ThinkRAG
1.0.0
Inglés | Chino simplificado
El sistema de generación de mejoras de recuperación de modelos grandes ThinkRAG se puede implementar fácilmente en una computadora portátil para realizar respuestas inteligentes a preguntas en una base de conocimientos local.
El sistema está construido sobre la base de LlamaIndex y Streamlit, y ha sido optimizado para usuarios domésticos en muchas áreas, como la selección de modelos y el procesamiento de texto.
ThinkRAG es un sistema de aplicación de modelo grande desarrollado para profesionales, investigadores, estudiantes y otros trabajadores del conocimiento. Puede usarse directamente en computadoras portátiles y los datos de la base de conocimientos se guardan localmente en la computadora.
ThinkRAG tiene las siguientes características:
En particular, ThinkRAG también ha realizado muchas personalizaciones y optimizaciones para usuarios domésticos:
ThinkRAG puede utilizar todos los modelos compatibles con el marco de datos LlamaIndex. Para obtener información sobre la lista de modelos, consulte la documentación correspondiente.
ThinkRAG se compromete a crear un sistema de aplicaciones que sea directamente utilizable, útil y fácil de usar.
Por lo tanto, hemos tomado decisiones cuidadosas y hemos hecho concesiones entre varios modelos, componentes y tecnologías.
Primero, al utilizar modelos grandes, ThinkRAG admite la API OpenAI y todas las API LLM compatibles, incluidos los principales fabricantes nacionales de modelos grandes, como:
Si desea implementar modelos grandes localmente, ThinkRAG elige Ollama, que es simple y fácil de usar. Podemos descargar modelos de gran tamaño para ejecutarlos localmente a través de Ollama.
Actualmente, Ollama admite la implementación localizada de casi todos los modelos grandes convencionales, incluidos Llama, Gemma, GLM, Mistral, Phi, Llava, etc. Para obtener más información, visite el sitio web oficial de Ollama a continuación.
El sistema también utiliza modelos integrados y modelos reorganizados, y es compatible con la mayoría de los modelos de Hugging Face. Actualmente, ThinkRAG utiliza principalmente los modelos de la serie BGE de BAAI. Los usuarios nacionales pueden visitar el sitio web espejo para aprender y descargar.
Después de descargar el código de Github, use pip para instalar los componentes necesarios.
pip3 install -r requirements.txtPara ejecutar el sistema sin conexión, primero descargue Ollama desde el sitio web oficial. Luego, use el comando Ollama para descargar modelos grandes como GLM, Gemma y QWen.
Sincrónicamente, descargue el modelo de incrustación (BAAI/bge-large-zh-v1.5) y el modelo de reclasificación (BAAI/bge-reranker-base) de Hugging Face al directorio localmodels.
Para conocer pasos específicos, consulte el documento en el directorio de documentos: HowToDownloadModels.md
Para obtener un mejor rendimiento, se recomienda utilizar la API LLM de modelo grande comercial con cientos de miles de millones de parámetros.
Primero, obtenga la clave API del proveedor de servicios LLM y configure las siguientes variables de entorno.
ZHIPU_API_KEY = " "
MOONSHOT_API_KEY = " "
DEEPSEEK_API_KEY = " "
OPENAI_API_KEY = " "Puede omitir este paso y configurar la clave API a través de la interfaz de la aplicación después de que el sistema se esté ejecutando.
Si elige utilizar una o más de las API de LLM, elimine el proveedor de servicios que ya no utiliza en el archivo de configuración config.py.
Por supuesto, también puede agregar otros proveedores de servicios compatibles con la API OpenAI en el archivo de configuración.
ThinkRAG se ejecuta en modo de desarrollo de forma predeterminada. En este modo, el sistema utiliza almacenamiento de archivos local y no es necesario instalar ninguna base de datos.
Para cambiar al modo de producción, puede configurar las variables de entorno de la siguiente manera.
THINKRAG_ENV = productionEn el modo de producción, el sistema utiliza la base de datos vectorial Chroma y la base de datos clave-valor Redis.
Si no tiene Redis instalado, se recomienda instalarlo a través de Docker o utilizar una instancia de Redis existente. Configure la información de parámetros de la instancia de Redis en el archivo config.py.
Ahora está listo para ejecutar ThinkRAG.
Ejecute el siguiente comando en el directorio que contiene el archivo app.py.
streamlit run app.pyEl sistema se ejecutará y abrirá automáticamente la siguiente URL en el navegador para mostrar la interfaz de la aplicación.
http://localhost:8501/
La primera ejecución puede tardar un poco. Si el modelo integrado en Hugging Face no se descarga con anticipación, el sistema descargará automáticamente el modelo y deberá esperar más.
ThinkRAG admite la configuración y selección de modelos grandes en la interfaz de usuario, que incluyen: la URL base y la clave API de la API LLM del modelo grande, y puede seleccionar el modelo específico a usar, por ejemplo: glm-4 de ThinkRAG.
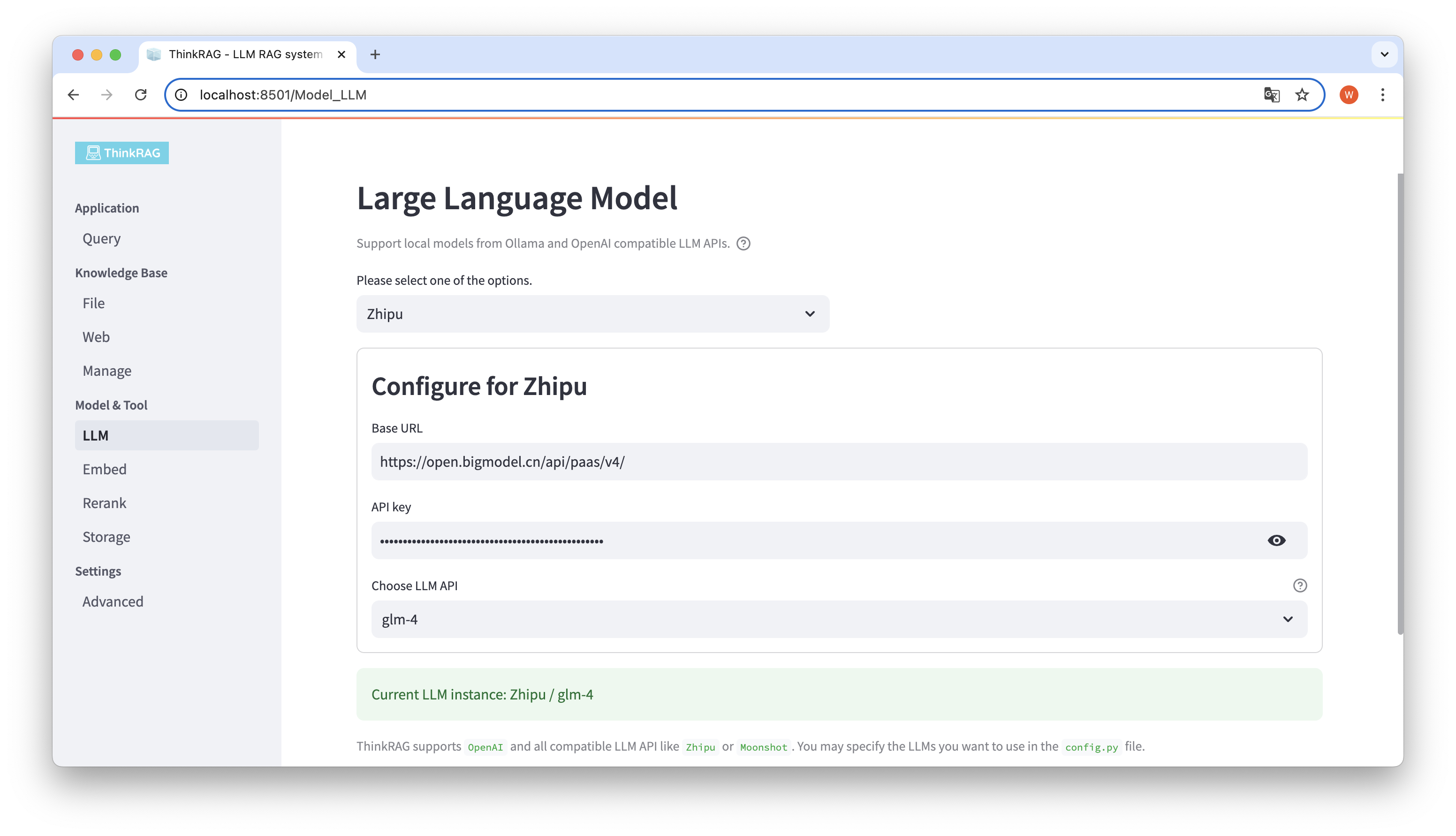
El sistema detectará automáticamente si la API y la clave están disponibles. Si están disponibles, la instancia del modelo grande seleccionado actualmente se mostrará en texto verde en la parte inferior.
De manera similar, el sistema puede obtener automáticamente los modelos descargados por Ollama, y el usuario puede seleccionar el modelo deseado en la interfaz de usuario.
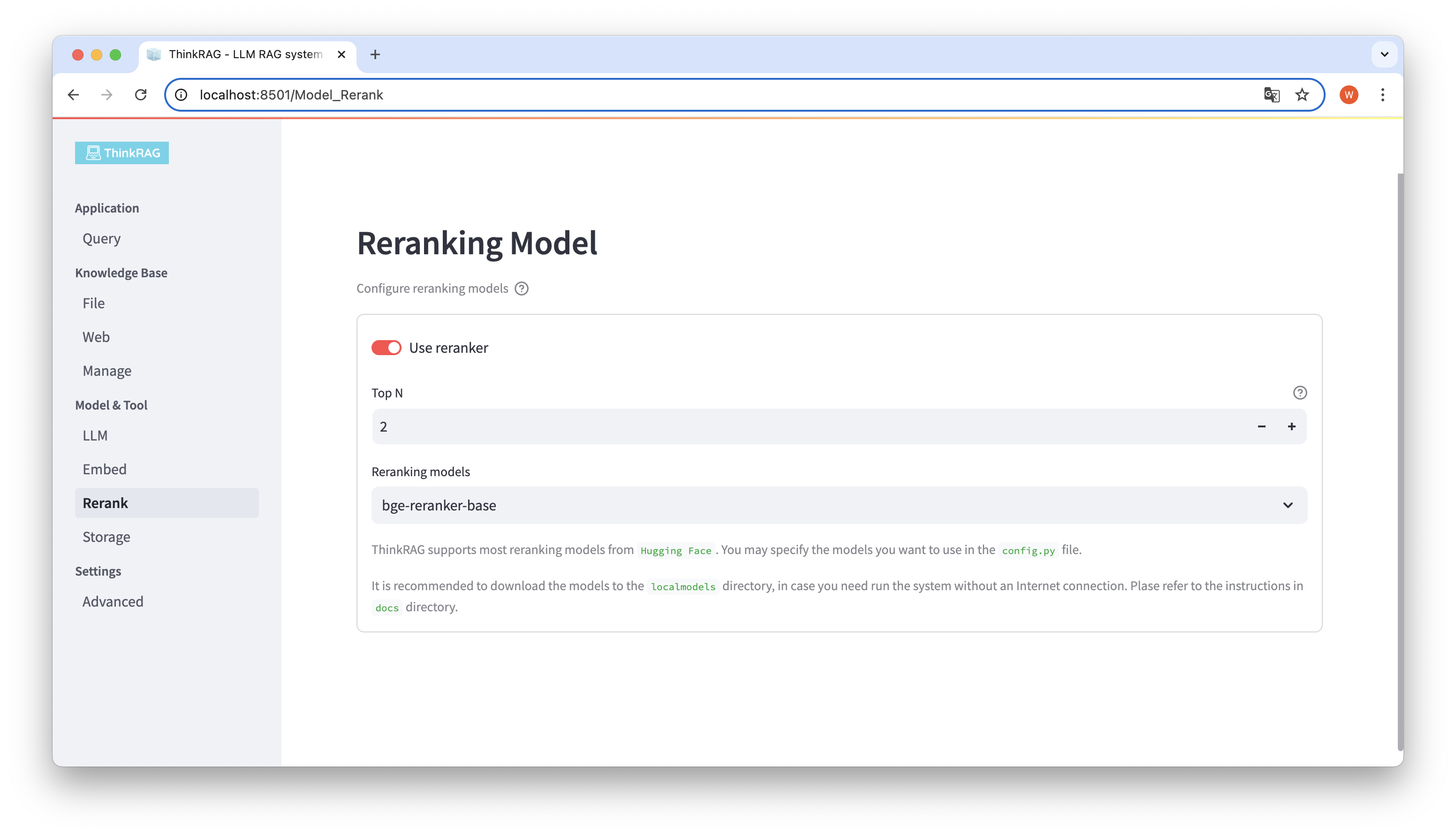
Si descargó el modelo incrustado y reorganizó el modelo en el directorio local de modelos locales. En la interfaz de usuario, puede cambiar el modelo seleccionado y configurar los parámetros del modelo reorganizado, como Top N.
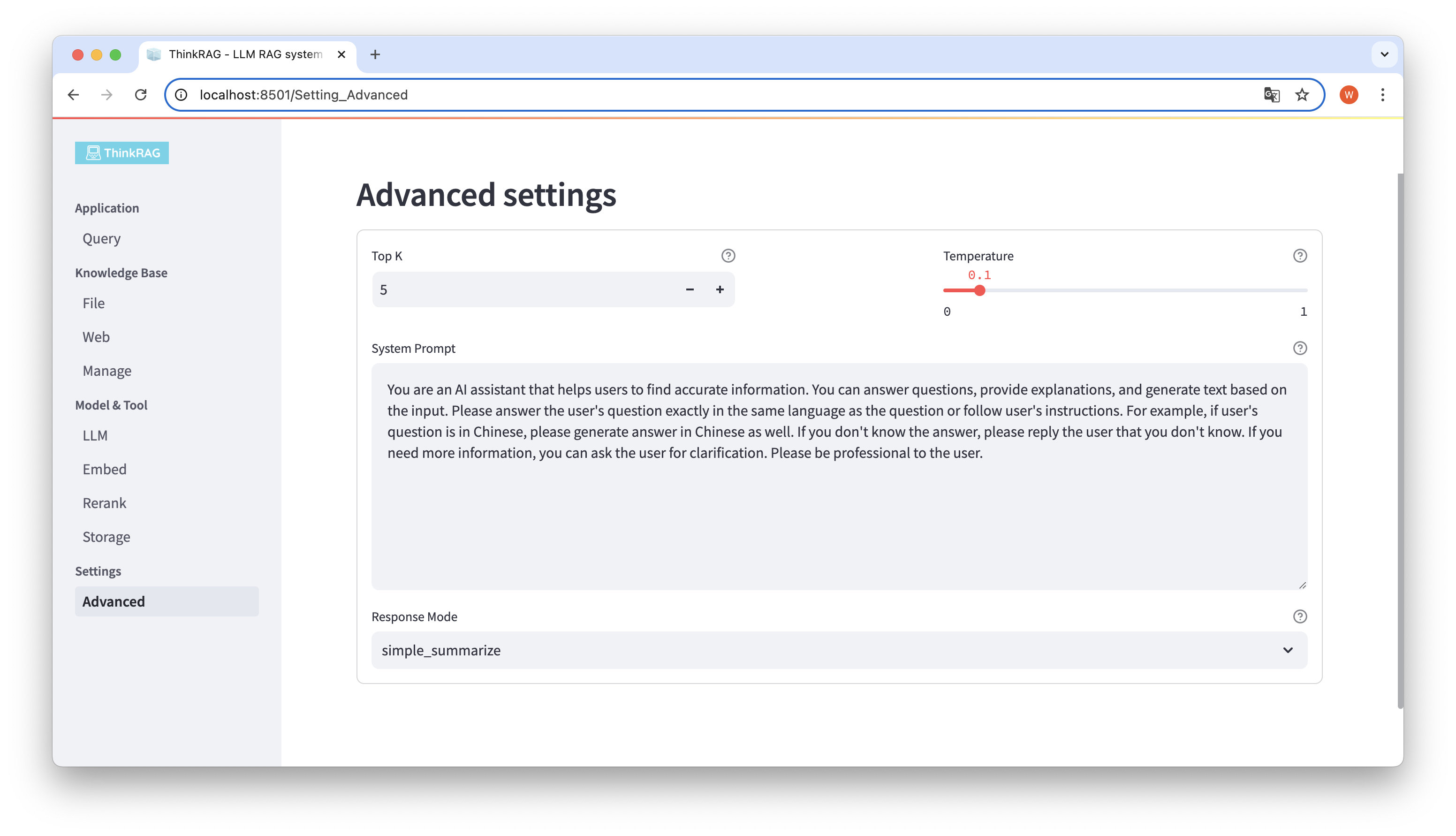
En la barra de navegación izquierda, haga clic en Configuración avanzada (Configuración-Avanzada). También puede configurar los siguientes parámetros:
Al utilizar diferentes parámetros, podemos comparar los resultados de modelos grandes y encontrar la combinación de parámetros más efectiva.
ThinkRAG admite la carga de varios archivos, como PDF, DOCX, PPTX, etc., y también admite la carga de URL de páginas web.
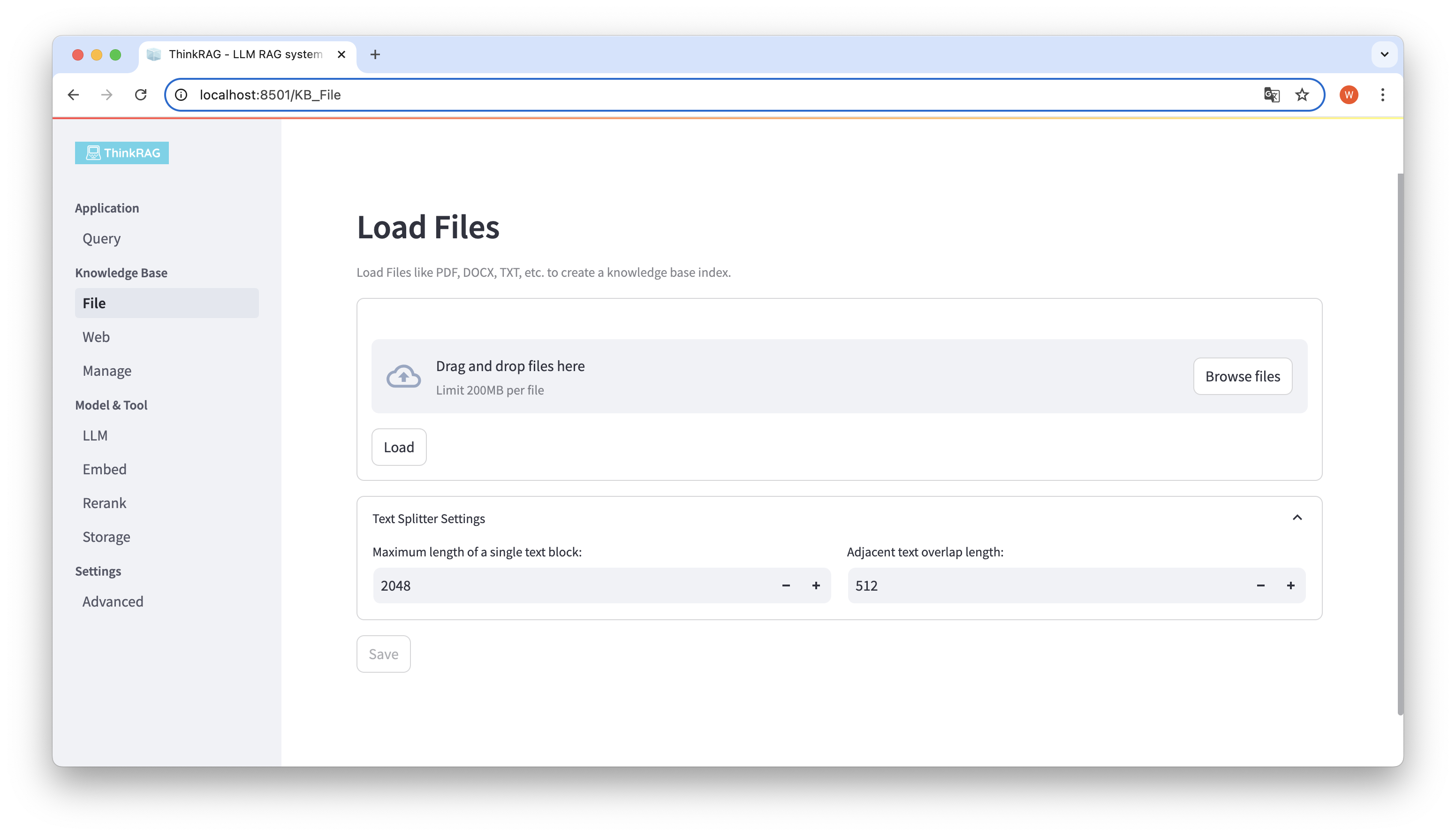
Haga clic en el botón Examinar archivos, seleccione el archivo en su computadora y luego haga clic en el botón Cargar para cargar. Se enumerarán todos los archivos cargados.
Luego, haga clic en el botón Guardar y el sistema procesará el archivo, incluida la segmentación e incrustación de texto, y lo guardará en la base de conocimientos.
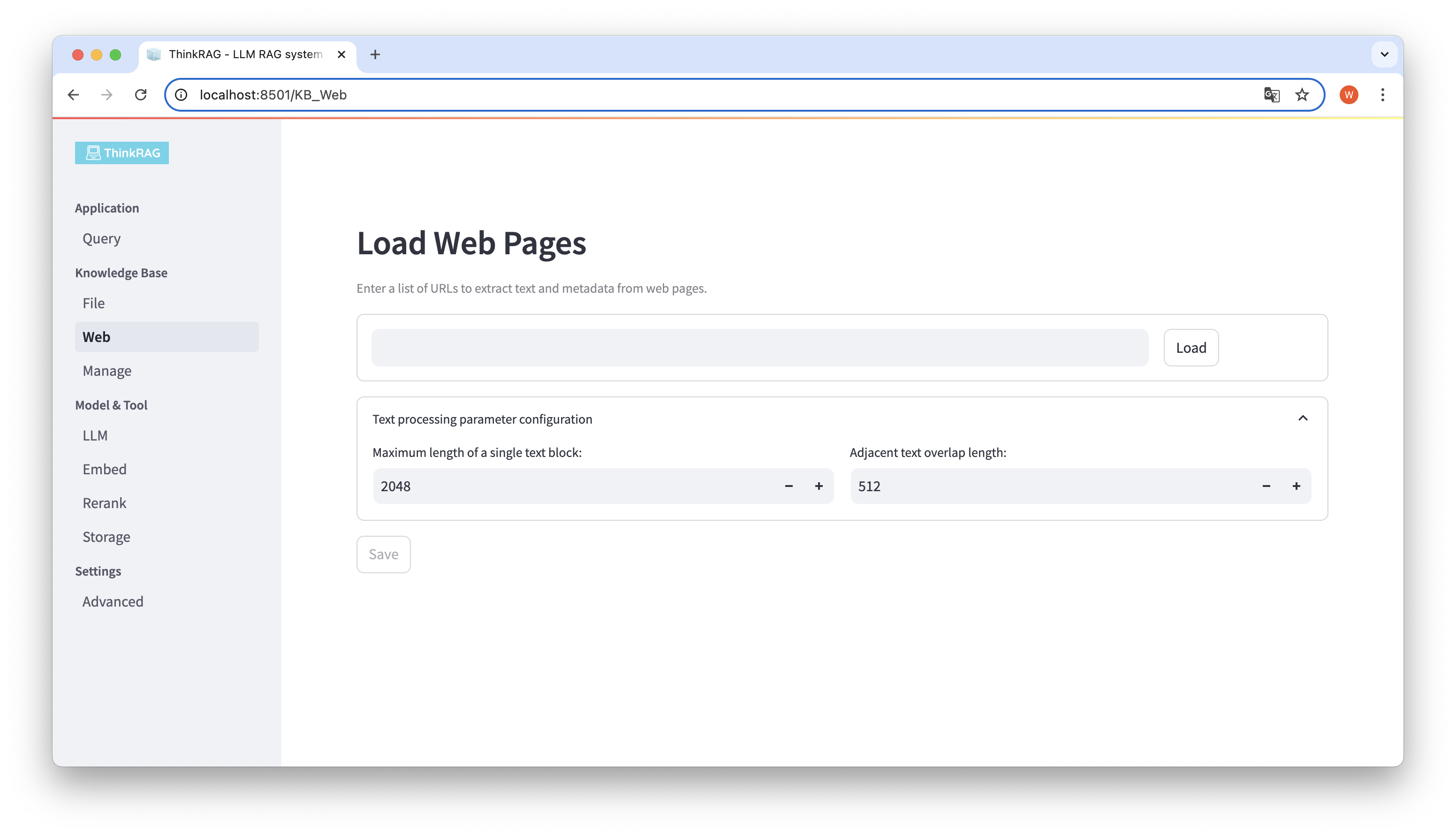
De manera similar, puede ingresar o pegar la URL de la página web, obtener la información de la página web y guardarla en la base de conocimientos después del procesamiento.
El sistema apoya la gestión de la base de conocimientos.
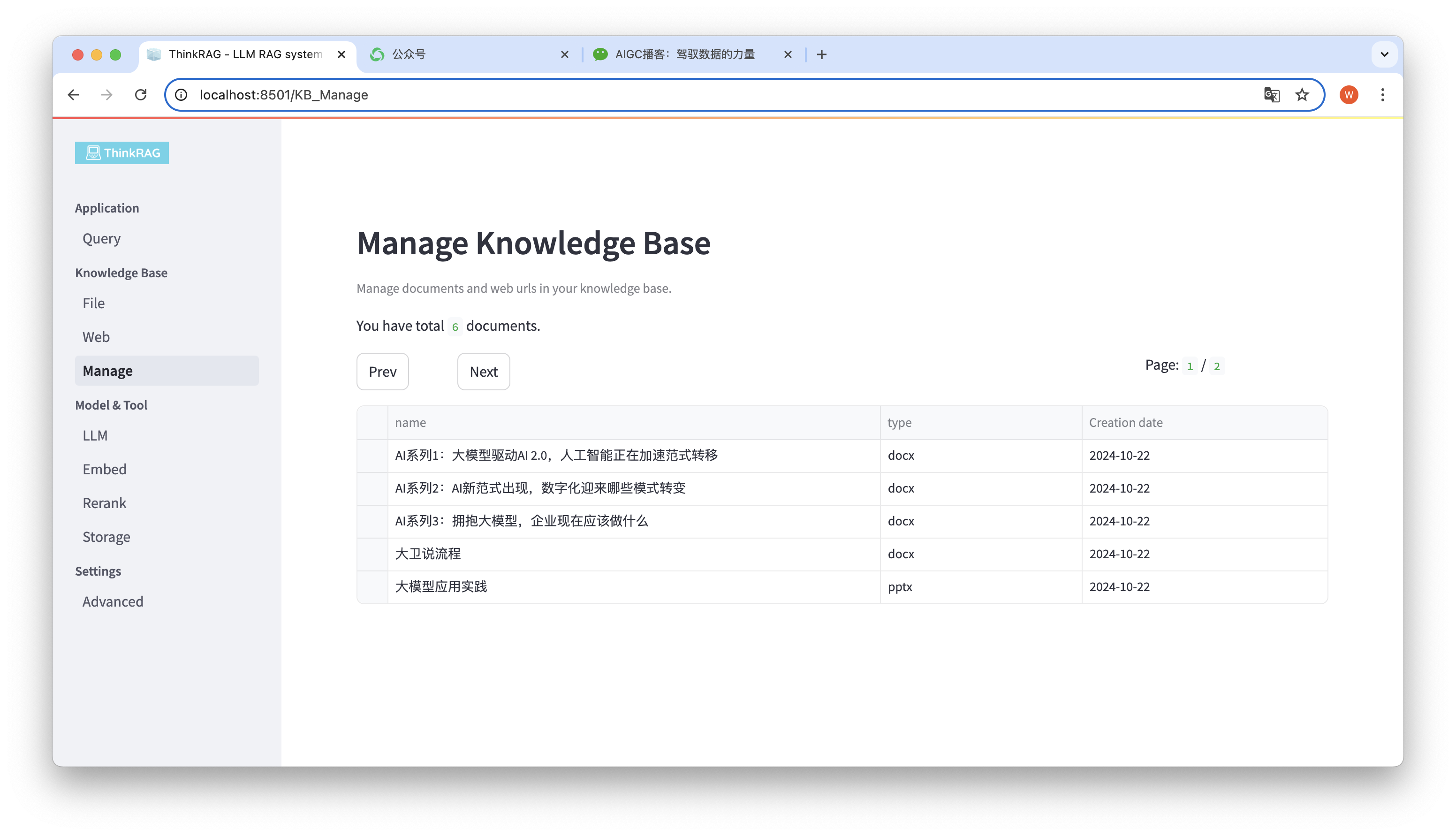
Como se muestra en la figura anterior, ThinkRAG puede enumerar todos los documentos de la base de conocimientos en páginas.
Seleccione los documentos que desea eliminar y aparecerá el botón Eliminar documentos seleccionados. Haga clic en este botón para eliminar los documentos de la base de conocimientos.
En la barra de navegación izquierda, haga clic en Consulta y aparecerá la página inteligente de preguntas y respuestas.
Después de ingresar la pregunta, el sistema buscará en la base de conocimientos y proporcionará una respuesta. Durante este proceso, el sistema utilizará tecnologías como la recuperación y reordenación híbridas para obtener contenido preciso de la base de conocimientos.
Por ejemplo, hemos subido un documento de Word a la base de conocimiento: "David Says Process.docx".
Ahora ingrese la pregunta: "¿Cuáles son las tres características de un proceso?"
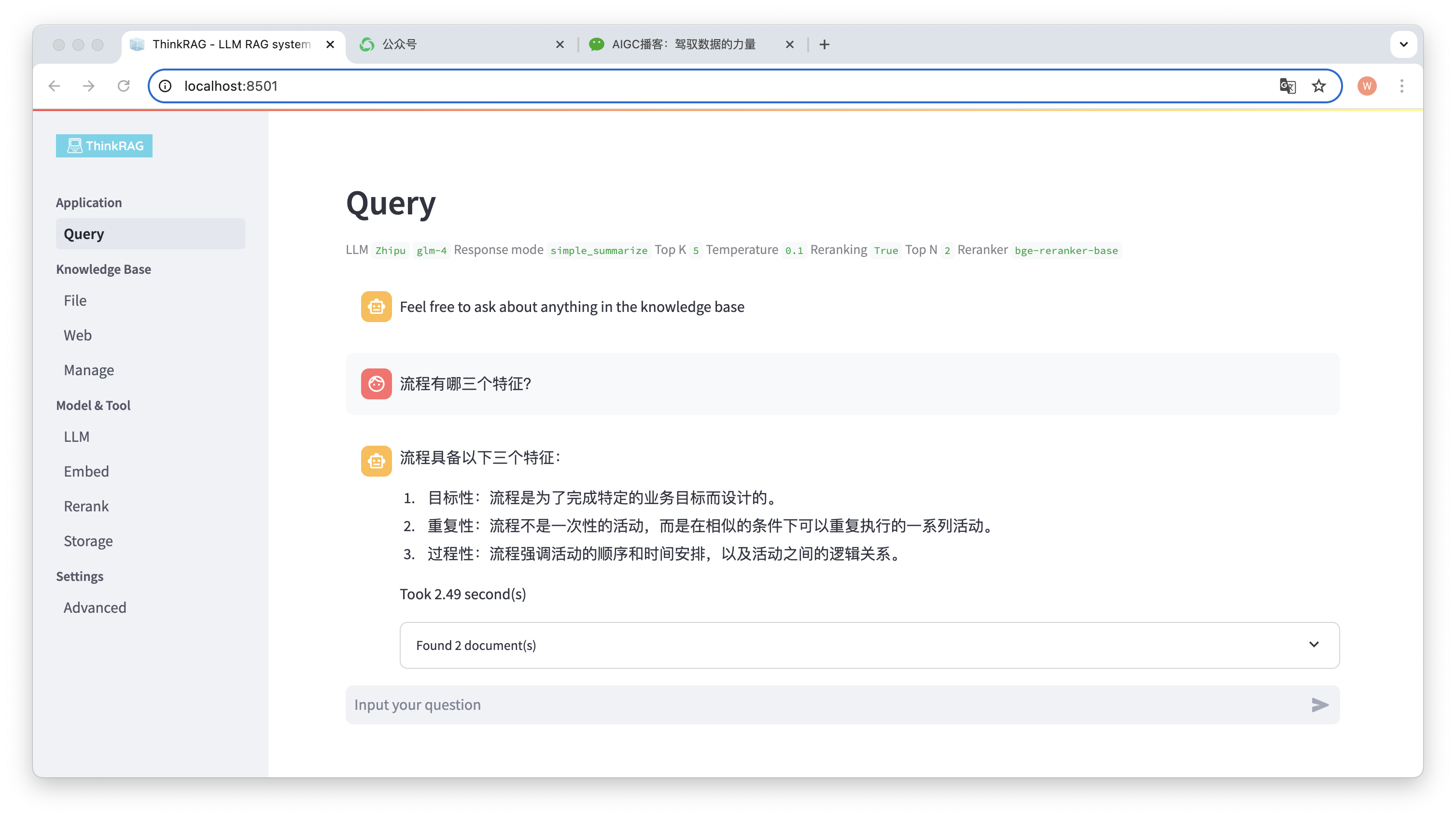
Como se muestra en la figura, el sistema tardó 2,49 segundos en dar una respuesta precisa: el proceso es específico, repetitivo y procedimental. Al mismo tiempo, el sistema también proporciona 2 documentos relacionados recuperados de la base de conocimientos.
Se puede ver que ThinkRAG implementa de manera completa y efectiva la función de generación mejorada de recuperación de modelos grandes basada en la base de conocimiento local.
ThinkRAG se desarrolla utilizando el marco de datos LlamaIndex y utiliza Streamlit para el front-end. El modo de desarrollo y el modo de producción del sistema utilizan diferentes componentes técnicos respectivamente, como se muestra en la siguiente tabla:
| modo de desarrollo | modo de producción | |
|---|---|---|
| marco GAR | LlamaIndex | LlamaIndex |
| marco frontal | iluminado | iluminado |
| modelo integrado | BAAI/bge-small-zh-v1.5 | BAAI/bge-grande-zh-v1.5 |
| reorganizar el modelo | BAAI/bge-reranker-base | BAAI/bge-reranker-grande |
| divisor de texto | Divisor de oraciones | Divisor de texto espacial |
| Almacenamiento de conversaciones | SimpleChatStore | Redis |
| Almacenamiento de documentos | Tienda de documentos simple | Redis |
| Almacenamiento de índice | SimpleIndexStore | Redis |
| almacenamiento de vectores | SimpleVectorStore | LanzaDB |
Estos componentes técnicos están diseñados arquitectónicamente de acuerdo con seis partes: interfaz, marco, modelo grande, herramientas, almacenamiento e infraestructura.
Como se muestra a continuación:
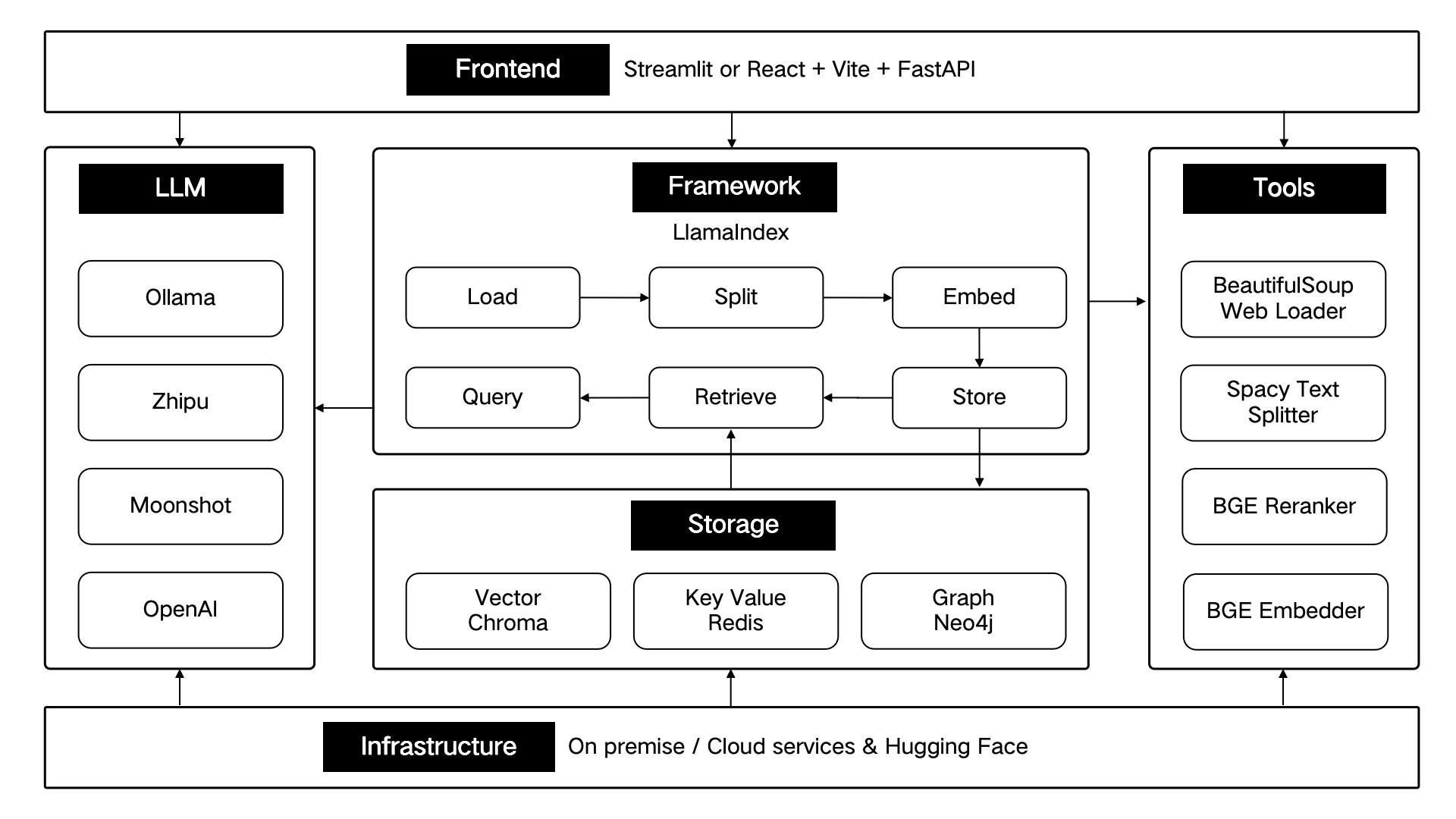
ThinkRAG continuará optimizando las funciones principales y mejorando la eficiencia y precisión de la recuperación, incluyendo principalmente:
Al mismo tiempo, mejoraremos aún más la arquitectura de la aplicación y mejoraremos la experiencia del usuario, incluyendo principalmente:
¡Le invitamos a unirse al proyecto de código abierto ThinkRAG y trabajar juntos para crear productos de IA que adoren a los usuarios!
ThinkRAG utiliza la licencia MIT.


