Okapi
1.0.0
Okapi
Modelos de lenguaje grandes adaptados a la instrucción en varios idiomas con aprendizaje reforzado a partir de retroalimentación humana
Este es el repositorio del marco Okapi que presenta recursos y modelos para el ajuste de instrucciones para modelos de lenguaje grandes (LLM) con aprendizaje reforzado a partir de retroalimentación humana (RLHF) en múltiples idiomas. Nuestro marco admite 26 idiomas, incluidos 8 idiomas de altos recursos, 11 idiomas de recursos medios y 7 idiomas de bajos recursos.
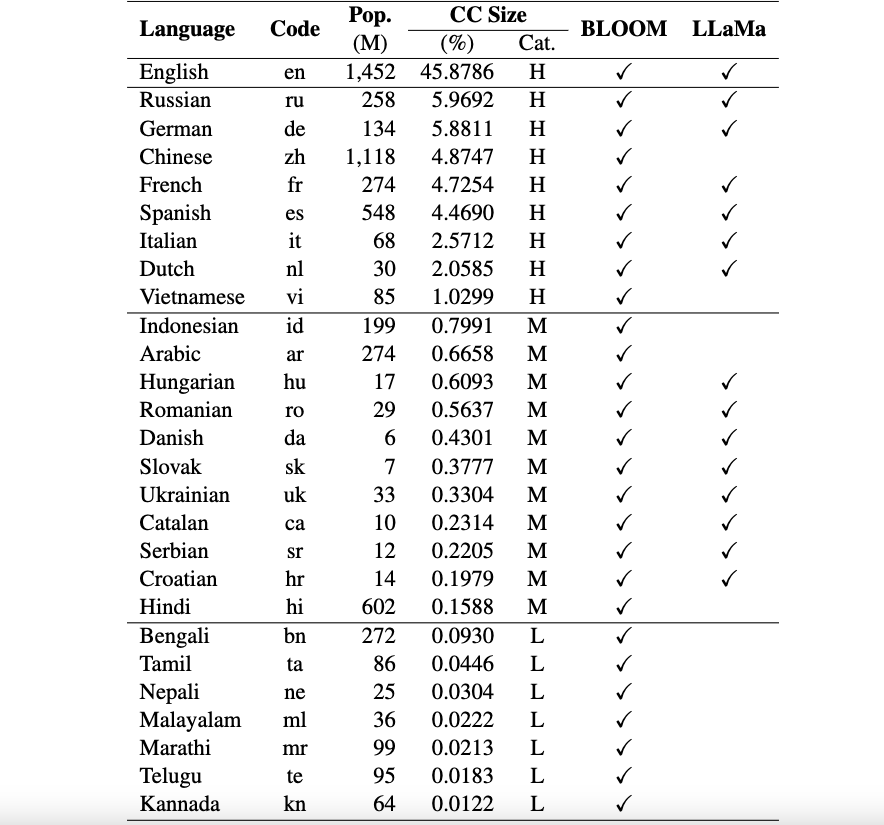
Recursos de Okapi : proporcionamos recursos para realizar ajustes de instrucción con RLHF para 26 idiomas, incluidas indicaciones de ChatGPT, conjuntos de datos de instrucción multilingüe y datos de clasificación de respuestas multilingües.
Modelos Okapi : proporcionamos LLM ajustados por instrucciones basados en RLHF para 26 idiomas en el conjunto de datos de Okapi. Nuestros modelos incluyen versiones basadas en BLOOM y LLaMa. También proporcionamos scripts para interactuar con nuestros modelos y ajustar los LLM con nuestros recursos.
Conjuntos de datos de referencia de evaluación multilingüe : proporcionamos tres conjuntos de datos de referencia para evaluar modelos de lenguajes grandes (LLM) multilingües para 26 idiomas. Puede acceder a los conjuntos de datos completos y los guiones de evaluación: aquí.
Avisos de uso y licencia : Okapi está destinado y tiene licencia para uso en investigación únicamente. Los conjuntos de datos son CC BY NC 4.0 (permite únicamente el uso no comercial) y los modelos entrenados con el conjunto de datos no deben usarse fuera de fines de investigación.
Nuestro documento técnico con los resultados de la evaluación se puede encontrar aquí.
Realizamos un proceso integral de recopilación de datos para preparar los datos necesarios para nuestro marco multilingüe Okapi en cuatro pasos principales:
Para descargar el conjunto de datos completo, puede utilizar el siguiente script:
bash scripts/download.shSi solo necesita los datos de un idioma específico, puede especificar el código del idioma como argumento del script:
bash scripts/download.sh [LANG]
# For example, to download the dataset for Vietnamese: bash scripts/download.sh viDespués de la descarga, nuestros datos publicados se pueden encontrar en el directorio de conjuntos de datos . Incluye:
multilingual-alpaca-52k : Los datos traducidos de 52K instrucciones en inglés en Alpaca a 26 idiomas.
multilingual-ranking-data-42k : datos de clasificación de respuestas multilingües para 26 idiomas. Para cada idioma, proporcionamos 42K instrucciones; cada uno de ellos tiene 4 respuestas clasificadas. Estos datos se pueden utilizar para entrenar modelos de recompensa para 26 idiomas.
multilingual-rl-tuning-64k : los datos de instrucción multilingüe para RLHF. Proporcionamos 62.000 instrucciones para cada uno de los 26 idiomas.
Utilizando nuestros conjuntos de datos de Okapi y la técnica de ajuste de instrucciones basada en RLHF, presentamos LLM multilingües optimizados para 26 idiomas, basados en las versiones 7B de LLaMA y BLOOM. Los modelos se pueden obtener de HuggingFace aquí.
Okapi admite chats interactivos con LLM multilingües adaptados a instrucciones en 26 idiomas. Siguiendo los siguientes pasos para los chats:
git clone https://github.com/nlp-uoregon/Okapi.git
cd Okapi
pip install -r requirements.txt
from chat import pipeline
model_path = 'uonlp/okapi-vi-bloom'
p = pipeline ( model_path , gpu = True )
instruction = 'Dịch câu sau sang Tiếng Việt' # Translate the following sentence into Vietnamese
prompt_input = 'The City of Eugene - a great city for the arts and outdoors. '
response = p . generate ( instruction = instruction , prompt_input = prompt_input )
print ( response )También proporcionamos scripts para ajustar los LLM con nuestros datos de instrucción usando RLHF, cubriendo tres pasos principales: ajuste supervisado, modelado de recompensas y ajuste con RLHF. Utilice los siguientes pasos para ajustar los LLM:
conda create -n okapi python=3.9
conda activate okapi
pip install -r requirements.txtbash scripts/supervised_finetuning.sh [LANG]bash scripts/reward_modeling.sh [LANG]bash scripts/rl_training.sh [LANG]Si utiliza los datos, modelo o código de este repositorio, cite:
@article { dac2023okapi ,
title = { Okapi: Instruction-tuned Large Language Models in Multiple Languages with Reinforcement Learning from Human Feedback } ,
author = { Dac Lai, Viet and Van Nguyen, Chien and Ngo, Nghia Trung and Nguyen, Thuat and Dernoncourt, Franck and Rossi, Ryan A and Nguyen, Thien Huu } ,
journal = { arXiv e-prints } ,
pages = { arXiv--2307 } ,
year = { 2023 }
}

