Seq2seqChatbots
1.0.0
Un contenedor alrededor de tensor2tensor para entrenar, interactuar y generar datos de manera flexible para chatbots neuronales.
La wiki contiene mis notas y resúmenes de más de 150 publicaciones recientes relacionadas con el modelado de diálogo neuronal.
? Ejecute sus propios entrenamientos o experimente con modelos previamente entrenados
✅ 4 conjuntos de datos de diálogo diferentes integrados con tensor2tensor
? Funciona perfectamente con cualquier modelo o conjunto de hiperparámetros en tensor2tensor
Clase base fácilmente extensible para problemas de diálogo
Ejecute setup.py, que instala los paquetes necesarios y le guía en la descarga de datos adicionales:
python setup.py
Puede descargar todos los modelos entrenados utilizados en este documento desde aquí. Cada entrenamiento contiene dos puntos de control, uno para la pérdida mínima de validación y otro después de 150 épocas. Los datos y la estructura de carpetas de formación coinciden exactamente.
python t2t_csaky/main.py --mode=train
El argumento del modo puede ser uno de los cuatro siguientes: {generar_datos, entrenar, decodificar, experimentar} . En el modo de experimento , puede especificar qué hacer dentro de la función de experimento del archivo de ejecución . A continuación se proporciona una explicación detallada de lo que hace cada modo.
Puede controlar las banderas y parámetros de cada modo directamente en este archivo. Para cada ejecución que inicie, este archivo se copiará en el directorio apropiado, para que pueda acceder rápidamente a los parámetros de cualquier ejecución. Hay algunas banderas que debes configurar para cada modo (el diccionario FLAGS en el archivo de configuración):
t2t_usr_dir : Ruta al directorio donde reside mi código. No es necesario cambiar esto, a menos que cambie el nombre del directorio.
data_dir : la ruta al directorio donde desea generar los pares de origen y destino, y otros datos. El conjunto de datos se descargará un nivel superior desde este directorio a una carpeta raw_data .
problema : este es el nombre de un problema registrado que tensor2tensor necesita. Detallado en la sección generate_data a continuación. Todas las rutas deben ser desde la raíz del repositorio.
Este modo descargará y preprocesará los datos y generará pares de origen y destino. Actualmente hay 6 problemas registrados, que puedes usar además de los dados por tensor2tensor:
persona_chat_chatbot : este problema implementa el conjunto de datos Persona-Chat (sin el uso de personas).
daily_dialog_chatbot : este problema implementa el conjunto de datos DailyDialog (sin el uso de temas, actos de diálogo o emociones).
opensubtitles_chatbot : este problema se puede utilizar para trabajar con el conjunto de datos OpenSubtitles.
cornell_chatbot_basic : este problema implementa el Cornell Movie-Dialog Corpus.
cornell_chatbot_separate_names : este problema utiliza el mismo corpus de Cornell, sin embargo, se agregan los nombres de los hablantes y destinatarios de cada expresión, lo que da como resultado expresiones fuente como las que se muestran a continuación.
BIANCA_m0 ¿Qué cosas buenas? CAMERON_m0
Character_chatbot : este es un problema general basado en caracteres que funciona con cualquier conjunto de datos. Antes de usar esto, los archivos .txt generados por cualquiera de los problemas anteriores deben colocarse dentro del directorio de datos, y luego este problema se puede usar para generar archivos de datos basados en caracteres tensor2tensor.
El diccionario PROBLEM_HPARAMS en el archivo de configuración contiene parámetros específicos del problema que puede configurar antes de generar datos:
num_train_shards / num_dev_shards : si desea que los datos de desarrollo o tren generados se divida en varios archivos.
vocabulario_size : Tamaño del vocabulario que queremos utilizar para el problema. Las palabras fuera de este vocabulario serán reemplazadas por el token.
dataset_size : Número de pares de expresiones, si no queremos utilizar el conjunto de datos completo (definido por 0).
dataset_split : especifica una división train-val-test para el problema.
dataset_version : esto solo es relevante para el conjunto de datos de opensubtitles, ya que existen varias versiones de este conjunto de datos, puede especificar el año del conjunto de datos que desea descargar.
name_vocab_size : Esto sólo es relevante para el problema de Cornell con nombres separados. Puede establecer el tamaño del vocabulario que contiene solo las personas.
Este modo le permite entrenar un modelo con el problema y los hiperparámetros especificados. El código simplemente llama al script de entrenamiento de tensor2tensor, por lo que se puede usar cualquier modelo que esté en tensor2tensor. Además de estos, también existe un modelo subclasificado con pequeñas modificaciones:
gradient_checkpointed_seq2seq : Pequeña modificación del modelo seq2seq basado en lstm, para que los hparams propios se puedan usar por completo. Antes de calcular el softmax, las unidades ocultas de LSTM se proyectan a 2048 unidades lineales como aquí. Finalmente, intenté implementar puntos de control de gradiente en este modelo, pero actualmente está eliminado porque no dio buenos resultados.
Hay varios indicadores adicionales que puede especificar para una ejecución de entrenamiento en el diccionario FLAGS del archivo de configuración, algunos de los cuales son:
train_dir : nombre del directorio donde se guardarán los archivos del punto de control de entrenamiento.
modelo : Nombre del modelo: uno de los anteriores o un modelo definido por tensor2tensor.
hparams : especifique un hparams_set registrado o déjelo vacío si desea definir hparams en el archivo de configuración. Para especificar hparams para un modelo seq2seq o transformador , puede usar los diccionarios SEQ2SEQ_HPARAMS y TRANSFORMER_HPARAMS en el archivo de configuración (compruébelo para obtener más detalles).
Con este modo puedes decodificar a partir de los modelos entrenados. Los siguientes parámetros afectan la decodificación (en el diccionario FLAGS en el archivo de configuración):
decode_mode : puede ser interactivo , donde puedes chatear con el modelo usando la línea de comando. El modo de archivo le permite especificar un archivo con expresiones de origen para las cuales generar respuestas, y el modo de conjunto de datos tomará muestras aleatorias de los datos de validación proporcionados y generará respuestas.
decode_dir : directorio donde puede proporcionar el archivo para decodificar y las respuestas generadas se guardarán aquí.
input_file_name : Nombre del archivo que debes dar en modo archivo (colocado en decode_dir ).
nombre_archivo_salida : nombre del archivo, dentro de decode_dir , donde se guardarán las respuestas de salida.
beam_size : Tamaño de la viga, cuando se utiliza la búsqueda de vigas.
return_beams : si es falso, devuelve solo la viga superior; de lo contrario, devuelve el número de vigas de tamaño_viga .
Los siguientes resultados provienen de estos dos artículos.
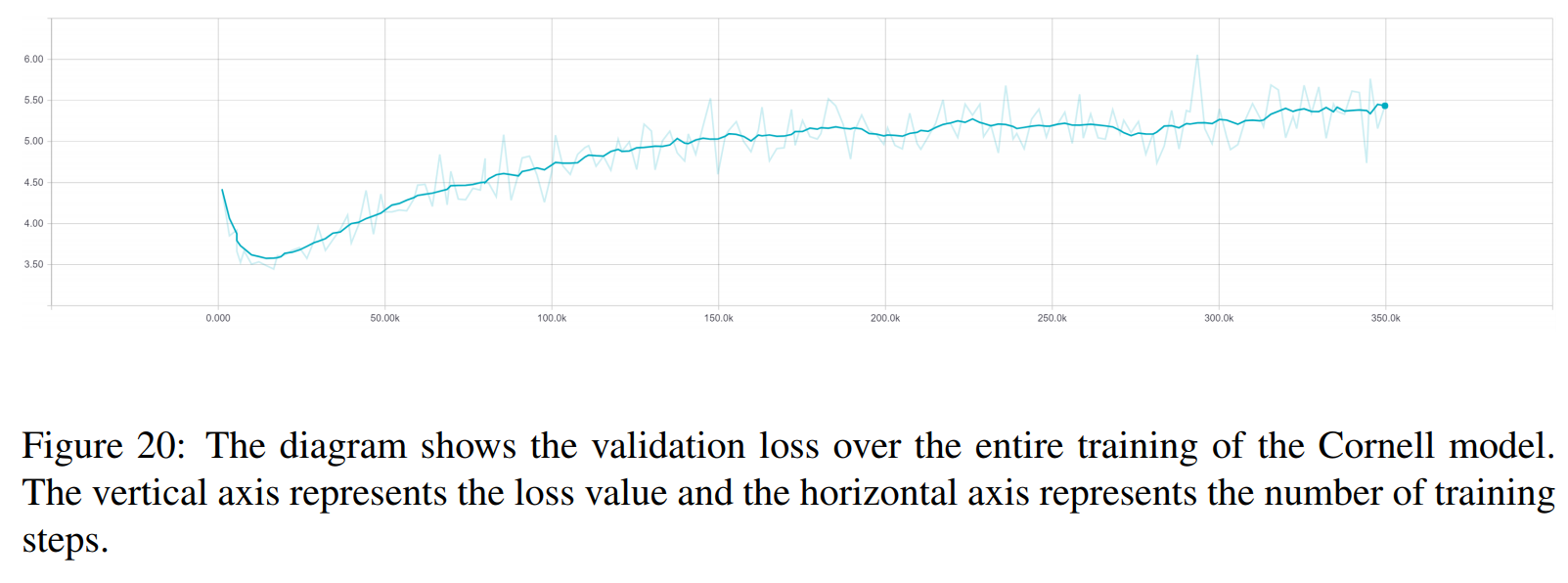

TRF es el modelo Transformer, mientras que RT significa respuestas seleccionadas aleatoriamente del conjunto de entrenamiento y GT significa respuestas reales sobre el terreno. Para obtener una explicación de las métricas, consulte el artículo.
S2S es un modelo seq2seq simple con LSTM entrenados en Cornell, otros son modelos Transformer. Opensubtitles F está previamente entrenado en Opensubtitles y ajustado en Cornell. 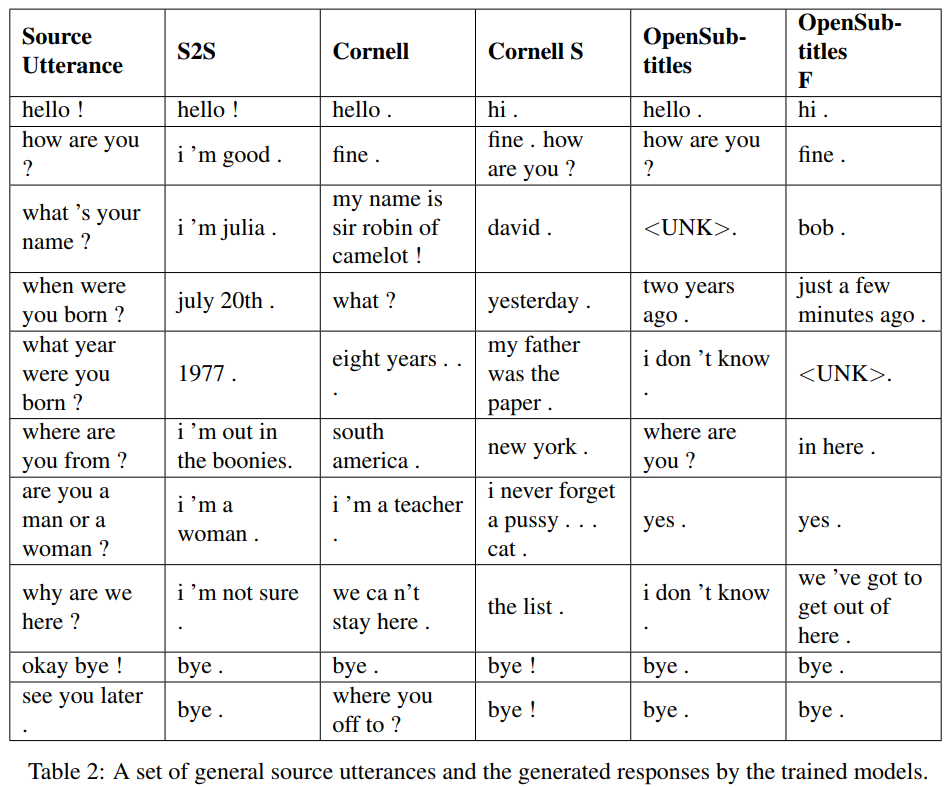
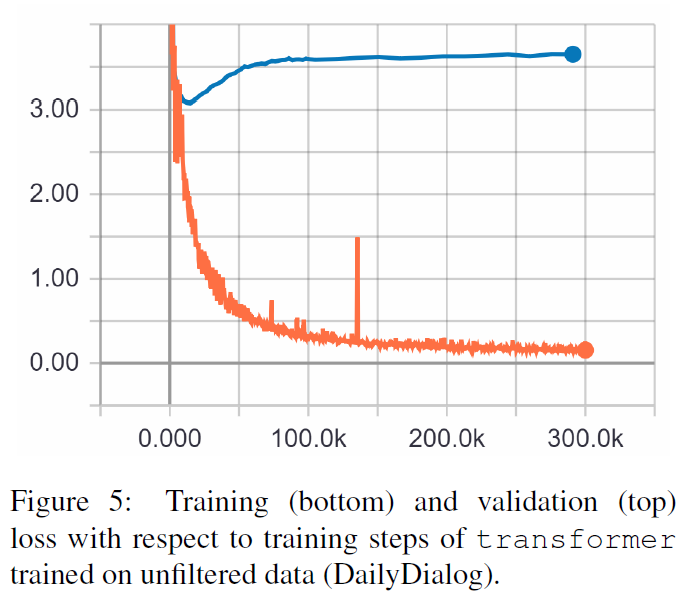

TRF es el modelo Transformer, mientras que RT significa respuestas seleccionadas aleatoriamente del conjunto de entrenamiento y GT significa respuestas reales sobre el terreno. Para obtener una explicación de las métricas, consulte el artículo.
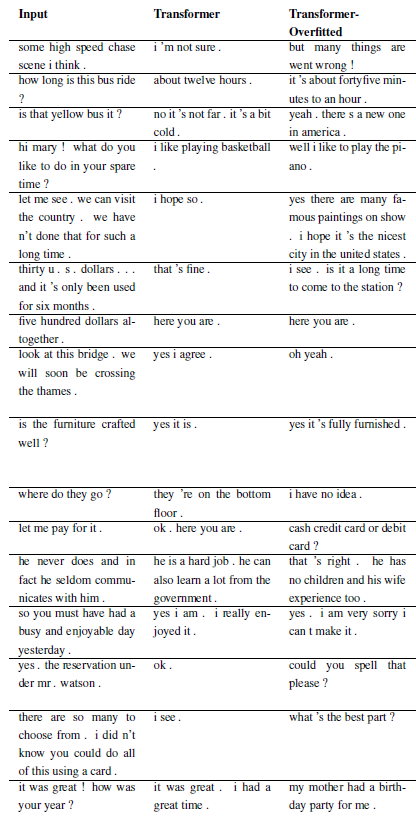
Se pueden registrar nuevos problemas subclasificando WordChatbot, o incluso mejor subclasificando CornellChatbotBasic u OpensubtitleChatbot, porque implementan algunas funcionalidades adicionales. Normalmente es suficiente anular las funciones preproceso y create_data . Consulte la documentación para obtener más detalles y consulte daily_dialog_chatbot para ver un ejemplo.
Se pueden agregar nuevos modelos e hiperparámetros siguiendo el tutorial de tensor2tensor.
Richard Csaky (Si necesita ayuda para ejecutar el código: [email protected])
Este proyecto tiene la licencia MIT; consulte el archivo de LICENCIA para obtener más detalles.
Incluya un enlace a este repositorio si lo utiliza en su trabajo y considere citar el siguiente documento:
@InProceedings{Csaky:2017,
title = {Deep Learning Based Chatbot Models},
author = {Csaky, Richard},
year = {2019},
publisher={National Scientific Students' Associations Conference},
url ={https://tdk.bme.hu/VIK/DownloadPaper/asdad},
note={https://tdk.bme.hu/VIK/DownloadPaper/asdad}
} 

