dream
v1.13.0
DeepPavlov Dream es una plataforma para crear asistentes de IA generativa con múltiples habilidades.
Para obtener más información sobre la plataforma y cómo crear asistentes de IA con ella, visite Dream. Si desea obtener más información sobre el Agente DeepPavlov que impulsa Dream, visite la documentación del Agente DeepPavlov.
Ya hemos incluido seis distribuciones: cuatro de ellas se basan en el robot social ligero Deepy, una es un chatbot Dream de tamaño completo (basado en la versión Alexa Prize Challenge) en inglés y un chatbot Dream en ruso.
Versión base del asistente Lunar. Deepy Base contiene un anotador de preprocesamiento ortográfico, una habilidad de mantenimiento de cosechadores basada en plantillas y una habilidad de programa de dominio abierto basada en AIML basada en Dialog Flow Framework.
Versión avanzada del asistente Lunar. Deepy Advanced contiene anotadores de preprocesamiento ortográfico, segmentación de oraciones, vinculación de entidades y captador de intenciones, habilidad GoBot de mantenimiento de cosechadores para respuestas orientadas a objetivos y habilidad de programa de dominio abierto basada en AIML basada en Dialog Flow Framework.
Versión de preguntas frecuentes del asistente Lunar. Las preguntas frecuentes de Deepy contienen un anotador de preprocesamiento ortográfico, una habilidad de preguntas frecuentes basada en plantillas y una habilidad de programa de dominio abierto basada en AIML basada en Dialog Flow Framework.
Versión orientada a objetivos del asistente Lunar. Deepy GoBot Base contiene un anotador de preprocesamiento ortográfico, una habilidad GoBot de mantenimiento de cosechadores para respuestas orientadas a objetivos y una habilidad de programa de dominio abierto basada en AIML basada en Dialog Flow Framework.
Versión completa de DeepPavlov Dream Socialbot. Esta es casi la misma versión del socialbot DREAM que al final del Alexa Prize Challenge 4. Algunos servicios API se reemplazan con modelos entrenables. Algunos servicios (por ejemplo, News Annotator, Game Skill, Weather Skill) requieren claves privadas para las API subyacentes; la mayoría de ellas se pueden obtener de forma gratuita. Si desea utilizar estos servicios en implementaciones locales, agregue sus claves a las variables ambientales (por ejemplo, ./.env , ./.env_ru ). Esta versión de Dream Socialbot consume muchos recursos debido a su arquitectura modular y objetivos originales (participación en Alexa Prize Challenge). Ofrecemos una demostración de Dream Socialbot en nuestro sitio web.
Mini versión de DeepPavlov Dream Socialbot. Este es un robot social generativo que utiliza el modelo DialoGPT en inglés para generar la mayoría de las respuestas. También contiene componentes de receptor de intenciones y de respuesta para cubrir solicitudes especiales de los usuarios. Enlace a la distribución.
Versión rusa de DeepPavlov Dream Socialbot. Este es un robot social generativo que utiliza el DialoGPT ruso de DeepPavlov para generar la mayoría de las respuestas. También contiene componentes de receptor de intenciones y de respuesta para cubrir solicitudes especiales de los usuarios. Enlace a la distribución.
Versión mini de DeepPavlov Dream Socialbot con el uso de modelos generativos basados en indicaciones. Se trata de un robot social de base generativa que utiliza grandes modelos de lenguaje para generar la mayoría de las respuestas. Puede cargar sus propios mensajes (archivos json) en common/prompts, agregar nombres de mensajes a PROMPTS_TO_CONSIDER (separados por comas) y la información proporcionada se utilizará en la generación de respuestas impulsada por LLM como un mensaje. Enlace a la distribución.
docker de 20 y superior;docker-compose v1.29.2; git clone https://github.com/deeppavlov/dream.git
Si recibe un error de "Permiso denegado" al ejecutar docker-compose, asegúrese de configurar su usuario de Docker correctamente.
docker-compose -f docker-compose.yml -f assistant_dists/deepy_base/docker-compose.override.yml up --build
docker-compose -f docker-compose.yml -f assistant_dists/deepy_adv/docker-compose.override.yml up --build
docker-compose -f docker-compose.yml -f assistant_dists/deepy_faq/docker-compose.override.yml up --build
docker-compose -f docker-compose.yml -f assistant_dists/deepy_gobot_base/docker-compose.override.yml up --build
La forma más sencilla de probar Dream es implementarlo mediante proxy. Todas las solicitudes se redireccionarán a la API de DeepPavlov, por lo que no es necesario utilizar ningún recurso local. Consulte el uso de proxy para obtener más detalles.
docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml -f assistant_dists/dream/proxy.yml up --build
Tenga en cuenta que los componentes de DeepPavlov Dream requieren muchos recursos. Consulte la sección de componentes para ver los requisitos estimados.
docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml up --build
También incluimos una configuración con asignaciones de GPU para entornos de múltiples GPU:
AGENT_PORT=4242 docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml -f assistant_dists/dream/test.yml up
Cuando necesite reiniciar un contenedor acoplable en particular sin reconstruirlo (asegúrese de que la asignación en assistant_dists/dream/dev.yml sea correcta):
AGENT_PORT=4242 docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml restart container-name
docker-compose -f docker-compose.yml -f assistant_dists/dream_persona_prompted/docker-compose.override.yml -f assistant_dists/dream_persona_prompted/dev.yml -f assistant_dists/dream_persona_prompted/proxy.yml up --build
También incluimos una configuración con asignaciones de GPU para entornos de múltiples GPU.
El agente DeepPavlov proporciona varias opciones de interacción: una interfaz de línea de comandos, una API HTTP y un bot de Telegram
En una pestaña de terminal separada, ejecute:
docker-compose exec agent python -m deeppavlov_agent.run agent.channel=cmd agent.pipeline_config=assistant_dists/dream/pipeline_conf.json
Ingresa tu nombre de usuario y charla con Dream!
Una vez que haya iniciado el bot, la API del agente de DeepPavlov se ejecutará en http://localhost:4242 . Puede obtener información sobre la API en los documentos del agente de DeepPavlov.
Una interfaz de chat básica estará disponible en http://localhost:4242/chat .
Actualmente, se implementa el bot de Telegram en lugar de la API HTTP. Edite la definición command agent dentro de la configuración docker-compose.override.yml :
agent:
command: sh -c 'bin/wait && python -m deeppavlov_agent.run agent.channel=telegram agent.telegram_token=<TELEGRAM_BOT_TOKEN> agent.pipeline_config=assistant_dists/dream/pipeline_conf.json'
NOTA: ¡trate su token de Telegram como un secreto y no lo envíe a repositorios públicos!
Dream utiliza varios archivos de configuración de Docker-Compose:
./docker-compose.yml es la configuración principal que incluye contenedores para el agente DeepPavlov y la base de datos mongo;
./assistant_dists/*/docker-compose.override.yml enumera todos los componentes de la distribución;
./assistant_dists/dream/dev.yml incluye enlaces de volumen para facilitar la depuración de Dream;
./assistant_dists/dream/proxy.yml es una lista de contenedores proxy.
Si sus recursos de implementación son limitados, puede reemplazar los contenedores con sus copias proxy alojadas en DeepPavlov. Para hacer esto, anule las definiciones de contenedor dentro de proxy.yml , por ejemplo:
convers-evaluator-annotator:
command: ["nginx", "-g", "daemon off;"]
build:
context: dp/proxy/
dockerfile: Dockerfile
environment:
- PROXY_PASS=proxy.deeppavlov.ai:8004
- SERVICE_PORT=8004
e incluya esta configuración en su comando de implementación:
docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml -f assistant_dists/dream/proxy.yml up --build
De forma predeterminada, proxy.yml contiene todas las definiciones de proxy disponibles.
Dream Architecture se presenta en la siguiente imagen: 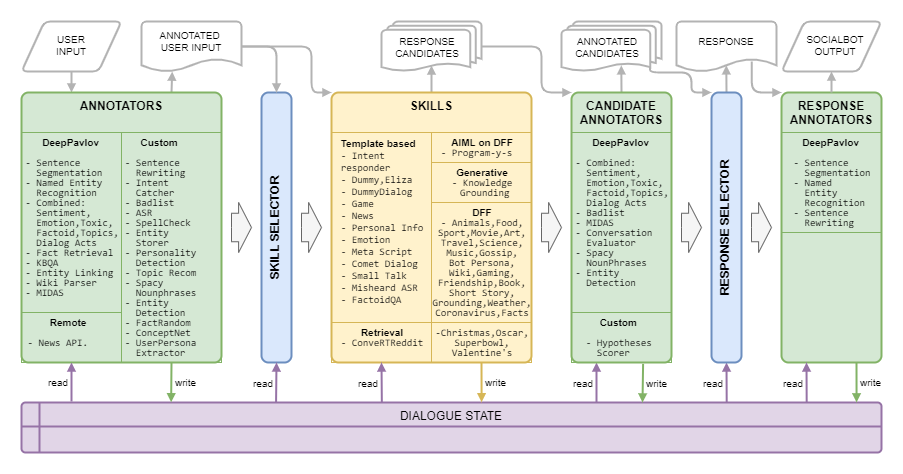
| Nombre | Requisitos | Descripción |
|---|---|---|
| Selector basado en reglas | Algoritmo que selecciona una lista de habilidades para generar respuestas de los candidatos al contexto actual en función de temas, entidades, emociones, toxicidad, actos de diálogo e historial de diálogo. | |
| Selector de respuesta | 50 MB de RAM | Algoritmo que selecciona una respuesta final entre la lista dada de respuestas candidatas |
| Nombre | Requisitos | Descripción |
|---|---|---|
| ASR | 40 MB de RAM | calcula la confianza general de ASR para una expresión determinada y la califica como muy baja , baja , media o alta (para el marcado de Amazon) |
| Palabras mal catalogadas | 150 MB de RAM | detecta palabras y frases de la lista mala |
| Clasificación combinada | 1,5 GB de RAM, 3,5 GB de GPU | Modelo basado en BERT que incluye clasificación de temas, clasificación de actos de diálogo, sentimiento, toxicidad, emoción y clasificación de factoides. |
| Clasificación combinada ligera | 1,6 GB de RAM | El mismo modelo que la Clasificación Combinada, pero tarda un 42% menos gracias a su columna vertebral más ligera |
| COMeT atómico | 2 GB de RAM, 1,1 GB de GPU | Modelos de predicción de sentido común COMeT Atomic |
| COMeT ConceptNet | 2 GB de RAM, 1,1 GB de GPU | Modelos de predicción de sentido común COMeT ConceptNet |
| Anotador del evaluador de Convers | 1 GB de RAM, 4,5 GB de GPU | se entrena con los datos del Premio Alexa de concursos anteriores y predice si la respuesta del candidato es interesante, comprensible, relacionada con el tema, atractiva o errónea |
| Clasificación de emociones | 2,5 GB de RAM | anotador de clasificación de emociones |
| Detección de entidades | 1,5 GB de RAM, 3,2 GB de GPU | extrae entidades y sus tipos de expresiones |
| Vinculación de entidades | 2,5 GB de RAM, 1,3 GB de GPU | encuentra identificadores de entidades de Wikidata para las entidades detectadas con Detección de entidades |
| Almacenador de entidades | 220 MB de RAM | un componente basado en reglas, que almacena entidades de las expresiones del usuario y del socialbot si la expresión de opinión se detecta con patrones o clasificador MIDAS y las guarda junto con la actitud detectada hacia el estado del diálogo |
| Hecho aleatorio | 50 MB de RAM | devuelve hechos aleatorios para la entidad dada (para entidades de la expresión del usuario) |
| Recuperación de hechos | 7,4 GB de RAM, 1,2 GB de GPU | extrae datos de Wikipedia y wikiHow |
| Captador de intenciones | 1,7 GB de RAM, 2,4 GB de GPU | clasifica las expresiones del usuario en una serie de intenciones predefinidas que se entrenan en un conjunto de frases y expresiones regulares |
| KBQA | 2 GB de RAM, 1,4 GB de GPU | responde a las preguntas factoides de los usuarios basadas en Wikidata KB |
| Clasificación MIDAS | 1,1 GB de RAM, 4,5 GB de GPU | Modelo basado en BERT entrenado en un subconjunto de clases semánticas del conjunto de datos MIDAS |
| Predictor MIDAS | 30 MB de RAM | Modelo basado en BERT entrenado en un subconjunto de clases semánticas del conjunto de datos MIDAS |
| NER | 2,2 GB de RAM, 5 GB de GPU | extrae nombres de personas, nombres de ubicaciones y organizaciones de texto sin mayúsculas |
| Anotador de API de noticias | 80 MB de RAM | extrae las últimas noticias sobre entidades o temas utilizando la API de GNews. Las implementaciones de DeepPavlov Dream utilizan nuestra propia clave API. |
| Captador de personalidad | 30 MB de RAM | la habilidad consiste en cambiar la descripción de personalidad del sistema a través de la interfaz de chat, funciona como un comando del sistema, la respuesta es un mensaje similar al del sistema. |
| Selector de mensajes | 50 MB de RAM | Anotador que utiliza Sentence Ranker para clasificar las indicaciones y seleccionar N_SENTENCES_TO_RETURN las indicaciones más relevantes (según las preguntas proporcionadas en las indicaciones) |
| Extracción de propiedad | 6,3 GB de RAM | extrae atributos de usuario de expresiones |
| Palabras clave de comisión | 40 MB de RAM | extrae palabras clave de expresiones con la ayuda del algoritmo RAKE |
| Extractor de persona relativa | 50 MB de RAM | Anotador que utiliza Sentence Ranker para clasificar oraciones personales y seleccionar N_SENTENCES_TO_RETURN las oraciones más relevantes |
| Sentreescribir | 200 MB de RAM | Reescribe las expresiones del usuario reemplazando los pronombres con nombres específicos que brindan información más útil a los componentes posteriores. |
| Sentseg | 1 GB de RAM | nos permite manejar expresiones largas y complejas del usuario dividiéndolas en oraciones y recuperando la puntuación |
| Frases sustantivas espaciosas | 180 MB de RAM | extrae frases nominales usando Spacy y filtra las genéricas |
| Clasificador de funciones de voz | 1,1 GB de RAM, 4,5 GB de GPU | un algoritmo jerárquico basado en varios modelos lineales y un enfoque basado en reglas para la predicción de funciones del habla descrito por Eggins y Slade |
| Predictor de la función del habla | 1,1 GB de RAM, 4,5 GB de GPU | produce probabilidades de funciones del habla que pueden seguir una función del habla predicha por el clasificador de funciones del habla |
| Preprocesamiento ortográfico | 50 MB de RAM | Componente basado en patrones para reescribir diferentes expresiones coloquiales en un estilo de conversación más formal. |
| Recomendación de tema | 40 MB de RAM | ofrece un tema para una mayor conversación utilizando la información sobre los temas discutidos y las preferencias del usuario. La versión actual está basada en personalidades de Reddit (consulte Dream Report para el Premio Alexa 4). |
| Clasificación tóxica | 3,5 GB de RAM, 3 GB de GPU | Modelo de clasificación tóxica de Transformers especificado como PRETRAINED_MODEL_NAME_OR_PATH |
| Extractor de personajes de usuario | 40 MB de RAM | determina a qué categoría de edad pertenece el usuario en función de algunas palabras clave |
| Analizador Wiki | 100 MB de RAM | extrae tripletes de Wikidata para las entidades detectadas con Entity Linking |
| Datos wiki | 1,7 GB de RAM | modelo que extrae hechos relacionados de páginas de Wikipedia y WikiHow |
| Nombre | Requisitos | Descripción |
|---|---|---|
| DiálogoGPT | 1,2 GB de RAM, 2,1 GB de GPU | servicio generativo basado en el modelo generativo de Transformers, el modelo se establece en el argumento de composición de la ventana acoplable PRETRAINED_MODEL_NAME_OR_PATH (por ejemplo, microsoft/DialoGPT-small con 0,2-0,5 segundos en GPU) |
| Basado en DialoGPT Persona | 1,2 GB de RAM, 2,1 GB de GPU | Servicio generativo basado en el modelo generativo de Transformers, el modelo fue entrenado previamente en el conjunto de datos PersonaChat para generar una respuesta condicionada a varias oraciones de la personalidad del socialbot. |
| Subtítulos de imágenes | 4 GB de RAM, 5,4 GB de GPU | crea una representación de texto de una imagen recibida |
| Relleno | 1 GB de RAM, 1,2 GB de GPU | (desactivado pero el código está disponible) servicio generativo basado en el modelo Infilling, para la expresión dada devuelve una expresión donde _ del texto original se reemplaza con tokens generados |
| Fundamento del conocimiento | 2 GB de RAM, 2,1 GB de GPU | Servicio generativo basado en la arquitectura BlenderBot que proporciona una respuesta al contexto teniendo en cuenta un párrafo de texto adicional. |
| LM enmascarado | 1,1 GB de RAM, 1 GB de GPU | (apagado pero el código está disponible) |
| Seq2seq basado en personas | 1,5 GB de RAM, 1,5 GB de GPU | Servicio generativo basado en el modelo Transformers seq2seq, el modelo fue entrenado previamente en el conjunto de datos PersonaChat para generar una respuesta condicionada a varias oraciones de la personalidad del socialbot. |
| Clasificador de oraciones | 1,2 GB de RAM, 2,1 GB de GPU | modelo de clasificación dado como PRETRAINED_MODEL_NAME_OR_PATH que para un par de oraciones devuelve una puntuación flotante de correspondencia |
| HistoriaGPT | 2,6 GB de RAM, 2,15 GB de GPU | Servicio generativo basado en GPT-2 ajustado, para el conjunto de palabras clave dado devuelve una historia corta usando las palabras clave |
| GPT-3.5 | 100 MB de RAM | servicio generativo basado en el servicio API OpenAI, el modelo se establece en el argumento de composición de la ventana acoplable PRETRAINED_MODEL_NAME_OR_PATH (en particular, en este servicio, se usa text-davinci-003 . |
| ChatGPT | 100 MB de RAM | servicio generativo basado en el servicio API OpenAI, el modelo se establece en el argumento de composición de Docker PRETRAINED_MODEL_NAME_OR_PATH (en particular, en este servicio, se usa gpt-3.5-turbo . |
| Historia inmediataGPT | 3 GB de RAM, 4 GB de GPU | servicio generativo basado en GPT-2 ajustado, para el tema dado representado por un sustantivo devuelve una historia corta sobre un tema determinado |
| GPT-J 6B | 1,5 GB de RAM, 24,2 GB de GPU | Servicio generativo basado en el modelo generativo de Transformers, el modelo se establece en el argumento de composición de la ventana acoplable PRETRAINED_MODEL_NAME_OR_PATH (en particular, en este servicio, se utiliza el modelo GPT-J. |
| BLOOMZ 7B | 2,5 GB de RAM, 29 GB de GPU | Servicio generativo basado en el modelo generativo de Transformers, el modelo se establece en el argumento de composición de la ventana acoplable PRETRAINED_MODEL_NAME_OR_PATH (en particular, en este servicio, se utiliza el modelo BLOOMZ-7b1. |
| GPT-JT 6B | 2,5 GB de RAM, 25,1 GB de GPU | Servicio generativo basado en el modelo generativo de Transformers, el modelo se establece en el argumento de composición de la ventana acoplable PRETRAINED_MODEL_NAME_OR_PATH (en particular, en este servicio, se utiliza el modelo GPT-JT. |
| Nombre | Requisitos | Descripción |
|---|---|---|
| Controlador de Alexa | 30 MB de RAM | controlador para varios comandos específicos de Alexa |
| Habilidad navideña | 30 MB de RAM | admite preguntas frecuentes, datos y guiones para Navidad |
| Habilidad de diálogo del cometa | 300 MB de RAM | utiliza el modelo COMeT ConceptNet para expresar una opinión, hacer una pregunta o dar un comentario sobre las acciones del usuario mencionadas en el diálogo |
| Convertir Reddit | 1,2 GB de RAM | utiliza un codificador ConveRT para crear representaciones eficientes de oraciones |
| Habilidad ficticia | una parte del contenedor del agente | una habilidad alternativa con múltiples respuestas candidatas no tóxicas |
| Diálogo de habilidad ficticia | 600 MB de RAM | devuelve el siguiente turno del conjunto de datos del chat temático si la respuesta del usuario a la habilidad ficticia es similar a la respuesta correspondiente en los datos de origen |
| elisa | 30 MB de RAM | Chatbot (https://github.com/wadetb/eliza) |
| Habilidad Emocional | 40 MB de RAM | devuelve respuestas de plantilla a las emociones detectadas por la Clasificación de emociones del anotador de Clasificación combinada |
| Control de calidad factual | 170 MB de RAM | responde preguntas factoides |
| Habilidad cooperativa de juego | 100 MB de RAM | proporciona al usuario una conversación sobre juegos de computadora: las listas de los mejores juegos del año pasado, el mes pasado y la semana pasada |
| Habilidad de mantenimiento de cosechadoras | 30 MB de RAM | Habilidad de mantenimiento de cosechadoras. |
| Habilidad Gobot de mantenimiento de cosechadoras | 30 MB de RAM | Mantenimiento de cosechadoras Habilidad orientada a objetivos |
| Habilidad para fundamentar el conocimiento | 100 MB de RAM | genera una respuesta basada en el historial de diálogo y proporciona conocimientos relacionados con el tema de conversación actual |
| Habilidad de metaguión | 150 MB de RAM | proporciona un diálogo de múltiples turnos en torno a las actividades humanas. La habilidad utiliza el modelo atómico COMeT para generar descripciones y preguntas de sentido común sobre varios aspectos. |
| ASR mal escuchado | 40 MB de RAM | utiliza las anotaciones del procesador ASR para brindar retroalimentación al usuario cuando la confianza de ASR es demasiado baja |
| Habilidad API de noticias | 60 MB de RAM | presenta las últimas noticias mejor valoradas sobre entidades o temas utilizando la API de GNews |
| Habilidad Óscar | 30 MB de RAM | admite preguntas frecuentes, hechos y guiones para Oscar |
| Habilidad de información personal | 40 MB de RAM | Consulta y almacena el nombre del usuario, lugar de nacimiento y ubicación. |
| Programa DFF Y Habilidad | 800 MB de RAM | [Nueva versión DFF] Programa Chatbot Y (https://github.com/keiffster/program-y) adaptado para Dream socialbot |
| Programa DFF Y Habilidad Peligrosa | 100 MB de RAM | [Nueva versión DFF] Programa Chatbot Y (https://github.com/keiffster/program-y) adaptado para Dream socialbot, que contiene respuestas a situaciones peligrosas en un diálogo |
| Programa DFF Y Amplia Habilidad | 110 MB de RAM | [Nueva versión DFF] Programa Chatbot Y (https://github.com/keiffster/program-y) adaptado para Dream socialbot, que incluye solo plantillas muy generales (con menor confianza) |
| Habilidad de charla trivial | 35 MB de RAM | hace preguntas utilizando guiones escritos a mano sobre 25 temas, incluidos, entre otros, el amor, los deportes, el trabajo, las mascotas, etc. |
| Habilidad del SuperBowl | 30 MB de RAM | admite preguntas frecuentes, datos y guiones para el SuperBowl |
| Control de calidad de texto | 1,8 GB de RAM, 2,8 GB de GPU | El servicio encuentra la respuesta a una pregunta factual en el texto. |
| Habilidad del día de San Valentín | 30 MB de RAM | admite preguntas frecuentes, datos y guiones para el día de San Valentín |
| Habilidad de marcado de Wikidata | 100 MB de RAM | genera una expresión utilizando tripletes de Wikidata. No encendido, necesita mejoras. |
| Habilidad de animales DFF | 200 MB de RAM | se crea usando DFF y tiene tres ramas de conversación sobre animales: las mascotas del usuario, las mascotas del socialbot y los animales salvajes. |
| Habilidad artística DFF | 100 MB de RAM | Habilidad basada en DFF para discutir arte |
| Habilidad del libro DFF | 400 MB de RAM | [Nueva versión DFF] detecta títulos de libros y autores mencionados en la expresión del usuario con la ayuda del analizador Wiki y enlaces de entidades y recomienda libros aprovechando la información de la base de datos GoodReads. |
| Habilidad de persona del robot DFF | 150 MB de RAM | tiene como objetivo discutir los favoritos de los usuarios y las 20 cosas más populares con historias cortas que expresan la opinión del socialbot hacia ellos. |
| Habilidad de coronavirus DFF | 110 MB de RAM | [Nueva versión DFF] recupera datos sobre la cantidad de casos y muertes por coronavirus en diferentes ubicaciones obtenidos del Centro de Ciencia e Ingeniería de Sistemas de la Universidad John Hopkins |
| Habilidad alimentaria DFF | 150 MB de RAM | construido con DFF para fomentar la conversación relacionada con la comida |
| Habilidad de amistad DFF | 100 MB de RAM | [Nueva versión de DFF] Habilidad basada en DFF para saludar al usuario al comienzo del diálogo y reenviar al usuario a alguna habilidad escrita |
| Habilidad de hecho divertido de DFF | 100 MB de RAM | [Nueva versión DFF] Cuenta datos curiosos para el usuario |
| Habilidad de juego DFF | 80 MB de RAM | proporciona una discusión sobre videojuegos. Gaming Skill es para una charla más general sobre videojuegos. |
| Habilidad de chisme DFF | 95 MB de RAM | Habilidad basada en DFF para hablar con otras personas sobre noticias sobre ellas |
| Habilidad de imagen DFF | 100 MB de RAM | [Nueva versión DFF] Habilidad con script que, según los subtítulos de la imagen enviada (a partir de anotaciones), responde con respuestas específicas en caso de que se detecten alimentos, animales o personas, y respuestas predeterminadas en caso contrario. |
| Habilidad de plantilla DFF | 50 MB de RAM | [Nueva versión de DFF] Habilidad basada en DFF que proporciona un ejemplo de uso de DFF |
| Habilidad solicitada por la plantilla DFF | 50 MB de RAM | [Nueva versión de DFF] Habilidad basada en DFF que proporciona respuestas generadas por el modelo de lenguaje según indicaciones específicas y el contexto del diálogo. El modelo a utilizar se especifica en GENERATIVE_SERVICE_URL. Por ejemplo, puede utilizar el servicio Transformer LM GPTJ. |
| Habilidad de conexión a tierra DFF | 90 MB de RAM | [Nueva versión DFF] Habilidad basada en DFF para responder cuál es el tema de la conversación, generar reconocimiento, generar respuestas universales sobre algunos actos de diálogo de MIDAS |
| Respondedor de intención de DFF | 100 MB de RAM | [Nueva versión de DFF] proporciona respuestas basadas en plantillas para algunas de las intenciones detectadas por el anotador de Intent Catcher |
| Habilidad de película DFF | 1,1 GB de RAM | se implementa usando DFF y se encarga de las conversaciones relacionadas con películas |
| Habilidad musical DFF | 70 MB de RAM | Habilidad basada en DFF para discutir música |
| Habilidad científica DFF | 90 MB de RAM | Habilidad basada en DFF para discutir ciencia |
| Habilidad de cuento corto DFF | 90 MB de RAM | [Nueva versión DFF] cuenta historias cortas para los usuarios de 3 categorías: (1) cuentos antes de dormir, como fábulas e historias morales, (2) historias de terror y (3) historias divertidas. |
| Habilidad deportiva DFF | 70 MB de RAM | Habilidad basada en DFF para discutir deportes |
| Habilidad de viaje DFF | 70 MB de RAM | Habilidad basada en DFF para discutir viajes |
| Habilidad meteorológica DFF | 1,4 GB de RAM | [Nueva versión de DFF] utiliza el servicio OpenWeatherMap para obtener el pronóstico de la ubicación del usuario |
| Habilidad Wiki DFF | 150 MB de RAM | Se utiliza para crear escenarios con extracción de entidades, llenado de espacios, inserción de hechos y reconocimientos. |
| Nombre | Requisitos | Descripción |
|---|---|---|
| Habilidad de preguntas frecuentes sobre IA | 150 MB de RAM | [Nueva versión DFF] ¡Todo lo que querías saber sobre la IA moderna pero tenías miedo de preguntar! Este asistente de preguntas frecuentes conversa con usted mientras le explica los temas más simples del mundo tecnológico actual. |
| Habilidad de estilista de moda | 150 MB de RAM | [Nueva versión DFF] ¡Manténgase protegido en cada temporada con el Asistente de ropa de Costa Industries! Experimente la máxima comodidad y protección, sin importar el clima. Mantente abrigado en invierno y... |
| Habilidad de la persona soñada | 150 MB de RAM | [Nueva versión de DFF] Habilidad basada en indicaciones que utiliza un servicio generativo determinado para generar respuestas basadas en la indicación dada |
| Habilidad de marketing | 150 MB de RAM | [Nueva versión de DFF] ¡Conéctate con tu audiencia como nunca antes con Marketing AI Assistant! Alcance nuevas alturas de éxito aprovechando el poder de la empatía. Di adios.. |
| Habilidad de cuento de hadas | 150 MB de RAM | [Nueva versión DFF] Este asistente le contará a usted o a sus hijos un cuento de hadas breve pero atractivo. Elige los personajes y el tema y deja el resto a la imaginación de la IA. |
| Habilidad de nutrición | 150 MB de RAM | [Nueva versión DFF] ¡Descubre el secreto para una alimentación saludable con nuestro asistente de IA! Encuentre opciones de alimentos nutritivos para usted y sus seres queridos con facilidad. Dile adiós al estrés a la hora de comer y da la bienvenida a las delicias... |
| Habilidad de coaching de vida | 150 MB de RAM | [Nueva versión DFF] ¡Desbloquea todo tu potencial con el asistente de IA patentado de Rhodes & Co! Alcance el máximo rendimiento en el trabajo y en casa. Ponte en plena forma sin esfuerzo e inspira a otros. |
Kuratov Y. et al. Informe técnico DREAM para el Premio Alexa 2019 //Actas del Premio Alexa. – 2020.
Baymurzina D. et al. Informe técnico DREAM para el Premio Alexa 4 // Actas del Premio Alexa. – 2021.
DeepPavlov Dream tiene licencia Apache 2.0.
Program-y (ver dream/skills/dff_program_y_skill , dream/skills/dff_program_y_wide_skill , dream/skills/dff_program_y_dangerous_skill ) tiene licencia Apache 2.0. Eliza (ver dream/skills/eliza ) tiene licencia MIT.
Para crear un archivo de certificación xlsx con respuestas de bot, puede usar el script xlsx_responder.py ejecutando
docker-compose -f docker-compose.yml -f dev.yml exec -T -u $( id -u ) agent python3
utils/xlsx_responder.py --url http://0.0.0.0:4242
--input ' tests/dream/test_questions.xlsx '
--output ' tests/dream/output/test_questions_output.xlsx '
--cache tests/dream/output/test_questions_output_ $( date --iso-8601=seconds ) .json Asegúrese de que todos los servicios estén implementados. --input : archivo xlsx con preguntas de certificación, --output : archivo xlsx con respuestas de bot, --cache - json , que contiene un marcado detallado y se utiliza para un caché.


