ChatLearner
1.0.0
Un chatbot implementado en TensorFlow basado en el nuevo modelo secuencia a secuencia (NMT), con ciertas reglas perfectamente integradas.
Para aquellos que estén interesados en chatbots en chino, consulte aquí.
El núcleo de ChatLearner (Papaya) se construyó sobre el modelo NMT (https://github.com/tensorflow/nmt), que se ha adaptado aquí para satisfacer las necesidades de un chatbot. Debido a los cambios realizados en la API tf.data en TensorFlow 1.4 y muchos otros cambios desde TensorFlow 1.12, esta versión de ChatLearner solo admite TF versión 1.4 a 1.11. Se pueden realizar actualizaciones sencillas en el archivo tokenizeddata.py si necesita compatibilidad con TensorFlow 1.12.
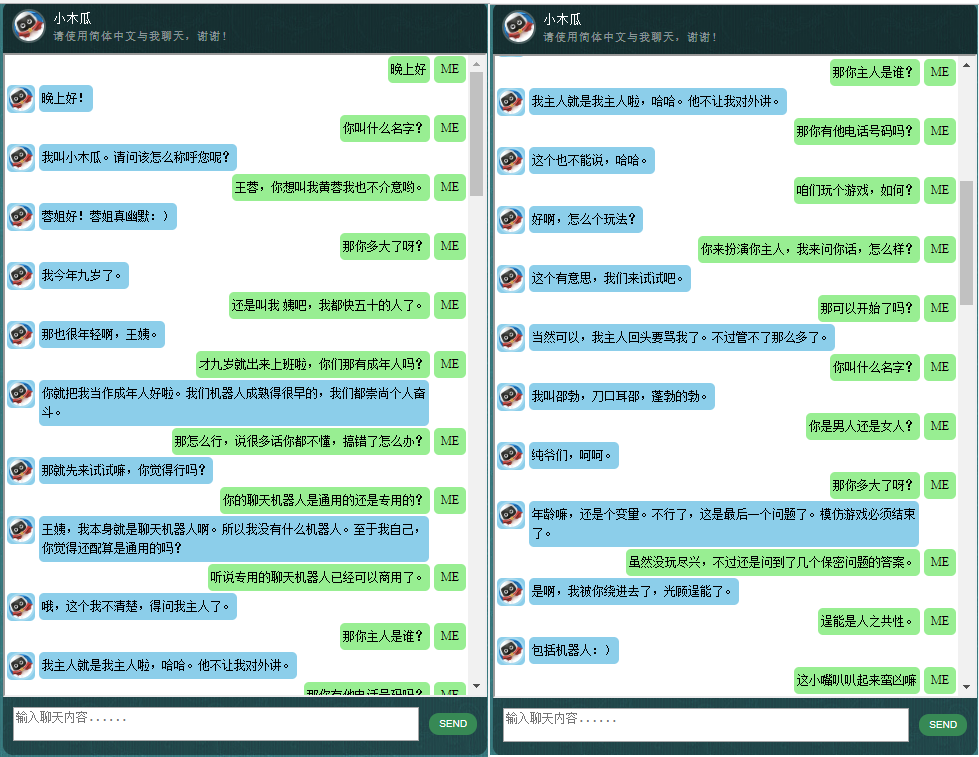
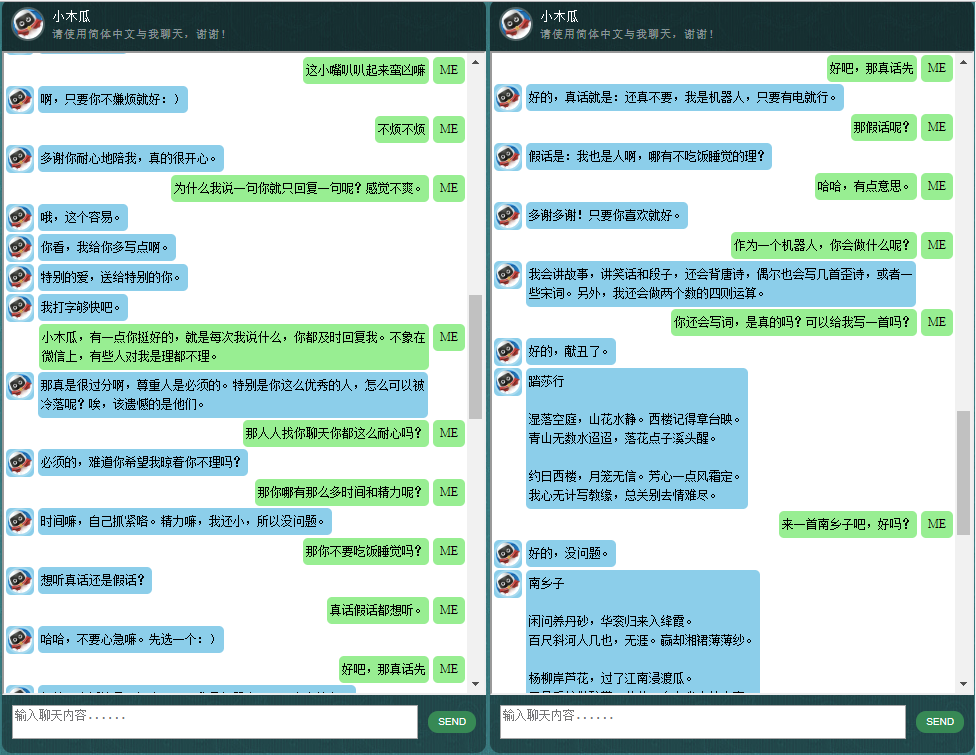
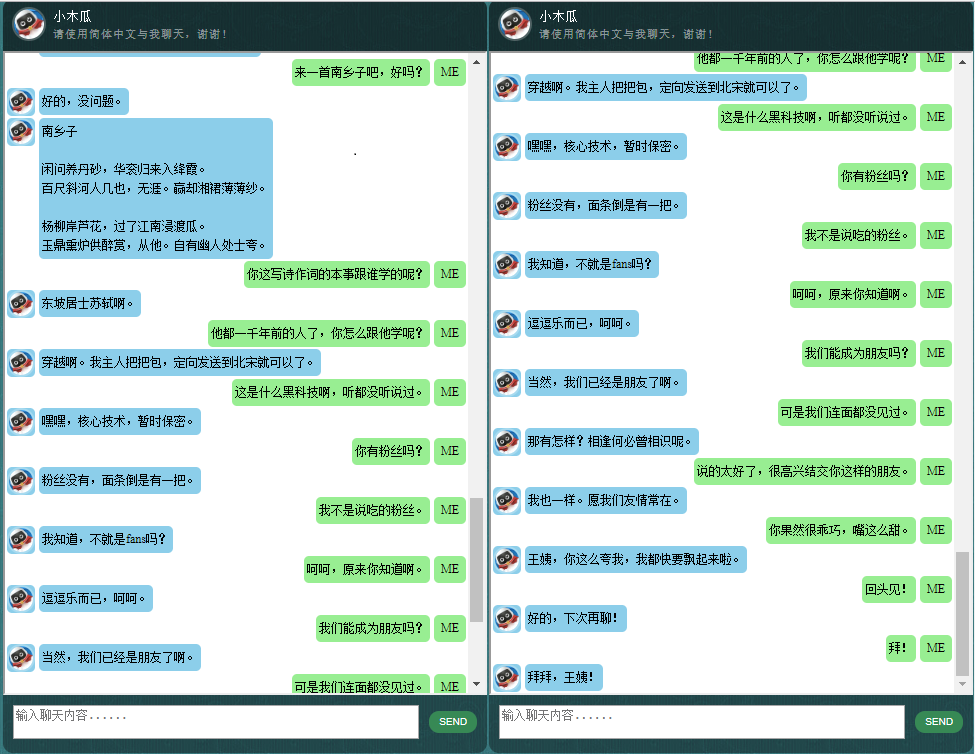
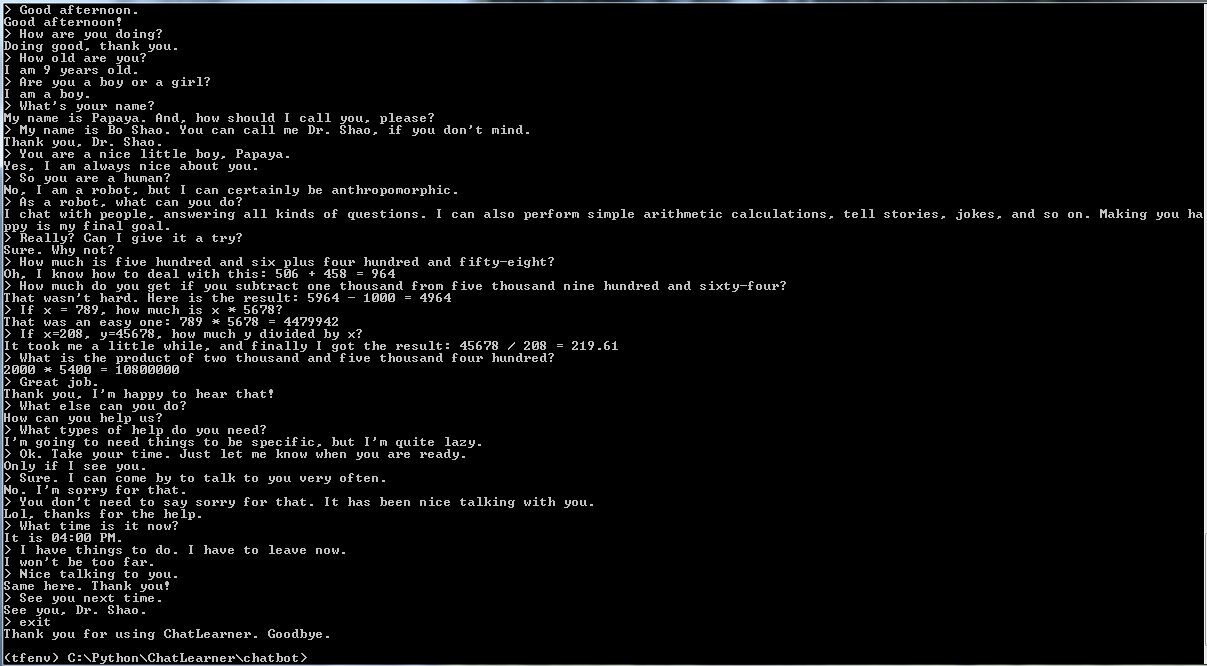
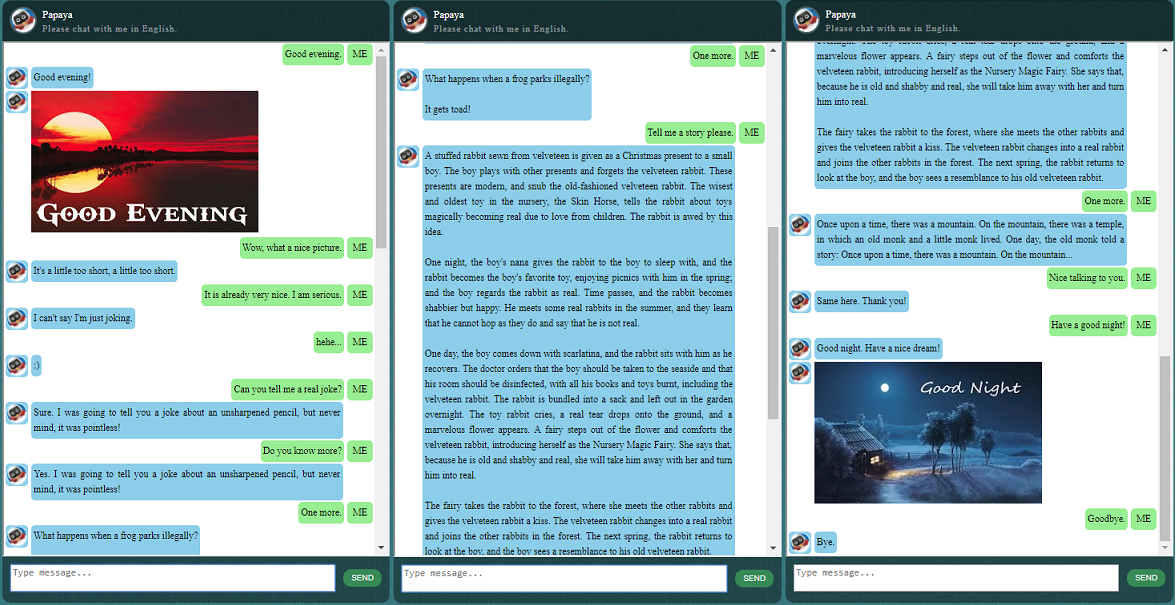
Antes de comenzar con todo lo demás, es posible que desee tener una idea de cómo se comporta ChatLearner. Eche un vistazo a la conversación de muestra a continuación o aquí, o si prefiere probar mi modelo entrenado, descárguelo aquí. Descomprima el archivo .rar descargado y copie la carpeta de Resultados en la carpeta de Datos debajo de la raíz de su proyecto. También se incluye un archivo vocab.txt en caso de que lo actualice sin actualizar el modelo entrenado en el futuro.
¿Por qué quieres dedicar tiempo a revisar este repositorio? Aquí hay algunas posibles razones:
El conjunto de datos de Papaya para entrenar el chatbot. Puedes encontrar fácilmente toneladas de datos de entrenamiento en línea, pero no puedes encontrar ninguno con tan alta calidad. Consulte la descripción detallada a continuación sobre el conjunto de datos.
El estilo de código conciso y la implementación clara del nuevo modelo seq2seq basado en RNN dinámico (también conocido como el nuevo modelo NMT). Está personalizado para chatbots y es mucho más fácil de entender en comparación con el tutorial oficial.
La idea de utilizar ChatSession perfectamente integrado para manejar el contexto conversacional básico.
Algunas reglas se integran para demostrar cómo combinar chatbots tradicionales basados en reglas con nuevos modelos de aprendizaje profundo. No importa cuán poderoso pueda ser un modelo de aprendizaje profundo, ni siquiera puede responder preguntas que requieran cálculos aritméticos simples y muchas otras. El enfoque demostrado aquí se puede adaptar fácilmente para recuperar noticias u otra información en línea. Una vez implementadas las reglas, podrá responder adecuadamente a muchas preguntas interesantes. Por ejemplo:
Si no está interesado en las reglas, puede eliminar fácilmente aquellas líneas relacionadas con Knowledgebase.py y Functiondata.py.
Un servicio web basado en SOAP (y una alternativa basada en REST-API, si no le gusta usar SOAP) le permite presentar la GUI en Java, mientras el modelo se entrena y se ejecuta en Python y TensorFlow.
Una solución simple (en gráfico) para convertir un tensor de cadena a minúsculas en TensorFlow. Es necesario si utiliza la nueva API DataSet (tf.data.TextLineDataSet) en TensorFlow para cargar datos de entrenamiento desde archivos de texto.
El repositorio también contiene una implementación de chatbot basada en el modelo heredado seq2seq. En caso de que esté interesado en eso, consulte la sucursal Legacy_Chatbot en https://github.com/bshao001/ChatLearner/tree/Legacy_Chatbot.
Papaya Data Set son los mejores datos de conversación en inglés gratuitos (los más limpios y mejor organizados) que puedes encontrar en la web para entrenar un chatbot. Aquí hay algunos detalles:
Los datos se componen de dos conjuntos: el primer conjunto fue elaborado a mano y creamos las muestras para mantener un papel consistente del chatbot, que por lo tanto puede ser entrenado para ser educado, paciente, humorístico, filosófico y consciente de que es. un robot, pero finge ser un niño de 9 años llamado Papaya; el segundo conjunto se limpió de algunos recursos en línea, incluidas las conversaciones de escenarios diseñadas para entrenar robots, los diálogos de la película Cornell y los datos limpios de Reddit.
El conjunto de datos de entrenamiento se divide en tres categorías: dos subconjuntos se aumentarán/repetirán durante el entrenamiento, con diferentes niveles o tiempos, mientras que el tercero no. Los subconjuntos aumentados sirven para entrenar el modelo con reglas a seguir y algo de conocimiento y sentido común, mientras que el tercer subconjunto es solo para ayudar a entrenar el modelo de lenguaje.
Las conversaciones de escenarios se extrajeron y reorganizaron de http://www.eslfast.com/robot/. Si su modelo puede soportar el contexto, funcionaría mucho mejor utilizando estas conversaciones.
El conjunto de datos original de Cornell se puede encontrar aquí. Lo limpiamos usando un script Python (el script también se puede encontrar en la carpeta Corpus); Luego lo limpiamos manualmente buscando rápidamente ciertos patrones.
Para los datos de Reddit, en este repositorio se incluye un subconjunto limpio (aproximadamente 110.000 pares). El archivo de vocabulario y los parámetros del modelo se crean y ajustan en función de todos los archivos de datos incluidos. En caso de que necesite un conjunto más grande, también puede encontrar scripts para analizar y limpiar los comentarios de Reddit en la carpeta Corpus/RedditData. Para utilizar esos scripts, debe descargar un torrente de comentarios de Reddit desde un enlace de torrent aquí. Normalmente, un solo mes de comentarios es suficiente (puede generar aproximadamente 3 millones de pares de muestras de entrenamiento). Puede ajustar los parámetros en los scripts según sus necesidades.
Los archivos de datos de este conjunto de datos ya se procesaron previamente con el tokenizador NLTK para que estén listos para alimentar el modelo utilizando la nueva API tf.data en TensorFlow.
Asegúrese de tener la versión correcta de TensorFlow. Solo funciona con TensorFlow 1.4, no con versiones anteriores porque la API tf.data utilizada aquí se actualizó recientemente en TF 1.4.
Asegúrese de tener la configuración de la variable de entorno PYTHONPATH. Debe apuntar al directorio raíz del proyecto, en el que se encuentran la carpeta chatbot, Datos y webui. Si está ejecutando un IDE, como PyCharm, lo creará por usted. Pero si ejecuta algún script de Python en una línea de comando, debe tener esa variable de entorno; de lo contrario, obtendrá errores de importación del módulo.
Asegúrese de utilizar el mismo archivo vocab.txt tanto para el entrenamiento como para la inferencia/predicción. Tenga en cuenta que su modelo nunca verá ninguna palabra como nosotros. Son todos los números enteros que entran y los números enteros que salen, mientras que las palabras y sus órdenes en vocab.txt ayudan a mapear las palabras y los números enteros.
Dedique un poco de tiempo a pensar en qué tan grande debería ser su modelo, cuál debería ser la longitud máxima del codificador/decodificador, el tamaño del conjunto de vocabulario y cuántos pares de datos de entrenamiento desea utilizar. Tenga en cuenta que un modelo tiene un límite de capacidad: cuántos datos puede aprender o recordar. Cuando tienes un número fijo de capas, un número de unidades, un tipo de celda RNN (como GRU) y decides la longitud del codificador/decodificador, es principalmente el tamaño del vocabulario lo que afecta la capacidad de aprendizaje de tu modelo, no el número de muestras de entrenamiento. Si puede lograr no dejar que el tamaño del vocabulario aumente cuando utiliza más datos de entrenamiento, probablemente funcionará, pero la realidad es que cuando tiene más muestras de entrenamiento, el tamaño del vocabulario también aumenta muy rápidamente, y entonces puede notar su modelo no puede acomodar ese tamaño de datos en absoluto. No dude en abrir un problema para discutirlo si lo desea.
Además de Python 3.6 (3.5 también debería funcionar), Numpy y TensorFlow 1.4. También necesita NLTK (Natural Language Toolkit) versión 3.2.4 (o 3.2.5).
Durante el entrenamiento, realmente te sugiero que intentes jugar con un parámetro (colocate_gradients_with_ops) en la función tf.gradients. Puede encontrar una línea como esta en modelcreator.py: gradients = tf.gradients(self.train_loss, params). Establezca colocate_gradients_with_ops=True (agregándolo) y ejecute el entrenamiento durante al menos una época, anote el tiempo y luego configúrelo en False (o simplemente elimínelo) y ejecute el entrenamiento durante al menos una época y vea si los tiempos requeridos para una época son significativamente diferentes. Al menos a mí me resulta chocante.
Aparte de eso, la formación es sencilla. Recuerde crear primero una carpeta llamada Resultado en la carpeta Datos. Luego simplemente ejecute los siguientes comandos:
cd chatbot
python bottrainer.pySe recomiendan encarecidamente buenas GPU para la formación, ya que puede llevar mucho tiempo. Si tiene varias GPU, TensorFlow utilizará la memoria de todas las GPU y puede ajustar el parámetro Batch_size en el archivo hparams.json en consecuencia para aprovechar al máximo la memoria. Podrás ver los resultados del entrenamiento en la carpeta Datos/Resultados/. Asegúrese de que existan los siguientes 2 archivos, ya que todos serán necesarios para las pruebas y la predicción (el archivo .meta es opcional ya que el modelo de inferencia se creará de forma independiente):
Para pruebas y predicciones, proporcionamos una interfaz de comando simple y una interfaz basada en web. Tenga en cuenta que el archivo vocab.txt (y los archivos de KnowledgeBase, para este chatbot) también son necesarios para la inferencia. Para comprobar rápidamente cómo funciona el modelo entrenado, utilice la siguiente interfaz de comando:
cd chatbot
python botui.pyEspere hasta que aparezca el símbolo del sistema ">".
También se proporciona un resultado de la prueba de demostración. Compruébelo para ver cómo se comporta este chatbot ahora: https://github.com/bshao001/ChatLearner/blob/master/Data/Test/responses.txt
Se implementa una arquitectura de servicios web basada en SOAP, con un servidor Python y un cliente Java. También se incluye una agradable GUI para su referencia. Para obtener más detalles, consulte: https://github.com/bshao001/ChatLearner/tree/master/webui. Tenga en cuenta que cierta información (como imágenes) solo está disponible en la interfaz web (no en la interfaz de línea de comandos).
También se ofrece una alternativa basada en REST-API si SOAP no es su elección. Para obtener más detalles, consulte: https://github.com/bshao001/ChatLearner/tree/master/webui_alternative. Es posible que algunas de las últimas actualizaciones no estén disponibles con esta opción. Combine los cambios de la otra opción si necesita usar esta.
Marco de marcado NLP (自然语言处理标记框架), 试图实现对特定领域问题的精准回复,并可以解决很多对话中的复杂的上下文相关问题。本方法尤其适用于商业上的专用(面向任务的)聊天机器人的开发,比如售前,售后,或特定领域(如法律,医疗)的技术咨询服务等。有兴趣的朋友欢迎微信联系。本人微信号:bshao001_miami