Dialog
1.0.0
Dialog es un proyecto de chatbot japonés.
La arquitectura utilizada en este proyecto es el modelo EncoderDecoder que tiene BERT Encoder y Transformer Decoder.
Artículo escrito en japonés.
Puede ejecutar scripts de capacitación y evaluación en Google Colab sin crear un entorno.
Por favor haga clic en el siguiente enlace.
Tenga en cuenta que en el cuaderno de capacitación, el comando de descarga se describe al final de la nota, pero aún no se ha probado. Por lo tanto, si ejecuta el cuaderno de entrenamiento y no puede descargar un archivo de peso entrenado, descárguelo manualmente.
blog escrito en japonés
@ ycat3 creó un ejemplo de conversión de texto a voz utilizando este proyecto para la generación de oraciones y Parallel Wavenet para la síntesis de voz. El código fuente no se comparte, pero puedes reproducirlo si aprovechas Parallel Wavenet. Ese blog tiene algunas muestras de audio, así que intente escucharlo.
Me gustaría crear una aplicación que nos permita hablar con IA en voz mediante síntesis de voz y reconocimiento de voz si tengo mucho tiempo libre, pero ahora no puedo hacerlo debido a que me estoy preparando para los exámenes...
2épocas
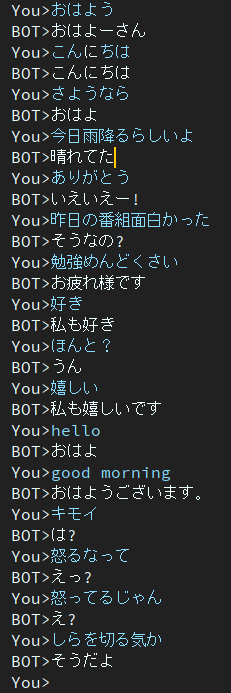
Este modelo todavía contiene el problema de la respuesta aburrida.
Para resolver este problema estoy investigando ahora.
Luego encontré que el artículo abordaba este problema.
Otra función objetiva que promueve la diversidad para la generación de diálogo neuronal
Los autores pertenecen al Instituto Nara de Ciencia y Tecnología, también conocido como NAIST.
Proponen la nueva función objetivo de generación de diálogo neuronal.
Espero que este método pueda ayudarme a resolver ese problema.
en googledrive.
Los paquetes necesarios son
Si se producen errores debido a los paquetes, instale los paquetes que faltan.
Ejemplo si usas conda.
# create new environment
$ conda create -n dialog python=3.7
# activate new environment
$ activate dialog
# install pytorch
$ conda install pytorch torchvision cudatoolkit={YOUR_VERSION} -c pytorch
# install rest of depending package except for MeCab
$ pip install transformers tqdm neologdn emoji
# #### Already installed MeCab #####
# ## Ubuntu ###
$ pip install mecab-python3
# ## Windows ###
# check that "path/to/MeCab/bin" are added to system envrionment variable
$ pip install mecab-python-windows
# #### Not Installed MeCab #####
# install Mecab in accordance with your OS.
# method described in below is one of the way,
# so you can use your way if you'll be able to use transformers.BertJapaneseTokenizer.
# ## Ubuntu ###
# if you've not installed MeCab, please execute following comannds.
$ apt install aptitude
$ aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
$ pip install mecab-python3
# ## Windows ###
# Install MeCab from https://github.com/ikegami-yukino/mecab/releases/tag/v0.996
# and add "path/to/Mecab/bin" to system environment variable.
# then run the following command.
$ pip install mecab-python-windows # in config.py, line 24
# default value is './data'
data_dir = 'path/to/dir_contains_training_data'Si está listo para comenzar a entrenar, ejecute el script principal.
$ python main.py # in config.py, line 24
# default value is './data'
data_dir = 'path/to/dir_contains_pretrained'$ python run_eval.pySi desea obtener más datos de la conversación, utilice get_tweet.py
Tenga en cuenta que debe cambiar consumer_key y access_token para poder utilizar este script.
Y luego, ejecute los siguientes comandos.
# usage
$ python get_tweet.py " query " " Num of continuous utterances "
# Example
# This command works until occurs errors
# and makes a file named "tweet_data_私は_5.txt" in "./data"
$ python get_tweet.py 私は 5Si ejecuta el comando de ejemplo, el script comenzará a recopilar 5 oraciones consecutivas si la última oración contiene "私は".
Sin embargo, configura 3 o más números como "expresiones continuas", make_training_data.py crea automáticamente un par de expresiones.
Luego ejecute el siguiente comando.
$ python make_training_data.pyEste script crea datos de entrenamiento usando './data/tweet_data_*.txt', tal como el nombre.
Codificador: BERT
Decodificador: Decodificador de Vanilla Transformer
Pérdida: Entropía cruzada
Optimizador: AdamW
Tokenizador: BertJapaneseTokenizer
Si desea obtener más información sobre la arquitectura de BERT o Transformer, consulte el siguiente artículo.


