lance
v0.20.0

Formato de datos en columnas moderno para ML. Convierta desde Parquet en 2 líneas de código para un acceso aleatorio 100 veces más rápido, un índice vectorial, control de versiones de datos y más.
Compatible con pandas, DuckDB, Polars y pyarrow con más integraciones en camino.
Documentación • Blog • Discord • Twitter
Lance es un formato de datos en columnas moderno que está optimizado para conjuntos de datos y flujos de trabajo de aprendizaje automático. Lanza es perfecta para:
Las características clave de Lance incluyen:
Acceso aleatorio de alto rendimiento: 100 veces más rápido que Parquet sin sacrificar el rendimiento del escaneo.
Búsqueda de vectores: encuentre vecinos más cercanos en milisegundos y combine consultas OLAP con búsqueda de vectores.
Control de versiones automático y sin copia: administre versiones de sus datos sin necesidad de infraestructura adicional.
Integraciones de ecosistemas: Apache Arrow, Pandas, Polars, DuckDB y más en camino.
Consejo
Lance está en desarrollo activo y agradecemos las contribuciones. Consulte nuestra guía de contribución para obtener más información.
Instalación
pip install pylancePara instalar una versión preliminar:
pip install --pre --extra-index-url https://pypi.fury.io/lancedb/ pylanceConsejo
Las versiones preliminares se publican con más frecuencia que las versiones completas y contienen las últimas funciones y correcciones de errores. Reciben el mismo nivel de pruebas que las versiones completas. Garantizamos que permanecerán publicados y disponibles para su descarga durante al menos 6 meses. Cuando desee fijar una versión específica, prefiera una versión estable.
Convirtiendo a lanza
import lance
import pandas as pd
import pyarrow as pa
import pyarrow . dataset
df = pd . DataFrame ({ "a" : [ 5 ], "b" : [ 10 ]})
uri = "/tmp/test.parquet"
tbl = pa . Table . from_pandas ( df )
pa . dataset . write_dataset ( tbl , uri , format = 'parquet' )
parquet = pa . dataset . dataset ( uri , format = 'parquet' )
lance . write_dataset ( parquet , "/tmp/test.lance" )Lectura de datos de lanza
dataset = lance . dataset ( "/tmp/test.lance" )
assert isinstance ( dataset , pa . dataset . Dataset )pandas
df = dataset . to_table (). to_pandas ()
dfPatoDB
import duckdb
# If this segfaults, make sure you have duckdb v0.7+ installed
duckdb . query ( "SELECT * FROM dataset LIMIT 10" ). to_df ()Búsqueda de vectores
Descargue el subconjunto sift1m
wget ftp://ftp.irisa.fr/local/texmex/corpus/sift.tar.gz
tar -xzf sift.tar.gzConviértelo en lanza
import lance
from lance . vector import vec_to_table
import numpy as np
import struct
nvecs = 1000000
ndims = 128
with open ( "sift/sift_base.fvecs" , mode = "rb" ) as fobj :
buf = fobj . read ()
data = np . array ( struct . unpack ( "<128000000f" , buf [ 4 : 4 + 4 * nvecs * ndims ])). reshape (( nvecs , ndims ))
dd = dict ( zip ( range ( nvecs ), data ))
table = vec_to_table ( dd )
uri = "vec_data.lance"
sift1m = lance . write_dataset ( table , uri , max_rows_per_group = 8192 , max_rows_per_file = 1024 * 1024 )Construir el índice
sift1m . create_index ( "vector" ,
index_type = "IVF_PQ" ,
num_partitions = 256 , # IVF
num_sub_vectors = 16 ) # PQBuscar en el conjunto de datos
# Get top 10 similar vectors
import duckdb
dataset = lance . dataset ( uri )
# Sample 100 query vectors. If this segfaults, make sure you have duckdb v0.7+ installed
sample = duckdb . query ( "SELECT vector FROM dataset USING SAMPLE 100" ). to_df ()
query_vectors = np . array ([ np . array ( x ) for x in sample . vector ])
# Get nearest neighbors for all of them
rs = [ dataset . to_table ( nearest = { "column" : "vector" , "k" : 10 , "q" : q })
for q in query_vectors ]| Directorio | Descripción |
|---|---|
| óxido | Implementación de Core Rust |
| pitón | Enlaces de Python (pyo3) |
| documentos | Fuente de documentación |
Aquí destacaremos algunos aspectos del diseño de Lance. Para obtener más detalles, consulte el documento de diseño completo de Lance.
Índice de vectores : índice de vectores para búsqueda de similitudes en el espacio de incrustación. Admite CPU ( x86_64 y arm ) y GPU ( Nvidia (cuda) y Apple Silicon (mps) ).
Codificaciones : para lograr un escaneo de columnas rápido y consultas de puntos sublineales, Lance utiliza codificaciones y diseños personalizados.
Campos anidados : Lance almacena cada subcampo como una columna separada para admitir filtros eficientes como "buscar imágenes donde los objetos detectados incluyan gatos".
Control de versiones : se puede utilizar un manifiesto para grabar instantáneas. Actualmente admitimos la creación automática de nuevas versiones mediante anexos, sobrescrituras y creación de índices.
Actualizaciones rápidas (ROADMAP): las actualizaciones se admitirán mediante registros de escritura anticipada.
Índices secundarios ricos (ROADMAP):
Utilizamos el conjunto de datos SIFT para comparar nuestros resultados con 1 millón de vectores de 128D.
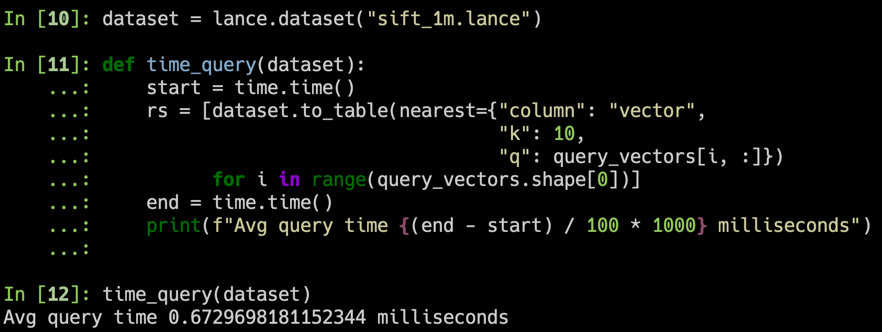
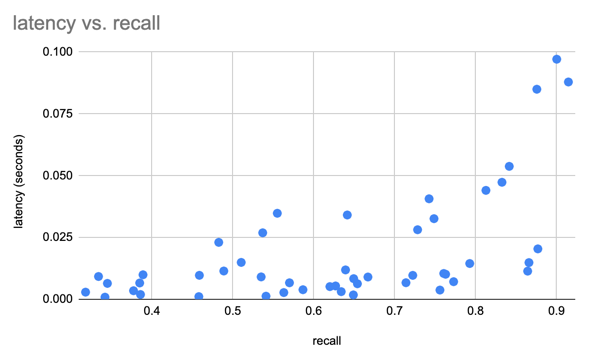
Creamos un conjunto de datos de Lance utilizando el conjunto de datos de Oxford Pet para realizar algunas pruebas preliminares de rendimiento de Lance en comparación con Parquet y imágenes sin formato/XML. Para consultas de análisis, Lance es entre 50 y 100 veces mejor que leer los metadatos sin procesar. Para el acceso aleatorio por lotes, Lance es 100 veces mejor que los archivos de parquet y sin formato.

El ciclo de desarrollo del aprendizaje automático implica los pasos:
gráfico LR
A[Colección] --> B[Exploración];
B --> C[Análisis];
C --> D[Ingeniero de funciones];
D --> E[Entrenamiento];
E --> F[Evaluación];
F --> C;
E --> G[Implementación];
G --> H[Monitoreo];
H --> A;
Las personas utilizan diferentes representaciones de datos en distintas etapas del rendimiento o están limitadas por las herramientas disponibles. El mundo académico utiliza principalmente XML/JSON para anotaciones e imágenes comprimidas/datos de sensores para el aprendizaje profundo, que es difícil de integrar en la infraestructura de datos y lento de entrenar en el almacenamiento en la nube. Si bien la industria utiliza lagos de datos (técnicas basadas en Parquet, es decir, Delta Lake, Iceberg) o almacenes de datos (AWS Redshift o Google BigQuery) para recopilar y analizar datos, tienen que convertir los datos en formatos aptos para la capacitación, como Rikai/ Petastorm o TFRecord. Múltiples transformaciones de datos con un solo propósito, así como la sincronización de copias entre el almacenamiento en la nube y las instancias de capacitación locales, se han convertido en una práctica común.
Si bien cada uno de los formatos de datos existentes sobresale en la carga de trabajo para la que fue diseñado originalmente, necesitamos un nuevo formato de datos adaptado a los ciclos de desarrollo de ML de varias etapas para reducir los silos de datos.
Una comparación de diferentes formatos de datos en cada etapa del ciclo de desarrollo de ML.
| Lanza | Parquet y ORC | JSON y XML | TFRegistro | Base de datos | Depósito | |
|---|---|---|---|---|---|---|
| Analítica | Rápido | Rápido | Lento | Lento | Decente | Rápido |
| Ingeniería de características | Rápido | Rápido | Decente | Lento | Decente | Bien |
| Capacitación | Rápido | Decente | Lento | Rápido | N / A | N / A |
| Exploración | Rápido | Lento | Rápido | Lento | Rápido | Decente |
| Soporte de infraestructura | Rico | Rico | Decente | Limitado | Rico | Rico |
Actualmente, Lance se utiliza en producción por:


