cambrian
1.0.0
Dato curioso: ¡la visión surgió en los animales durante el período Cámbrico! Esta fue la inspiración para el nombre de nuestro proyecto, Cambrian.
eval/ para obtener más detalles.dataengine/ para obtener más detalles.Actualmente, apoyamos la capacitación en TPU usando TorchXLA
git clone https://github.com/cambrian-mllm/cambrian
cd cambrianconda create -n cambrian python=3.10 -y
conda activate cambrian
pip install --upgrade pip # enable PEP 660 support
pip install -e " .[tpu] " pip install torch~=2.2.0 torch_xla[tpu]~=2.2.0 -f https://storage.googleapis.com/libtpu-releases/index.html
git clone https://github.com/cambrian-mllm/cambrian
cd cambrianconda create -n cambrian python=3.10 -y
conda activate cambrian
pip install --upgrade pip # enable PEP 660 support
pip install " .[gpu] " Aquí están nuestros puntos de control del Cámbrico junto con instrucciones sobre cómo usar las pesas. Nuestros modelos destacan en varias dimensiones, en los niveles de parámetros 8B, 13B y 34B. Demuestran un rendimiento competitivo en comparación con modelos propietarios de código cerrado como GPT-4V, Gemini-Pro y Grok-1.4V en varios puntos de referencia.
| Modelo | #Vis. Tok. | MMB | SQA-I | MatemáticasVistaM | GráficoQA | MMVP |
|---|---|---|---|---|---|---|
| GPT-4V | Desconocido | 75,8 | - | 49,9 | 78,5 | 50.0 |
| Géminis-1.0 Pro | Desconocido | 73,6 | - | 45.2 | - | - |
| Géminis-1.5 Pro | Desconocido | - | - | 52.1 | 81.3 | - |
| Grok-1.5 | Desconocido | - | - | 52,8 | 76.1 | - |
| MM-1-8B | 144 | 72.3 | 72,6 | 35,9 | - | - |
| MM-1-30B | 144 | 75.1 | 81.0 | 39,4 | - | - |
| LLM básico: Phi-3-3.8B | ||||||
| Cámbrico-1-8B | 576 | 74,6 | 79,2 | 48.4 | 66,8 | 40.0 |
| LLM base: LLaMA3-8B-Instrucción | ||||||
| Mini-Géminis-HD-8B | 2880 | 72,7 | 75.1 | 37.0 | 59.1 | 18.7 |
| LLaVA-NeXT-8B | 2880 | 72.1 | 72,8 | 36.3 | 69,5 | 38,7 |
| Cámbrico-1-8B | 576 | 75,9 | 80,4 | 49.0 | 73.3 | 51.3 |
| LLM base: Vicuña1.5-13B | ||||||
| Mini-Géminis-HD-13B | 2880 | 68,6 | 71,9 | 37.0 | 56,6 | 19.3 |
| LLaVA-NeXT-13B | 2880 | 70.0 | 73,5 | 35.1 | 62.2 | 36.0 |
| Cámbrico-1-13B | 576 | 75,7 | 79,3 | 48.0 | 73,8 | 41.3 |
| LLM básico: Hermes2-Yi-34B | ||||||
| Mini-Gemini-HD-34B | 2880 | 80,6 | 77,7 | 43.4 | 67,6 | 37.3 |
| LLaVA-NeXT-34B | 2880 | 79,3 | 81,8 | 46,5 | 68,7 | 47.3 |
| Cámbrico-1-34B | 576 | 81,4 | 85,6 | 53.2 | 75,6 | 52,7 |
Para ver la tabla completa, consulte nuestro artículo Cambrian-1.
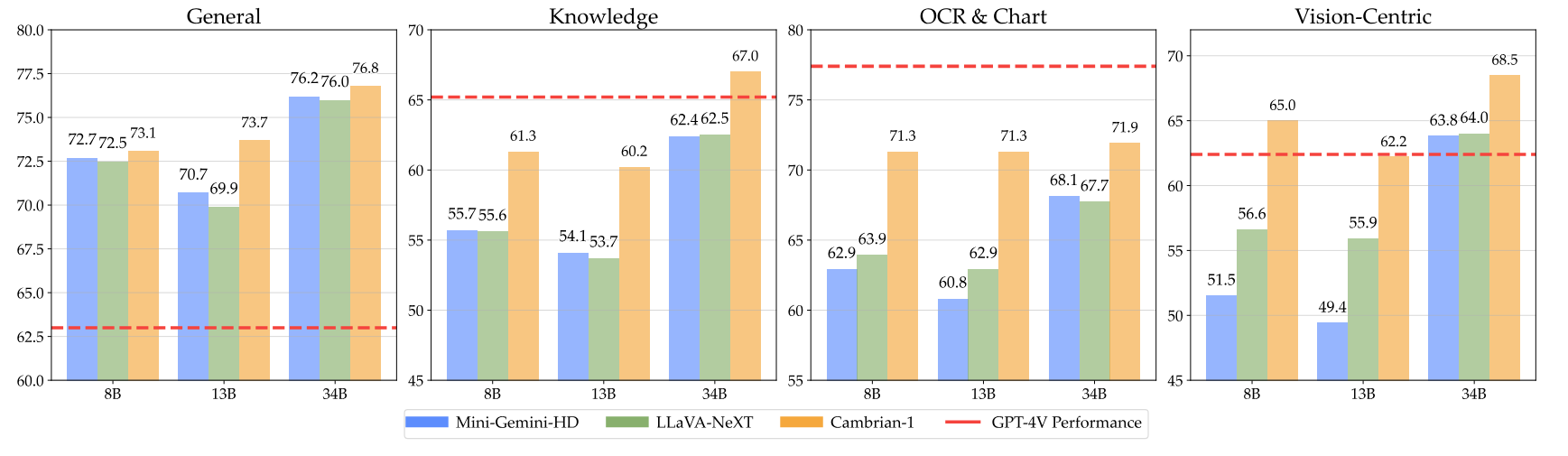
Nuestros modelos ofrecen un rendimiento altamente competitivo y utilizan una cantidad fija más pequeña de tokens visuales.
Para utilizar los pesos del modelo, descárguelos de Hugging Face:
Proporcionamos un script de muestra de carga y generación de modelos en inference.py .

En este trabajo, recopilamos un conjunto muy grande de datos de ajuste de instrucciones, Cambrian-10M, para nosotros y el trabajo futuro para estudiar datos en el entrenamiento de MLLM. En nuestro estudio preliminar, filtramos los datos a un conjunto de alta calidad de 7 millones de puntos de datos seleccionados, al que llamamos Cambrian-7M. Ambos conjuntos de datos están disponibles en el siguiente conjunto de datos de Hugging Face: Cambrian-10M.
Recopilamos una amplia gama de datos de ajuste de instrucción visual de diversas fuentes, incluido VQA, conversación visual e interacción visual incorporada. Para garantizar datos de conocimiento de alta calidad, confiables y a gran escala, diseñamos un motor de datos de Internet.
Además, observamos que los datos VQA tienden a generar resultados muy cortos, lo que crea un cambio en la distribución de los datos de entrenamiento. Para abordar este problema, aprovechamos GPT-4v y GPT-4o para crear respuestas extendidas y datos más creativos.
Para resolver la insuficiencia de los datos relacionados con la ciencia, diseñamos un motor de datos de Internet para recopilar datos VQA confiables relacionados con la ciencia. Este motor se puede aplicar para recopilar datos sobre cualquier tema. Utilizando este motor, recopilamos 161.000 puntos de datos adicionales de ajuste de instrucciones visuales relacionados con la ciencia, ¡lo que aumentó los datos totales en este dominio en un 400%! Si desea utilizar esta parte de los datos, utilice este jsonl.
Usamos GPT-4v para crear 77k puntos de datos adicionales. Estos datos utilizan GPT-4v para reescribir el VQA original de solo respuesta en respuestas más largas con respuestas más detalladas o generan datos de ajuste de instrucciones visuales basados en la imagen proporcionada. Si desea utilizar esta parte de los datos, utilice este jsonl.
Usamos GPT-4o para crear 60.000 puntos de datos creativos adicionales. Estos datos alientan al modelo a generar respuestas muy largas y, a menudo, contienen preguntas muy creativas, como escribir un poema, componer una canción y más. Si desea utilizar esta parte de los datos, utilice este jsonl.
Realizamos un estudio inicial sobre curación de datos mediante:
Empíricamente, encontramos que el escenario
| Categoría | Proporción de datos |
|---|---|
| Idioma | 21,00% |
| General | 34,52% |
| LOC | 27,22% |
| Cálculo | 8,71% |
| Matemáticas | 7,20% |
| Código | 0,87% |
| Ciencia | 0,88% |
En comparación con el modelo LLaVA-665K anterior, la ampliación y la curación de datos mejorada mejoran significativamente el rendimiento del modelo, como se muestra en la siguiente tabla:
| Modelo | Promedio | Conocimiento general | LOC | Cuadro | Centrado en la visión |
|---|---|---|---|---|---|
| LLaVA-665K | 40.4 | 64,7 | 45.2 | 20.8 | 31.0 |
| Cámbrico-10M | 53,8 | 68,7 | 51,6 | 47.1 | 47,6 |
| Cámbrico-7M | 54,8 | 69,6 | 52,6 | 47.3 | 49,5 |
Si bien el entrenamiento con Cambrian-7M proporciona resultados comparativos competitivos, observamos que el modelo tiende a generar respuestas más cortas y a actuar como una máquina de preguntas y respuestas. Este comportamiento, al que nos referimos como el fenómeno de la "contestadora automática", puede limitar la utilidad del modelo en interacciones más complejas.
Descubrimos que agregar un mensaje del sistema como "Responda la pregunta usando una sola palabra o frase". puede ayudar a mitigar el problema. Este enfoque alienta al modelo a proporcionar respuestas tan concisas sólo cuando sea contextualmente apropiado. Para obtener más detalles, consulte nuestro artículo.
También hemos seleccionado un conjunto de datos, Cambrian-7M con aviso del sistema, que incluye el aviso del sistema para mejorar la creatividad y la capacidad de chat del modelo.
A continuación se muestra la última configuración de entrenamiento para Cambrian-1.
En el artículo de Cambrian-1, realizamos estudios extensos para demostrar la necesidad de un entrenamiento en dos etapas. El entrenamiento Cambrian-1 consta de dos etapas:
Cambrian-1 está entrenado en TPU-V4-512 pero también puede entrenarse en TPU a partir de TPU-V4-64. El código de entrenamiento de GPU se publicará pronto. Para el entrenamiento de GPU en menos GPU, reduzca per_device_train_batch_size y aumente gradient_accumulation_steps en consecuencia, asegurándose de que el tamaño del lote global siga siendo el mismo: per_device_train_batch_size x gradient_accumulation_steps x num_gpus .
A continuación se proporcionan ambos hiperparámetros utilizados en el preentrenamiento y el ajuste fino.
| LLM básico | Tamaño de lote global | Tasa de aprendizaje | Tasa de aprendizaje SVA | Épocas | Longitud máxima |
|---|---|---|---|---|---|
| Llama-3 8B | 512 | 1e-3 | 1e-4 | 1 | 2048 |
| Vicuña-1.5 13B | 512 | 1e-3 | 1e-4 | 1 | 2048 |
| Hermes Yi-34B | 1024 | 1e-3 | 1e-4 | 1 | 2048 |
| LLM básico | Tamaño de lote global | Tasa de aprendizaje | Épocas | Longitud máxima |
|---|---|---|---|---|
| Llama-3 8B | 512 | 4e-5 | 1 | 2048 |
| Vicuña-1.5 13B | 512 | 4e-5 | 1 | 2048 |
| Hermes Yi-34B | 1024 | 2e-5 | 1 | 2048 |
Para ajustar la instrucción, realizamos experimentos para determinar la tasa de aprendizaje óptima para el entrenamiento de nuestro modelo. Según nuestros hallazgos, recomendamos utilizar la siguiente fórmula para ajustar su tasa de aprendizaje según la disponibilidad de su dispositivo:
optimal lr = base_lr * sqrt(bs / base_bs)
Para obtener el LLM básico y entrenar los modelos 8B, 13B y 34B:
Usamos una combinación de datos de alineación de LLaVA, ShareGPT4V, Mini-Gemini y ALLaVA para preparar previamente nuestro conector visual (SVA). En Cambrian-1, realizamos estudios extensos para demostrar la necesidad y los beneficios de utilizar datos de alineación adicionales.
Para comenzar, visite nuestra página de datos de alineación de Hugging Face para obtener más detalles. Puede descargar los datos de alineación desde los siguientes enlaces:
Proporcionamos guiones de capacitación de muestra en:
Si desea entrenar con otras fuentes de datos o datos personalizados, admitimos el formato de datos LLaVA de uso común. Para manejar archivos muy grandes, utilizamos el formato JSONL en lugar del formato JSON para una carga diferida de datos para optimizar el uso de la memoria.
De manera similar a Training SVA, visite nuestros datos de Cambrian-10M para obtener más detalles sobre los datos de ajuste de instrucciones.
Proporcionamos guiones de capacitación de muestra en:
--mm_projector_type : para utilizar nuestro módulo SVA, establezca este valor en sva . Para utilizar el proyector MLP de 2 capas estilo LLaVA, establezca este valor en mlp2x_gelu .--vision_tower_aux_list : la lista de modelos de visión a usar (por ejemplo '["siglip/CLIP-ViT-SO400M-14-384", "openai/clip-vit-large-patch14-336", "facebook/dinov2-giant-res378", "clip-convnext-XXL-multi-stage"]' ).--vision_tower_aux_token_len_list : la lista del número de fichas de visión para cada torre de visión; cada número debe ser un número cuadrado (por ejemplo '[576, 576, 576, 9216]' ). El mapa de características de cada torre de visión se interpolará para cumplir con este requisito.--image_token_len : la cantidad final de tokens de visión que se proporcionarán a LLM; el número debe ser un número cuadrado (por ejemplo, 576 ). Tenga en cuenta que si mm_projector_type es mlp, cada número en vision_tower_aux_token_len_list debe ser el mismo que image_token_len . Los argumentos siguientes sólo son significativos para el proyector SVA.--num_query_group : el valor G para el módulo SVA.--query_num_list : una lista de números de consulta para cada grupo de consultas en SVA (por ejemplo, '[576]' ). La longitud de la lista debe ser igual a num_query_group .--connector_depth : el valor D para el módulo SVA.--vision_hidden_size : el tamaño oculto del módulo SVA.--connector_only : si es verdadero, el módulo SVA solo aparecerá antes del LLM; de lo contrario, se insertará varias veces dentro del LLM. Los tres argumentos siguientes sólo tienen sentido cuando se establece en False .--num_of_vision_sampler_layers : el número total de módulos SVA insertados dentro del LLM.--start_of_vision_sampler_layers : el índice de la capa LLM después del cual comienza la inserción de SVA.--stride_of_vision_sampler_layers : El paso de la inserción del módulo SVA dentro del LLM. Hemos publicado nuestro código de evaluación en la subcarpeta eval/ . Consulte el archivo README allí para obtener más detalles.
Las siguientes instrucciones lo guiarán a través del inicio de una demostración local de Gradio con Cambrian. Proporcionamos una interfaz web sencilla para que pueda interactuar con el modelo. También puede utilizar la CLI para realizar inferencias. Esta configuración está fuertemente inspirada en LLaVA.
Siga los pasos a continuación para iniciar una demostración local de Gradio. A continuación 1 se muestra un diagrama del código de servicio local.
%%{init: {"tema": "base"}}%%
diagrama de flujo BT
%% declarar nodos
estilo gws relleno:#f9f,trazo:#333,ancho de trazo:2px
relleno de estilo c:#bbf,trazo:#333,ancho de trazo:2px
estilo mw8b relleno:#aff,trazo:#333,ancho de trazo:2px
estilo mw13b relleno:#aff,trazo:#333,ancho de trazo:2px
%% estilo sglw13b relleno:#ffa,trazo:#333,ancho de trazo:2px
%% estilo lsglw13b relleno:#ffa,trazo:#333,ancho de trazo:2px
gws["Gradio (servidor de interfaz de usuario)"]
c["Controlador (servidor API):<br/>PUERTO: 10000"]
mw8b["Trabajador modelo:<br/><b>Cambrian-1-8B</b><br/>PUERTO: 40000"]
mw13b["Trabajador modelo:<br/><b>Cambrian-1-13B</b><br/>PUERTO: 40001"]
%% sglw13b["SGLang Backend:<br/><b>Cambrian-1-34B</b><br/>http://localhost:30000"]
%% lsglw13b["Trabajador SGLang:<br/>><b>Cambrian-1-34B<b><br/>PUERTO: 40002"]
subgrafo "Arquitectura de demostración"
dirección BT
c <--> gws
mw8b <--> c
mw13b <--> c
%% lsglw13b <--> c
%% sglw13b <--> lsglw13b
fin
python -m cambrian.serve.controller --host 0.0.0.0 --port 10000python -m cambrian.serve.gradio_web_server --controller http://localhost:10000 --model-list-mode reloadAcaba de iniciar la interfaz web de Gradio. Ahora puede abrir la interfaz web con la URL impresa en la pantalla. Puede notar que no hay ningún modelo en la lista de modelos. No te preocupes, todavía no hemos lanzado ningún modelo de trabajador. Se actualizará automáticamente cuando inicie un trabajador modelo.
Muy pronto.
Este es el trabajador real que realiza la inferencia en la GPU. Cada trabajador es responsable de un único modelo especificado en --model-path .
python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path nyu-visionx/cambrian-8bEspere hasta que el proceso termine de cargar el modelo y vea "Uvicorn ejecutándose en ...". Ahora, actualice su interfaz de usuario web de Gradio y verá el modelo que acaba de lanzar en la lista de modelos.
Puede iniciar tantos trabajadores como desee y comparar entre diferentes puntos de control de modelos en la misma interfaz de Gradio. Mantenga el --controller igual y modifique --port y --worker a un número de puerto diferente para cada trabajador.
python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port < different from 40000, say 40001> --worker http://localhost: < change accordingly, i.e. 40001> --model-path < ckpt 2> Si está utilizando un dispositivo Apple con un chip M1 o M2, puede especificar el dispositivo mps usando el indicador --device : --device mps .
Si la VRAM de su GPU es inferior a 24 GB (por ejemplo, RTX 3090, RTX 4090, etc.), puede intentar ejecutarla con varias GPU. Nuestra base de código más reciente intentará utilizar automáticamente varias GPU si tiene más de una GPU. Puede especificar qué GPU usar con CUDA_VISIBLE_DEVICES . A continuación se muestra un ejemplo de ejecución con las dos primeras GPU.
CUDA_VISIBLE_DEVICES=0,1 python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path nyu-visionx/cambrian-8bHACER
Si encuentra útil el Cámbrico para su investigación y aplicaciones, cítelo utilizando este BibTeX:
@misc { tong2024cambrian1 ,
title = { Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs } ,
author = { Shengbang Tong and Ellis Brown and Penghao Wu and Sanghyun Woo and Manoj Middepogu and Sai Charitha Akula and Jihan Yang and Shusheng Yang and Adithya Iyer and Xichen Pan and Austin Wang and Rob Fergus and Yann LeCun and Saining Xie } ,
year = { 2024 } ,
eprint = { 2406.16860 } ,
}
Avisos de uso y licencia : este proyecto utiliza ciertos conjuntos de datos y puntos de control que están sujetos a sus respectivas licencias originales. Los usuarios deben cumplir con todos los términos y condiciones de estas licencias originales, incluidos, entre otros, los Términos de uso de OpenAI para el conjunto de datos y las licencias específicas para modelos de lenguaje base para puntos de control entrenados utilizando el conjunto de datos (por ejemplo, licencia comunitaria Llama para LLaMA-3, y Vicuña-1.5). Este proyecto no impone restricciones adicionales más allá de las estipuladas en las licencias originales. Además, se recuerda a los usuarios que se aseguren de que el uso del conjunto de datos y los puntos de control cumpla con todas las leyes y regulaciones aplicables.
Copiado del diagrama de LLaVA. ↩


