LLaMA_MPS
1.0.0
Ejecute la inferencia de LLaMA (y Stanford-Alpaca) en las GPU de Apple Silicon.
Como puede ver, a diferencia de otros LLM, ¿LLaMA no está sesgado de ninguna manera?
1. Clona este repositorio
git clone https://github.com/jankais3r/LLaMA_MPS
2. Instalar dependencias de Python
cd LLaMA_MPS
pip3 install virtualenv
python3 -m venv env
source env/bin/activate
pip3 install -r requirements.txt
pip3 install -e . 3. Descargue los pesos de los modelos y colóquelos en una carpeta llamada models (por ejemplo, LLaMA_MPS/models/7B ).
4. (Opcional) Vuelva a endurecer los pesos del modelo (13B/30B/65B)
Dado que estamos ejecutando la inferencia en una sola GPU, necesitamos fusionar los pesos de los modelos más grandes en un solo archivo.
mv models/13B models/13B_orig
mkdir models/13B
python3 reshard.py 1 models/13B_orig models/13B5. Ejecute la inferencia
python3 chat.py --ckpt_dir models/13B --tokenizer_path models/tokenizer.model --max_batch_size 8 --max_seq_len 256
Los pasos anteriores le permitirán ejecutar inferencias en el modelo LLaMA sin procesar en un modo de "autocompletar".
Si desea probar el modo de 'instrucción-respuesta' similar a ChatGPT utilizando los pesos ajustados de Stanford Alpaca, continúe la configuración con los siguientes pasos:
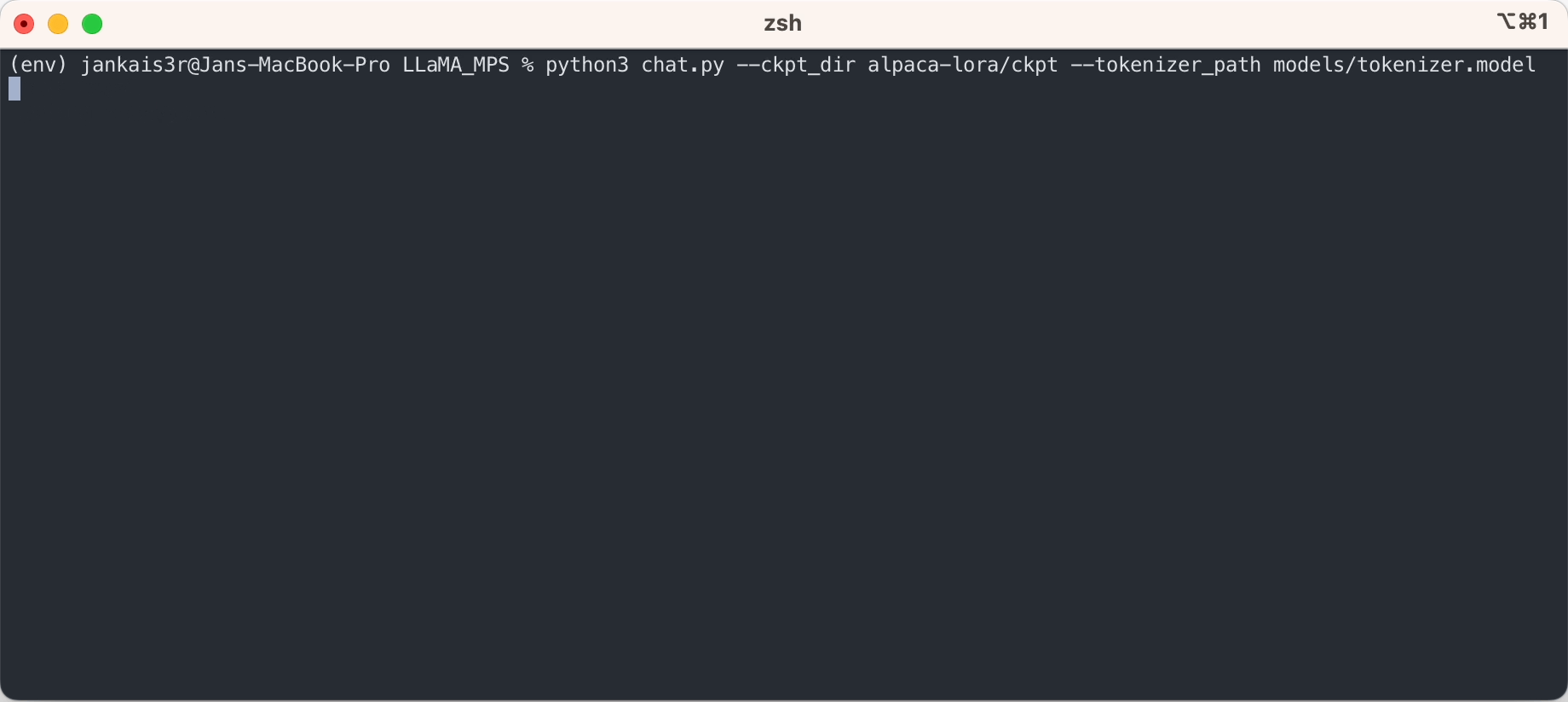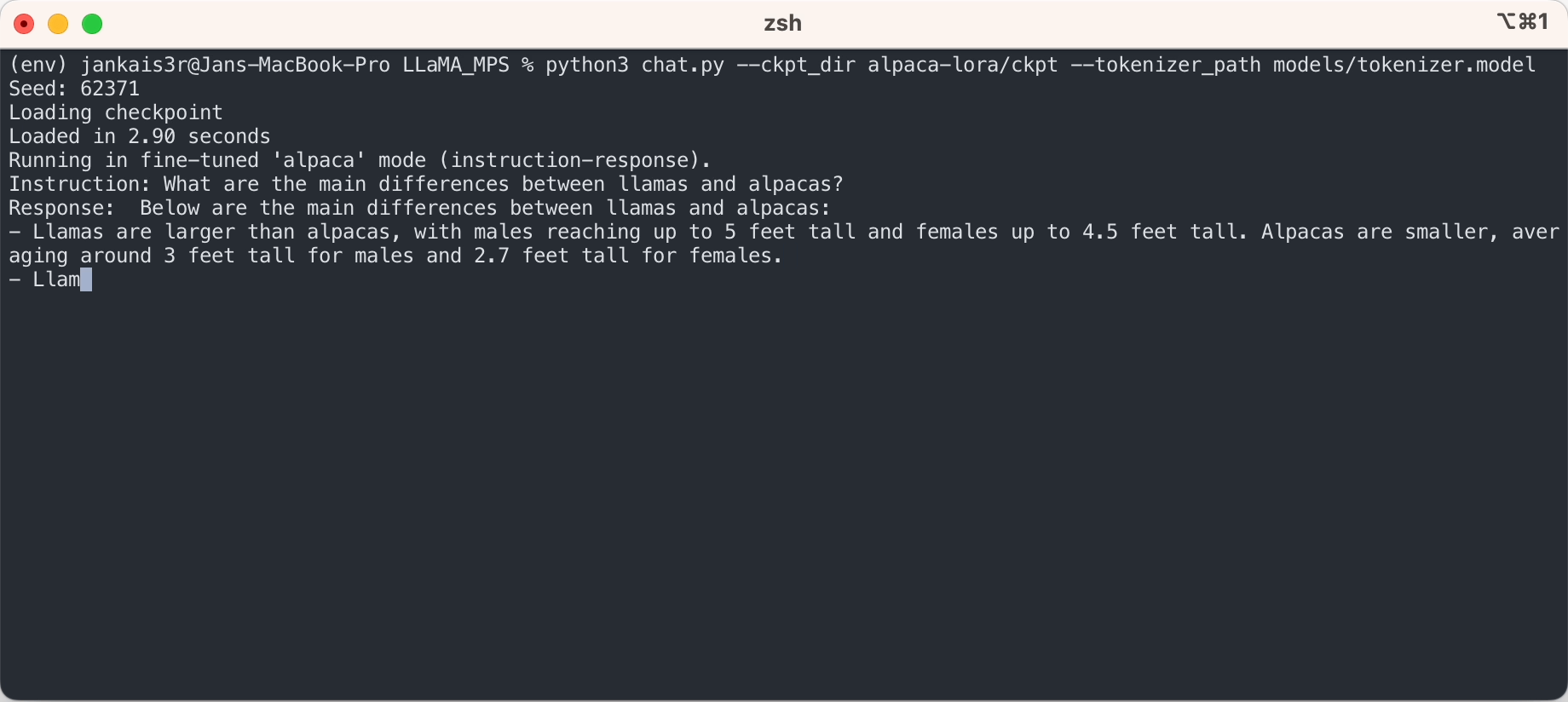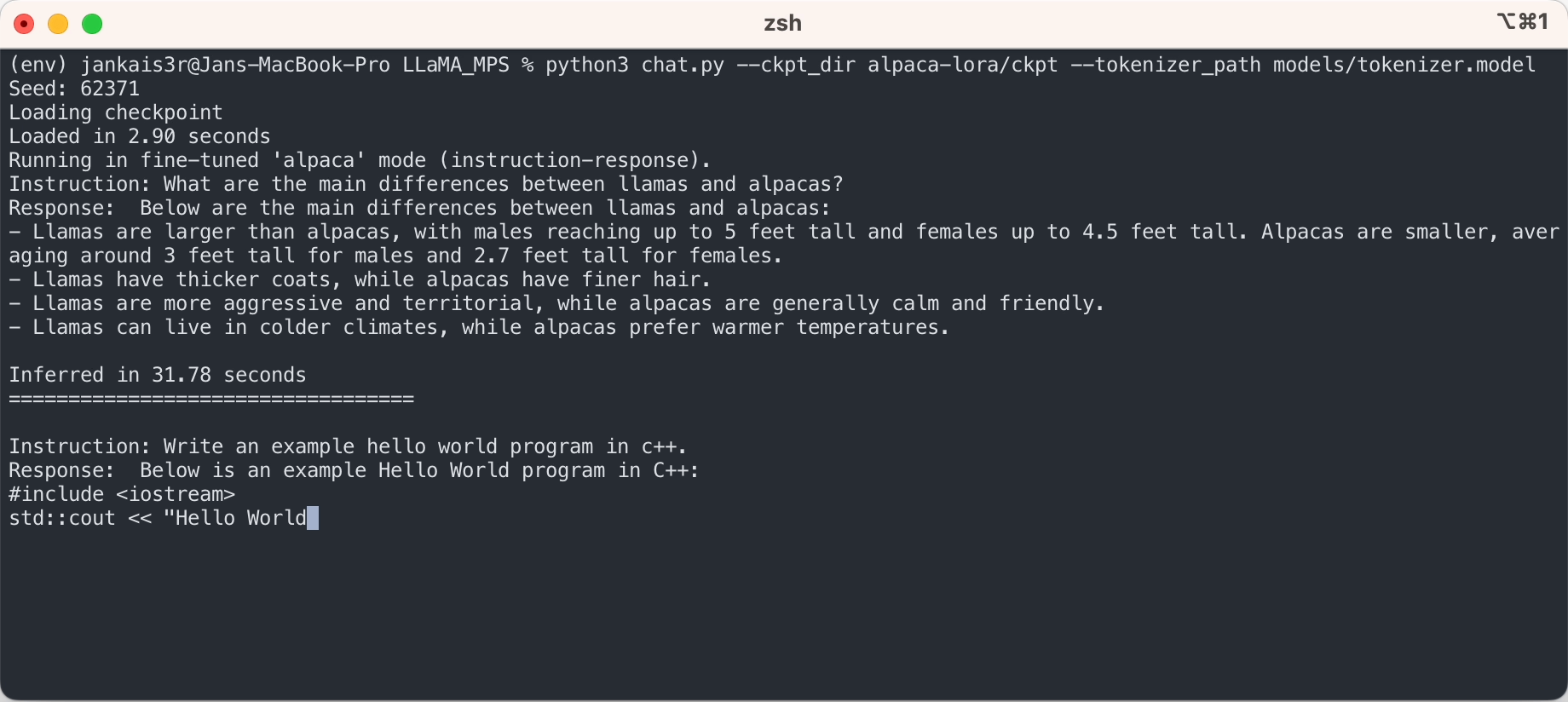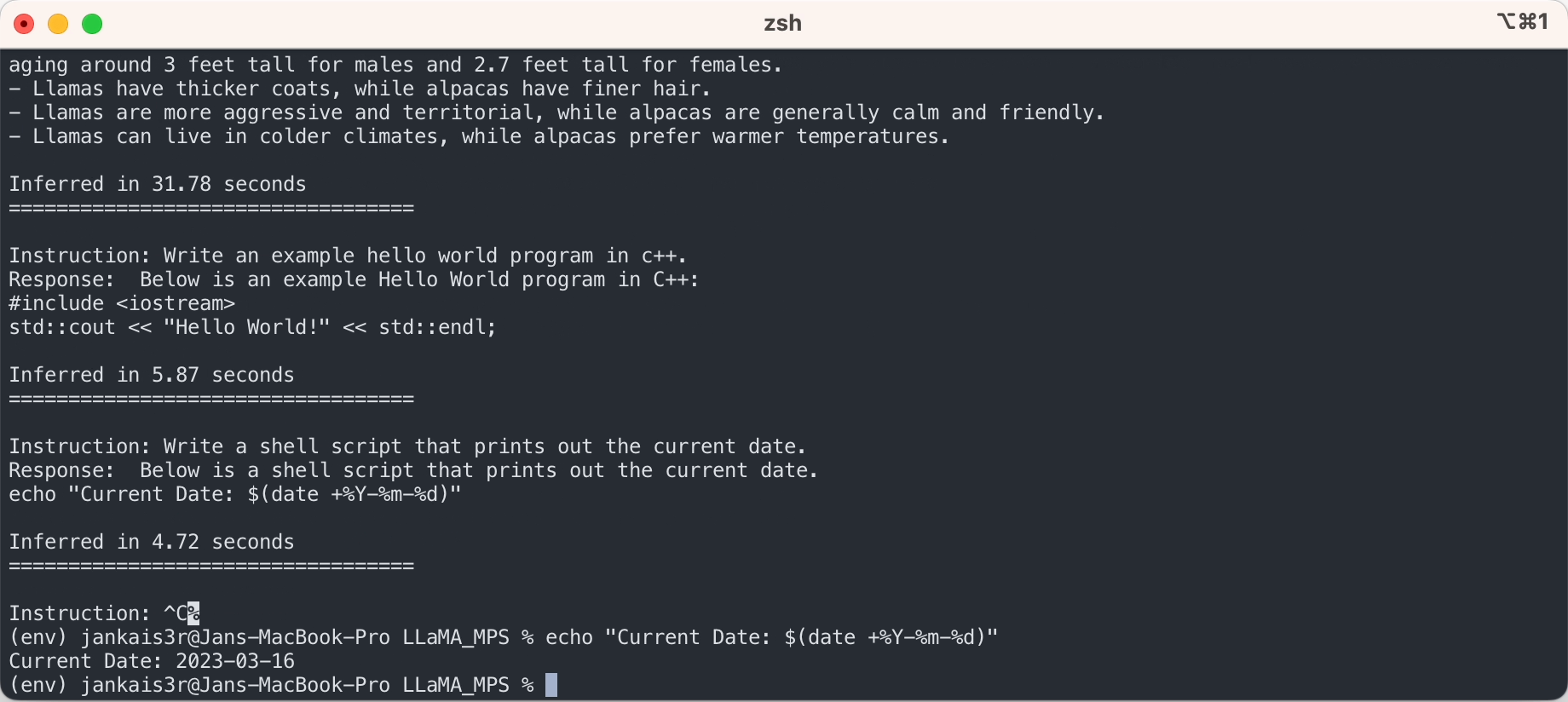
3. Descargue los pesos ajustados (disponibles para 7B/13B)
python3 export_state_dict_checkpoint.py 7B
python3 clean_hf_cache.py4. Ejecute la inferencia
python3 chat.py --ckpt_dir models/7B-alpaca --tokenizer_path models/tokenizer.model --max_batch_size 8 --max_seq_len 256
| Modelo | Iniciar la memoria durante la inferencia | Memoria máxima durante la conversión del punto de control | Memoria máxima durante la reconstrucción |
|---|---|---|---|
| 7B | 16GB | 14GB | N / A |
| 13B | 32GB | 37GB | 45GB |
| 30B | 66GB | 76GB | 125GB |
| 65B | ?? ES | ?? ES | ?? ES |
Especificaciones mínimas por modelo (lentas debido al intercambio):
Especificaciones recomendadas por modelo:
- tamaño_max_batch
Si tiene memoria adicional (por ejemplo, cuando ejecuta el modelo 13B en una Mac de 64 GB), puede aumentar el tamaño del lote usando el argumento --max_batch_size=32 . El valor predeterminado es 1 .
- max_seq_len
Para aumentar/disminuir la longitud máxima del texto generado, utilice el argumento --max_seq_len=256 . El valor predeterminado es 512 .
- use_repetition_penalty
El script de ejemplo penaliza al modelo por generar contenido repetitivo. Esto debería conducir a una producción de mayor calidad, pero ralentiza ligeramente la inferencia. Ejecute el script con el argumento --use_repetition_penalty=False para desactivar el algoritmo de penalización.
La mejor alternativa a LLaMA_MPS para los usuarios de Apple Silicon es llama.cpp, que es una reimplementación de C/C++ que ejecuta la inferencia únicamente en la parte de la CPU del SoC. Debido a que el código C compilado es mucho más rápido que Python, en realidad puede superar esta implementación MPS en velocidad, aunque a costa de una eficiencia energética y térmica mucho peor.
Consulte la siguiente comparación para decidir qué implementación se adapta mejor a su caso de uso.
| Implementación | Tiempo de ejecución total: 256 tokens | Fichas/s | Uso máximo de memoria | Temperatura máxima de SoC | Consumo máximo de energía de SoC | Fichas por 1 Wh |
|---|---|---|---|---|---|---|
| LLAMA_MPS (13B fp16) | 75 segundos | 3.41 | 30 GB | 79 ºC | 10W | 1.228,80 |
| llama.cpp (13B fp16) | años 70 | 3.66 | 25GB | 106ºC | 35W | 376,16 |


