BLIVA
1.0.0
Wenbo Hu*, Yifan Xu*, Yi Li, Weiyue Li, Zeyuan Chen y Zhuowen Tu. *Igual contribución
Universidad de California en San Diego , Coinbase Global, Inc.
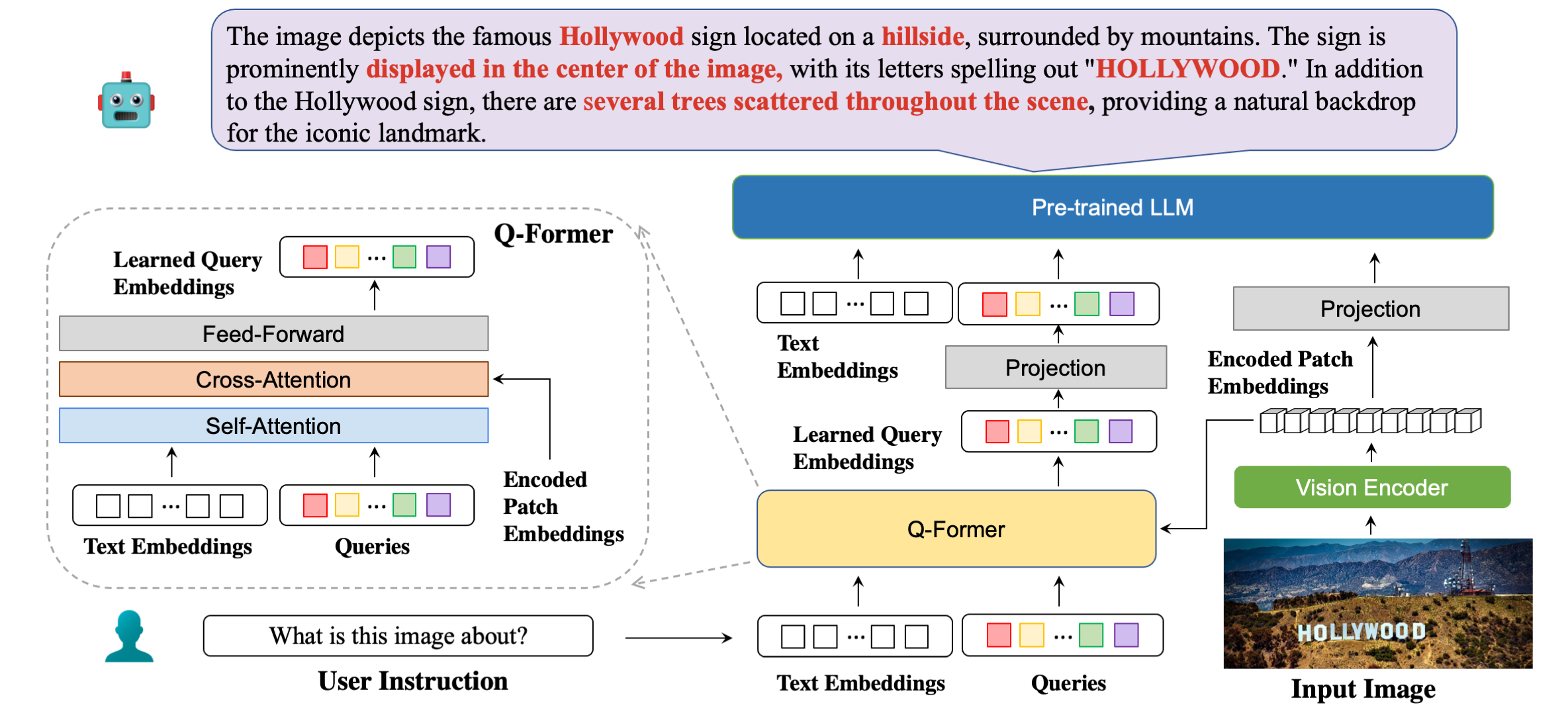
Nuestra arquitectura modelo en detalle con respuestas de ejemplo.
| Método | STVQA | OCRVQA | TextoVQA | DocVQA | InfoVQA | GráficoQA | ESTVQA | FUNSD | SROIE | POIE | Promedio |
|---|---|---|---|---|---|---|---|---|---|---|---|
| AbiertoFlamingo | 19.32 | 27,82 | 29.08 | 5.05 | 14,99 | 9.12 | 28.20 | 0,85 | 0,12 | 2.12 | 13.67 |
| BLIP2-OPT | 13.36 | 10.58 | 21.18 | 0,82 | 8.82 | 7.44 | 27.02 | 0.00 | 0.00 | 0,02 | 8.92 |
| BLIP2-FLanT5XXL | 21.38 | 30.28 | 30,62 | 4.00 | 10.17 | 7.20 | 42,46 | 1.19 | 0,20 | 2.52 | 15.00 |
| MiniGPT4 | 14.02 | 11.52 | 18,72 | 2,97 | 13.32 | 4.32 | 28.36 | 1.19 | 0,04 | 1.31 | 9.58 |
| LLaVA | 22,93 | 15.02 | 28.30 | 4.40 | 13,78 | 7.28 | 33,48 | 1.02 | 0,12 | 2.09 | 12,84 |
| mPLUG-búho | 26.32 | 35.00 | 37,44 | 6.17 | 16.46 | 9.52 | 49,68 | 1.02 | 0,64 | 3.26 | 18.56 |
| InstruccionesBLIP (FLANT5XXL) | 26.22 | 55.04 | 36,86 | 4.94 | 10.14 | 8.16 | 43,84 | 1.36 | 0,50 | 1.91 | 18,90 |
| InstructBLIP (Vicuña-7B) | 28,64 | 47,62 | 39,60 | 5,89 | 13.10 | 5.52 | 47,66 | 0,85 | 0,64 | 2.66 | 19.22 |
| BLIVA (FLANT5XXL) | 28.24 | 61,34 | 39.36 | 5.22 | 10,82 | 9.28 | 45,66 | 1,53 | 0,50 | 2.39 | 20.43 |
| BLIVA (Vicuña-7B) | 29.08 | 65,38 | 42.18 | 6.24 | 13.50 | 8.16 | 48.14 | 1.02 | 0,88 | 2.91 | 21,75 |
| Método | VSR | IconoQA | TextoVQA | Visdial | Flickr30K | HM | VizWiz | MSRVTT |
|---|---|---|---|---|---|---|---|---|
| Flamenco-3B | - | - | 30.1 | - | 60,6 | - | - | - |
| Flamenco-9B | - | - | 31,8 | - | 61,5 | - | - | - |
| Flamenco-80B | - | - | 35.0 | - | 67,2 | - | - | - |
| MiniGPT-4 | 50,65 | - | 18.56 | - | - | 29.0 | 34,78 | - |
| LLaVA | 56.3 | - | 37,98 | - | - | 9.2 | 36,74 | - |
| BLIP-2 (Vicuña-7B) | 50.0 | 39,7 | 40.1 | 44,9 | 74,9 | 50.2 | 49,34 | 4.17 |
| InstructBLIP (Vicuña-7B) | 54.3 | 43.1 | 50.1 | 45.2 | 82,4 | 54,8 | 43.3 | 18.7 |
| BLIVA (Vicuña-7B) | 62.2 | 44,88 | 57,96 | 45,63 | 87.1 | 55,6 | 42,9 | 23,81 |
conda create -n bliva python=3.9
conda activate blivagit clone https://github.com/mlpc-ucsd/BLIVA
cd BLIVA
pip install -e . BLIVA Vicuña 7B
Nuestro modelo versión Vicuña se publica aquí. Descargue el peso de nuestro modelo y especifique la ruta en la configuración del modelo aquí en la línea 8.
El LLM que utilizamos es la versión v0.1 de Vicuña-7B. Para preparar el peso de Vicuña, consulte nuestras instrucciones aquí. Luego, establezca la ruta al peso de la vicuña en el archivo de configuración del modelo aquí en la Línea 21.
BLIVA FlanT5 XXL (Disponible para uso comercial)
El modelo de versión FlanT5 se publica aquí. Descargue el peso de nuestro modelo y especifique la ruta en la configuración del modelo aquí en la línea 8.
El peso LLM para Flant5 comenzará a descargarse automáticamente desde huggingface cuando ejecute nuestro código de inferencia.
Para responder una pregunta de la imagen, ejecute el siguiente código de evaluación. Por ejemplo,
python evaluate.py --answer_qs
--model_name bliva_vicuna
--img_path images/example.jpg
--question " what is this image about? "También admitimos responder preguntas de opción múltiple, que es la misma que utilizamos para las tareas de evaluación en papel. Para proporcionar una lista de opciones, debe ser una cadena dividida por comas. Por ejemplo,
python evaluate.py --answer_mc
--model_name bliva_vicuna
--img_path images/mi6.png
--question " Which genre does this image belong to? "
--candidates " play, tv show, movie " Nuestra demostración está disponible públicamente aquí. Para ejecutar nuestra demostración localmente en su máquina. Correr:
python demo.pyDespués de descargar los conjuntos de datos de entrenamiento y especificar su ruta en las configuraciones del conjunto de datos, estamos listos para el entrenamiento. Utilizamos 8x A6000 Ada en nuestros experimentos. Ajuste los hiperparámetros de acuerdo con los recursos de su GPU. Los transformadores pueden tardar alrededor de 2 minutos en cargar el modelo, déle algo de tiempo para que el modelo comience a entrenar. Aquí damos un ejemplo de entrenamiento de la versión BLIVA Vicuña, la versión Flant5 sigue el mismo formato.
torchrun --nnodes=1 --nproc_per_node=8
train.py
--cfg-path train_configs/pretrain_bliva_vicuna.yamltorchrun --nnodes=1 --nproc_per_node=8
train.py
--cfg-path train_configs/finetune_bliva_vicuna.yamlO también apoyamos el entrenamiento de Vicuna7b junto con BLIVA usando LoRA durante el segundo paso; de forma predeterminada, no usamos esta versión.
torchrun --nnodes=1 --nproc_per_node=8
train.py
--cfg-path train_configs/finetune_bliva_and_vicuna.yamlSi encuentra que BLIVA es útil para su investigación y aplicaciones, cítelo utilizando este BibTeX:
@misc { hu2023bliva ,
title = { BLIVA: A Simple Multimodal LLM for Better Handling of Text-Rich Visual Questions } ,
author = { Wenbo Hu and Yifan Xu and Yi Li and Weiyue Li and Zeyuan Chen and Zhuowen Tu } ,
publisher = { arXiv:2308.09936 } ,
year = { 2023 } ,
}El código de este repositorio está bajo la licencia BSD de 3 cláusulas. Muchos códigos se basan en Lavis con licencia BSD de 3 cláusulas aquí.
Para los parámetros de nuestro modelo de la versión BLIVA Vicuña, se debe utilizar bajo la licencia de modelo de LLaMA. Para el peso del modelo BLIVA FlanT5, está bajo la licencia Apache 2.0. Para nuestros datos YTTB-VQA, están bajo CC BY NC 4.0


