Synonyms
Synonyms
Sinónimos chinos de procesamiento y comprensión del lenguaje natural.
Mejores sinónimos en chino: chatbot, kit de herramientas inteligente de preguntas y respuestas.
synonyms se pueden utilizar para muchas tareas en la comprensión del lenguaje natural: alineación de texto, algoritmos de recomendación, cálculos de similitud, compensación semántica, extracción de palabras clave, extracción de conceptos, resumen automático, motores de búsqueda, etc.
Para brindar servicios estables, confiables y optimizados a largo plazo, Synonyms cambió para usar la licencia Chunsong, v1.0 y cobra por descargar modelos de aprendizaje automático; consulte la tienda de certificados para obtener más detalles. Los contribuyentes anteriores (contribuyentes de código con contribuciones destacadas) pueden contactarnos para discutir cuestiones de cobro. -- Chatopera Inc. @ octubre de 2023
Siga los pasos a continuación para instalar y activar paquetes.
pip install -U synonymsLa versión estable actual es v3.x.
Los paquetes de modelos de aprendizaje automático de Synonyms requieren una licencia de Chatopera License Store, primero compre una licencia y obtenga la license id en la página Licencias en Chatopera License Store ( license id : en el almacén de certificados, en la página de detalles del certificado, haga clic en [Copiar Identidad del certificado]).
En segundo lugar, configure la variable de entorno en su terminal o scripts de shell como se muestra a continuación.
por ejemplo, Shell, CMD Scripts en Linux, Windows, macOS.
# Linux / macOS
export SYNONYMS_DL_LICENSE=YOUR_LICENSE
# # e.g. if your license id is `FOOBAR`, run `export SYNONYMS_DL_LICENSE=FOOBAR`
# Windows
# # 1/2 Command Prompt
set SYNONYMS_DL_LICENSE=YOUR_LICENSE
# # 2/2 PowerShell
$env :SYNONYMS_DL_LICENSE= ' YOUR_LICENSE 'Cuaderno Jupyter, etc.
import os
os . environ [ "SYNONYMS_DL_LICENSE" ] = "YOUR_LICENSE"
_licenseid = os . environ . get ( "SYNONYMS_DL_LICENSE" , None )
print ( "SYNONYMS_DL_LICENSE=" , _licenseid )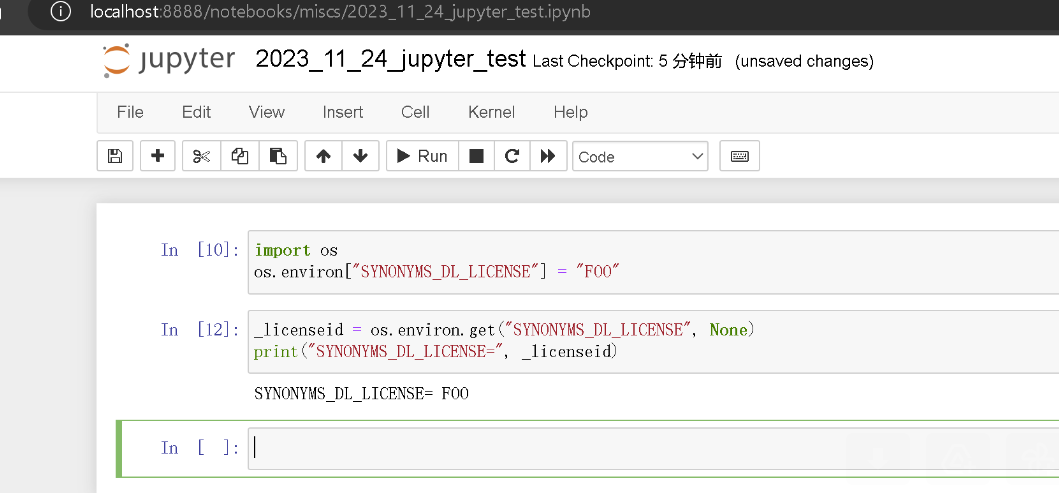
Consejo: el archivo vectorial de Word se descargará por primera vez después de la instalación y la velocidad de descarga depende de las condiciones de la red.
Por último, descargue el paquete del modelo mediante comando o script:
python -c " import synonyms; synonyms.display('能量') " # download word vectors file 
Admite el uso de variables de entorno para configurar el vocabulario de segmentación de palabras y los archivos vectoriales de palabras word2vec.
| variables de entorno | describir |
|---|---|
| SYNONYMS_WORD2VEC_BIN_MODEL_ZH_CN | Archivo vectorial de Word entrenado con word2vec, formato binario. |
| SINÓNIMOS_WORDSEG_DICT | Diccionario maestro de segmentación de palabras chinas, referencia de formato y uso |
| SINÓNIMOS_DEBUG | ["TRUE"|"FALSE"], si se generan registros de depuración, configurado en salida "TRUE", el valor predeterminado es "FALSE" |
import synonyms
print ( "人脸: " , synonyms . nearby ( "人脸" ))
print ( "识别: " , synonyms . nearby ( "识别" ))
print ( "NOT_EXIST: " , synonyms . nearby ( "NOT_EXIST" )) synonyms.nearby(WORD [,SIZE]) devuelve una tupla. La tupla contiene dos elementos: ([nearby_words], [nearby_words_score]) nearby_words sinónimos de WORD. También se almacenan en forma de lista y se basan en. distancia. Las longitudes están ordenadas de cerca a lejos, nearby_words_score es la puntuación de la distancia entre las palabras en la posición correspondiente en nearby_words . La puntuación está en el intervalo (0-1). Cuanto más cerca esté de 1, más cerca estará el SIZE de palabras devueltas. el valor predeterminado es 10. Por ejemplo:
synonyms . nearby (人脸, 10 ) = (
[ "图片" , "图像" , "通过观察" , "数字图像" , "几何图形" , "脸部" , "图象" , "放大镜" , "面孔" , "Mii" ],
[ 0.597284 , 0.580373 , 0.568486 , 0.535674 , 0.531835 , 0.530
095 , 0.525344 , 0.524009 , 0.523101 , 0.516046 ]) En el caso de OOV, se devuelve ([], []) , tamaño actual del diccionario: 435,729.
Comparación de similitud entre dos oraciones.
sen1 = "发生历史性变革"
sen2 = "发生历史性变革"
r = synonyms . compare ( sen1 , sen2 , seg = True )Entre ellos, el parámetro seg indica si sinónimos.compare realiza la segmentación de palabras en sen1 y sen2, y el valor predeterminado es Verdadero. Valor de retorno: [0-1], y cuanto más cerca esté de 1, más similares serán las dos oraciones.
旗帜引领方向 vs 道路决定命运: 0.429
旗帜引领方向 vs 旗帜指引道路: 0.93
发生历史性变革 vs 发生历史性变革: 1.0 Imprima sinónimos de una manera amigable para facilitar la depuración. display(WORD [, SIZE]) llama synonyms#nearby .
>> > synonyms . display ( "飞机" )
'飞机'近义词:
1. 飞机: 1.0
2. 直升机: 0.8423391
3. 客机: 0.8393003
4. 滑翔机: 0.7872388
5. 军用飞机: 0.7832081
6. 水上飞机: 0.77857226
7. 运输机: 0.7724742
8. 航机: 0.7664748
9. 航空器: 0.76592904
10. 民航机: 0.74209654 SIZE es el número de listas de vocabulario impresas, el valor predeterminado es 10.
Imprima la información de descripción del paquete actual:
>>> synonyms.describe()
Vocab size in vector model: 435729
model_path: /Users/hain/chatopera/Synonyms/synonyms/data/words.vector.gz
version: 3.18.0
{'vocab_size': 435729, 'version': '3.18.0', 'model_path': '/chatopera/Synonyms/synonyms/data/words.vector.gz'}
Obtenga un vector de palabras, que es una matriz numerosa. Cuando la palabra es una palabra no registrada, se genera una excepción KeyError.
>> > synonyms . v ( "飞机" )
array ([ - 2.412167 , 2.2628384 , - 7.0214124 , 3.9381874 , 0.8219283 ,
- 3.2809453 , 3.8747153 , - 5.217062 , - 2.2786229 , - 1.2572327 ],
dtype = float32 )Obtenga un vector de la oración después de la segmentación de palabras. El vector se compone en modo BoW.
sentence : 句子是分词后通过空格联合起来
ignore : 是否忽略OOV , False时,随机生成一个向量Segmentación de palabras chinas
synonyms . seg ( "中文近义词工具包" )El resultado de la segmentación de palabras es una tupla que consta de dos listas, que son palabras y sus correspondientes partes de la oración.
([ '中文' , '近义词' , '工具包' ], [ 'nz' , 'n' , 'n' ])Este participio no elimina las palabras vacías ni la puntuación.
Extraer palabras clave De forma predeterminada, las palabras clave se extraen según su importancia.
keywords = synonyms.keywords("9月15日以来,台积电、高通、三星等华为的重要合作伙伴,只要没有美国的相关许可证,都无法供应芯片给华为,而中芯国际等国产芯片企业,也因采用美国技术,而无法供货给华为。目前华为部分型号的手机产品出现货少的现象,若该形势持续下去,华为手机业务将遭受重创。")
Obtenga más registros para depurar, establezca la variable de entorno.
SYNONYMS_DEBUG=TRUE
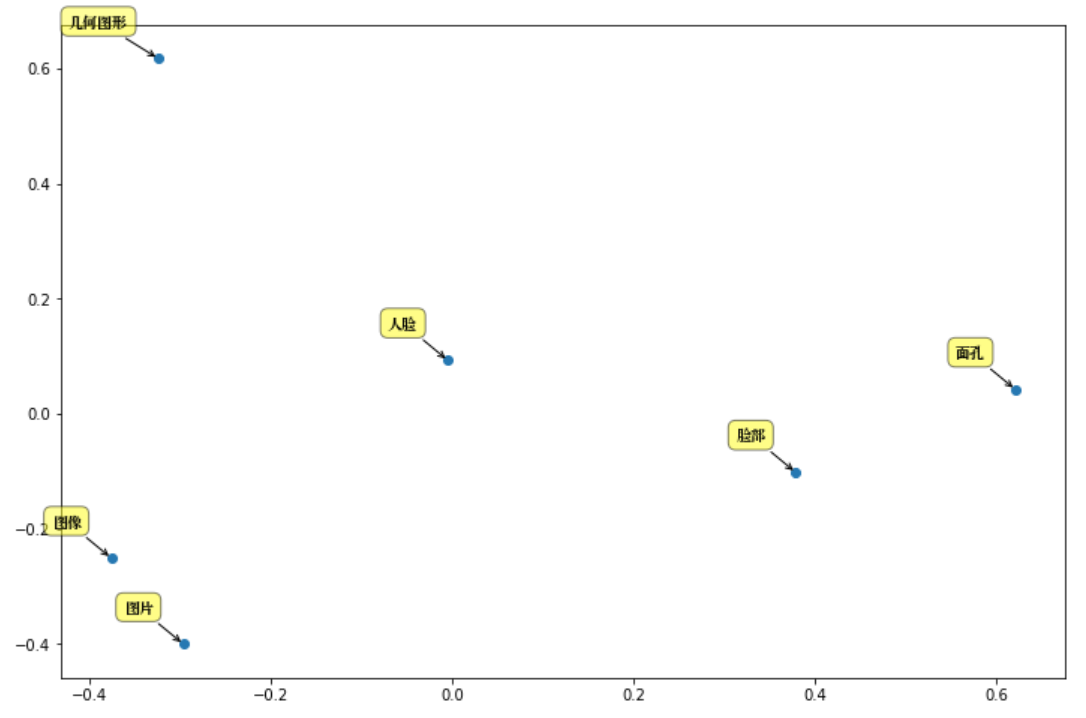
Tomando como ejemplo el "rostro humano" para analizar los componentes principales:
$ pip install -r Requirements.txt
$ python demo.pyDeclaración de estado actualizada.
Lo que dicen los usuarios:
Los datos se construyen en base a wikidata-corpus.
"Sinónimos Cilin" fue compilado por Mei Jiaju y otros en 1983. La versión más utilizada ahora es la "Edición ampliada de Sinónimos Cilin" mantenida por el Centro de Investigación de Computación Social y Recuperación de Información del Instituto de Tecnología de Harbin. Divide finamente el vocabulario chino en grandes. Las categorías y subcategorías clasifican la relación entre palabras. La versión ampliada de Sinónimos Cilin contiene más de 70.000 palabras, de las cuales más de 30.000 se comparten en forma de datos abiertos.
HowNet, también conocido como HowNet, no es solo un diccionario semántico, sino un sistema de conocimiento. La relación entre palabras es uno de sus escenarios de uso básicos. CNKI contiene más de 8 palabras.
El estándar de evaluación internacional para algoritmos de similitud de palabras generalmente adopta el valor de juicio manual del conjunto de pares de palabras en inglés publicado por Miller & Charles. El conjunto de pares de palabras consta de diez pares de palabras en inglés altamente relacionadas, diez pares de moderadamente relacionadas y diez pares de palabras en inglés poco relacionadas, y luego se pide a 38 sujetos que juzguen la relevancia semántica de estos 30 pares y finalmente tomen su promedio. El valor sirve como criterio manual. Luego, diferentes herramientas de sinónimos también califican la similitud de estas palabras y las comparan con criterios de juicio manual, como el uso del coeficiente de correlación de Pearson. En el ámbito chino, también es un método común utilizar la versión traducida de esta lista de vocabulario para comparar sinónimos chinos.
La capacidad de la lista de vocabulario de Sinónimos es 435,729 A continuación seleccionamos algunas palabras que existen en Sinónimos Cilin, CNKI y Sinónimos para comparar su similitud:
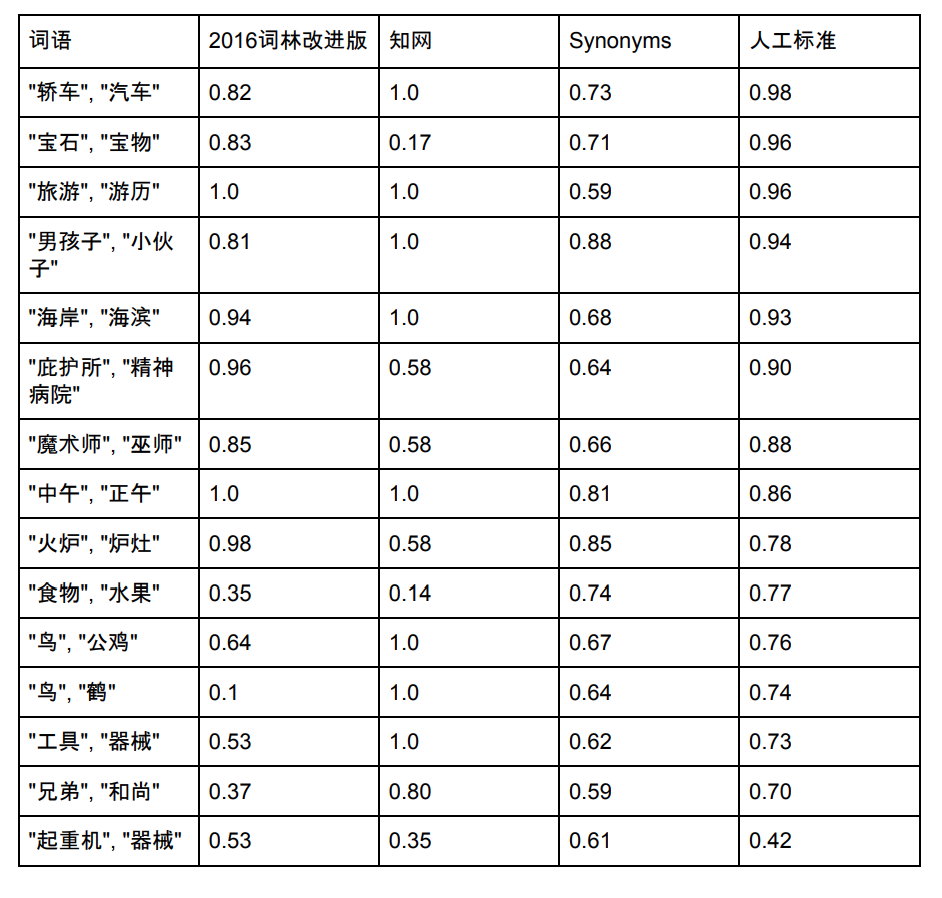
Nota: Fuentes de datos y puntuaciones de Synonym Forest y CNKI. Los sinónimos también se optimizan constantemente y las nuevas puntuaciones pueden no coincidir con la imagen de arriba.
Más resultados de comparación.
Lista de usuarios asociados a Github
Prueba con py3, MacBook Pro.
python benchmark.py
++++++++++ Nombre y versión del sistema operativo ++++++++++
Plataforma: Darwin
Núcleo: 16.7.0
Arquitectura: ('64 bits', '')
++++++++++ Núcleos de CPU ++++++++++
Núcleos: 4
Carga de CPU: 60
++++++++++ Memoria del sistema ++++++++++
memoria 8GB
synonyms#nearby: 100000 loops, best of 3 epochs: 0.209 usec per loop
52nlp.cn
Corazón de la máquina
Registro de intercambio en línea: kit de herramientas de sinónimos en chino @ 2018-02-07
Sinónimos publica certificado MIT. Los datos y procedimientos pueden usarse en productos comerciales y de investigación y deben citarse y abordarse, como en cualquier medio, diario, revista o blog publicado.
@online{Synonyms:hain2017,
author = {Hai Liang Wang, Hu Ying Xi},
title = {中文近义词工具包Synonyms},
year = 2017,
url = {https://github.com/chatopera/Synonyms},
urldate = {2017-09-27}
}
corpus-wikidata
derivación del principio de word2vec y análisis de código
No es compatible; consulte el punto 5 para obtener más información.
Word2vec lanzado por Google, esta biblioteca está escrita en lenguaje C, tiene una alta eficiencia de uso de memoria y una rápida velocidad de entrenamiento. gensim puede cargar archivos de modelo generados por word2vec.
Consulte el n.º 64 para obtener más detalles.
Hai Liang Wang
Huyingxi
Este libro fue escrito en coautoría por autores de sinónimos.
Enlace de compra rápida de libros 
"Respuesta inteligente de preguntas y aprendizaje profundo" Este libro está dirigido a estudiantes e ingenieros de software que se están preparando para comenzar con el aprendizaje automático y el procesamiento del lenguaje natural. Presenta muchos principios y algoritmos en teoría y también proporciona muchos programas de ejemplo para aumentar la practicidad. se resumen en la biblioteca de códigos de programas de muestra. Estos programas están destinados principalmente a ayudar a todos a comprender los principios y algoritmos. Puede descargarlos y ejecutarlos. La dirección de la base del código es:
https://github.com/l11x0m7/book-of-qna-code
Word2vec de Google
Wikimedia: fuente del corpus de entrenamiento
gensim: word2vec.py
SentenceSim: corpus de evaluación de similitudes
jieba: segmentación de palabras chinas
Licencia pública Chunsong, versión 1.0
https://bot.chatopera.com/
El servicio en la nube Chatopera es un servicio en la nube integral para implementar robots de chat y se factura según la cantidad de llamadas a la interfaz. Chatopera Cloud Service es una instancia de software como servicio de la plataforma de bot Chatopera. Basado en la computación en la nube, el servicio en la nube Chatopera es un servicio en la nube de chatbot como servicio .
La plataforma del robot Chatopera incluye componentes como base de conocimientos, diálogo de múltiples rondas, reconocimiento de intenciones y reconocimiento de voz, desarrollo de robots de chat estandarizados y admite escenarios como preguntas y respuestas inteligentes de acceso abierto empresarial, preguntas y respuestas inteligentes de recursos humanos, servicio al cliente inteligente y marketing en línea. ¡Los departamentos de TI empresariales y los departamentos comerciales utilizan los servicios en la nube de Chatopera para poner rápidamente los chatbots en línea!


