duplicut
v2.2 release
Hoy en día, la creación de listas de palabras de contraseñas suele implicar la concatenación de múltiples fuentes de datos.
Idealmente, las contraseñas más probables deberían estar al comienzo de la lista de palabras, de modo que las contraseñas más comunes se descifren instantáneamente.
Con las herramientas de deduplicación existentes, se ve obligado a elegir si prefiere conservar el orden O manejar listas de palabras masivas .
Desafortunadamente, la creación de una lista de palabras requiere ambos :

Entonces, ¿escribí duplicut en C altamente optimizado para abordar esta necesidad tan específica?
git clone https://github.com/nil0x42/duplicut
cd duplicut/ && make
./duplicut wordlist.txt -o clean-wordlist.txt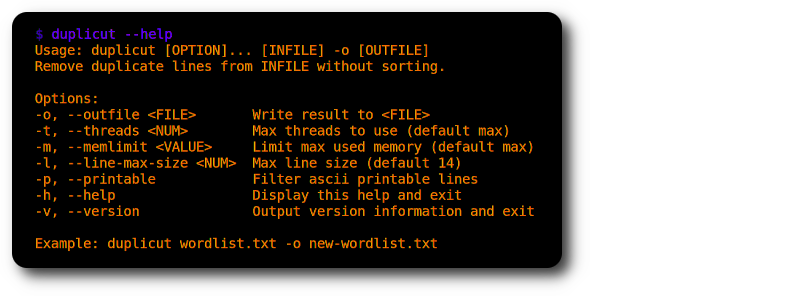
Características :
-l )-p )Implementación :
Limitaciones :
Un uint64 es suficiente para indexar líneas en hashmap, empaquetando información size dentro de los bits adicionales del puntero:
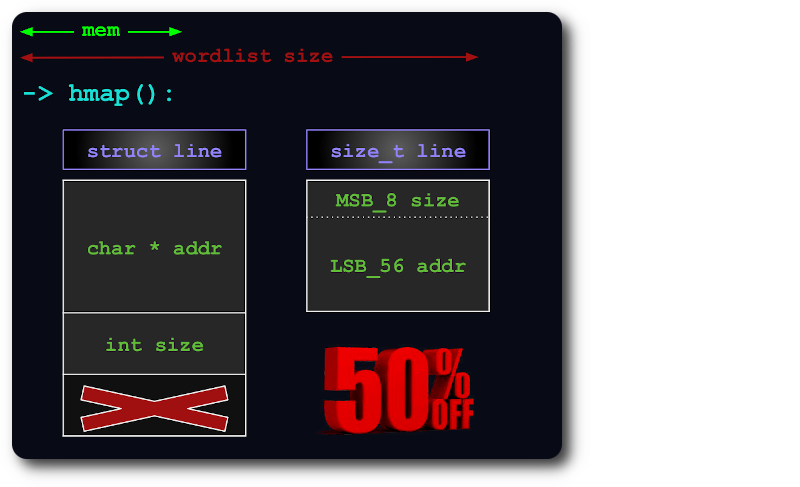
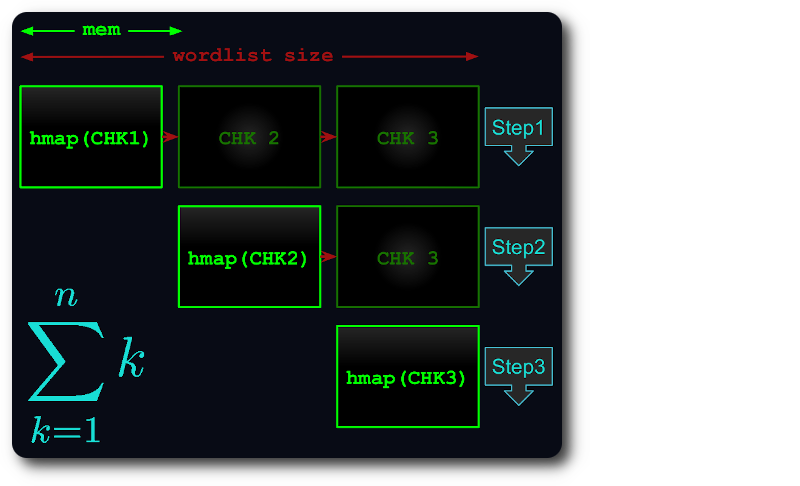
Si el archivo completo no cabe en la memoria, se divide en fragmentos virtuales, de tal manera que cada fragmento utilice tanta RAM como sea posible.
Luego, cada fragmento se carga en hashmap, se deduplica y se prueba con fragmentos posteriores.
De esta manera, el tiempo de ejecución disminuye como máximo hasta el número del triángulo :
Si encuentra un error o algo no funciona como se esperaba, compile duplicut en modo de depuración y publique un problema con el resultado adjunto:
# debug level can be from 1 to 4
make debug level=1
./duplicut [OPTIONS] 2>&1 | tee /tmp/duplicut-debug.log


