ChatBot chino/Chatbot chino
- El autor se ha transferido íntegramente a
Dirección de la red neuronal del gráfico GNN El desarrollo de C ++ ya no seguirá la PNL y el código del proyecto dejará de mantenerse. Cuando se completó el proyecto Yuanxiang, había muy pocos recursos en línea. El autor entró en contacto con la PNL y el aprendizaje profundo por primera vez por capricho. Superando muchas dificultades, finalmente escribió este modelo de juguete. Por lo tanto, el autor sabe que no es fácil para los principiantes, por lo que incluso si el proyecto ya no se mantiene, los problemas o correos electrónicos ([email protected]) serán respondidos de manera oportuna para ayudar a los recién llegados al aprendizaje profundo. (La versión de Tensorflow que uso es demasiado antigua. Si ejecuta la nueva versión directamente, definitivamente obtendrá varios errores. Si tiene dificultades, no se moleste en instalar la versión anterior del entorno. Se recomienda utilizar Pytorch para reconstruirlo de acuerdo con mi lógica de procesamiento. Demasiado vago para escribir)
- Aspecto GNN:
- Un conjunto de modelos de comparación de referencia: GNNs-Baseline se ha adaptado y compilado para facilitar la verificación rápida de ideas.
- El código fuente abierto de mi artículo ACMMM 2023 (CCF-A) está aquí LSTGM.
- El código fuente abierto de mi artículo ICDM 2023 (CCF-B) aún se está compilando. . . verde
- Los becarios pueden agregar, comunicarse y aprender.
Configuración del entorno
| programa | Versión |
|---|
| pitón | 3.68 |
| flujo tensor | 1.13.1 |
| Keras | 2.2.4 |
| windows10 | |
| jupyter | |
Principales materiales de referencia.
- Tesis "TRADUCCIÓN MÁQUINA NEURAL APRENDIENDO CONJUNTAMENTE A ALINEAR Y TRADUCIR ( Haga clic en el título para descargar )"
- Diagrama de estructura de atención.
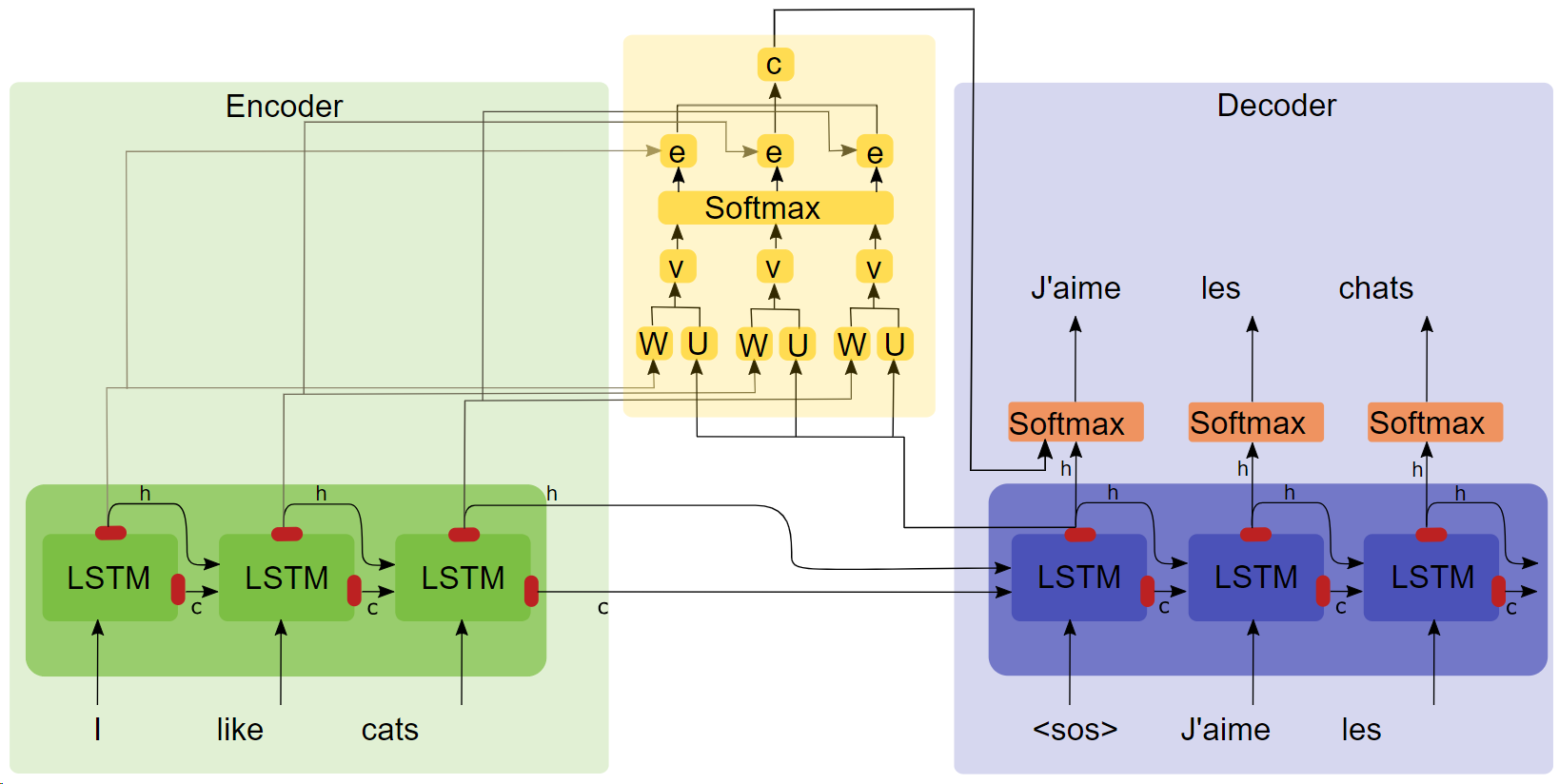
Puntos clave
- LSTM
- seq2seq
- Los experimentos de atención muestran que después de agregar el mecanismo de atención, la velocidad de entrenamiento es más rápida, la convergencia es más rápida y el efecto es mejor.
Corpus y entorno de formación.
100.000 grupos de diálogo del corpus Qingyun, formados en el colaboratorio de Google.
correr
Método 1: proceso completo
- Preprocesamiento de datos
get_data
- Entrenamiento modelo
chatbot_train (Esta es la versión montada en Google Colab, la ruta de ejecución local debe modificarse ligeramente)
- Predicción del modelo
chatbot_inference_Attention
Método 2: cargar un modelo existente
- Ejecute
chatbot_inference_Attention
-
models/W--184-0.5949-.h5
Interfaz (Tkinter)
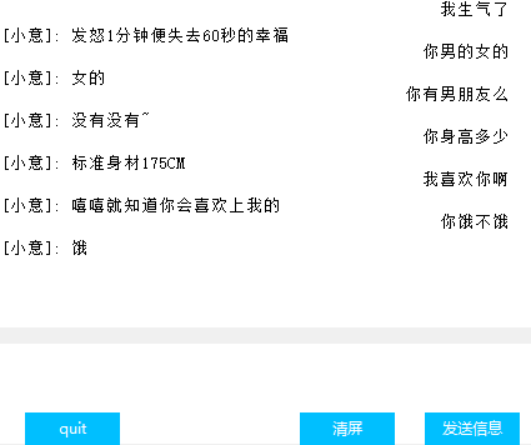
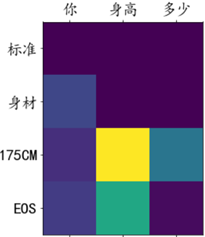
Visualización del peso de atención.
otro
- En el archivo de entrenamiento chat_bot, los dos primeros de los últimos tres bloques de código se usan para montar Google Cloud Disk, y el último se usa para obtener esas pérdidas para facilitar el dibujo, no sé por qué, el tensorbord en la función de devolución de llamada. no funciona, así que se me ocurrió esta estrategia;
- El penúltimo bloque de código en el archivo de predicción solo tiene entrada de texto pero no tiene interfaz. El último bloque de código es la interfaz. Uno de los dos bloques se puede ejecutar inmediatamente según las necesidades.
- Hay muchas salidas intermedias en el código, espero que te ayude a comprender el código;
- Hay un modelo que he entrenado en modelos. No debería haber ningún problema en el funcionamiento normal. También puedes entrenarlo tú mismo.
- El autor tiene una capacidad limitada y no ha encontrado un indicador para cuantificar el efecto del diálogo, por lo que la pérdida sólo puede reflejar de forma aproximada el progreso del entrenamiento.


