MELD
1.0.0
Si está interesado en los LLM sobre pruebas de coeficiente intelectual, consulte nuestro nuevo trabajo: AlgoPuzzleVQA
Hemos publicado las funciones visuales extraídas con Resnet: https://github.com/declare-lab/MM-Align
Para obtener líneas de base actualizadas, visite este enlace: conv-emotion
Para descargar los datos utilice wget: wget http://web.eecs.umich.edu/~mihalcea/downloads/MELD.Raw.tar.gz
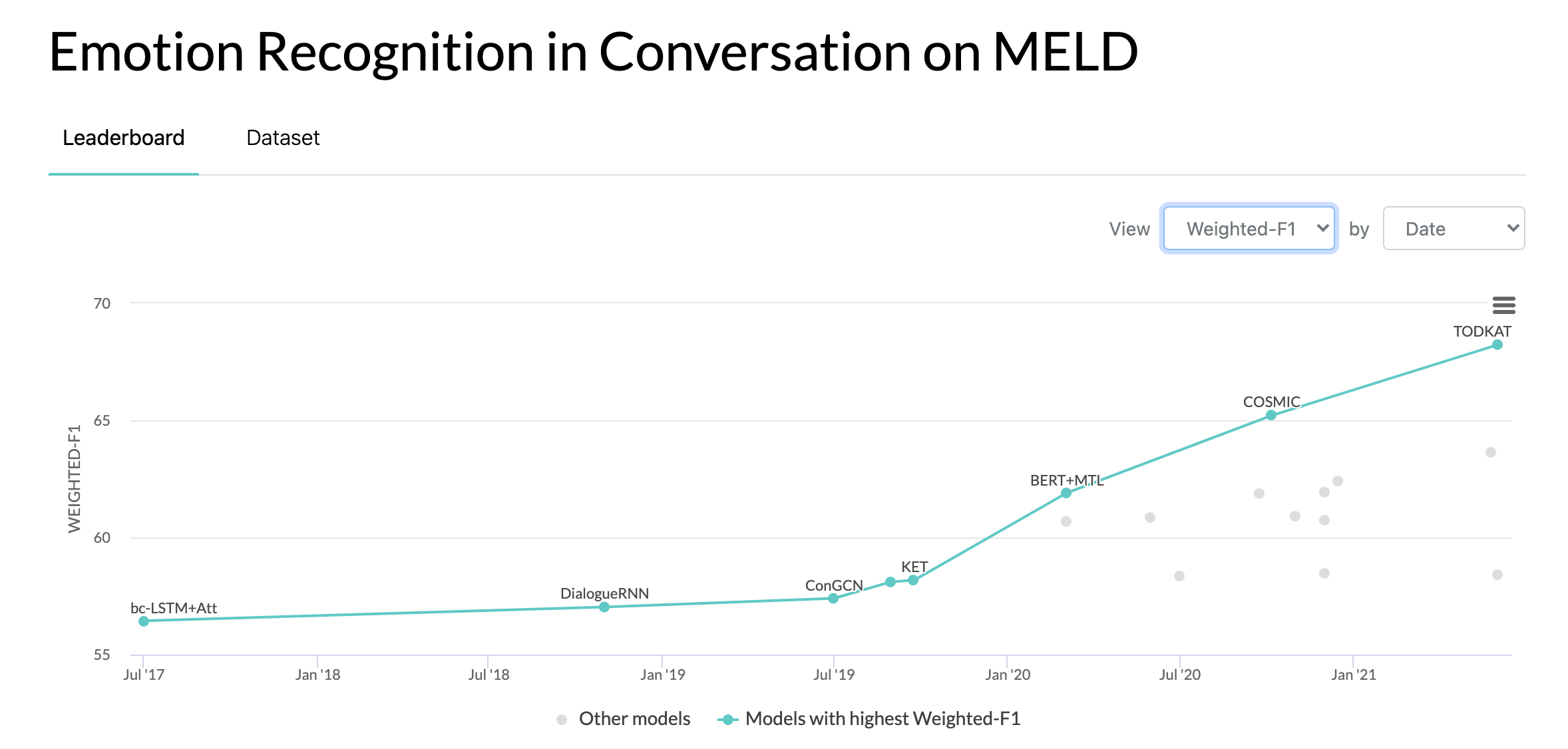
10/10/2020: Nuevo artículo y SOTA en Reconocimiento de emociones en conversaciones en el conjunto de datos MELD. Consulte el directorio COSMIC para obtener el código. Lea el artículo: COSMIC: conocimiento de sentido común para la identificación de emociones en conversaciones.
22/05/2019: MELD: A Multimodal Multi-Party Dataset for Emotion Recognition in Conversation ha sido aceptado como artículo completo en ACL 2019. El artículo actualizado se puede encontrar aquí: https://arxiv.org/pdf/1810.02508. pdf
22/05/2019: Se lanzó Dyadic MELD. Puede utilizarse para probar modelos conversacionales diádicos.
15/11/2018: Se ha solucionado el problema en train.tar.gz.
Zhang, Yazhou, Qiuchi Li, Dawei Song, Peng Zhang y Panpan Wang. "Redes interactivas de inspiración cuántica para el análisis de sentimientos conversacionales". IJCAI 2019.
Zhang, Dong, Liangqing Wu, Changlong Sun, Shoushan Li, Qiaoming Zhu y Guodong Zhou. "Modelado de la dependencia sensible al contexto y al hablante para la detección de emociones en conversaciones entre varios hablantes". IJCAI 2019.
Ghosal, Deepanway, Navonil Majumder, Soujanya Poria, Niyati Chhaya y Alexander Gelbukh. "DialogueGCN: una red neuronal convolucional gráfica para el reconocimiento de emociones en la conversación". EMNLP 2019.
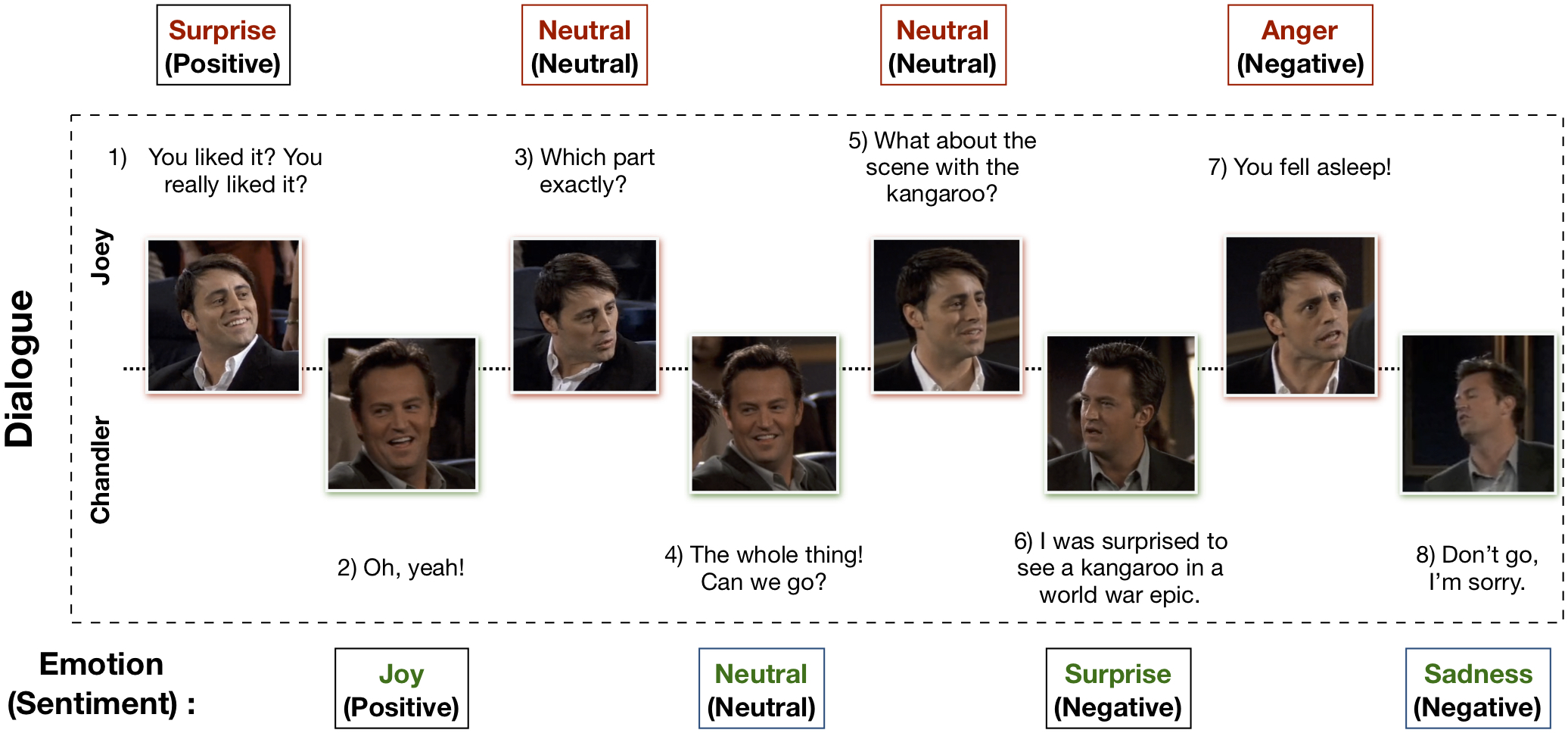
El conjunto de datos Multimodal EmotionLines (MELD) se ha creado mejorando y ampliando el conjunto de datos EmotionLines. MELD contiene las mismas instancias de diálogo disponibles en EmotionLines, pero también abarca modalidad audio y visual junto con texto. MELD tiene más de 1400 diálogos y 13000 declaraciones de la serie de televisión Friends. Varios oradores participaron en los diálogos. Cada expresión en un diálogo ha sido etiquetada por cualquiera de estas siete emociones: ira, disgusto, tristeza, alegría, neutral, sorpresa y miedo. MELD también tiene anotaciones de sentimiento (positivo, negativo y neutral) para cada expresión.
| Estadística | Tren | desarrollador | Prueba |
|---|---|---|---|
| # de modalidad | {a,v,t} | {a,v,t} | {a,v,t} |
| # de palabras únicas | 10.643 | 2,384 | 4.361 |
| Promedio longitud del enunciado | 8.03 | 7,99 | 8.28 |
| Máx. longitud del enunciado | 69 | 37 | 45 |
| Promedio # de emociones por diálogo | 3.30 | 3.35 | 3.24 |
| # de diálogos | 1039 | 114 | 280 |
| # de expresiones | 9989 | 1109 | 2610 |
| # de hablantes | 260 | 47 | 100 |
| # de cambio de emoción | 4003 | 427 | 1003 |
| Promedio duración de un enunciado | 3,59s | 3,59s | 3,58s |
Visite https://affective-meld.github.io para obtener más detalles.
| Tren | desarrollador | Prueba | |
|---|---|---|---|
| Enojo | 1109 | 153 | 345 |
| Asco | 271 | 22 | 68 |
| Miedo | 268 | 40 | 50 |
| Alegría | 1743 | 163 | 402 |
| Neutral | 4710 | 470 | 1256 |
| Tristeza | 683 | 111 | 208 |
| Sorpresa | 1205 | 150 | 281 |
El análisis de datos multimodal explota información de múltiples canales de datos paralelos para la toma de decisiones. Con el rápido crecimiento de la IA, el reconocimiento de emociones multimodal ha ganado un gran interés en la investigación, principalmente debido a sus aplicaciones potenciales en muchas tareas desafiantes, como la generación de diálogos, la interacción multimodal, etc. Se puede utilizar un sistema de reconocimiento de emociones conversacional para generar respuestas apropiadas mediante Analizar las emociones del usuario. Aunque existen numerosos trabajos realizados sobre el reconocimiento de emociones multimodal, sólo unos pocos se centran realmente en la comprensión de las emociones en las conversaciones. Sin embargo, su trabajo se limita únicamente a la comprensión de conversaciones diádicas y, por lo tanto, no es escalable al reconocimiento de emociones en conversaciones entre varias partes que tienen más de dos participantes. EmotionLines se puede utilizar como recurso para el reconocimiento de emociones solo en texto, ya que no incluye datos de otras modalidades, como visual y de audio. Al mismo tiempo, cabe señalar que no existe ningún conjunto de datos conversacionales multimodales y multipartitos disponibles para la investigación del reconocimiento de emociones. En este trabajo, hemos ampliado, mejorado y desarrollado aún más el conjunto de datos EmotionLines para el escenario multimodal. El reconocimiento de emociones en turnos secuenciales presenta varios desafíos y la comprensión del contexto es uno de ellos. El cambio de emoción y el flujo de emoción en la secuencia de turnos en un diálogo hacen que el modelado preciso del contexto sea una tarea difícil. En este conjunto de datos, como tenemos acceso a las fuentes de datos multimodales para cada diálogo, planteamos la hipótesis de que mejorará el modelado del contexto, beneficiando así el rendimiento general del reconocimiento de emociones. Este conjunto de datos también se puede utilizar para desarrollar un sistema de diálogo afectivo multimodal. IEMOCAP, SEMAINE son conjuntos de datos conversacionales multimodales que contienen etiquetas de emoción para cada expresión. Sin embargo, estos conjuntos de datos son de naturaleza diádica, lo que justifica la importancia de nuestro conjunto de datos Multimodal-EmotionLines. Los otros conjuntos de datos de reconocimiento de sentimientos y emociones multimodales disponibles públicamente son MOSEI, MOSI, MOUD. Sin embargo, ninguno de esos conjuntos de datos es conversacional.
El primer paso consiste en encontrar la marca de tiempo de cada expresión en cada uno de los diálogos presentes en el conjunto de datos de EmotionLines. Para lograr esto, rastreamos los archivos de subtítulos de todos los episodios que contienen la marca de tiempo de inicio y finalización de las declaraciones. Este proceso nos permitió obtener el ID de la temporada, el ID del episodio y la marca de tiempo de cada expresión del episodio. Ponemos dos restricciones al obtener las marcas de tiempo: (a) las marcas de tiempo de las expresiones en un diálogo deben estar en orden creciente, (b) todas las expresiones en un diálogo deben pertenecer al mismo episodio y escena. Restringir estas dos condiciones reveló que en EmotionLines, algunos diálogos constan de múltiples diálogos naturales. Filtramos esos casos del conjunto de datos. Debido a este paso de corrección de errores, en nuestro caso, tenemos un número diferente de diálogos en comparación con EmotionLines. Después de obtener la marca de tiempo de cada expresión, extrajimos sus clips audiovisuales correspondientes del episodio fuente. Por separado, también eliminamos el contenido de audio de esos videoclips. Finalmente, el conjunto de datos contiene modalidad visual, de audio y textual para cada diálogo.
El documento que explica este conjunto de datos se puede encontrar en: https://arxiv.org/pdf/1810.02508.pdf
Visite: http://web.eecs.umich.edu/~mihalcea/downloads/MELD.Raw.tar.gz para descargar los datos sin procesar. Los datos se almacenan en formato .mp4 y se pueden encontrar en archivos XXX.tar.gz. Las anotaciones se pueden encontrar en https://github.com/declare-lab/MELD/tree/master/data/MELD.
| Nombre de columna | Descripción |
|---|---|
| Sr No. | Números de serie de los enunciados principalmente para hacer referencia a los enunciados en caso de diferentes versiones o copias múltiples con diferentes subconjuntos |
| Declaración | Declaraciones individuales de EmotionLines como una cadena. |
| Vocero | Nombre del hablante asociado con el enunciado. |
| Emoción | La emoción (neutral, alegría, tristeza, ira, sorpresa, miedo, disgusto) expresada por el hablante en el enunciado. |
| Sentimiento | El sentimiento (positivo, neutral, negativo) expresado por el hablante en el enunciado. |
| Diálogo_ID | El índice del diálogo a partir de 0. |
| ID_enunciado | El índice del enunciado particular en el diálogo comenzando desde 0. |
| Estación | La temporada nro. del programa de televisión Friends al que pertenece una expresión en particular. |
| Episodio | El episodio nro. del programa de televisión Friends en una temporada particular a la que pertenece el enunciado. |
| Hora de inicio | La hora de inicio de la expresión en el episodio determinado en el formato 'hh:mm:ss,ms'. |
| Hora de finalización | La hora de finalización de la expresión en el episodio determinado en el formato 'hh:mm:ss,ms'. |
Hay 13 archivos pickle que contienen los datos y las características utilizadas para entrenar los modelos de referencia. A continuación se muestra una breve descripción de cada uno de los archivos pickle.
import pickle
data , W , vocab , word_idx_map , max_sentence_length , label_index = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_avg_emb , val_text_avg_emb , test_text_avg_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_audio_emb , val_audio_emb , test_audio_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_CNN_emb , val_text_CNN_emb , test_text_CNN_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_emb , val_text_emb , test_text_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_audio_emb , val_audio_emb , test_audio_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_bimodal_emb , val_bimodal_emb , test_bimodal_emb = pickle . load ( open ( filepath , 'rb' ))Hay 2 scripts de Python proporcionados en './utils/':
Para la experimentación, todas las etiquetas se representan como codificaciones one-hot, cuyos índices son los siguientes:
Para la base de referencia sobre la clasificación de las emociones, se utilizaron las siguientes ponderaciones de clase. La indexación es la misma que se mencionó anteriormente. Pesos de clase: [4.0, 15.0, 15.0, 3.0, 1.0, 6.0, 3.0].
Siga estos pasos para ejecutar la línea base:
./data/pickles/baseline/baseline.py de la siguiente manera:python baseline.py -classify [Sentiment|Emotion] -modality [text|audio|bimodal] [-train|-test]python baseline.py -classify Sentiment -modality text -trainpython baseline.py -h para obtener texto de ayuda para los parámetros../data/models/ . Cite los siguientes artículos si este conjunto de datos le resulta útil en su investigación.
S. Poria, D. Hazarika, N. Majumder, G. Naik, E. Cambria, R. Mihalcea. MELD: un conjunto de datos multimodal y multipartito para el reconocimiento de emociones en la conversación. ACL 2019.
Chen, SY, Hsu, CC, Kuo, CC y Ku, LW EmotionLines: un corpus emocional de conversaciones multipartitas. Preimpresión de arXiv arXiv:1802.08379 (2018).
El conjunto de datos de detección de emociones multimodal EmoryNLP se ha creado mejorando y ampliando el conjunto de datos de detección de emociones EmoryNLP. Contiene las mismas instancias de diálogo disponibles en el conjunto de datos de detección de emociones de EmoryNLP, pero también abarca la modalidad de audio y visual junto con el texto. Hay más de 800 diálogos y 9000 expresiones de la serie de televisión Friends en el conjunto de datos multimodal EmoryNLP. Varios oradores participaron en los diálogos. Cada expresión en un diálogo ha sido etiquetada por cualquiera de estas siete emociones: Neutral, Alegre, Pacífica, Poderosa, Asustada, Loca y Triste. Las anotaciones se toman prestadas del conjunto de datos original.
| Estadística | Tren | desarrollador | Prueba |
|---|---|---|---|
| # de modalidad | {a,v,t} | {a,v,t} | {a,v,t} |
| # de palabras únicas | 9.744 | 2,123 | 2,345 |
| Promedio longitud del enunciado | 7,86 | 6,97 | 7,79 |
| Máx. longitud del enunciado | 78 | 60 | 61 |
| Promedio # de emociones por escena | 4.10 | 4.00 | 4.40 |
| # de diálogos | 659 | 89 | 79 |
| # de expresiones | 7551 | 954 | 984 |
| # de hablantes | 250 | 46 | 48 |
| # de cambio de emoción | 4596 | 575 | 653 |
| Promedio duración de un enunciado | 5,55s | 5,46s | 5,27s |
| Tren | desarrollador | Prueba | |
|---|---|---|---|
| Alegre | 1677 | 205 | 217 |
| Enojado | 785 | 97 | 86 |
| Neutral | 2485 | 322 | 288 |
| Pacífico | 638 | 82 | 111 |
| Poderoso | 551 | 70 | 96 |
| Triste | 474 | 51 | 70 |
| Asustado | 941 | 127 | 116 |
Los videoclips de este conjunto de datos se pueden descargar desde este enlace. Los archivos de anotaciones se pueden encontrar en https://github.com/SenticNet/MELD/tree/master/data/emorynlp. Hay 3 archivos .csv. Cada entrada en la primera columna de estos archivos csv contiene una expresión cuyo videoclip correspondiente se puede encontrar aquí. Cada expresión y su videoclip están indexados por el número de temporada, el número de episodio, la identificación de la escena y la identificación de la expresión. Por ejemplo, sea1_ep2_sc6_utt3.mp4 implica que el clip corresponde al enunciado con la temporada no. 1, episodio núm. 2, scene_id 6 y utterance_id 3. Una escena es simplemente un diálogo. Esta indexación es consistente con el conjunto de datos original. Los archivos .csv y los archivos de vídeo se dividen en el conjunto de tren, validación y prueba de acuerdo con el conjunto de datos original. Las anotaciones se han tomado directamente del conjunto de datos original de EmoryNLP (Zahiri et al. (2018)).
| Nombre de columna | Descripción |
|---|---|
| Declaración | Declaraciones individuales de EmoryNLP como una cadena. |
| Vocero | Nombre del hablante asociado con el enunciado. |
| Emoción | La emoción (neutral, alegre, pacífica, poderosa, asustada, enojada y triste) expresada por el hablante en el enunciado. |
| ID_escena | El índice del diálogo a partir de 0. |
| ID_enunciado | El índice del enunciado particular en el diálogo comenzando desde 0. |
| Estación | La temporada nro. del programa de televisión Friends al que pertenece una expresión en particular. |
| Episodio | El episodio nro. del programa de televisión Friends en una temporada particular a la que pertenece el enunciado. |
| Hora de inicio | La hora de inicio de la expresión en el episodio determinado en el formato 'hh:mm:ss,ms'. |
| Hora de finalización | La hora de finalización de la expresión en el episodio determinado en el formato 'hh:mm:ss,ms'. |
Nota : Hay algunas expresiones para las cuales no pudimos encontrar la hora de inicio y finalización debido a algunas inconsistencias en los subtítulos. Estas expresiones se han omitido del conjunto de datos. Sin embargo, animamos a los usuarios a encontrar las expresiones correspondientes en el conjunto de datos original y generar videoclips para las mismas.
Cite los siguientes artículos si este conjunto de datos le resulta útil en su investigación.
S. Zahiri y JD Choi. Detección de emociones en transcripciones de programas de televisión con redes neuronales convolucionales basadas en secuencias. En el taller de la AAAI sobre análisis de contenido afectivo, AFFCON'18, 2018.
S. Poria, D. Hazarika, N. Majumder, G. Naik, E. Cambria, R. Mihalcea. MELD: un conjunto de datos multimodal y multipartito para el reconocimiento de emociones en la conversación. ACL 2019.


