msg_reply
1.0.0
¿Alguna vez has visto o utilizado Google Smart Reply? Es un servicio que proporciona sugerencias de respuesta automática para los mensajes de los usuarios. Vea abajo.
Esta es una aplicación útil del chatbot basado en recuperación. Piénsalo. ¿Cuántas veces enviamos un mensaje de texto como gracias , hola o hasta luego ? En este proyecto, construimos un sistema simple de sugerencia de respuesta de mensajes.
Parque Kyubyong
Revisión de código por Yj Choe
Necesitamos configurar la lista de sugerencias para mostrar. Naturalmente, la frecuencia se considera primero. Pero ¿qué pasa con aquellas frases que tienen un significado similar? Por ejemplo, ¿ deberían muchas gracias y ser tratados de forma independiente? No lo creemos. Queremos agruparlos y guardar nuestras ranuras. ¿Cómo? Hacemos uso de un corpus paralelo. Muchas gracias a ambos y es probable que se traduzcan al mismo texto. Con base en esta suposición, construimos grupos de sinónimos en inglés que comparten la misma traducción.
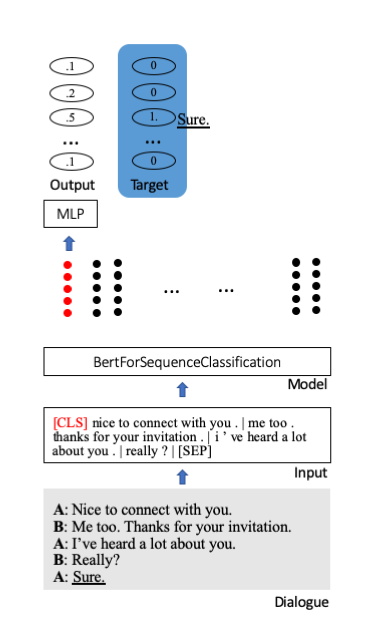
Ajustamos el modelo previamente entrenado de Huggingface para la clasificación de secuencias. En él, un token de inicio especial [CLS] almacena la información completa de una oración. Se adjuntan capas adicionales para proyectar la información condensada en unidades de clasificación (aquí 100).
Usamos corpus paralelo OpenSubtitles 2018 español-inglés para construir grupos de sinónimos. OpenSubtitles es una gran colección de subtítulos de películas traducidos. Los datos en-es constan de más de 61 millones de líneas alineadas.
Idealmente, se necesita un corpus de diálogo (muy) grande para la capacitación, lo cual no pudimos encontrar. En su lugar, utilizamos el Cornell Movie Dialogue Corpus. Se compone de 83.097 diálogos o 304.713 líneas.
pitón>=3.6
tqdm>=4.30.0
pytorch>=1.0
pytorch_pretrained_bert>=0.6.1
ntk>=3.4
PASO 0. Descargar OpenSubtitles 2018 Datos paralelos español-inglés.
bash download.sh
PASO 1. Construya grupos de sinónimos a partir del corpus.
python construct_sg.py
PASO 2. Cree diccionarios phr2sg_id y sg_id2phr.
python make_phr2sg_id.py
PASO 3. Convierta un texto monolingüe en inglés a ids.
python encode.py
PASO 4. Crea datos de entrenamiento y guárdalos como pickle.
python prepro.py
PASO 5. Entrena.
python train.py
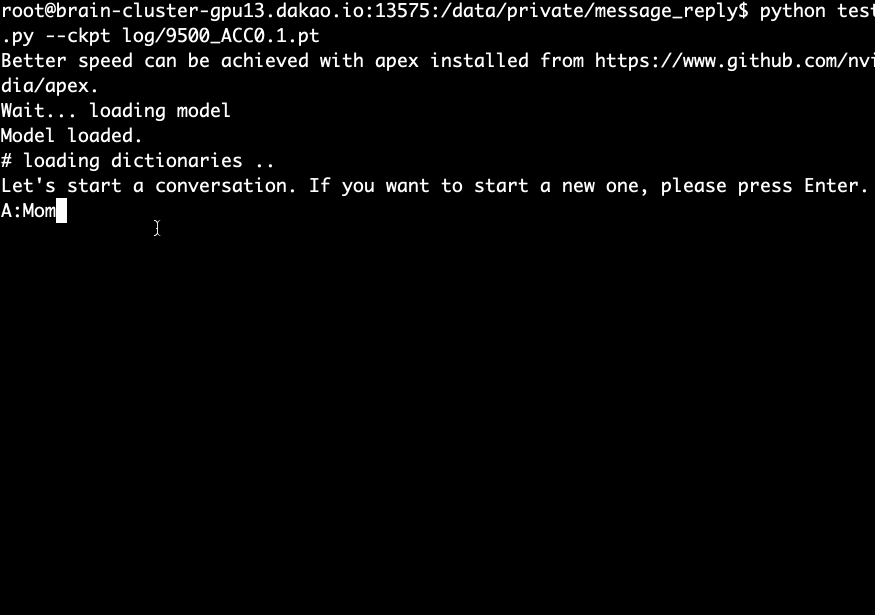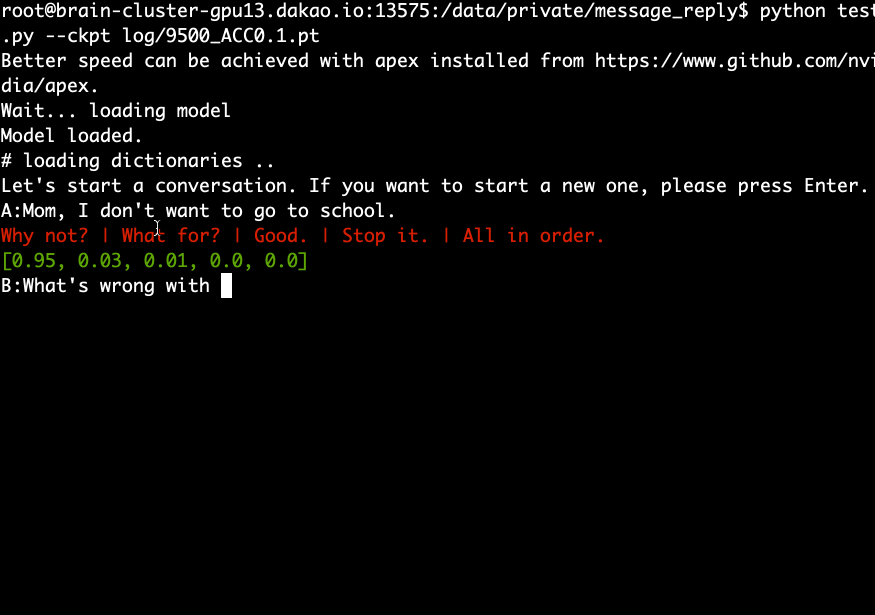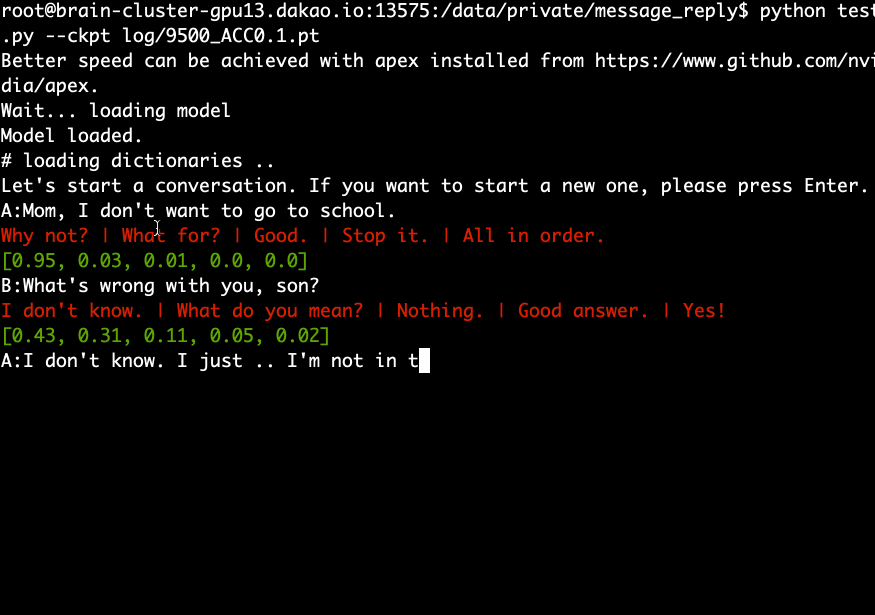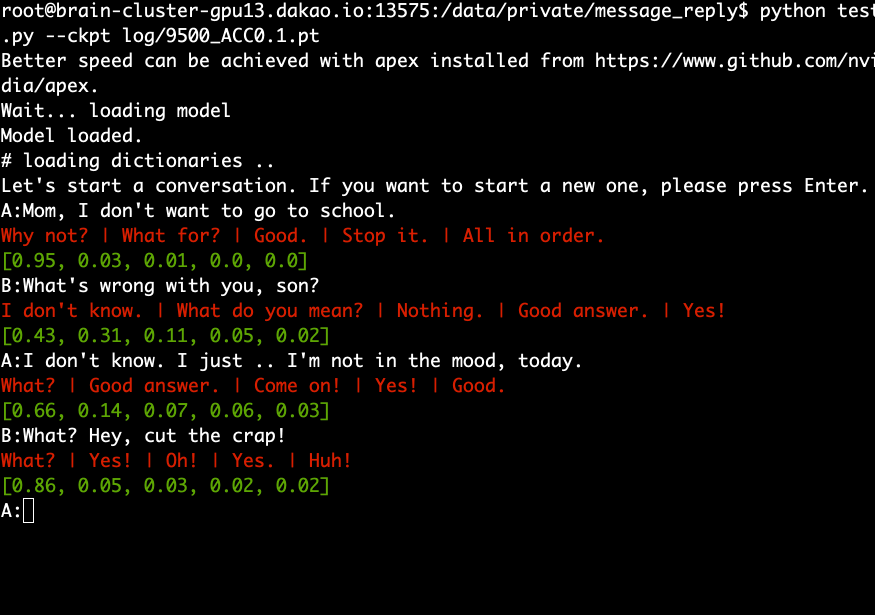
Descargue y extraiga el modelo previamente entrenado y ejecute el siguiente comando.
python test.py --ckpt log/9500_ACC0.1.pt
La pérdida de entrenamiento disminuye lenta pero constantemente.
La precisión@5 de los datos de evaluación es del 10 al 20 por ciento.
Para una aplicación real, se necesita un corpus mucho más grande.
No estoy seguro de hasta qué punto los guiones de películas se parecen a los diálogos de mensajes.
Es necesaria una mejor estrategia para construir grupos de sinónimos.
Un chatbot basado en recuperación es una aplicación realista, ya que es más seguro y más fácil que uno basado en generaciones.


