clearml fractional gpu
1.0.0
? Leave a star to support the project! ?
Compartir GPU de alta gama o incluso GPU de prosumidores y consumidores entre varios usuarios es la forma más rentable de acelerar el desarrollo de la IA. Desafortunadamente, hasta ahora la única solución existente se aplicaba a GPU de gama alta MIG/Slicing (A100+) y requería Kubernetes.
? ¡Bienvenido a la GPU fraccionaria basada en contenedores para cualquier tarjeta Nvidia! ?
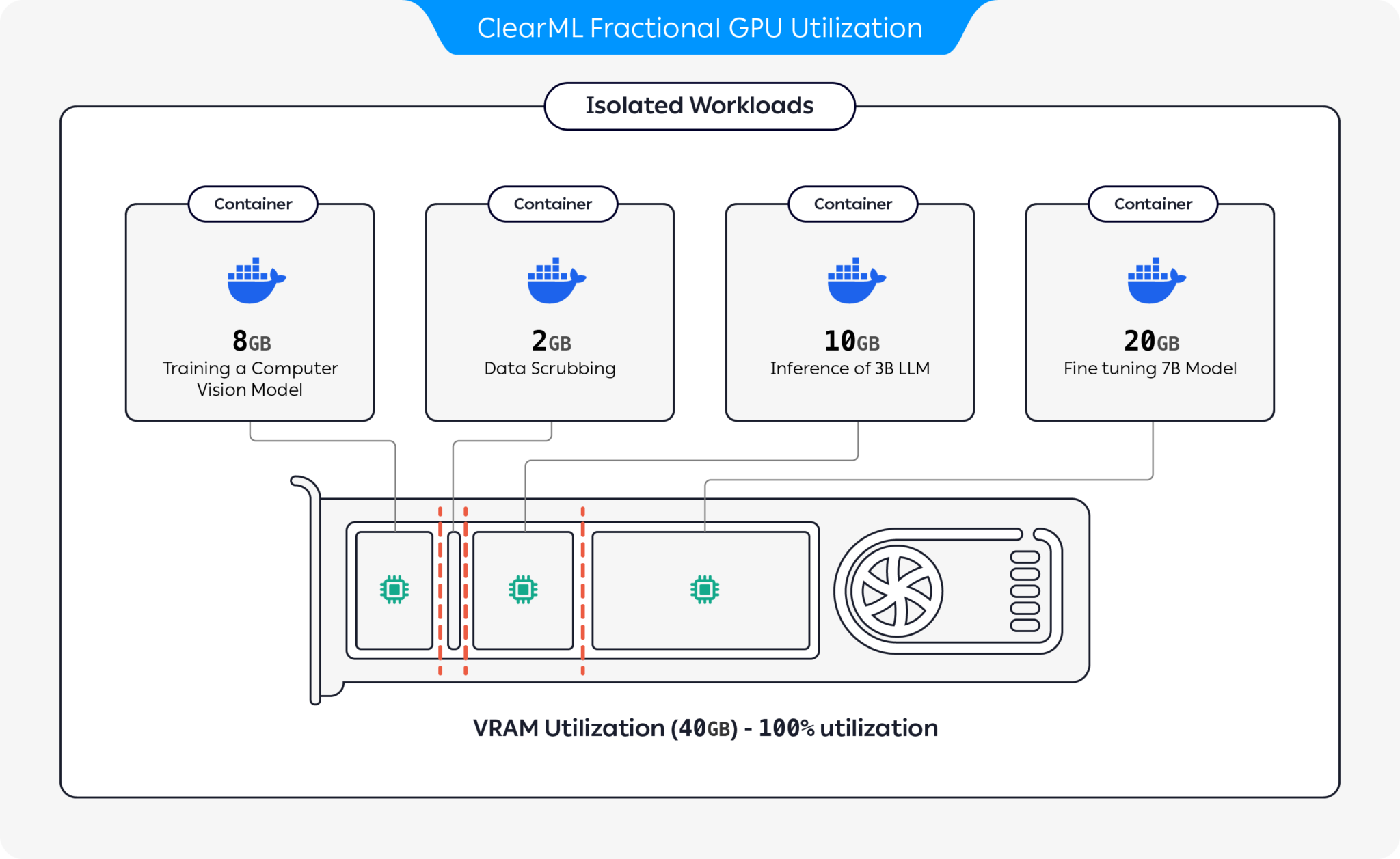
¡Presentamos contenedores preempaquetados que admiten CUDA 11.x y CUDA 12.x con limitación de memoria dura prediseñada! Esto significa que se pueden iniciar varios contenedores en la misma GPU, lo que garantiza que un usuario no pueda asignar toda la memoria de la GPU del host. (¡No más procesos codiciosos que se apoderan de toda la memoria de la GPU! Finalmente, tenemos una opción de memoria de limitación estricta a nivel del controlador).
ClearML ofrece varias opciones para optimizar la utilización de recursos de GPU mediante la partición de GPU:
Con estas opciones, ClearML permite ejecutar cargas de trabajo de IA con una utilización del hardware y un rendimiento de la carga de trabajo optimizados. Este repositorio cubre GPU fraccionarias basadas en contenedores. Para obtener más información sobre las ofertas de GPU fraccionarias de ClearML, consulte la documentación de ClearML.
Elija el contenedor que funcione para usted y ejecútelo:
docker run -it --gpus 0 --ipc=host --pid=host clearml/fractional-gpu:u22-cu12.3-8gb bashPara verificar que el límite de memoria de la GPU de fracción esté funcionando correctamente, ejecute dentro del contenedor:
nvidia-smiAquí hay un ejemplo de salida de la GPU A100:
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 545.23.08 Driver Version: 545.23.08 CUDA Version: 12.3 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 A100-PCIE-40GB Off | 00000000:01:00.0 Off | N/A |
| 32% 33C P0 66W / 250W | 0MiB / 8128MiB | 3% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
+---------------------------------------------------------------------------------------+
| Límite de memoria | Versión CUDA | Versión de Ubuntu | Imagen acoplable |
|---|---|---|---|
| 12GB | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-12gb |
| 12GB | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-12gb |
| 12GB | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-12gb |
| 12GB | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-12gb |
| 8GB | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-8gb |
| 8GB | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-8gb |
| 8GB | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-8gb |
| 8GB | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-8gb |
| 4 GB | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-4gb |
| 4 GB | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-4gb |
| 4 GB | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-4gb |
| 4 GB | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-4gb |
| 2 GB | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-2gb |
| 2 GB | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-2gb |
| 2 GB | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-2gb |
| 2 GB | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-2gb |
Importante
¡Debes ejecutar el contenedor con --pid=host !
Nota
--pid=host es necesario para permitir que el controlador diferencie entre los procesos del contenedor y otros procesos del host al limitar el uso de memoria/utilización.
Consejo
Los usuarios de ClearML-Agent agregan [--pid=host] a su sección agent.extra_docker_arguments en su archivo de configuración
Construya sus propios contenedores y herede de los contenedores originales.
Puedes encontrar algunos ejemplos aquí.
Los contenedores de GPU fraccionados se pueden utilizar en ejecuciones bare-metal, así como en Kubernetes POD. ¡Sí! Al utilizar uno de los contenedores de GPU fraccional, puede limitar el consumo de memoria de su Job/Pod y compartir GPU fácilmente sin temor a que la memoria se bloquee entre sí.
Aquí hay una plantilla POD de Kubernetes simple:
apiVersion : v1
kind : Pod
metadata :
name : train-pod
labels :
app : trainme
spec :
hostPID : true
containers :
- name : train-container
image : clearml/fractional-gpu:u22-cu12.3-8gb
command : ['python3', '-c', 'print(f"Free GPU Memory: (free, global) {torch.cuda.mem_get_info()}")'] Importante
Debes ejecutar el pod con hostPID: true !
Nota
hostPID: true para permitir que el controlador diferencie entre los procesos del pod y otros procesos del host al limitar el uso de memoria/utilización
Los contenedores admiten controladores Nvidia <= 545.xx Seguiremos actualizando y brindando soporte a nuevos controladores a medida que se lancen.
GPU compatibles : RTX series 10, 20, 30, 40, serie A y Data-Center P100, A100, A10/A40, L40/s, H100
Limitaciones : actualmente no se admiten máquinas host con Windows. Si esto es importante para usted, deje una solicitud en la sección Problemas
P : ¿La ejecución nvidia-smi dentro del contenedor informará el consumo de GPU de los procesos locales?
R : Sí, nvidia-smi se comunica directamente con los controladores de bajo nivel e informa tanto la memoria precisa de la GPU del contenedor como la limitación de la memoria local del contenedor.
Tenga en cuenta que la utilización de GPU será la utilización de GPU global (es decir, del lado del host) y no la utilización de GPU del contenedor local específico.
P : ¿Cómo me aseguro de que mi Python/Pytorch/Tensorflow tenga realmente una memoria limitada?
R : Para PyTorch puedes ejecutar:
import torch
print ( f'Free GPU Memory: (free, global) { torch . cuda . mem_get_info () } ' )Ejemplo de Numba:
from numba import cuda
print ( f'Free GPU Memory: { cuda . current_context (). get_memory_info () } ' ) P : ¿Un usuario puede romper la limitación?
R : Estamos seguros de que un usuario malintencionado encontrará la manera. Nunca fue nuestra intención protegernos contra usuarios malintencionados.
Si tiene un usuario malintencionado con acceso a sus máquinas, ¿las GPU fraccionarias no son su problema número uno?
P : ¿Cómo puedo detectar mediante programación la limitación de memoria?
R : Puede comprobar la variable de entorno del sistema operativo GPU_MEM_LIMIT_GB .
Tenga en cuenta que cambiarlo no eliminará ni reducirá la limitación.
P : ¿Es seguro ejecutar el contenedor con --pid=host ?
R : Debe ser a la vez seguro y protegido. La principal advertencia desde una perspectiva de seguridad es que un proceso contenedor puede ver cualquier línea de comando ejecutándose en el sistema host. Si la línea de comando de un proceso contiene un "secreto", entonces sí, esto podría convertirse en una posible fuga de datos. Tenga en cuenta que no es aconsejable pasar "secretos" en la línea de comandos y, por lo tanto, no lo consideramos un riesgo para la seguridad. Dicho esto, si la seguridad es clave, la edición empresarial (ver más abajo) elimina la necesidad de ejecutar con pid-host y, por lo tanto, es completamente segura.
P : ¿Puedes ejecutar el contenedor sin --pid=host ?
R : ¡Puedes! Pero tendrá que utilizar la versión empresarial del contenedor clearml-fractional-gpu (de lo contrario, el límite de memoria se aplica en todo el sistema en lugar de en todo el contenedor). Si esta característica es importante para usted, comuníquese con el departamento de ventas y soporte de ClearML.
La licencia para utilizar ClearML se otorga únicamente con fines de investigación o desarrollo. ClearML se puede utilizar para uso educativo, personal o comercial interno.
Una licencia comercial ampliada para su uso dentro de un producto o servicio está disponible como parte de la solución ClearML Scale o Enterprise.
ClearML ofrece licencia empresarial y comercial que agrega muchas funciones adicionales además de las GPU fraccionarias, que incluyen orquestación, colas de prioridad, administración de cuotas, panel de control de clústeres de computación, administración de conjuntos de datos y administración de experimentos, así como seguridad y soporte de nivel empresarial. Obtenga más información sobre ClearML Orchestration o hable con nosotros directamente en ventas de ClearML.
¡Cuéntaselo a todos! #ClearMLFractionalGPU
Únase a nuestro canal Slack
Infórmenos cuando algo no funcione y ayúdenos a depurarlo en la página de problemas
Este producto es presentado por el equipo de ClearML con ❤️


