whisperX
3.1.1
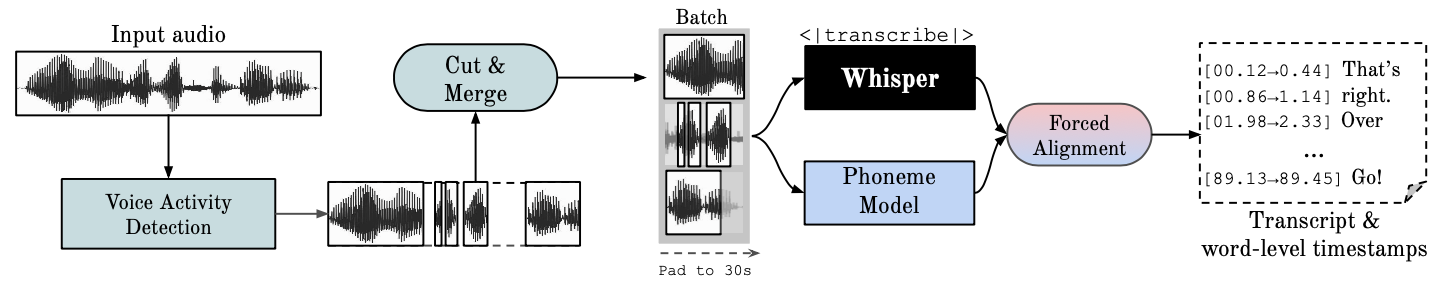
Este repositorio proporciona reconocimiento de voz automático rápido (70 veces en tiempo real con versión grande 2) con marcas de tiempo a nivel de palabra y registro del hablante.
Whisper es un modelo ASR desarrollado por OpenAI, entrenado en un gran conjunto de datos de audio diverso. Si bien produce transcripciones muy precisas, las marcas de tiempo correspondientes están a nivel de expresión, no por palabra, y pueden tener una imprecisión de varios segundos. El susurro de OpenAI no admite de forma nativa el procesamiento por lotes.
ASR basado en fonemas Un conjunto de modelos ajustados para reconocer la unidad de habla más pequeña que distingue una palabra de otra, por ejemplo, el elemento p en "tap". Un modelo de ejemplo popular es wav2vec2.0.
La alineación forzada se refiere al proceso mediante el cual las transcripciones ortográficas se alinean con las grabaciones de audio para generar automáticamente una segmentación a nivel de teléfono.
La Detección de Actividad de Voz (VAD) es la detección de la presencia o ausencia del habla humana.
La diarioización del hablante es el proceso de dividir un flujo de audio que contiene el habla humana en segmentos homogéneos según la identidad de cada hablante.
La ejecución de GPU requiere que las bibliotecas NVIDIA cuBLAS 11.x y cuDNN 8.x estén instaladas en el sistema. Consulte la documentación de CTranslate2.
conda create --name whisperx python=3.10
conda activate whisperx
conda install pytorch==2.0.0 torchaudio==2.0.0 pytorch-cuda=11.8 -c pytorch -c nvidia
Vea otros métodos aquí.
pip install git+https://github.com/m-bain/whisperx.git
Si ya está instalado, actualice el paquete a la confirmación más reciente
pip install git+https://github.com/m-bain/whisperx.git --upgrade
Si desea modificar este paquete, clónelo e instálelo en modo editable:
$ git clone https://github.com/m-bain/whisperX.git
$ cd whisperX
$ pip install -e .
Es posible que también necesite instalar ffmpeg, rust, etc. Siga las instrucciones de openAI aquí https://github.com/openai/whisper#setup.
Para habilitar Speaker Diarization , incluya su token de acceso Hugging Face (lectura) que puede generar desde aquí después del argumento --hf_token y acepte el acuerdo de usuario para los siguientes modelos: Segmentation y Speaker-Diarization-3.1 (si elige usar Speaker Diarization) -Diarización 2.x, siga los requisitos aquí.)
Nota
A partir del 11 de octubre de 2023, existe un problema conocido relacionado con el rendimiento lento con pyannote/Speaker-Diarization-3.0 en WhisperX. Se debe a conflictos de dependencia entre fast-whisper y pyannote-audio 3.0.0. Consulte este problema para obtener más detalles y posibles soluciones.
Ejecute susurro en un segmento de ejemplo (usando parámetros predeterminados, susurro pequeño) y agregue --highlight_words True para visualizar la sincronización de las palabras en el archivo .srt.
whisperx examples/sample01.wav
Resultado usando WhisperX con alineación forzada a wav2vec2.0 grande:
Compare esto con el susurro original, donde muchas transcripciones no están sincronizadas:
Para una mayor precisión de la marca de tiempo, a costa de una mayor memoria de GPU, utilice modelos más grandes (el modelo de alineación más grande no resulta tan útil, consulte el documento), por ejemplo
whisperx examples/sample01.wav --model large-v2 --align_model WAV2VEC2_ASR_LARGE_LV60K_960H --batch_size 4
Para etiquetar la transcripción con el ID de los oradores (establezca el número de oradores si lo conoce, por ejemplo, --min_speakers 2 --max_speakers 2 ):
whisperx examples/sample01.wav --model large-v2 --diarize --highlight_words True
Para ejecutar en CPU en lugar de GPU (y para ejecutar en Mac OS X):
whisperx examples/sample01.wav --compute_type int8
El modelo de alineación ASR de fonemas es específico del idioma ; para los idiomas probados, estos modelos se seleccionan automáticamente de los canales de torchaudio o huggingface. Simplemente pase el código --language y use el susurro --model large .
Actualmente se proporcionan modelos predeterminados para {en, fr, de, es, it, ja, zh, nl, uk, pt} . Si el idioma detectado no está en esta lista, debe encontrar un modelo ASR basado en fonemas en el centro de modelos de Huggingface y probarlo en sus datos.
whisperx --model large-v2 --language de examples/sample_de_01.wav
Vea más ejemplos en otros idiomas aquí.
import whisperx
import gc
device = "cuda"
audio_file = "audio.mp3"
batch_size = 16 # reduce if low on GPU mem
compute_type = "float16" # change to "int8" if low on GPU mem (may reduce accuracy)
# 1. Transcribe with original whisper (batched)
model = whisperx . load_model ( "large-v2" , device , compute_type = compute_type )
# save model to local path (optional)
# model_dir = "/path/"
# model = whisperx.load_model("large-v2", device, compute_type=compute_type, download_root=model_dir)
audio = whisperx . load_audio ( audio_file )
result = model . transcribe ( audio , batch_size = batch_size )
print ( result [ "segments" ]) # before alignment
# delete model if low on GPU resources
# import gc; gc.collect(); torch.cuda.empty_cache(); del model
# 2. Align whisper output
model_a , metadata = whisperx . load_align_model ( language_code = result [ "language" ], device = device )
result = whisperx . align ( result [ "segments" ], model_a , metadata , audio , device , return_char_alignments = False )
print ( result [ "segments" ]) # after alignment
# delete model if low on GPU resources
# import gc; gc.collect(); torch.cuda.empty_cache(); del model_a
# 3. Assign speaker labels
diarize_model = whisperx . DiarizationPipeline ( use_auth_token = YOUR_HF_TOKEN , device = device )
# add min/max number of speakers if known
diarize_segments = diarize_model ( audio )
# diarize_model(audio, min_speakers=min_speakers, max_speakers=max_speakers)
result = whisperx . assign_word_speakers ( diarize_segments , result )
print ( diarize_segments )
print ( result [ "segments" ]) # segments are now assigned speaker IDs Si no tiene acceso a sus propias GPU, utilice los enlaces anteriores para probar WhisperX.
Para obtener detalles específicos sobre el procesamiento por lotes y la alineación, el efecto de VAD, así como el modelo de alineación elegido, consulte el documento preimpreso.
Para reducir los requisitos de memoria de la GPU, pruebe cualquiera de las siguientes opciones (2. y 3. pueden afectar la calidad):
--batch_size 4--model base--compute_type int8Diferencias de transcripción del susurro de openai:
--without_timestamps True , esto garantiza 1 pasada directa por muestra en el lote. Sin embargo, esto puede provocar discrepancias en la salida de susurro predeterminada.--condition_on_prev_text está configurado en False de forma predeterminada (reduce las alucinaciones) Si eres multilingüe, una forma importante de contribuir a este proyecto es encontrar modelos de fonemas en huggingface (o entrenar el tuyo propio) y probarlos en el habla del idioma de destino. Si los resultados parecen buenos, envíe una solicitud de extracción y algunos ejemplos que muestren su éxito.
La búsqueda de errores y las solicitudes de extracción también son muy apreciadas para mantener este proyecto en marcha, ya que ya se está desviando del alcance de la investigación original.
Inicio multilingüe
Selección automática de modelos de alineación basada en la detección de idioma
Uso de Python
Incorporación de la diarioización de los hablantes
Descarga de modelo, para recursos de memoria de GPU bajos
Backend más rápido
Agregue max-line, etc. consulte (susurro de openai utils.py)
Segmentos a nivel de oración (caja de herramientas nltk)
Mejorar la lógica de alineación
actualizar ejemplos con diario y resaltado de palabras
Salida de subtítulo .ass <- traer esto de vuelta (eliminado en v3)
Agregue código de evaluación comparativa (TEDLIUM para spd/WER y segmentación de palabras)
Permitir silero-vad como opción VAD alternativa
Mejorar la diarioización (nivel de palabras). Más difícil de lo que se pensaba...
Póngase en contacto con [email protected] para consultas.
Este trabajo, y mi doctorado, cuentan con el apoyo del VGG (Visual Geometry Group) y la Universidad de Oxford.
Por supuesto, esto se basa en el susurro de openAI. Toma prestado un importante código de alineación del tutorial de PyTorch sobre alineación forzada y utiliza el maravilloso pyannote VAD/Diarización https://github.com/pyannote/pyannote-audio
Valiosos modelos de VAD y diarización de [pyannote audio][https://github.com/pyannote/pyannote-audio]
Excelente backend de Fast-Whisper y CTranslate2
Quienes han apoyado económicamente este trabajo.
Finalmente, gracias a los contribuyentes del sistema operativo de este proyecto, por mantenerlo en marcha e identificar errores.
@article { bain2022whisperx ,
title = { WhisperX: Time-Accurate Speech Transcription of Long-Form Audio } ,
author = { Bain, Max and Huh, Jaesung and Han, Tengda and Zisserman, Andrew } ,
journal = { INTERSPEECH 2023 } ,
year = { 2023 }
}

