amazon bedrock rag
1.0.0
Recuperación-Generación Aumentada (RAG) es el proceso de optimizar la salida de un modelo de lenguaje grande, por lo que hace referencia a una base de conocimiento autorizada fuera de sus fuentes de datos de entrenamiento antes de generar una respuesta. Los modelos de lenguajes grandes (LLM) se entrenan con grandes volúmenes de datos y utilizan miles de millones de parámetros para generar resultados originales para tareas como responder preguntas, traducir idiomas y completar oraciones. RAG extiende las ya poderosas capacidades de los LLM a dominios específicos o a la base de conocimiento interna de una organización, todo sin la necesidad de volver a entrenar el modelo. Es un enfoque rentable para mejorar los resultados del LLM, de modo que siga siendo relevante, preciso y útil en diversos contextos. Obtenga más información sobre RAG aquí.
Amazon Bedrock es un servicio totalmente administrado que ofrece una selección de modelos básicos (FM) de alto rendimiento de empresas líderes en inteligencia artificial como AI21 Labs, Anthropic, Cohere, Meta, Stability AI y Amazon a través de una única API, junto con un amplio conjunto de capacidades que necesita para crear aplicaciones de IA generativa con seguridad, privacidad e IA responsable. Con Amazon Bedrock, puede experimentar y evaluar fácilmente los principales FM para su caso de uso, personalizarlos de forma privada con sus datos mediante técnicas como ajuste fino y RAG, y crear agentes que ejecuten tareas utilizando sus sistemas y fuentes de datos empresariales. Dado que Amazon Bedrock no tiene servidor, no es necesario administrar ninguna infraestructura y puede integrar e implementar de forma segura capacidades de IA generativa en sus aplicaciones utilizando los servicios de AWS con los que ya está familiarizado.
Knowledge Bases for Amazon Bedrock es una capacidad totalmente administrada que le ayuda a implementar todo el flujo de trabajo de RAG, desde la ingesta hasta la recuperación y el aumento rápido, sin tener que crear integraciones personalizadas con fuentes de datos ni administrar flujos de datos. La gestión del contexto de la sesión está integrada, por lo que su aplicación puede admitir fácilmente conversaciones de varios turnos.
Como parte de la creación de una base de conocimientos, usted configura una fuente de datos y un almacén de vectores de su elección. Un conector de fuente de datos le permite conectar sus datos propietarios a una base de conocimientos. Una vez que haya configurado un conector de fuente de datos, puede sincronizar o mantener sus datos actualizados con su base de conocimientos y hacer que sus datos estén disponibles para consultas. Amazon Bedrock primero divide sus documentos o contenido en partes manejables para una recuperación de datos eficiente. Luego, los fragmentos se convierten en incrustaciones y se escriben en un índice vectorial (representación vectorial de los datos), manteniendo al mismo tiempo una asignación con el documento original. Las incrustaciones de vectores permiten comparar matemáticamente la similitud de los textos.
Este proyecto se implementa con dos fuentes de datos; una fuente de datos para documentos almacenados en Amazon S3 y otra fuente de datos para contenido publicado en un sitio web. Se crea una colección de búsqueda de vectores en Amazon OpenSearch Serverless para el almacenamiento de vectores.
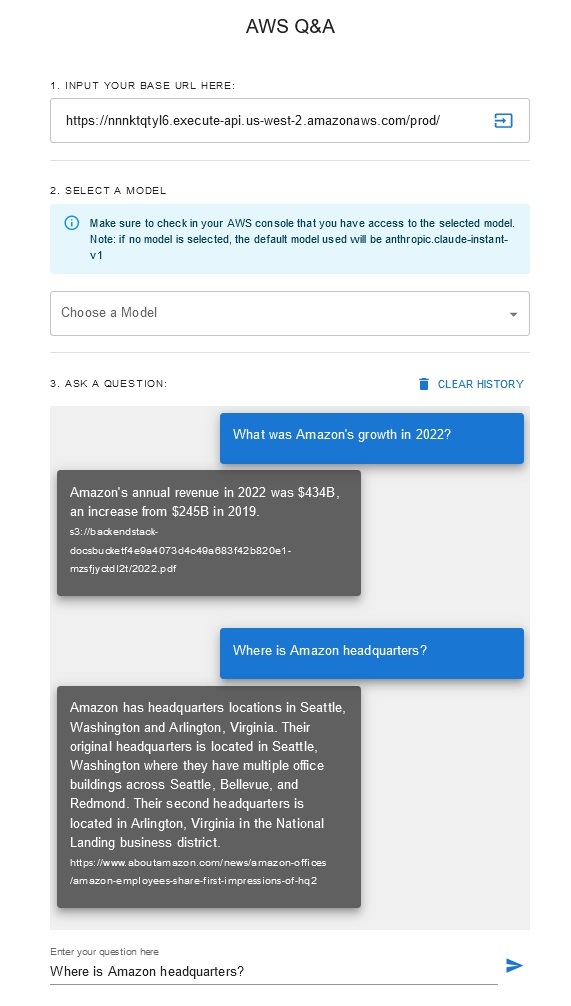
Chatbot de preguntas y respuestas 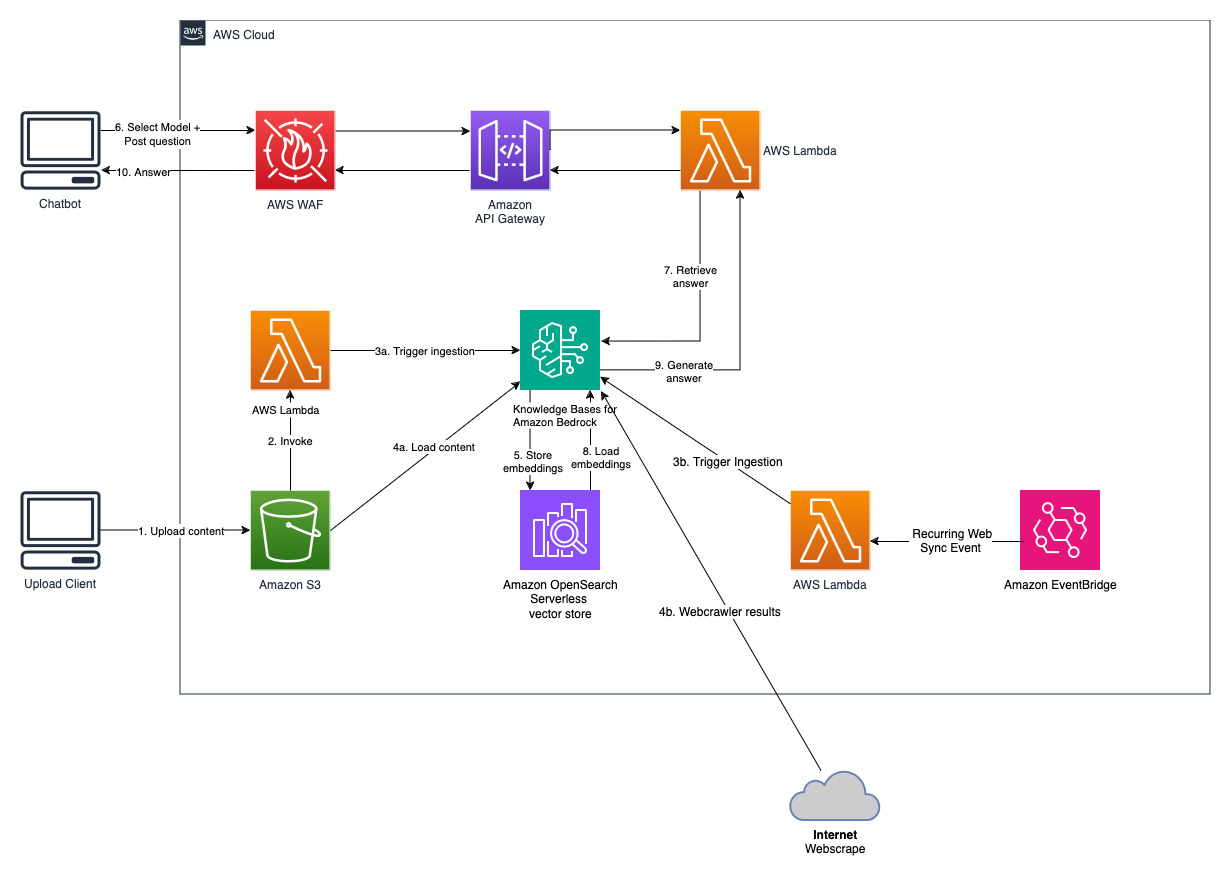
Agregar nuevos sitios web para la fuente de datos web 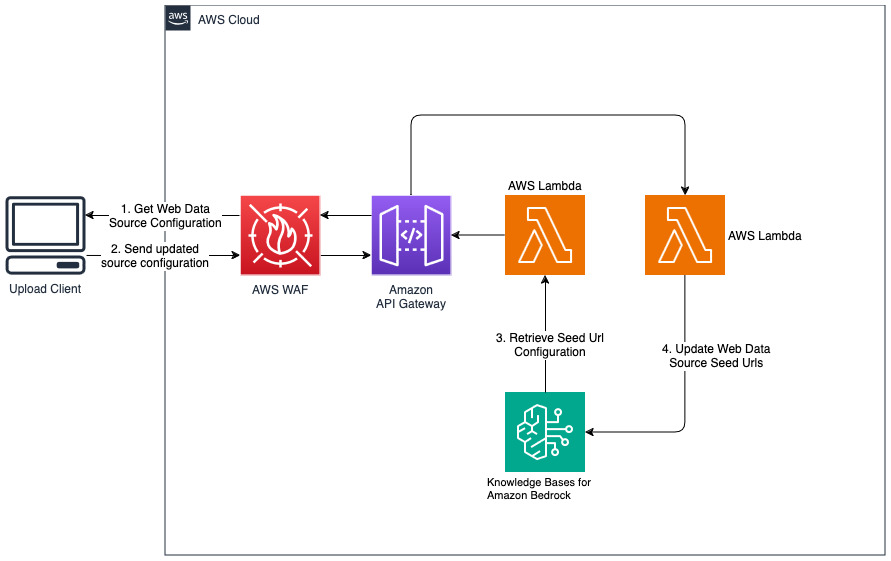
cdk deploy --context allowedip="xxx.xxx.xxx.xxx/32"
Proporcione una dirección IP de cliente que tenga permiso para acceder a API Gateway en formato CIDR como parte de la variable de contexto 'allowedip'.
Cuando se complete la implementación,
Esta solución permite a los usuarios seleccionar qué modelo fundamental desean utilizar durante la fase de recuperación y generación. El modelo predeterminado es Anthropic Claude Instant . Para el modelo de inserción de la base de conocimientos, esta solución utiliza Amazon Titan Embeddings G1: modelo de texto . Asegúrese de tener acceso a estos modelos de bases.
Obtenga un informe anual reciente de Amazon disponible públicamente y cópielo en el nombre del depósito S3 indicado anteriormente. Para una prueba rápida, puede copiar el informe anual de 2022 de Amazon utilizando la consola AWS S3. El contenido del depósito de S3 se sincronizará automáticamente con la base de conocimientos porque la implementación de la solución busca contenido nuevo en el depósito de S3 y desencadena un flujo de trabajo de ingesta.
La solución implementada inicializa la fuente de datos web llamada "WebCrawlerDataSource" con la URL https://www.aboutamazon.com/news/amazon-offices . Debe sincronizar manualmente esta fuente de datos del rastreador web con la base de conocimientos desde la consola de AWS para buscar en el contenido del sitio web porque la ingesta del sitio web está programada para ocurrir en el futuro. Seleccione esta fuente de datos de la consola de conocimiento basada en Amazon Bedrock e inicie una operación de "Sincronización". Consulte Sincronizar su fuente de datos con su base de conocimientos de Amazon Bedrock para obtener más detalles. Tenga en cuenta que el contenido del sitio web estará disponible para el chatbot de preguntas y respuestas solo después de que se complete la sincronización. Utilice esta guía al configurar sitios web como fuente de datos.
Utilice "cdk destroy" para eliminar la pila de recursos de nube creados en esta implementación de solución.


