turing
v0.3.8
Viglet Turing ES (https://openviglet.github.io/turing/) es una solución de código abierto (https://github.com/openturing), que tiene como características principales la navegación semántica y el bot de chat. Puede elegir entre varias PNL para enriquecer los datos. Todo el contenido está indexado en Solr como motor de búsqueda.
La documentación técnica sobre Turing ES está disponible en https://openviglet.github.io/docs/turing/.
Para ejecutar Turing ES, simplemente ejecute las siguientes líneas:
# Turing Appmvn -Dmaven.repo.local=D:repo spring-boot:run -pl turing-app -Dskip.npm# Nueva interfaz de usuario de Turing ES usando Angular 18 y Primer CSS.cd turing-ui## Servicio de inicio de sesión bienvenido## Consoleng servir consola## Searchng servir sn## Chat botng servir conversar
Puede iniciar Turing ES usando MariaDB, Solr y Nginx.
Docker-componer
Consola de administración: http://localhost:2700. (administrador/administrador)
Muestra de navegación semántica: http://localhost:2700/sn/Sample.
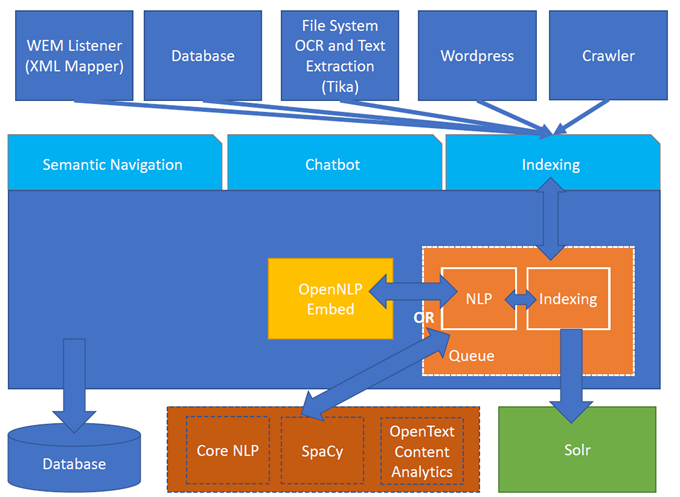
Figura 1. Arquitectura de Turing ES
Turing admite los siguientes proveedores:
Apache OpenNLP es un conjunto de herramientas basado en aprendizaje automático para el procesamiento de texto en lenguaje natural.
Sitio web: https://opennlp.apache.org/
Transforma los datos en conocimientos para una mejor toma de decisiones y gestión de la información, al tiempo que libera recursos y tiempo.
Sitio web: https://www.opentext.com/
¡CoreNLP es su ventanilla única para el procesamiento de lenguaje natural en Java! CoreNLP permite a los usuarios derivar anotaciones lingüísticas para texto, incluidos límites de tokens y oraciones, partes del discurso, entidades nombradas, valores numéricos y de tiempo, análisis de dependencias y circunscripciones, correferencias, sentimientos, atribuciones de citas y relaciones. CoreNLP actualmente admite 6 idiomas: árabe, chino, inglés, francés, alemán y español.
Sitio web: https://stanfordnlp.github.io/CoreNLP/,
Es una biblioteca gratuita de código abierto para el procesamiento del lenguaje natural en Python. Cuenta con NER, etiquetado POS, análisis de dependencias, vectores de palabras y más.
Sitio web: https://spacy.io
Polyglot es un canal de lenguaje natural que admite aplicaciones multilingües masivas.
Sitio web: https://polyglot.readthedocs.io
Puede leer archivos PDF y documentos y convertirlos a texto sin formato, y también utiliza OCR para detectar texto en imágenes e imágenes en documentos.
La navegación semántica utiliza conectores para indexar el contenido de muchas fuentes.
Complemento para Apache Nutch para indexar contenido mediante un rastreador.
Obtenga más información en https://docs.viglet.com/turing/connectors/#nutch
Línea de comando que utiliza el mismo concepto que sqoop (https://sqoop.apache.org/), para crear consultas complejas y asignar atributos para indexar en función del resultado.
Obtenga más información en https://docs.viglet.com/turing/connectors/#database
Línea de comando para indexar archivos, extrayendo texto de archivos como Word, Excel, PDF, incluidas imágenes, mediante OCR.
Obtenga más información en https://docs.viglet.com/turing/connectors/#file-system
OpenText WEM Listener para publicar contenido en Viglet Turing.
Obtenga más información en https://docs.viglet.com/turing/connectors/#wem
Complemento de WordPress que te permite indexar publicaciones.
Obtenga más información en https://docs.viglet.com/turing/connectors/#wordpress
Con PNL es posible detectar entidades como:
Gente
Lugares
Organizaciones
Dinero
Tiempo
Porcentaje
Defina atributos que serán utilizados como filtros para su navegación, consolidando el contenido total en su display.
A través de atributos definidos en los contenidos, es posible utilizarlos para restringir su visualización en función del perfil del usuario.
La API de Java (https://github.com/openturing/turing-java-sdk) facilita el uso y el acceso a Viglet Turing ES, sin la necesidad de que el consumidor busque contenido con consultas complejas.
Comuníquese con su cliente y elabore intenciones complejas, obtenga informes y evolucione progresivamente su interacción.
Sus componentes:
Maneja conversaciones con sus usuarios finales. Es un módulo de procesamiento del lenguaje natural que comprende los matices del lenguaje humano.
Una intención categoriza la intención de un usuario final de realizar un cambio de conversación. Para cada agente, usted define varias intenciones, donde sus intenciones combinadas pueden manejar una conversación completa.
El campo de acción es un campo simple de conveniencia que ayuda a ejecutar la lógica en el servicio.
Cada parámetro de intención tiene un tipo, llamado tipo de entidad, que dicta exactamente cómo se extraen los datos en una expresión de usuario final.
Define y corrige intenciones.
Muestra el historial de conversaciones y los informes.
Turing ES detecta entidades de documentos OpenText Blazon utilizando OCR y NLP, generando Blazon XML para mostrar las entidades en el documento.
Turing ES tiene muchos componentes: motor de búsqueda, PNL, Converse (bot de chat), navegación semántica
Cuando acceda a Turing ES, aparecerá una página de inicio de sesión. Por defecto el nombre de usuario/contraseña es admin / admin
Figura 2. Página de inicio de sesión
Turing utiliza el motor de búsqueda para almacenar y recuperar datos de Converse (bot de chat) y sitios de navegación semántica.
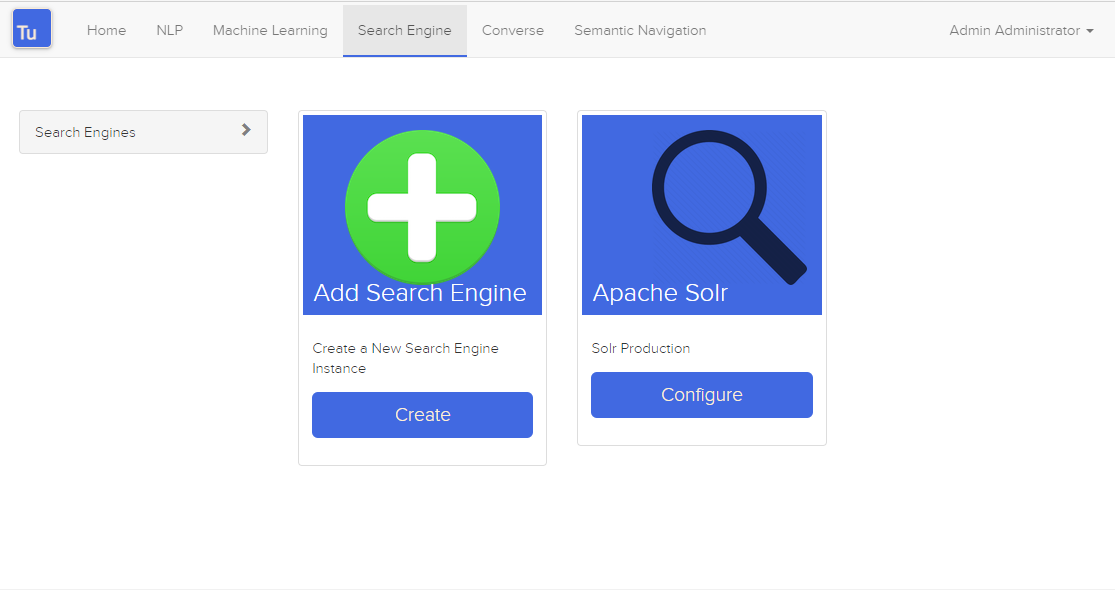
Figura 3. Página del motor de búsqueda
Es posible crear o editar un Motor de Búsqueda con los siguientes atributos:
| Atributo | Descripción |
|---|---|
Nombre | Nombre del motor de búsqueda |
Descripción | Descripción del motor de búsqueda |
Proveedor | Seleccione el proveedor del motor de búsqueda. Por ahora, sólo es compatible con Solr. |
Anfitrión | Nombre del host donde está instalado el servicio del motor de búsqueda |
Puerto | Puerto de servicio de motor de búsqueda |
Idioma | Idioma del servicio del motor de búsqueda. |
Activado | Si el Buscador está habilitado. |
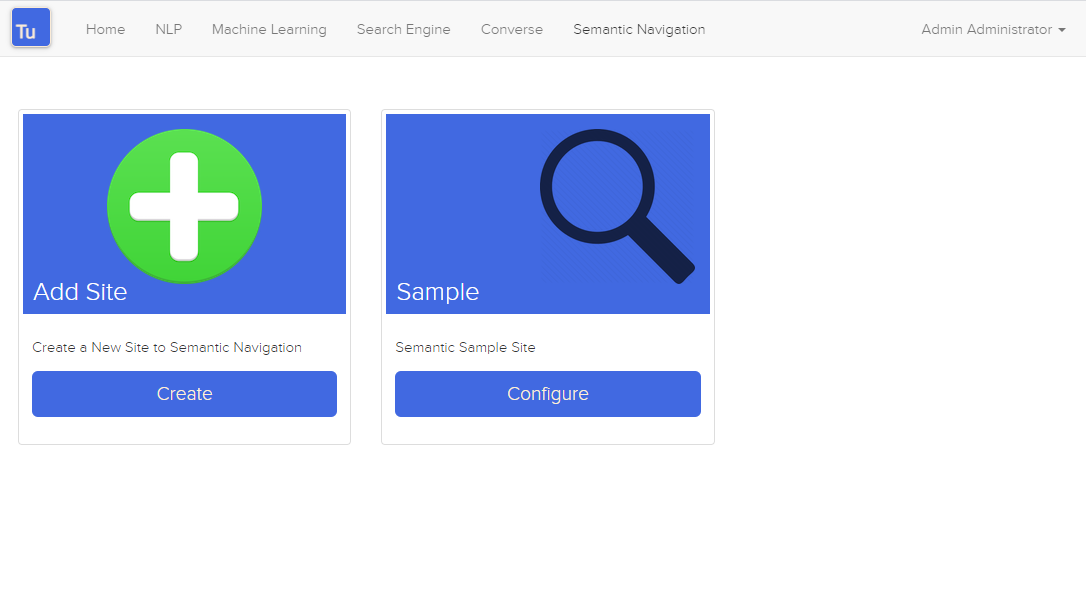
Figura 4. Página de navegación semántica
El Detalle del Sitio de Navegación Semántica contiene los siguientes atributos:
| Atributo | Descripción |
|---|---|
Nombre | Nombre del Sitio de Navegación Semántica. |
Descripción | Descripción del Sitio de Navegación Semántica. |
Motor de búsqueda | Seleccione el motor de búsqueda que se creó en la sección Motor de búsqueda. El Sitio de Navegación Semántica utilizará este Motor de Búsqueda para almacenar y recuperar datos. |
PNL | Seleccione la PNL que se creó en la sección PNL. El Sitio de Navegación Semántica utilizará este PNL para detectar entidades durante la indexación. |
Tesauro | Si utiliza el diccionario de sinónimos. |
Idioma | Lenguaje de Navegación Semántica del Sitio. |
Centro | Nombre del núcleo del motor de búsqueda donde se almacenarán y recuperarán los datos. |
La pestaña Campos contiene una tabla con las siguientes columnas: .Columnas de campos del sitio de navegación semántica
| Nombre de columna | Descripción |
|---|---|
Tipo | Tipo de campo. Puede ser: - NER (Reconocimiento de entidad nombrada) utilizado por PNL. - Buscador utilizado por Solr. |
Campo | Nombre del campo. |
Activado | Si el campo está habilitado o no. |
MLT | Si este campo se utilizará en MLT. |
facetas | Para utilizar este campo como una faceta (filtro) |
Destacando | Si este campo mostrará líneas resaltadas. |
PNL | Si este campo será procesado por PNL para detectar entidades (NER) como personas, organización y lugar. |
Al hacer clic en Campo aparece una nueva página con Detalles del campo con los siguientes atributos:
| Atributo | Descripción |
|---|---|
Nombre | Nombre del campo |
Descripción | Descripción del campo |
Tipo | Tipo de campo. Puede ser: |
Valor múltiple | si es una matriz |
Nombre de faceta | Nombre de la etiqueta de la faceta (filtro) en la página de búsqueda. |
Faceta | Para utilizar este campo como una faceta (filtro) |
Destacando | Si este campo mostrará líneas resaltadas. |
MLT | Si este campo se utilizará en MLT. |
Activado | Si el campo está habilitado. |
Requerido | Si el campo es obligatorio. |
Valor predeterminado | En caso de que el contenido esté indexado sin estos campos, ese es el valor predeterminado. |
PNL | Si este campo será procesado por PNL para detectar entidades (NER) como personas, organización y lugar. |
Contiene los siguientes atributos:
| Sección | Atributo | Descripción |
|---|---|---|
Apariencia | Número de artículos por página | Número de artículos que aparecerán en la búsqueda. |
Faceta | ¿Faceta habilitada? | Si se mostrará Faceta (Filtros) en la búsqueda. |
Número de elementos por faceta | Número de elementos que aparecerán en cada Faceta (Filtro). | |
Destacando | ¿Resaltado habilitado? | Defina si se mostrarán las líneas resaltadas. |
Etiqueta previa | Etiqueta HTML que se utilizará al inicio del semestre. Por ejemplo: <marca> | |
Etiqueta de publicación | Etiqueta HTML que se utilizará al final del período. Por ejemplo: </marca> | |
MLT | ¿Más como este habilitado? | Definir si mostrar MLT |
Campos predeterminados | Título | Campo que se utilizará como título definido en Solr esquema.xml |
Texto | Campo que se utilizará como título definido en Solr esquema.xml | |
Descripción | Campo que se utilizará como descripción definida en Solr esquema.xml | |
Fecha | Campo que se utilizará como fecha definida en Solr esquema.xml | |
Imagen | Campo que se utilizará como URL de imagen definida en Solr esquema.xml | |
URL | Campo que se utilizará como URL definida en Solr esquema.xml |
En Turing ES Console > Semantic Navigation > <SITE_NAME> , haga clic en el botón Configure y haga clic en el botón Search Page .
Se abrirá una página de búsqueda que utiliza el patrón:
OBTENER http://localhost:2700/sn/<NOMBRE_SITIO>
Esta página solicita la API Turing Rest a través de AJAX. Por ejemplo, para devolver todos los resultados del sitio de navegación semántica en formato JSON:
OBTENER http://localhost:2700/api/sn/<SITE_NAME>/search?p=1&q=*&sort=relevance
| Atributo | Requerido / Opcional | Descripción | Ejemplo |
|---|---|---|---|
q | Requerido | Consulta de búsqueda. | q=fu |
pag | Requerido | Número de página, la primera página es 1. | p=1 |
clasificar | Requerido | Ordenar valores: | ordenar=relevancia |
fq[] | Opcional | Campo de consulta. Filtre por campo, usando el siguiente patrón: CAMPO : VALOR . | fq[]=título:barra |
tr[] | Opcional | Regla de focalización. Restringir la búsqueda basada en: CAMPO : VALOR . | tr[]=departamento:foobar |
filas | Opcional | Número de filas que devolverá la consulta. | filas=10 |
En la Intranet de la Compañía de Seguros se utiliza OpenText WEM y OpenText Portal integrado con el Módulo Dynamic Portal, se creó una búsqueda consolidada en Viglet Turing ES, utilizando los conectores: WEM, Base de Datos con Sistema de Archivos. De esta manera fue posible visualizar todos los contenidos y archivos de la Intranet de búsqueda, con reglas de segmentación, permitiendo mostrar sólo contenidos que el usuario tenga permiso. El Portal OpenText accede a la API Java de Viglet Turing ES, por lo que no fue necesario crear consultas complejas para devolver los resultados.
Se creó un conjunto de API Rest para que todo el contenido de la empresa gubernamental esté disponible para los socios. Todos estos contenidos están en OpenText WEM y el conector WEM se utilizó para indexar los contenidos en Viglet Turing ES. Se creó una aplicación Spring Boot con el conjunto de API Rest que consume contenido de Turing ES a través de la API Java de Viglet Turing ES.
El sitio web de la Universidad Brasileña se desarrolló utilizando Viglet Shio CMS (https://viglet.com/shio) y todos los contenidos se indexan automáticamente en Viglet Turing ES. Esta configuración se realizó en modelado de contenido y el desarrollo de la plantilla de búsqueda se realizó en Viglet Shio CMS.


