LARS
v2.0-beta8:

LARS es una aplicación que le permite ejecutar LLM (modelos de lenguaje grande) localmente en su dispositivo, cargar sus propios documentos y participar en conversaciones en las que el LLM basa sus respuestas en el contenido subido. Esta conexión a tierra ayuda a aumentar la precisión y reducir el problema común de las imprecisiones o "alucinaciones" generadas por la IA. Esta técnica se conoce comúnmente como "Generación Aumentada de Recuperación" o RAG.
Existen muchas aplicaciones de escritorio para ejecutar LLM localmente, y LARS pretende ser la aplicación LLM de código abierto centrada en RAG definitiva. Con este fin, LARS lleva el concepto de RAG mucho más allá al agregar citas detalladas a cada respuesta, proporcionándole nombres de documentos específicos, números de página, resaltado de texto e imágenes relevantes para su pregunta, e incluso presentando un lector de documentos directamente dentro del ventana de respuesta. Si bien no siempre todas las citas están presentes para cada respuesta, la idea es tener al menos alguna combinación de citas para cada respuesta del RAG y, en general, ese es el caso.
Vídeo de demostración de funciones LARS
Python v3.10.x o superior: https://www.python.org/downloads/
PyTorch:
Si planea usar su GPU para ejecutar LLM, asegúrese de instalar los controladores de GPU y los kits de herramientas CUDA/ROCm según corresponda para su configuración, y solo entonces continúe con la configuración de PyTorch a continuación.
Descargue e instale la versión de PyTorch adecuada para su sistema: https://pytorch.org/get-started/locally/
Clonar el repositorio:
git clone https://github.com/abgulati/LARS
cd LARS
GitHub Settings -> Developer settings (located on the bottom left!) -> Personal access tokensInstale las dependencias de Python:
Windows a través de PIP:
pip install -r .requirements.txt
Linux a través de PIP:
pip3 install -r ./requirements.txt
Nota sobre Azure: ¡Algunas bibliotecas de Azure requeridas NO están disponibles en la plataforma MacOS! Por lo tanto, se incluye un archivo de requisitos independiente para MacOS que excluye estas bibliotecas:
Mac OS:
pip3 install -r ./requirements_mac.txt
Volver a la tabla de contenidos
Después de la instalación, ejecute LARS usando:
cd web_app
python app.py # Use 'python3' on Linux/macOS
Navegue a http://localhost:5000/ en su navegador
Todos los directorios de aplicaciones requeridos por LARS ahora se crearán en el disco
El servidor HF-Waitress se iniciará automáticamente y descargará un LLM (Microsoft Phi-3-Mini-Instruct-44) en la primera ejecución, lo que puede tardar un poco dependiendo de la velocidad de su conexión a Internet.
En la primera consulta, se descargará un modelo de incrustación (all-mpnet-base-v2) de HuggingFace Hub, lo que debería tomar un breve tiempo.
Volver a la tabla de contenidos
En Windows:
Descargue Microsoft Visual Studio Build Tools 2022 desde el sitio oficial: "Herramientas para Visual Studio"
NOTA: Al instalar lo anterior, asegúrese de seleccionar los siguientes componentes:
Desktop development with C++
# Then from the "Optional" category on the right, make sure to select the following:
MSVC C++ x64/x86 build tools
C++ CMake tools for Windows
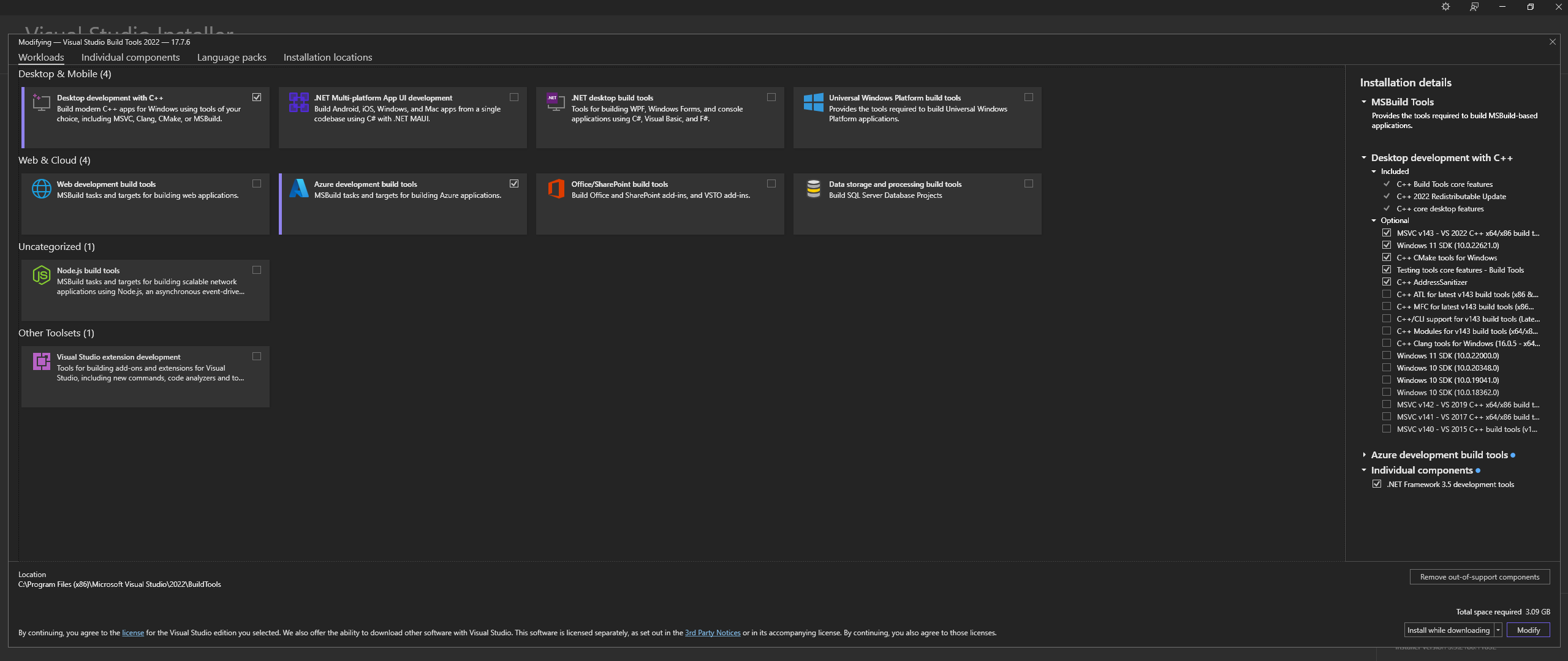
Desktop development with C++ y las opciones opcionales MSVC and C++ CMake estén seleccionadas como se describe arriba.En Linux (basado en Ubuntu y Debian), instale los siguientes paquetes:
sudo apt-get update
sudo apt-get install -y software-properties-common build-essential libffi-dev libssl-dev cmake
Descargar desde el repositorio oficial:
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
Instale CMAKE en Windows desde el sitio oficial
C:Program FilesCMakebinConstruya llama.cpp con CMAKE:
Nota: Para una compilación más rápida, agregue el argumento -j para ejecutar varios trabajos en paralelo. Por ejemplo, cmake --build build --config Release -j 8 ejecutará 8 trabajos en paralelo.
Construir con CUDA:
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES="52;61;70;75;80;86"
cmake --build build --config Release
cmake -B build
cmake --build build --config Release
Si tiene problemas al intentar ejecutar CMake -B build , consulte los pasos detallados para la solución de problemas de instalación de CMake a continuación
Agregar a RUTA:
path_to_cloned_repollama.cppbuildbinRelease
Verifique la instalación a través del terminal:
llama-server
Instalar controladores de GPU Nvidia
Instale Nvidia CUDA Toolkit: LARS creado y probado con v12.2 y v12.4
Verifique la instalación a través del terminal:
nvcc -V
nvidia-smi
Solución CMAKE-CUDA (¡Muy importante!):
Copie los cuatro archivos del siguiente directorio:
C:Program FilesNVIDIA GPU Computing ToolkitCUDAv12.2extrasvisual_studio_integrationMSBuildExtensions
y pégalos en el siguiente directorio:
C:Program Files (x86)Microsoft Visual Studio2022BuildToolsMSBuildMicrosoftVCv170BuildCustomizations
Esta es una dependencia opcional, pero muy recomendada: solo se admiten archivos PDF si no se completa esta configuración.
Ventanas:
Descargar desde el sitio oficial
Agregar a PATH, ya sea a través de:
Configuración avanzada del sistema -> Variables de entorno -> Variables del sistema -> EDITAR variable de RUTA -> Agregue lo siguiente (cambie según su ubicación de instalación):
C:Program FilesLibreOfficeprogram
O mediante PowerShell:
Set PATH=%PATH%;C:Program FilesLibreOfficeprogram
Ubuntu y Linux basado en Debian: descárguelo desde el sitio oficial o instálelo mediante la terminal:
sudo apt-get update
sudo apt-get install -y libreoffice
Fedora y otras distribuciones basadas en RPM: descargue desde el sitio oficial o instálelas mediante terminal:
sudo dnf update
sudo dnf install libreoffice
MacOS: descárguelo desde el sitio oficial o instálelo a través de Homebrew:
brew install --cask libreoffice
Verificar la instalación:
En Windows y MacOS: ejecute la aplicación LibreOffice
En Linux a través de la terminal:
libreoffice --version
LARS utiliza la biblioteca Python pdf2image para convertir cada página de un documento en una imagen según lo requiere OCR. Esta biblioteca es esencialmente un contenedor de la utilidad Poppler que maneja el proceso de conversión.
Ventanas:
Descargar desde el repositorio oficial
Agregar a PATH, ya sea a través de:
Configuración avanzada del sistema -> Variables de entorno -> Variables del sistema -> EDITAR variable de RUTA -> Agregue lo siguiente (cambie según su ubicación de instalación):
path_to_installationpoppler_versionLibrarybin
O mediante PowerShell:
Set PATH=%PATH%;path_to_installationpoppler_versionLibrarybin
Linux:
sudo apt-get update
sudo apt-get install -y poppler-utils wget
Esta es una dependencia opcional: Tesseract-OCR no se usa activamente en LARS, pero los métodos para usarlo están presentes en el código fuente.
Ventanas:
Descargue Tesseract-OCR para Windows a través de UB-Mannheim
Agregar a PATH, ya sea a través de:
Configuración avanzada del sistema -> Variables de entorno -> Variables del sistema -> EDITAR variable de RUTA -> Agregue lo siguiente (cambie según su ubicación de instalación):
C:Program FilesTesseract-OCR
O mediante PowerShell:
Set PATH=%PATH%;C:Program FilesTesseract-OCR
Volver a la tabla de contenidos
LARS ha sido construido y probado con Python v3.11.x
Instale Python v3.11.x en Windows:
Descargue v3.11.9 del sitio oficial
Durante la instalación, asegúrese de marcar "Agregar Python 3.11 a la RUTA" o agréguelo manualmente más tarde, ya sea a través de:
Configuración avanzada del sistema -> Variables de entorno -> Variables del sistema -> EDITAR variable de RUTA -> Agregue lo siguiente (cambie según su ubicación de instalación):
C:Usersuser_nameAppDataLocalProgramsPythonPython311
O mediante PowerShell:
Set PATH=%PATH%;C:Usersuser_nameAppDataLocalProgramsPythonPython311
Instale Python v3.11.x en Linux (basado en Ubuntu y Debian):
sudo add-apt-repository ppa:deadsnakes/ppa -y
sudo apt-get update
sudo apt-get install -y python3.11 python3.11-venv python3.11-dev
sudo python3.11 -m ensurepip
Verifique la instalación a través del terminal:
python3 --version
Si encuentra errores con pip install , intente lo siguiente:
Eliminar números de versión:
==version.number , por ejemplo:urllib3==2.0.4urllib3Cree y utilice un entorno virtual Python:
Es recomendable utilizar un entorno virtual para evitar conflictos con otros proyectos de Python.
Ventanas:
Cree un entorno virtual Python (venv):
python -m venv larsenv
Active y posteriormente utilice el venv:
.larsenvScriptsactivate
Desactive venv cuando haya terminado:
deactivate
Linux y MacOS:
Cree un entorno virtual Python (venv):
python3 -m venv larsenv
Active y posteriormente utilice el venv:
source larsenv/bin/activate
Desactive venv cuando haya terminado:
deactivate
Si los problemas persisten, considere abrir una incidencia en el repositorio LARS GitHub para obtener soporte.
CMake nmake failed al intentar compilar llama.cpp, como se muestra a continuación: 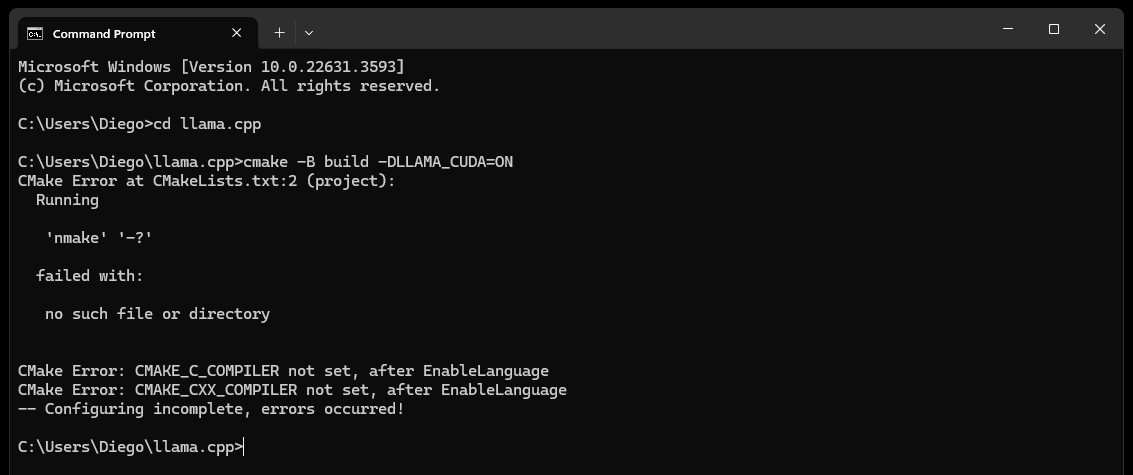
Normalmente, esto indica un problema con las herramientas de compilación de Microsoft Visual Studio, ya que CMake no puede encontrar la herramienta nmake, que forma parte de las herramientas de compilación de Microsoft Visual Studio. Pruebe los pasos a continuación para resolver el problema:
Asegúrese de que las herramientas de compilación de Visual Studio estén instaladas:
Asegúrese de tener instaladas las herramientas de compilación de Visual Studio, incluido nmake. Puede instalar estas herramientas a través del instalador de Visual Studio seleccionando la carga de trabajo Desktop development with C++ y las opciones opcionales de MSVC and C++ CMake
Verifique el Paso 0 de la sección Dependencias, específicamente la captura de pantalla que contiene
Verifique las variables de entorno:
C:Program Files (x86)Microsoft Visual Studio2019CommunityVCAuxiliaryBuild
C:Program Files (x86)Microsoft Visual Studio2019CommunityCommon7IDE
C:Program Files (x86)Microsoft Visual Studio2019CommunityCommon7Tools
Utilice el símbolo del sistema del desarrollador:
Abra un "Símbolo del sistema del desarrollador para Visual Studio" que configura las variables de entorno necesarias para usted
Puede encontrar este mensaje en el menú Inicio en Visual Studio
Configurar el generador CMake:
cmake -G "NMake Makefiles" -B build -DLLAMA_CUDA=ON
Si los problemas persisten, considere abrir una incidencia en el repositorio LARS GitHub para obtener soporte.
Finalmente (después de aproximadamente 60 segundos) verá una alerta en la página que indica un error:
Failed to start llama.cpp local-server
Esto indica que se completó la primera ejecución, se crearon todos los directorios de aplicaciones, pero no hay LLM presentes en el directorio models y ahora se pueden mover a él.
Mueva sus LLM (cualquier formato de archivo compatible con llama.cpp, preferiblemente GGUF) al directorio models recién creado, ubicado de forma predeterminada en las siguientes ubicaciones:
C:/web_app_storage/models/app/storage/models/app/models Una vez que haya colocado sus LLM en el directorio de models apropiado arriba, actualice http://localhost:5000/
Una vez más recibirás una alerta de error que indica Failed to start llama.cpp local-server después de aproximadamente 60 segundos.
Esto se debe a que ahora es necesario seleccionar su LLM en el menú Settings de LARS.
Acepte la alerta y haga clic en el ícono de ajustes Settings en la esquina superior derecha.
En la pestaña LLM Selection , seleccione su LLM y el formato de plantilla de solicitud apropiado en los menús desplegables correspondientes.
Modifique la configuración avanzada para configurar correctamente las opciones GPU , la Context-Length y, opcionalmente, el límite de generación de tokens ( Maximum tokens to predict ) para su LLM seleccionado.
Presione Save y si no se activa una actualización automática, actualice manualmente la página
Si todos los pasos se han ejecutado correctamente, la configuración inicial ya está completa y LARS está listo para usar.
LARS también recordará su configuración de LLM para su uso posterior
Volver a la tabla de contenidos
Formatos de documentos admitidos:
Si LibreOffice está instalado y agregado a PATH como se detalla en el Paso 4 de la sección Dependencias, se admiten los siguientes formatos:
Si LibreOffice no está configurado, solo se admiten archivos PDF
Opciones de OCR para extracción de texto:
LARS proporciona tres métodos para extraer texto de documentos, acomodando varios tipos y calidades de documentos:
Extracción de texto local: utiliza PyPDF2 para una extracción de texto eficiente de archivos PDF no escaneados. Ideal para procesamiento rápido cuando la alta precisión no es crítica o cuando es necesario un procesamiento completamente local.
Azure ComputerVision OCR: mejora la precisión de la extracción de texto y admite documentos escaneados. Útil para manejar diseños de documentos estándar. Ofrece un nivel gratuito adecuado para pruebas iniciales y uso de bajo volumen, con un límite de 5000 transacciones/mes a 20 transacciones/minuto.
OCR de inteligencia de documentos de Azure AI: ideal para documentos con estructuras complejas, como tablas. Un analizador personalizado en LARS optimiza el proceso de extracción.
NOTAS:
Las opciones de Azure OCR generan costos de API en la mayoría de los casos y no están incluidas con LARS.
Un nivel gratuito limitado para ComputerVision OCR está disponible como se encuentra en el enlace anterior. Este servicio es más económico en general, pero más lento y es posible que no funcione con diseños de documentos no estándar (que no sean A4, etc.).
Considere los tipos de documentos y sus necesidades de precisión al seleccionar una opción de OCR.
LLM:
Actualmente, solo se admiten LLM locales
El menú Settings proporciona muchas opciones para que el usuario avanzado configure y cambie el LLM a través de la pestaña LLM Selection
Nota si usa llama.cpp: Muy importante: seleccione el formato de plantilla de solicitud apropiado para el LLM que está ejecutando
Los LLM capacitados para los siguientes formatos de plantillas de mensajes actualmente son compatibles a través de llama.cpp:
Modifique la configuración del núcleo a través de Advanced Settings (activa la recarga de LLM y la actualización de página):
Modifique la configuración para cambiar el comportamiento de respuesta en cualquier momento:
Incrustación de modelos y base de datos de vectores:
En LARS se proporcionan cuatro modelos de incrustación:
Con la excepción de las incorporaciones de Azure-OpenAI, todos los demás modelos se ejecutan de forma totalmente local y gratuita. En la primera ejecución, estos modelos se descargarán desde HuggingFace Hub. Esta es una descarga única y posteriormente estarán presentes localmente.
El usuario puede cambiar entre estos modelos de incrustación en cualquier momento a través de la pestaña VectorDB & Embedding Models en el menú Settings .
Tabla cargada de documentos: en el menú Settings , se muestra una tabla para el modelo de incrustación seleccionado que muestra la lista de documentos incrustados en la base de datos vectorial asociada. Si un documento se carga varias veces, tendrá varias entradas en esta tabla, lo que podría resultar útil para depurar cualquier problema.
Borrar VectorDB: use el botón Reset y proporcione confirmación para borrar la base de datos de vectores seleccionada. Esto crea un nuevo vectorDB en el disco para el modelo de incrustación seleccionado. El antiguo vectorDB aún se conserva y se puede volver a él modificando manualmente el archivo config.json.
Editar mensaje del sistema:
El mensaje del sistema sirve como instrucción para el LLM durante toda la conversación.
LARS proporciona al usuario la posibilidad de editar el mensaje del sistema a través del menú Settings seleccionando la opción Custom en el menú desplegable de la pestaña System Prompt .
Los cambios en el mensaje del sistema iniciarán un nuevo chat
Forzar habilitar/deshabilitar RAG:
A través del menú Settings , el usuario puede forzar la activación o desactivación de RAG (Generación aumentada de recuperación: el uso del contenido de sus documentos para mejorar las respuestas generadas por LLM) cuando sea necesario.
Esto suele ser útil para evaluar las respuestas de LLM en ambos escenarios.
La desactivación forzada también desactivará las funciones de atribución.
La configuración predeterminada, que utiliza PNL para determinar cuándo se debe y cuándo no se debe realizar RAG, es la opción recomendada.
Esta configuración se puede cambiar en cualquier momento.
Historial de chat:
Utilice el menú del historial de chat en la parte superior izquierda para explorar y reanudar conversaciones anteriores.
Muy importante: tenga en cuenta las discrepancias entre las plantillas de mensajes al reanudar conversaciones anteriores. Utilice el ícono Information en la parte superior derecha para asegurarse de que el LLM utilizado en la conversación anterior y el LLM actualmente en uso se basen en los mismos formatos de plantilla de solicitud.
Calificación del usuario:
Cada respuesta puede ser calificada en una escala de 5 puntos por el usuario en cualquier momento.
Los datos de calificaciones se almacenan en la base de datos SQLite3 chat-history.db ubicada en el directorio de la aplicación:
C:/web_app_storage/app/storage/appLos datos de calificaciones son muy valiosos para la evaluación y el refinamiento de la herramienta para sus flujos de trabajo.
Lo que se debe y no se debe hacer:
Volver a la tabla de contenidos
Si un chat sale mal o se generan respuestas extrañas, simplemente intente iniciar un New Chat a través del menú en la parte superior izquierda.
Alternativamente, inicie un nuevo chat simplemente actualizando la página.
Si tiene problemas con las citas o el rendimiento de RAG, intente restablecer vectorDB como se describe en el Paso 4 de la Guía general del usuario anterior.
Si surge algún problema con la aplicación y no se resuelve simplemente iniciando un nuevo chat o reiniciando LARS, intente eliminar el archivo config.json siguiendo los pasos a continuación:
CTRL+Cconfig.json ubicado en LARS/web_app (el mismo directorio que app.py )Para cualquier problema grave de datos y citas que no se resuelva incluso restableciendo VectorDB como se describe en el Paso 4 de la Guía general del usuario anterior, realice los siguientes pasos:
CTRL+CC:/web_app_storage/app/storage/appSi los problemas persisten, considere abrir una incidencia en el repositorio LARS GitHub para obtener soporte.
Volver a la tabla de contenidos
LARS se ha adaptado a un entorno de implementación de contenedores Docker a través de dos imágenes separadas como se muestra a continuación:
Ambos tienen requisitos diferentes: el primero es una implementación más simple, pero sufre un rendimiento de inferencia mucho más lento debido a que la CPU y la memoria DDR actúan como cuellos de botella.
Si bien no es un requisito explícito, algo de experiencia con contenedores Docker y familiaridad con los conceptos de contenedorización y virtualización serán muy útiles en esta sección.
Comenzando con pasos de configuración comunes para ambos:
Instalación de ventana acoplable
Su CPU debe admitir la virtualización y debe estar habilitada en el BIOS/UEFI de su sistema.
Descargue e instale Docker Desktop
Si está en Windows, es posible que necesite instalar el Subsistema de Windows para Linux si aún no está presente. Para hacerlo, abra PowerShell como administrador y ejecute lo siguiente:
wsl --install
Asegúrese de que Docker Desktop esté en funcionamiento, luego abra un símbolo del sistema/terminal y ejecute el siguiente comando para asegurarse de que Docker esté instalado y en funcionamiento correctamente:
docker ps
Cree un volumen de almacenamiento Docker, que se adjuntará a los contenedores LARS en tiempo de ejecución:
Crear un volumen de almacenamiento para usar con el contenedor LARS es muy ventajoso ya que le permitirá actualizar el contenedor LARS a una versión más nueva o cambiar entre las variantes del contenedor CPU y GPU mientras conserva todas sus configuraciones, historial de chat y bases de datos vectoriales sin problemas. .
Ejecute el siguiente comando en un símbolo del sistema/terminal:
docker volume create lars_storage_volue
Este volumen se adjuntará al contenedor LARS más adelante durante el tiempo de ejecución; por ahora, proceda a crear la imagen LARS siguiendo los pasos a continuación.
En un símbolo del sistema/terminal, ejecute los siguientes comandos:
git clone https://github.com/abgulati/LARS # skip if already done
cd LARS # skip if already done
cd dockerized
docker build -t lars-no-gpu .
# Once the build is complete, run the container:
docker run -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-no-gpu
Una vez hecho esto, navegue hasta http://localhost:5000/ en su navegador y siga el resto de los pasos de la primera ejecución y la guía del usuario.
Las secciones de Solución de problemas también se aplican a Container-LARS.
Requisitos (además de Docker):
Compatible Nvidia GPU(s)
Nvidia GPU drivers
Nvidia CUDA Toolkit v12.2
Para Linux, ya está todo configurado con lo anterior, así que omita el siguiente paso y diríjase directamente a los pasos de compilación y ejecución que se encuentran más abajo.
Si está en Windows, y si es la primera vez que ejecuta un contenedor de GPU Nvidia en Docker, abróchese el cinturón, ya que será todo un viaje (¡su bebida favorita o tres muy recomendables!)
Arriesgándose a una redundancia extrema, antes de continuar, asegúrese de que estén presentes las siguientes dependencias:
Compatible Nvidia GPU(s)
Nvidia GPU drivers
Nvidia CUDA Toolkit v12.2
Docker Desktop
Windows Subsystem for Linux (WSL)
Consulte la sección Dependencias de Nvidia CUDA y la sección Configuración de Docker anterior si no está seguro.
Si lo anterior está presente y configurado, puede continuar
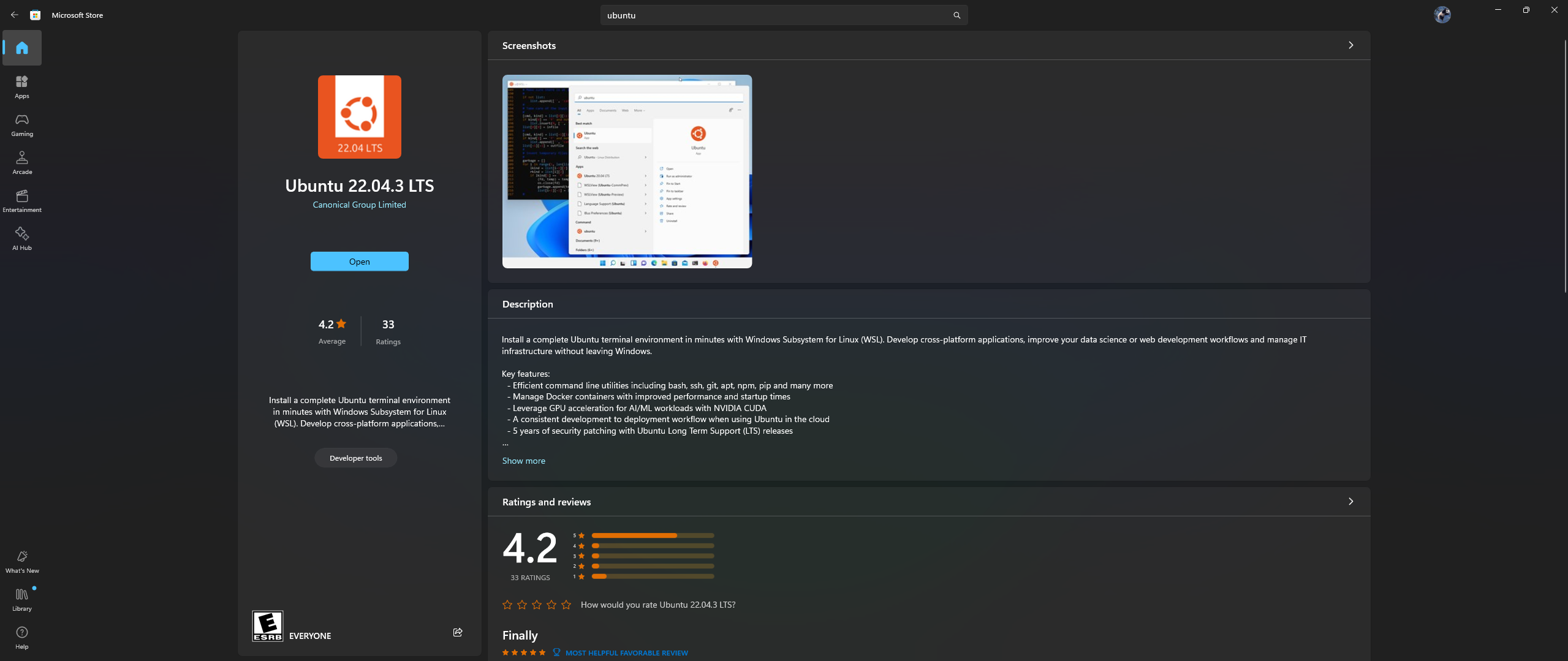
Abra la aplicación Microsoft Store en su PC y descargue e instale Ubuntu 22.04.3 LTS (debe coincidir con la versión en la línea 2 del archivo acoplable)
Sí, leíste bien lo anterior: descarga e instala Ubuntu desde la aplicación de la tienda de Microsoft, consulta la captura de pantalla a continuación:
Ahora es el momento de instalar Nvidia Container Toolkit en Ubuntu, siga los pasos a continuación para hacerlo:
Inicie un shell de Ubuntu en Windows buscando Ubuntu en el menú Inicio una vez completada la instalación anterior.
En esta línea de comandos de Ubuntu que se abre, realice los siguientes pasos:
Configurar el repositorio de producción:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list |
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' |
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
Actualice la lista de paquetes desde el repositorio e instale los paquetes de Nvidia Container Toolkit:
sudo apt-get update && apt-get install -y nvidia-container-toolkit
Configure el tiempo de ejecución del contenedor usando el comando nvidia-ctk, que modifica el archivo /etc/docker/daemon.json para que Docker pueda usar el tiempo de ejecución del contenedor Nvidia:
sudo nvidia-ctk runtime configure --runtime=docker
Reinicie el demonio Docker:
sudo systemctl restart docker
Ahora que su configuración de Ubuntu está completa, es hora de completar las integraciones de WSL y Docker:
Abra una nueva ventana de PowerShell y configure esta instalación de Ubuntu como WSL predeterminada:
wsl --list
wsl --set-default Ubuntu-22.04 # if not already marked as Default
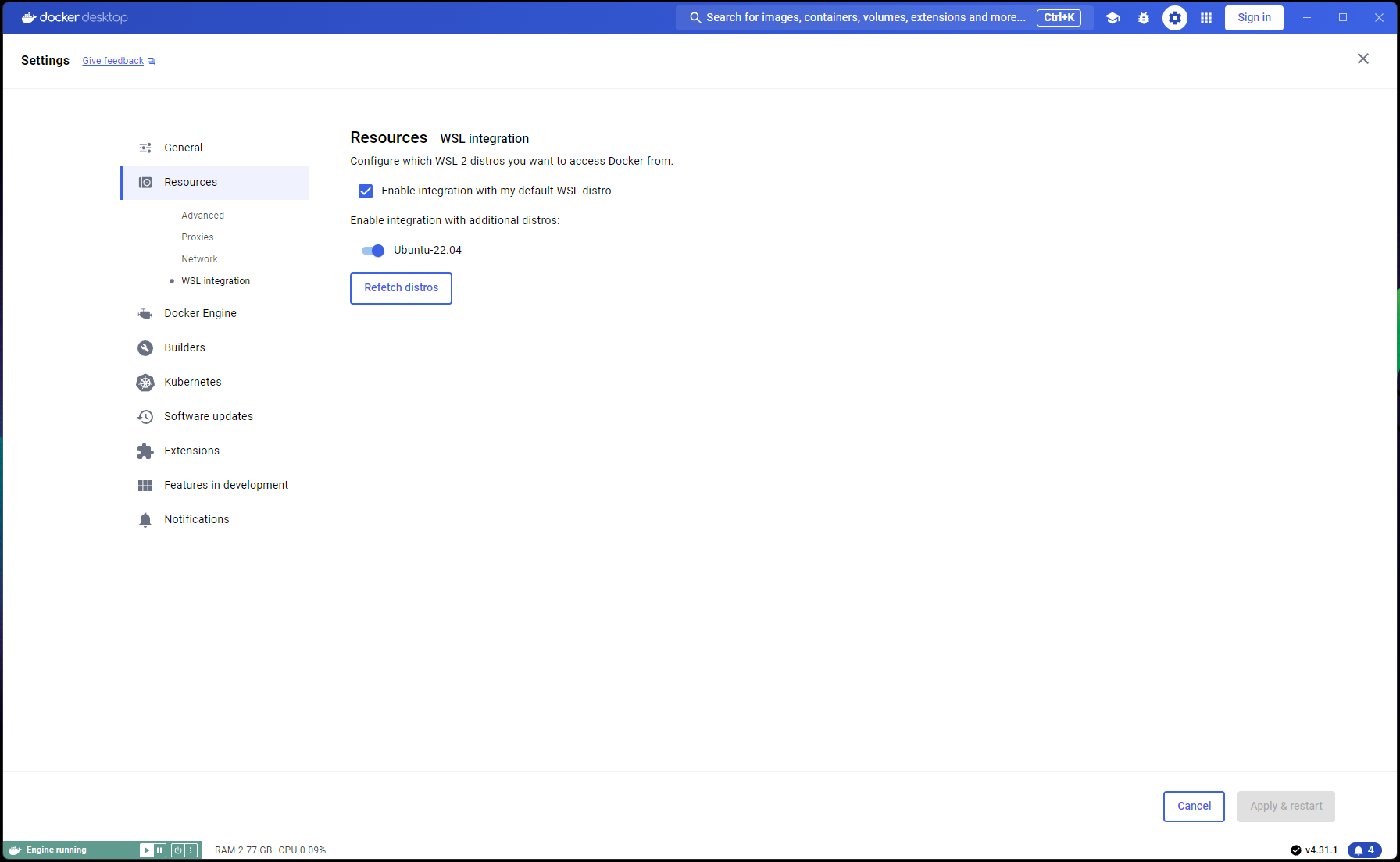
Navegue a Docker Desktop -> Settings -> Resources -> WSL Integration -> Verifique las integraciones predeterminadas y Ubuntu 22.04. Consulte la captura de pantalla a continuación:
Ahora, si todo se ha hecho correctamente, ¡está listo para construir y ejecutar el contenedor!
En un símbolo del sistema/terminal, ejecute los siguientes comandos:
git clone https://github.com/abgulati/LARS # skip if already done
cd LARS # skip if already done
cd dockerized_nvidia_cuda_gpu
docker build -t lars-nvcuda .
# Once the build is complete, run the container:
docker run --gpus all -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-nvcuda
Una vez hecho esto, navegue hasta http://localhost:5000/ en su navegador y siga el resto de los pasos de la primera ejecución y la guía del usuario.
Las secciones de Solución de problemas también se aplican a Container-LARS.
En caso de que encuentre errores relacionados con la red, especialmente relacionados con repositorios de paquetes no disponibles al crear el contenedor, este es un problema de red de su parte que a menudo está relacionado con problemas de firewall.
En Windows, navegue hasta Control PanelSystem and SecurityWindows Defender FirewallAllowed apps , o busque Firewall en el menú Inicio y diríjase a Allow an app through the firewall y asegúrese de que ```Docker Desktop Backend`` esté permitido.
La primera vez que ejecute LARS, se descargará el modelo de incrustación de transformadores de oraciones.
En el entorno en contenedores, esta descarga a veces puede ser problemática y generar errores al realizar una consulta.
Si esto ocurre, simplemente diríjase al menú de configuración de LARS: Settings->VectorDB & Embedding Models y cambie el modelo de incrustación a BGE-Base o BGE-Large, esto forzará una recarga y una nueva descarga.
Una vez hecho esto, proceda a hacer preguntas nuevamente y la respuesta debería generarse normalmente.
Puede volver al modelo de incrustación de transformadores de oraciones y el problema debería resolverse
Como se indicó en la sección Solución de problemas anterior, los modelos integrados se descargan la primera vez que se ejecuta LARS.
Es mejor guardar el estado del contenedor antes de cerrarlo para que no sea necesario repetir este paso de descarga cada vez que se inicie el contenedor.
Para hacerlo, abra otro símbolo del sistema/terminal y confirme los cambios ANTES de cerrar el contenedor LARS en ejecución:
docker ps # note the container_id here
docker commit <container_ID> <new_image_name> # for new_image_name, I simply add 'pfr', for 'post-first-run' to the current image name, example: lars-nvcuda-pfr
Esto creará una imagen actualizada que podrá usar en ejecuciones posteriores:
docker run --gpus all -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-nvcuda-pfr
NOTA: Habiendo hecho lo anterior, si verifica el espacio utilizado por las imágenes con docker images , notará que se utiliza mucho espacio. PERO, ¡no tomes las tallas aquí literalmente! El tamaño que se muestra para cada imagen incluye el tamaño total de todas sus capas, pero muchas de esas capas se comparten entre imágenes, especialmente si esas imágenes se basan en la misma imagen base o si una imagen es una versión comprometida de otra. Para ver cuánto espacio en disco están usando realmente sus imágenes de Docker, use:
docker system df
Volver a la tabla de contenidos
| Categoría | Tareas | Estado |
|---|---|---|
| Corrección de errores: | Peligro de creación de archivos de texto de cero bytes: a veces, si falla el OCR/extracción de texto del documento de entrada, es posible que quede un archivo .txt 0B, lo que provoca que más intentos vuelvan a creer que el archivo ya se ha cargado. | ? Tarea futura |
| Características prácticas: | Centrado en la facilidad de uso: | |
| Alternancia de interfaz de usuario de nivel gratuito de Azure CV-OCR | ✅ Hecho el 8 de junio de 2024 | |
| Eliminar chats | ? Tarea futura | |
| Cambiar el nombre de los chats | ? Tarea futura | |
| Script de instalación de PowerShell | ? Tarea futura | |
| Script de instalación de Linux | ? Tarea futura | |
| Backend de inferencia de Ollama LLM como alternativa a llama.cpp | ? Tarea futura | |
| Integración de servicios OCR de otros proveedores de la nube (GCP, AWS, OCI, etc.) | ? Tarea futura | |
| Alternancia de la interfaz de usuario para ignorar extractos de texto anteriores al cargar un documento | ? Tarea futura | |
| Ventana emergente modal para carga de archivos: reflejar las opciones de extracción de texto de la configuración, sobrescritura global en los envíos, alternar para conservar la configuración | ? Tarea futura | |
| Centrado en el rendimiento: | ||
| Compatibilidad con Nvidia TensorRT-LLM AWQ | ? Tarea futura | |
| Tareas de investigación: | Investigue Nvidia TensorRT-LLM: requiere construir motores TRT AWQ-LLM específicos para la GPU de destino, NvTensorRT-LLM es su propio ecosistema y solo funciona en Python v3.10. | ✅ Hecho el 13 de junio de 2024 |
| OCR local con Vision LLM: MS-TrOCR (hecho), Kosmos-2.5 (alta prioridad), Llava, Florence-2 | ? Actualización en curso del 5 de julio de 2024 | |
| Mejoras de RAG: Re-ranker, RAPTOR, T-RAG | ? Tarea futura | |
| Investigar la integración de GraphDB: uso de LLM para extraer datos de relaciones entre entidades de documentos y completar, actualizar y mantener un GraphDB | ? Tarea futura |
Volver a la tabla de contenidos
Espero que LARS haya sido valioso en tu trabajo y te invito a apoyar su continuo desarrollo. Si aprecia la herramienta y le gustaría contribuir a sus mejoras futuras, considere hacer una donación. Su apoyo me ayuda a seguir mejorando LARS y agregando nuevas funciones.
Cómo donar Para hacer una donación, utilice el siguiente enlace a mi PayPal:
Donar a través de PayPal
Sus contribuciones son muy apreciadas y se utilizarán para financiar futuros esfuerzos de desarrollo.
Volver a la tabla de contenidos


