para acelerar aún más.
También hay algunos ejemplos de wasm para susurro y llama2.c. Puedes construirlos con trunk o probarlos en línea: Whisper, Llama2, T5, Phi-1.5 y Phi-2, Segment Anything Model.
Para LLaMA2, ejecute el siguiente comando para recuperar los archivos de peso e iniciar un servidor de prueba:
cd candle-wasm-examples/llama2-c
wget https://huggingface.co/spaces/lmz/candle-llama2/resolve/main/model.bin
wget https://huggingface.co/spaces/lmz/candle-llama2/resolve/main/tokenizer.json
trunk serve --release --port 8081Y luego dirígete a http://localhost:8081/.
candle-tutorial : un tutorial muy detallado que muestra cómo convertir un modelo de PyTorch a Candle.candle-lora : Implementación LoRA eficiente y ergonómica para Candle. candle-lora tieneoptimisers : una colección de optimizadores que incluye SGD con impulso, AdaGrad, AdaDelta, AdaMax, NAdam, RAdam y RMSprop.candle-vllm : plataforma eficiente para inferencia y servicio de LLM locales, incluido un servidor API compatible con OpenAI.candle-ext : una biblioteca de extensión para Candle que proporciona funciones de PyTorch que no están disponibles actualmente en Candle.candle-coursera-ml : Implementación de algoritmos de ML del curso de especialización en aprendizaje automático de Coursera.kalosm : un metamarco multimodal en Rust para interactuar con modelos locales previamente entrenados con soporte para generación controlada, samplers personalizados, bases de datos vectoriales en memoria, transcripción de audio y más.candle-sampling : Técnicas de muestreo para velas.gpt-from-scratch-rs : una adaptación del tutorial Construyamos GPT de Andrej Karpathy en YouTube que muestra la API Candle en un problema de juguete.candle-einops : Una implementación puramente oxidada de la biblioteca einops de Python.atoma-infer : una biblioteca de Rust para una inferencia rápida a escala, que aprovecha FlashAttention2 para un cálculo de atención eficiente, PagedAttention para una gestión eficiente de la memoria caché KV y compatibilidad con múltiples GPU. Es compatible con la API de OpenAI.Si tiene una adición a esta lista, envíe una solicitud de extracción.
Hoja de referencia:
| Usando PyTorch | Usando vela | |
|---|---|---|
| Creación | torch.Tensor([[1, 2], [3, 4]]) | Tensor::new(&[[1f32, 2.], [3., 4.]], &Device::Cpu)? |
| Creación | torch.zeros((2, 2)) | Tensor::zeros((2, 2), DType::F32, &Device::Cpu)? |
| Indexación | tensor[:, :4] | tensor.i((.., ..4))? |
| Operaciones | tensor.view((2, 2)) | tensor.reshape((2, 2))? |
| Operaciones | a.matmul(b) | a.matmul(&b)? |
| Aritmética | a + b | &a + &b |
| Dispositivo | tensor.to(device="cuda") | tensor.to_device(&Device::new_cuda(0)?)? |
| tipo D | tensor.to(dtype=torch.float16) | tensor.to_dtype(&DType::F16)? |
| Ahorro | torch.save({"A": A}, "model.bin") | candle::safetensors::save(&HashMap::from([("A", A)]), "model.safetensors")? |
| Cargando | weights = torch.load("model.bin") | candle::safetensors::load("model.safetensors", &device) |
TensorEl objetivo principal de Candle es hacer posible la inferencia sin servidor . Los marcos completos de aprendizaje automático como PyTorch son muy grandes, lo que hace que la creación de instancias en un clúster sea lenta. Candle permite el despliegue de binarios ligeros.
En segundo lugar, Candle te permite eliminar Python de las cargas de trabajo de producción. La sobrecarga de Python puede perjudicar gravemente el rendimiento y GIL es una fuente notoria de dolores de cabeza.
¡Finalmente, Rust es genial! Gran parte del ecosistema HF ya tiene cajas Rust, como tensores de seguridad y tokenizadores.
dfdx es una caja formidable, con formas incluidas en tipos. Esto evita muchos dolores de cabeza al hacer que el compilador se queje de las discrepancias de forma desde el principio. Sin embargo, descubrimos que algunas funciones aún requieren trabajo nocturno y escribir código puede resultar un poco desalentador para los expertos en no oxidación.
Estamos aprovechando y contribuyendo con otras cajas principales durante el tiempo de ejecución, por lo que esperamos que ambas cajas puedan beneficiarse entre sí.
burn es una caja general que puede aprovechar múltiples backends para que puedas elegir el mejor motor para tu carga de trabajo.
tch-rs Enlaces a la biblioteca torch en Rust. Extremadamente versátiles, pero incorporan toda la biblioteca de antorchas al tiempo de ejecución. El principal contribuyente de tch-rs también participa en el desarrollo de candle .
Si le faltan algunos símbolos al compilar binarios/pruebas usando mkl o funciones de aceleración, por ejemplo, para mkl obtendrá:
= note: /usr/bin/ld: (....o): in function `blas::sgemm':
.../blas-0.22.0/src/lib.rs:1944: undefined reference to `sgemm_' collect2: error: ld returned 1 exit status
= note: some `extern` functions couldn't be found; some native libraries may need to be installed or have their path specified
= note: use the `-l` flag to specify native libraries to link
= note: use the `cargo:rustc-link-lib` directive to specify the native libraries to link with Cargo
o para acelerar:
Undefined symbols for architecture arm64:
"_dgemm_", referenced from:
candle_core::accelerate::dgemm::h1b71a038552bcabe in libcandle_core...
"_sgemm_", referenced from:
candle_core::accelerate::sgemm::h2cf21c592cba3c47 in libcandle_core...
ld: symbol(s) not found for architecture arm64
Es probable que esto se deba a que falta un indicador del vinculador que era necesario para habilitar la biblioteca mkl. Puedes intentar agregar lo siguiente para mkl en la parte superior de tu binario:
extern crate intel_mkl_src ;o para acelerar:
extern crate accelerate_src ; Error: request error: https://huggingface.co/meta-llama/Llama-2-7b-hf/resolve/main/tokenizer.json: status code 401
Es probable que esto se deba a que no tienes permiso para el modelo LLaMA-v2. Para solucionar este problema, debe registrarse en huggingface-hub, aceptar las condiciones del modelo LLaMA-v2 y configurar su token de autenticación. Consulte el número 350 para obtener más detalles.
In file included from kernels/flash_fwd_launch_template.h:11:0,
from kernels/flash_fwd_hdim224_fp16_sm80.cu:5:
kernels/flash_fwd_kernel.h:8:10: fatal error: cute/algorithm/copy.hpp: No such file or directory
#include <cute/algorithm/copy.hpp>
^~~~~~~~~~~~~~~~~~~~~~~~~
compilation terminated.
Error: nvcc error while compiling:
cutlass se proporciona como un submódulo de git, por lo que es posible que desees ejecutar el siguiente comando para registrarlo correctamente.
git submodule update --init /usr/include/c++/11/bits/std_function.h:530:146: error: parameter packs not expanded with ‘...’:
Este es un error en gcc-11 provocado por el compilador Cuda. Para solucionar este problema, instale una versión diferente de gcc compatible, por ejemplo gcc-10, y especifique la ruta al compilador en la variable de entorno NVCC_CCBIN.
env NVCC_CCBIN=/usr/lib/gcc/x86_64-linux-gnu/10 cargo ...
Couldn't compile the test.
---- .candle-booksrcinferencehub.md - Using_the_hub::Using_in_a_real_model_ (line 50) stdout ----
error: linking with `link.exe` failed: exit code: 1181
//very long chain of linking
= note: LINK : fatal error LNK1181: cannot open input file 'windows.0.48.5.lib'
Asegúrese de vincular todas las bibliotecas nativas que puedan estar ubicadas fuera del objetivo del proyecto; por ejemplo, para ejecutar pruebas de mdbook, debe ejecutar:
mdbook test candle-book -L .targetdebugdeps `
-L native=$env:USERPROFILE.cargoregistrysrcindex.crates.io-6f17d22bba15001fwindows_x86_64_msvc-0.42.2lib `
-L native=$env:USERPROFILE.cargoregistrysrcindex.crates.io-6f17d22bba15001fwindows_x86_64_msvc-0.48.5lib
Esto puede deberse a que los modelos se cargan desde /mnt/c , más detalles en stackoverflow.
Puede configurar RUST_BACKTRACE=1 para que se le proporcionen rastreos cuando se genere un error de vela.
Si encuentra un error como este called Result::unwrap() on an value: LoadLibraryExW { source: Os { code: 126, kind: Uncategorized, message: "The specified module could not be found." } } en ventanas. Para arreglarlo, copie y cambie el nombre de estos 3 archivos (asegúrese de que estén en la ruta). Las rutas dependen de su versión de cuda. c:WindowsSystem32nvcuda.dll -> cuda.dll c:Program FilesNVIDIA GPU Computing ToolkitCUDAv12.4bincublas64_12.dll -> cublas.dll c:Program FilesNVIDIA GPU Computing ToolkitCUDAv12.4bincurand64_10.dll -> curand.dll


