MoEL
1.0.0


Esta es la implementación de PyTorch del artículo:
MoEL: mezcla de oyentes empáticos . Zhaojiang Lin , Andrea Madotto, Jamin Shin, Peng Xu, Pascale Fung EMNLP 2019 [PDF]
Este código ha sido escrito usando PyTorch >= 0.4.1. Si utiliza algún código fuente o conjunto de datos incluidos en este kit de herramientas en su trabajo, cite el siguiente documento. El bibtex se enumera a continuación:
@artículo{lin2019moel,
title={MoEL: Mezcla de oyentes empáticos},
autor = {Lin, Zhaojiang y Madotto, Andrea y Shin, Jamin y Xu, Peng y Fung, Pascale},
diario={arXiv preimpresión arXiv:1908.07687},
año={2019}
}
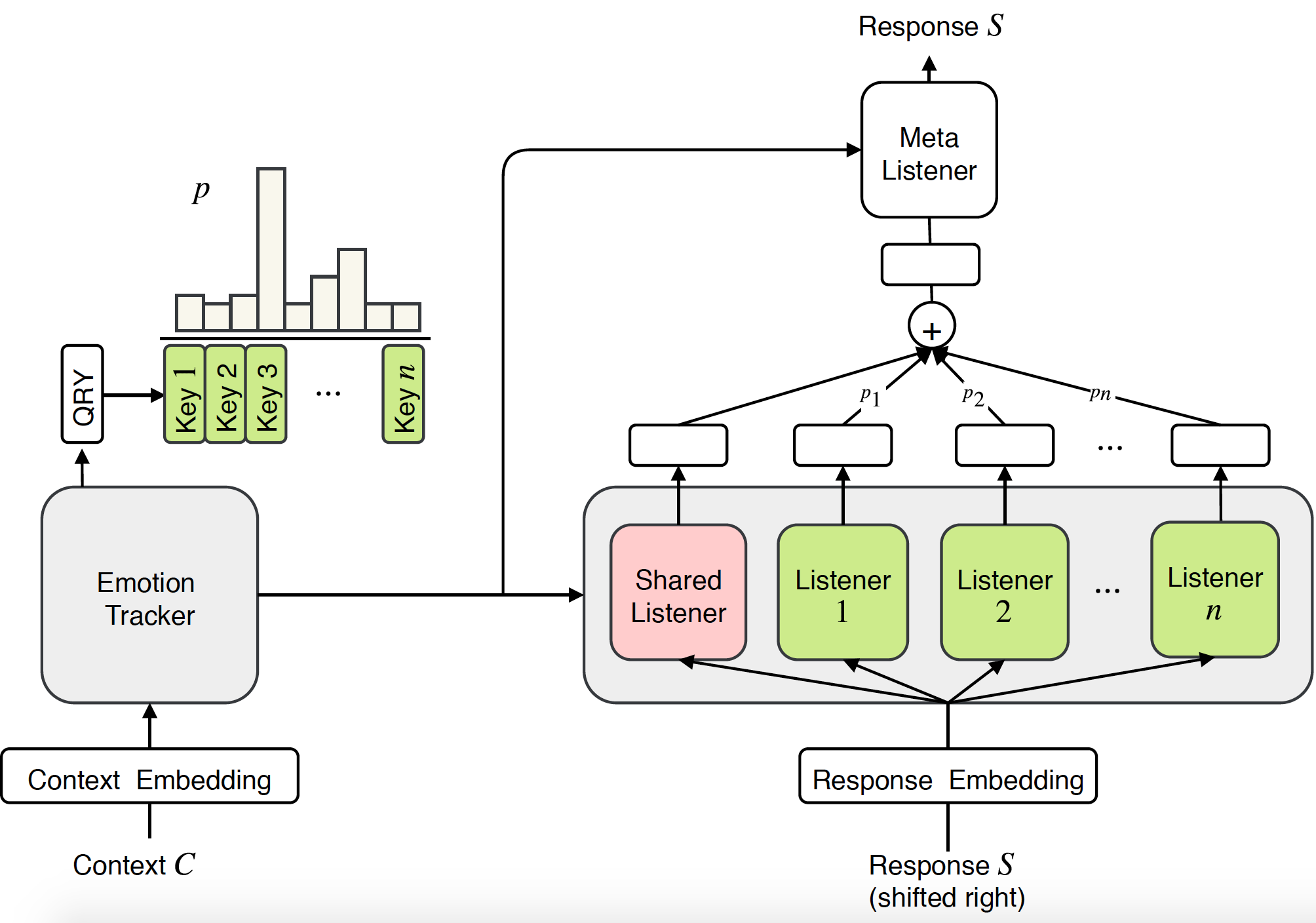
Investigaciones anteriores sobre sistemas de diálogo empático se han centrado principalmente en generar respuestas dadas ciertas emociones. Sin embargo, ser empático no sólo requiere la capacidad de generar respuestas emocionales, sino que, lo que es más importante, requiere comprender las emociones del usuario y responder de manera adecuada. En este artículo, proponemos un enfoque novedoso de un extremo a otro para modelar la empatía en sistemas de diálogo: Mezcla de oyentes empáticos (MoEL). Nuestro modelo primero captura las emociones del usuario y genera una distribución de emociones. En base a esto, MoEL combinará suavemente los estados de salida de los oyentes apropiados, cada uno de los cuales está optimizado para reaccionar a ciertas emociones y generar una respuesta empática. Las evaluaciones humanas sobre el conjunto de datos de diálogos empáticos confirman que MoEL supera la base de entrenamiento multitarea en términos de empatía, relevancia y fluidez. Además, el estudio de caso sobre las respuestas generadas de diferentes oyentes muestra una alta interpretabilidad de nuestro modelo.
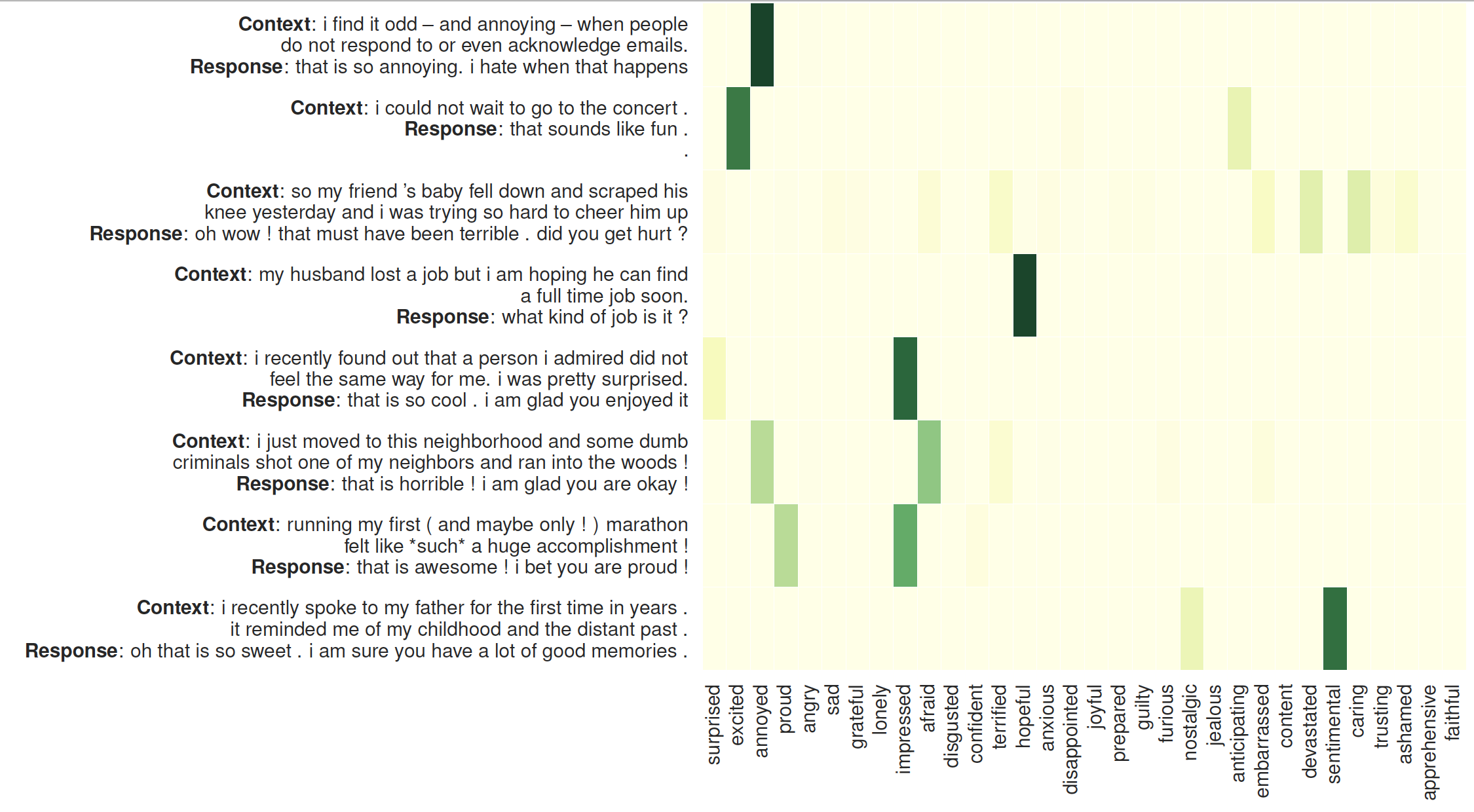
La visualización de la atención de los oyentes: el lado izquierdo es el contexto seguido de las respuestas generadas por MoEL. El mapa de calor ilustra los pesos de atención de 32 oyentes.
Verifique los paquetes necesarios o simplemente ejecute el comando
❱❱❱ pip install -r requirements.txtIncrustación de guantes previamente entrenados : guante.6B.300d.txt dentro de la carpeta /vectors/.
Resultado rápido
Para omitir la capacitación, consulte generate_result.txt .
Conjunto de datos
El conjunto de datos (diálogo empático) se preprocesa y almacena en formato npy: sys_dialog_texts.train.npy, sys_target_texts.train.npy, sys_emotion_texts.train.npy que constan de una lista paralela de contexto (fuente), respuesta (destino) y etiqueta de emoción. (etiqueta adicional).
Entrenamiento y prueba
Moel
❱❱❱ python3 main.py --model experts --label_smoothing --noam --emb_dim 300 --hidden_dim 300 --hop 1 --heads 2 --topk 5 --cuda --pretrain_emb --softmax --basic_learner --schedule 10000 --save_path save/moel/
Línea base del transformador
❱❱❱ python3 main.py --model trs --label_smoothing --noam --emb_dim 300 --hidden_dim 300 --hop 2 --heads 2 --cuda --pretrain_emb --save_path save/trs/
Línea base del transformador multitarea
❱❱❱ python3 main.py --model trs --label_smoothing --noam --emb_dim 300 --hidden_dim 300 --hop 2 --heads 2 --cuda --pretrain_emb --multitask --save_path save/multi-trs/


