GenDataAttribution
1.0.0
Proyecto | Papel
Sheng-Yu Wang 1 , Alexei A. Efros 2 , Jun-Yan Zhu 1 , Richard Zhang 3 .
Universidad Carnegie Mellon 1 , UC Berkeley 2 , Adobe Research 2
En ICCV, 2023.
Si bien los modelos grandes de texto a imagen pueden sintetizar imágenes "novedosas", estas imágenes son necesariamente un reflejo de los datos de entrenamiento. El problema de la atribución de datos en tales modelos (cuáles de las imágenes del conjunto de entrenamiento son las más responsables de la apariencia de una imagen generada determinada) es difícil pero importante. Como paso inicial hacia este problema, evaluamos la atribución mediante métodos de "personalización", que ajustan un modelo existente a gran escala hacia un objeto o estilo ejemplar determinado. Nuestra idea clave es que esto nos permite crear de manera eficiente imágenes sintéticas que están influenciadas computacionalmente por el ejemplo por construcción. Con nuestro nuevo conjunto de datos de imágenes influenciadas por ejemplos, podemos evaluar varios algoritmos de atribución de datos y diferentes espacios de características posibles. Además, al entrenar con nuestro conjunto de datos, podemos ajustar modelos estándar, como DINO, CLIP y ViT, al problema de atribución. Aunque el procedimiento está orientado a conjuntos ejemplares pequeños, mostramos la generalización a conjuntos más grandes. Finalmente, al tener en cuenta la incertidumbre inherente del problema, podemos asignar puntuaciones de atribución suaves a un conjunto de imágenes de entrenamiento.
conda env create -f environment.yaml
conda activate gen-attr # Download precomputed features of 1M LAION images
bash feats/download_laion_feats.sh
# Download jpeg-ed 1M LAION images for visualization
bash dataset/download_dataset.sh laion_jpeg
# Download pretrained models
bash weights/download_weights.sh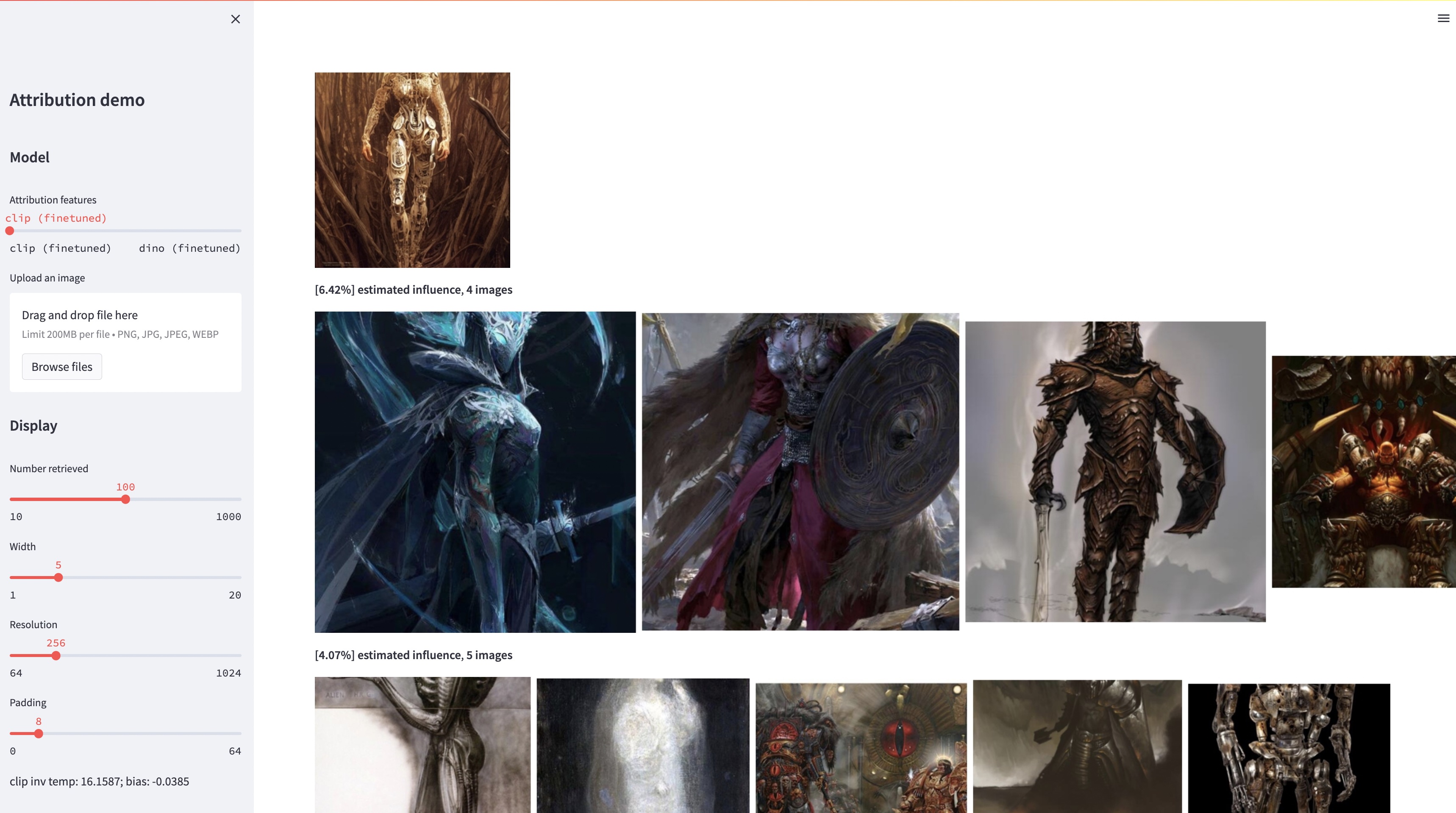
streamlit run streamlit_demo.pyLanzamos nuestro conjunto de pruebas para su evaluación. Para descargar el conjunto de datos:
# Download the exemplar real images
bash dataset/download_dataset.sh exemplar
# Download the testset portion of images synthesized from Custom Diffusion
bash dataset/download_dataset.sh testset
# (Optional, can download precomputed features instead!)
# Download the uncompressed 1M LAION subset in pngs
bash dataset/download_dataset.sh laionEl conjunto de datos está estructurado de la siguiente manera:
dataset
├── exemplar
│ ├── artchive
│ ├── bamfg
│ └── imagenet
├── synth
│ ├── artchive
│ ├── bamfg
│ └── imagenet
├── laion_subset
└── json
├──test_artchive.json
├──test_bamfg.json
├──...
Todas las imágenes ejemplares se almacenan en dataset/exemplar , todas las imágenes sintetizadas se almacenan en dataset/synth y 1 millón de imágenes laion en pngs se almacenan en dataset/laion_subset . Los archivos JSON en dataset/json especifican las divisiones tren/val/prueba, incluidos diferentes casos de prueba, y sirven como etiquetas de verdad sobre el terreno. Cada entrada dentro de un archivo JSON es un modelo único y ajustado. Una entrada también registra las imágenes ejemplares utilizadas para el ajuste fino y las imágenes sintetizadas generadas por el modelo. Tenemos cuatro casos de prueba: test_artchive.json , test_bamfg.json , test_observed_imagenet.json y test_unobserved_imagenet.json .
Después de descargar el conjunto de pruebas, las características LAION precalculadas y los pesos previamente entrenados, podemos precalcular las características del conjunto de pruebas ejecutando extract_feat.py y luego evaluar el rendimiento ejecutando eval.py A continuación se muestran los scripts de bash que ejecutan la evaluación en lotes:
# precompute all features from the testset
bash scripts/preprocess_feats.sh
# run evaluation in batches
bash scripts/run_eval.sh Las métricas se almacenan en archivos .pkl en results . Actualmente, el script ejecuta cada comando de forma secuencial. No dude en modificarlo para ejecutar los comandos en paralelo. El siguiente comando analizará los archivos .pkl en tablas almacenadas como archivos .csv :
python results_to_csv.py Actualización 18/12/2023 Para descargar modelos entrenados solo en modelos centrados en objetos o centrados en estilos, ejecute bash weights/download_style_object_ablation.sh
@inproceedings{wang2023evaluating,
title={Evaluating Data Attribution for Text-to-Image Models},
author={Wang, Sheng-Yu and Efros, Alexei A. and Zhu, Jun-Yan and Zhang, Richard},
booktitle={ICCV},
year={2023}
}
Agradecemos a Aaron Hertzmann por leer un borrador anterior y por sus valiosos comentarios. Agradecemos a los colegas de Adobe Research, incluidos Eli Shechtman, Oliver Wang, Nick Kolkin, Taesung Park, John Collomosse y Sylvain Paris, junto con Alex Li y Yonglong Tian por su útil debate. Agradecemos a Nupur Kumari por su orientación con la capacitación de Difusión personalizada, a Ruihan Gao por revisar el borrador, a Alex Li por sus sugerencias para extraer características de Difusión estable y a Dan Ruta por su ayuda con el conjunto de datos BAM-FG. Agradecemos a Bryan Russell por su caminata y lluvia de ideas durante la pandemia. Este trabajo comenzó cuando SYW era pasante de Adobe y fue apoyado en parte por una donación de Adobe y el premio de investigación docente JP Morgan Chase.


