text dependency parser
1.0.0
Análisis de dependencia 
datos
Ejecute el programa: entrene el modelo y evalúe
Explorar dependencias
Apéndice: Explicación de las partes del discurso
Apéndice: Análisis sintáctico (árbol de sintaxis)
Apéndice: Representación de relaciones
Descripción del formato: formato CoNLL-U
En este programa se requieren al menos las primeras 10 columnas de datos en este formato:
| Lista | nombre | significado |
|---|---|---|
| 1 | IDENTIFICACIÓN | ID de palabra a partir de 1 |
| 2 | FORMA | palabra |
| 3 | LEMA | Raíz inglesa, significado chino |
| 4 | UPOSTAG | Partes del discurso (un conjunto de partes del discurso resumidas en todos los idiomas) |
| 5 | XPOSTAG | Partes del discurso no universales (específicas del idioma) |
| 6 | hazañas | Características morfológicas |
| 7 | CABEZA | El nodo padre al que pertenece esta palabra |
| 8 | DEPREL | Relación con el nodo padre |
| 9 | DEPÓSITO | nodo asociado secundario |
| 10 | MISC | Otra información complementaria |
En cada una de las columnas anteriores, un valor de '_' significa no disponible.
En este programa, las columnas 3, 5, 6, 9 y 10 pueden tener '_' y las demás columnas deben tener valores válidos.
https://github.com/UniversalDependencies/UD_Chinese-GSD
https://github.com/UniversalDependencies/UD_English-EWT
Conjuntos de capacitación y conjuntos de desarrollo proporcionados por la Universidad de Tsinghua y el Instituto de Tecnología de Harbin
Consulte otros conjuntos de datos.
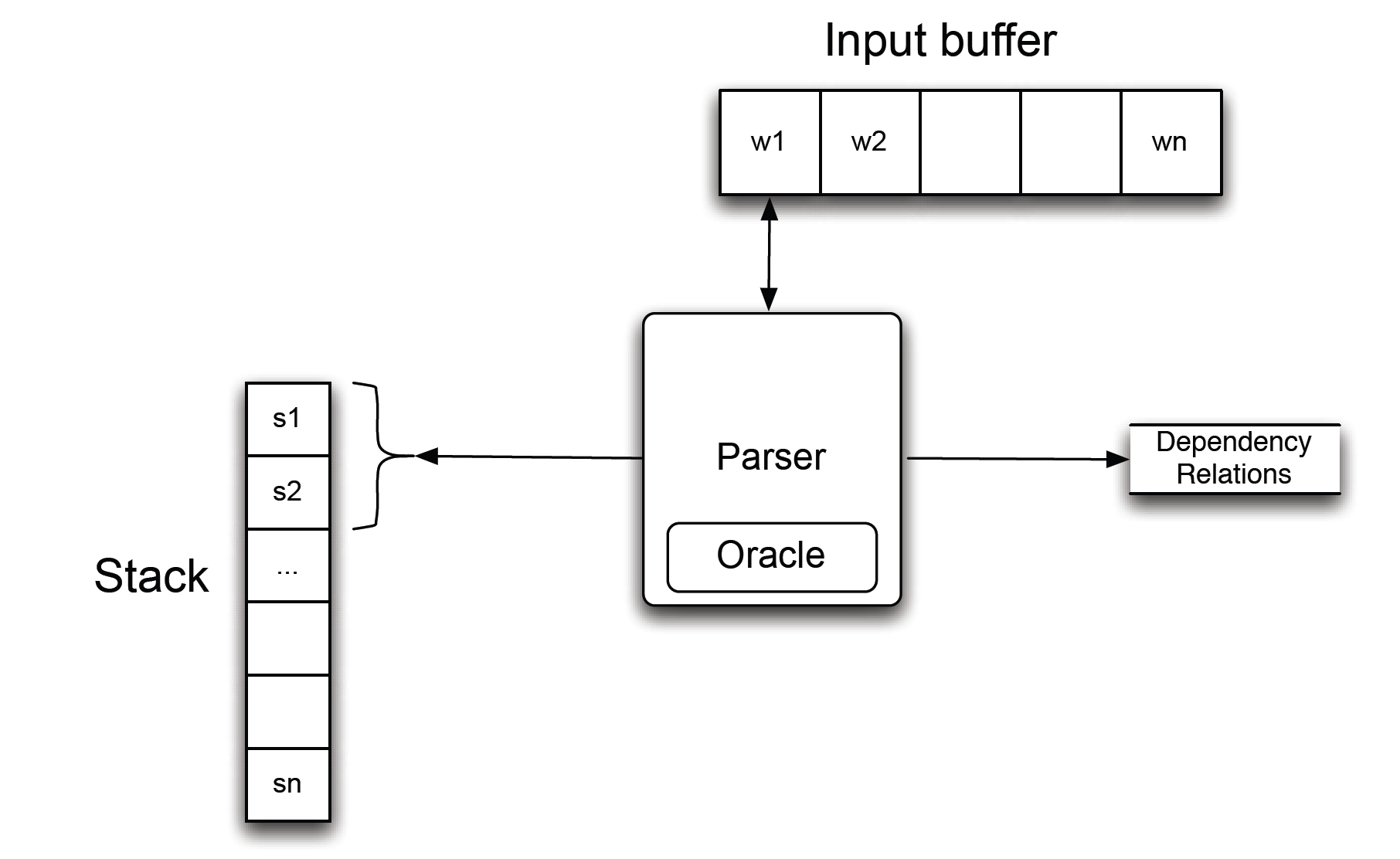
Introducción detallada: análisis de dependencias
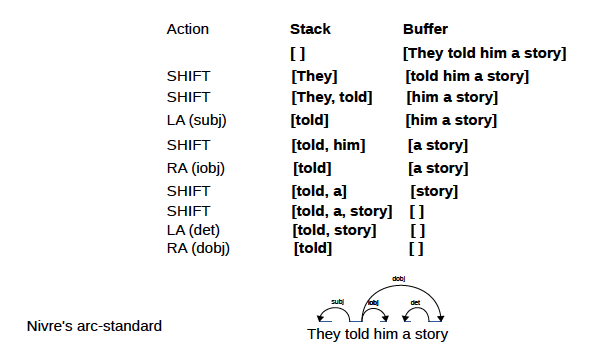
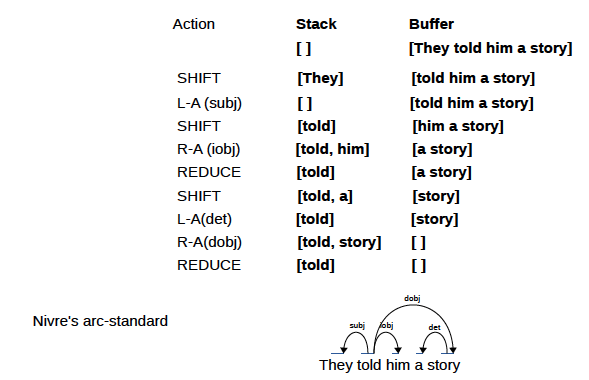
Al actualizar específicamente el árbol de dependencia de una oración, hay dos ideas: estándar (de abajo hacia arriba) y ansioso (de arriba a abajo).
Dependencias: py2.7
pip install -r requirements.txt
admin/standard.thu.train.sh # 训练中文模型
admin/standard.thu.test.sh # 测试中文模型
admin/standard.ewt.train.sh # 训练英文模型
admin/standard.ewt.test.sh # 测试英文模型
admin/eager.thu.train.sh # 训练中文模型
admin/eager.thu.test.sh # 测试中文模型
admin/eager.ewt.train.sh # 训练英文模型
admin/eager.ewt.test.sh # 测试英文模型
Resultados para UD_Chino-GSD :
I0316 23:19:25.249176 140736085984064 eager.py:152] accuracy: 0.760666326704
I0316 23:19:25.249367 140736085984064 eager.py:153] complete: 0.206
I0316 23:19:25.389566 140736085984064 eager.py:156] recall: 0.745088245088
I0316 23:19:25.391751 140736085984064 eager.py:158] precision: 0.760666326704
I0316 23:19:25.391916 140736085984064 eager.py:159] assigned: 0.97952047952
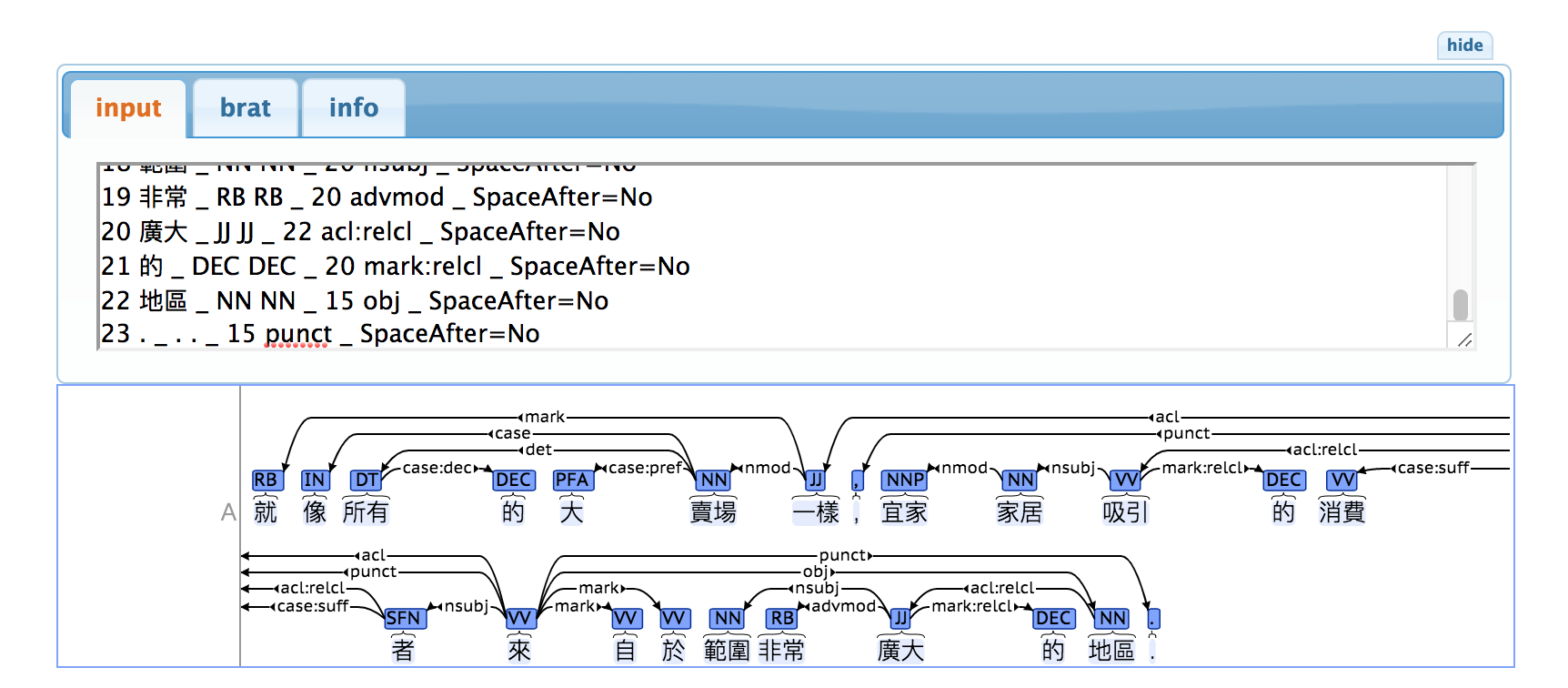
Utilice conllu.js para explorar dependencias: abra la página web, haga clic en el botón "editar" y pegue el contenido en formato CoNLL-U en el editor. Por ejemplo, pegue el siguiente contenido en la página web conllu.js.
1 就 _ RB RB _ 7 mark _ SpaceAfter=No
2 像 _ IN IN _ 6 case _ SpaceAfter=No
3 所有 _ DT DT _ 6 det _ SpaceAfter=No
4 的 _ DEC DEC _ 3 case:dec _ SpaceAfter=No
5 大 _ PFA PFA _ 6 case:pref _ SpaceAfter=No
6 賣場 _ NN NN _ 7 nmod _ SpaceAfter=No
7 一樣 _ JJ JJ _ 15 acl _ SpaceAfter=No
8 , _ , , _ 15 punct _ SpaceAfter=No
9 宜家 _ NNP NNP _ 10 nmod _ SpaceAfter=No
10 家居 _ NN NN _ 11 nsubj _ SpaceAfter=No
11 吸引 _ VV VV _ 14 acl:relcl _ SpaceAfter=No
12 的 _ DEC DEC _ 11 mark:relcl _ SpaceAfter=No
13 消費 _ VV VV _ 14 case:suff _ SpaceAfter=No
14 者 _ SFN SFN _ 15 nsubj _ SpaceAfter=No
15 來 _ VV VV _ 0 root _ SpaceAfter=No
16 自 _ VV VV _ 15 mark _ SpaceAfter=No
17 於 _ VV VV _ 15 mark _ SpaceAfter=No
18 範圍 _ NN NN _ 20 nsubj _ SpaceAfter=No
19 非常 _ RB RB _ 20 advmod _ SpaceAfter=No
20 廣大 _ JJ JJ _ 22 acl:relcl _ SpaceAfter=No
21 的 _ DEC DEC _ 20 mark:relcl _ SpaceAfter=No
22 地區 _ NN NN _ 15 obj _ SpaceAfter=No
23 . _ . . _ 15 punct _ SpaceAfter=No
NOTA: Incluya la línea en blanco debajo de la línea 17 al pegar porque las líneas en blanco sirven como marcadores entre oraciones.
Se obtiene el siguiente árbol de dependencia:
app/standard.py y app/eager.py son códigos de entrenamiento y la implementación principal del analizador de transición está en app/transitionparser.py .
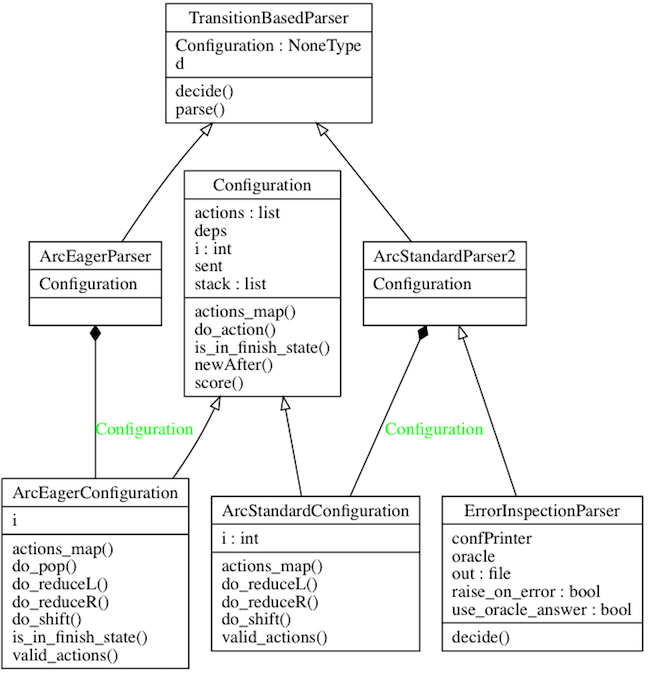
Dependencias: ArcEagerConfiguration --> ArcEagerParser, ArcStandardConfiguration --> ArcStandardParser2
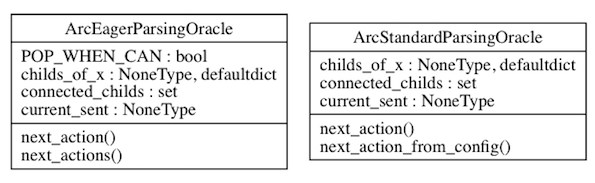
Código: 
Código: 
Introducción al análisis sintáctico.
Tarea compartida CoNLL-2009: dependencias sintácticas y semánticas en múltiples idiomas
Analizadores de dependencia basados en transiciones
conllu.js
python︱Pruebe seis módulos de segmentación de palabras chinas: jieba, THULAC, SnowNLP, pynlpir, CoreNLP, pyLTP
[1] Liang Huang, Wenbin Jiang y Qun Liu 2009. Análisis de reducción de cambios bilingüe restringido (monolingüe).
CC: conjunction, coordinatin 表示连词
CD: numeral, cardinal 表示基数词
DT: determiner 表示限定词
EX: existential there 存在句
FW: foreign word 外来词
IN: preposition or conjunction, subordinating 介词或从属连词
JJ: adjective or numeral, ordinal 形容词或序数词
JJR: adjective, comparative 形容词比较级
JJS: adjective, superlative 形容词最高级
LS: list item marker 列表标识
MD: modal auxiliary 情态助动词
NN: noun, common, singular or mass
NNS: noun, common, plural
NNP: noun, proper, singular
NNPS: noun, proper, plural
PDT: pre-determiner 前位限定词
POS: genitive marker 所有格标记
PRP: pronoun, personal 人称代词
PRP:pronoun,possessive所有格代词RB:adverb副词RBR:adverb,comparative副词比较级RBS:adverb,superlative副词最高级RP:particle小品词SYM:symbol符号TO:”to”asprepositionorinfinitivemarker作为介词或不定式标记UH:interjection插入语VB:verb,baseformVBD:verb,pasttenseVBG:verb,presentparticipleorgerundVBN:verb,pastparticipleVBP:verb,presenttense,not3rdpersonsingularVBZ:verb,presenttense,3rdpersonsingularWDT:WH−determinerWH限定词WP:WH−pronounWH代词WP: WH-pronoun, possessive WH所有格代词
WRB:Wh-adverb WH副词
Estándar chino de etiquetado de parte del discurso: conjunto de etiquetas de parte del discurso ICTPOS3.0
ROOT:要处理文本的语句
IP:简单从句
NP:名词短语
VP:动词短语
PU:断句符,通常是句号、问号、感叹号等标点符号
LCP:方位词短语
PP:介词短语
CP:由‘的’构成的表示修饰性关系的短语
DNP:由‘的’构成的表示所属关系的短语
ADVP:副词短语
ADJP:形容词短语
DP:限定词短语
QP:量词短语
NN:常用名词
NR:固有名词:表示仅适用于该项事物的名词,含地名,人名,国名,书名,团体名称以及一事件的名称等。
NT:时间名词
PN:代词
VV:动词
VC:是
CC:表示连词
VE:有
VA:表语形容词
AS:内容标记(如:了)
VRD:动补复合词
CD: 表示基数词
DT: determiner 表示限定词
EX: existential there 存在句
FW: foreign word 外来词
IN: preposition or conjunction, subordinating 介词或从属连词
JJ: adjective or numeral, ordinal 形容词或序数词
JJR: adjective, comparative 形容词比较级
JJS: adjective, superlative 形容词最高级
LS: list item marker 列表标识
MD: modal auxiliary 情态助动词
PDT: pre-determiner 前位限定词
POS: genitive marker 所有格标记
PRP: pronoun, personal 人称代词
RB: adverb 副词
RBR: adverb, comparative 副词比较级
RBS: adverb, superlative 副词最高级
RP: particle 小品词
SYM: symbol 符号
TO:”to” as preposition or infinitive marker 作为介词或不定式标记
WDT: WH-determiner WH限定词
WP: WH-pronoun WH代词
WP$: WH-pronoun, possessive WH所有格代词
WRB:Wh-adverb WH副词
abbrev: abbreviation modifier,缩写
acomp: adjectival complement,形容词的补充;
advcl : adverbial clause modifier,状语从句修饰词
advmod: adverbial modifier状语
agent: agent,代理,一般有by的时候会出现这个
amod: adjectival modifier形容词
appos: appositional modifier,同位词
attr: attributive,属性
aux: auxiliary,非主要动词和助词,如BE,HAVE SHOULD/COULD等到
auxpass: passive auxiliary 被动词
cc: coordination,并列关系,一般取第一个词
ccomp: clausal complement从句补充
complm: complementizer,引导从句的词好重聚中的主要动词
conj : conjunct,连接两个并列的词。
cop: copula。系动词(如be,seem,appear等),(命题主词与谓词间的)连系
csubj : clausal subject,从主关系
csubjpass: clausal passive subject 主从被动关系
dep: dependent依赖关系
det: determiner决定词,如冠词等
dobj : direct object直接宾语
expl: expletive,主要是抓取there
infmod: infinitival modifier,动词不定式
iobj : indirect object,非直接宾语,也就是所以的间接宾语;
mark: marker,主要出现在有“that” or “whether”“because”, “when”,
mwe: multi-word expression,多个词的表示
neg: negation modifier否定词
nn: noun compound modifier名词组合形式
npadvmod: noun phrase as adverbial modifier名词作状语
nsubj : nominal subject,名词主语
nsubjpass: passive nominal subject,被动的名词主语
num: numeric modifier,数值修饰
number: element of compound number,组合数字
parataxis: parataxis: parataxis,并列关系
partmod: participial modifier动词形式的修饰
pcomp: prepositional complement,介词补充
pobj : object of a preposition,介词的宾语
poss: possession modifier,所有形式,所有格,所属
possessive: possessive modifier,这个表示所有者和那个’S的关系
preconj : preconjunct,常常是出现在 “either”, “both”, “neither”的情况下
predet: predeterminer,前缀决定,常常是表示所有
prep: prepositional modifier
prepc: prepositional clausal modifier
prt: phrasal verb particle,动词短语
punct: punctuation,这个很少见,但是保留下来了,结果当中不会出现这个
purpcl : purpose clause modifier,目的从句
quantmod: quantifier phrase modifier,数量短语
rcmod: relative clause modifier相关关系
ref : referent,指示物,指代
rel : relative
root: root,最重要的词,从它开始,根节点
tmod: temporal modifier
xcomp: open clausal complement
xsubj : controlling subject 掌控者
https://bot.chatopera.com/
El servicio en la nube Chatopera es un servicio en la nube integral para implementar robots de chat y se factura según la cantidad de llamadas a la interfaz. Chatopera Cloud Service es una instancia de software como servicio de la plataforma de bot Chatopera. Basado en la computación en la nube, el servicio en la nube Chatopera es un servicio en la nube de chatbot como servicio .
La plataforma del robot Chatopera incluye componentes como base de conocimientos, diálogo de múltiples rondas, reconocimiento de intenciones y reconocimiento de voz, desarrollo de robots de chat estandarizados y admite escenarios como preguntas y respuestas inteligentes de acceso abierto empresarial, preguntas y respuestas inteligentes de recursos humanos, servicio al cliente inteligente y marketing en línea. ¡Los departamentos de TI empresariales y los departamentos comerciales utilizan los servicios en la nube de Chatopera para poner rápidamente los chatbots en línea!
Diccionario personalizado
Términos personalizados
Crear intención
Agregar argumentos y espacios
Modelo de entrenamiento
conversación de prueba
retrato de robot
Integración del sistema
Historial de chat
Usar ahora