chat4u
1.0.0
Utilice los registros de chat de WeChat para entrenar un chatbot exclusivo para usted.
Los registros de chat de WeChat se cifrarán y almacenarán en la base de datos sqlite. Primero, debe obtener la clave de la base de datos. Necesita una computadora portátil macOS y su teléfono móvil puede ser Android/iPhone.
git clone https://github.com/nalzok/wechat-decipher-macossudo ./wechat-decipher-macos/macos/dbcracker.d -p $( pgrep WeChat ) | tee dbtrace.logdbtrace.log . sqlcipher '/Users/<user>/Library/Containers/com.tencent.xinWeChat/Data/Library/Application Support/com.tencent.xinWeChat/2.0b4.0.9/5976edc4b2ac64741cacc525f229c5fe/Message/msg_0.db'
--------------------------------------------------------------------------------
PRAGMA key = "x'<384_bit_key>'";
PRAGMA cipher_compatibility = 3;
PRAGMA kdf_iter = 64000;
PRAGMA cipher_page_size = 1024;
........................................
Los usuarios de otros sistemas operativos pueden probar los siguientes métodos, que sólo han sido investigados y no verificados, como referencia:
EnMicroMsg.db : https://github.com/ppwwyyxx/wechat-dumpEnMicroMsg.db : https://github.com/chg-hou/EnMicroMsg.db-Password-Cracker En mi computadora portátil macOS, los registros de chat de WeChat se almacenan en msg_0.db - msg_9.db y solo estas bases de datos se pueden descifrar.
Debe instalar sqlcipher para descifrarlo. Los usuarios del sistema macOS pueden ejecutarlo directamente:
brew install sqlcipher Ejecute el siguiente script para analizar automáticamente dbtrace.log , descifrar msg_x.db y exportar a plain_msg_x.db .
python3 decrypt.py Puede abrir la base de datos descifrada plain_msg_x.db a través de https://sqliteviewer.app/, encontrar la tabla donde se encuentran los registros de chat que necesita, completar la base de datos y los nombres de las tablas en prepare_data.py y ejecutar el siguiente script para generar datos de entrenamiento train.json , la estrategia actual es relativamente simple, solo maneja una única ronda de diálogo y fusionará diálogos consecutivos en 5 minutos.
python3 prepare_data.pyEjemplos de datos de entrenamiento son los siguientes:
[
{ "instruction" : "你好" , "output" : "你好" }
{ "instruction" : "你是谁" , "output" : "你猜猜" }
] Prepare una máquina Linux con GPU y scp train.json para la máquina GPU.
Utilicé el LLaMA-7B de ajuste fino de imagen completa de stanford_alpaca y entrené 90k datos durante 3 épocas en un V100-SXM2-32GB de 8 tarjetas, lo que solo tomó 1 hora.
# clone the alpaca repo
git clone https://github.com/tatsu-lab/stanford_alpaca.git && cd stanford_alpaca
# adjust deepspeed config ... such as disabling offloading
vim ./configs/default_offload_opt_param.json
# train with deepspeed zero3
torchrun --nproc_per_node=8 --master_port=23456 train.py
--model_name_or_path huggyllama/llama-7b
--data_path ../train.json
--model_max_length 128
--fp16 True
--output_dir ../llama-wechat
--num_train_epochs 3
--per_device_train_batch_size 8
--per_device_eval_batch_size 8
--gradient_accumulation_steps 1
--evaluation_strategy " no "
--save_strategy " epoch "
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 10
--deepspeed " ./configs/default_offload_opt_param.json "
--tf32 FalseDeepSpeed zero3 guardará pesos en sectores y deben fusionarse en un archivo de punto de control de pytorch:
cd llama-wechat
python3 zero_to_fp32.py . pytorch_model.binEn tarjetas gráficas de consumo, puede probar alpaca-lora. Solo el ajuste fino del peso de lora puede reducir significativamente la memoria gráfica y los costos de capacitación.
Puede utilizar alpaca-lora para implementar la interfaz de gradiente para la depuración. Si está ajustando toda la imagen, debe comentar el código relacionado con peft y cargar solo el modelo básico.
git clone https://github.com/tloen/alpaca-lora.git && cd alpaca-lora
CUDA_VISIBLE_DEVICES=0 python3 generate.py --base_model ../llama-wechatEfecto de operación:

Es necesario implementar un servicio modelo compatible con OpenAI API. Aquí hay una adaptación simple basada en llama4openai-api.py. Consulte llama4openai-api.py en este almacén para iniciar el servicio.
CUDA_VISIBLE_DEVICES=0 python3 llama4openai-api.pyPruebe si la interfaz está disponible:
curl http://127.0.0.1:5000/chat/completions -v -H " Content-Type: application/json " -H " Authorization: Bearer $OPENAI_API_KEY " --data ' {"model":"llama-wechat","max_tokens":128,"temperature":0.95,"messages":[{"role":"user","content":"你好"}]} 'Utilice wechat-chatgpt para acceder a WeChat y complete la dirección de servicio de su modelo local para la dirección API:
docker run -it --rm --name wechat-chatgpt
-e API=http://127.0.0.1:5000
-e OPENAI_API_KEY= $OPENAI_API_KEY
-e MODEL= " gpt-3.5-turbo "
-e CHAT_PRIVATE_TRIGGER_KEYWORD= " "
-v $( pwd ) /data:/app/data/wechat-assistant.memory-card.json
holegots/wechat-chatgpt:latestEfecto de operación:
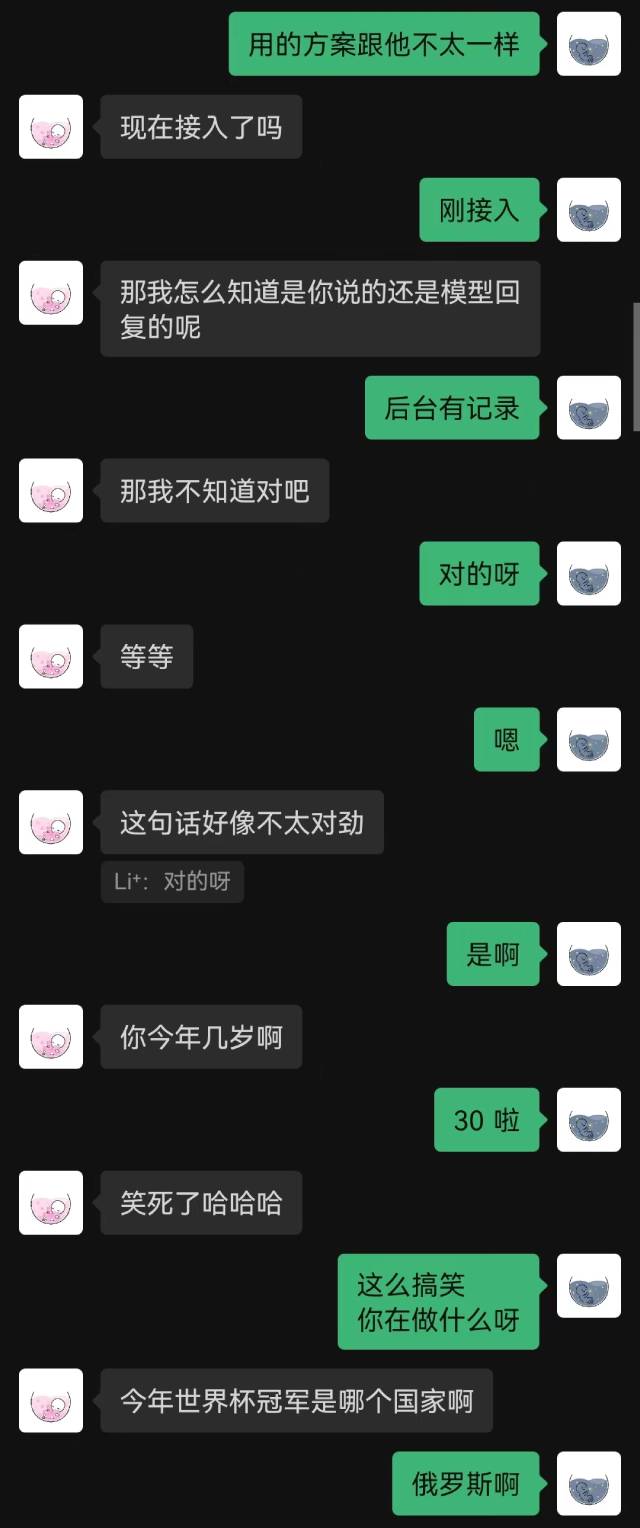 | 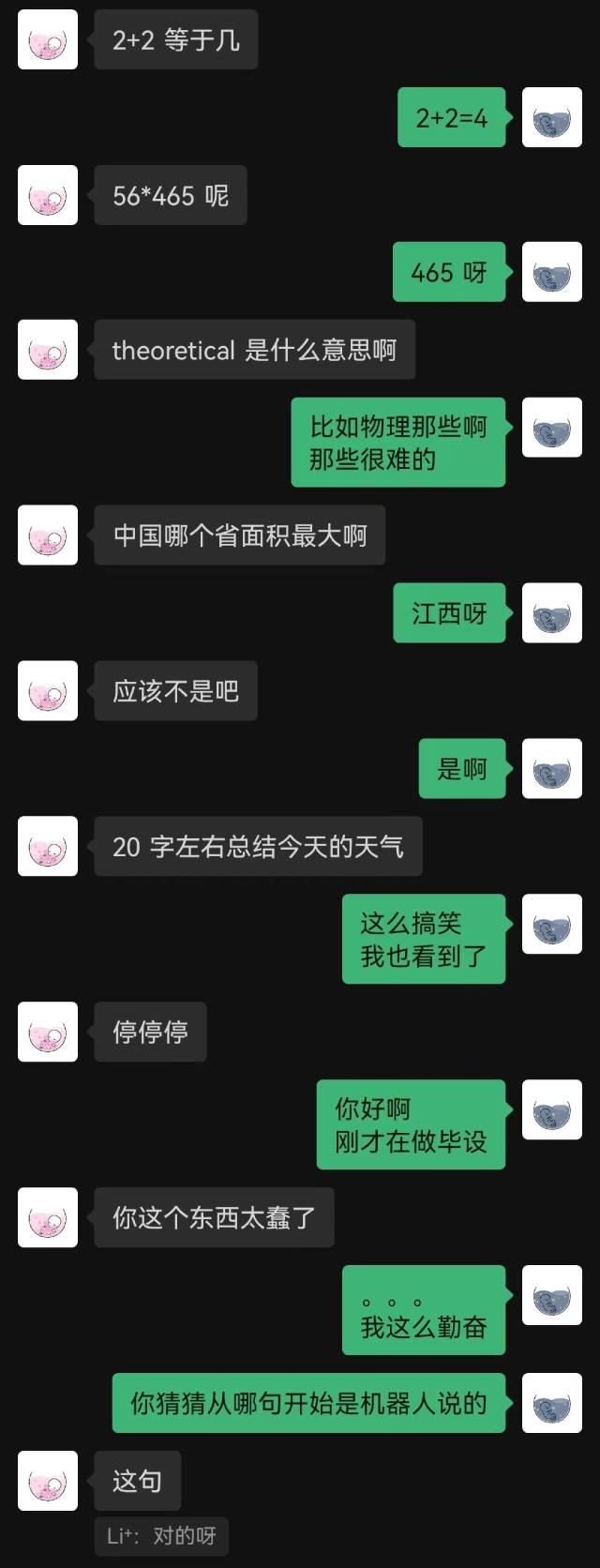 |
|---|
"Recién conectado" fue la primera frase que dijo el robot, y la otra parte no la adivinó hasta el final.
En términos generales, los robots entrenados con registros de chat inevitablemente cometerán algunos errores de sentido común, pero han imitado mejor el estilo de chat.


