EasyNLU
1.0.0
EasyNLU es una biblioteca de comprensión del lenguaje natural (NLU) escrita en Java para aplicaciones móviles. Al estar basado en la gramática, es una buena opción para dominios que son limitados pero que requieren un control estricto.
El proyecto tiene una aplicación de Android de muestra que puede programar recordatorios a partir de entradas en lenguaje natural:
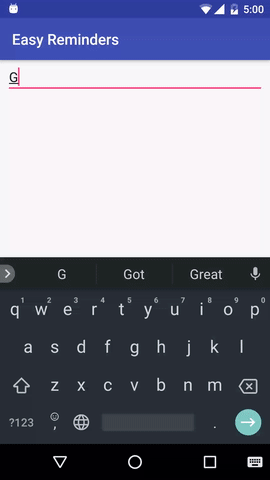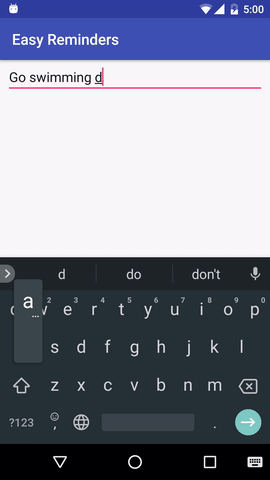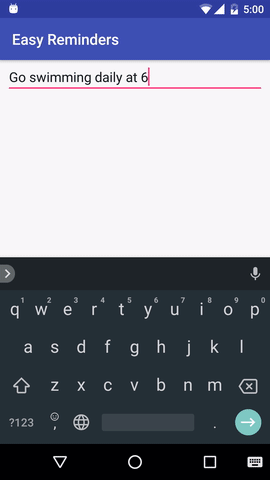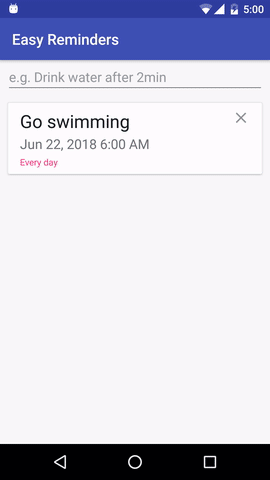
EasyNLU tiene licencia Apache 2.0.
En esencia, EasyNLU es un analizador semántico basado en CCG. Puede encontrar una buena introducción al análisis semántico aquí. Un analizador semántico puede analizar una entrada como:
Ve al dentista mañana a las 5 p.m.
en una forma estructurada:
{task: "Go to the dentist", startTime:{offset:{day:1}, hour:5, shift:"pm"}}
EasyNLU proporciona la forma estructurada como un mapa Java recursivo. Esta forma estructurada puede luego resolverse en un objeto específico de tarea que se "ejecuta". Por ejemplo, en el proyecto de muestra, el formulario estructurado se resuelve en un objeto Reminder que tiene campos como task , startTime y repeat y se utiliza para configurar una alarma con el servicio AlarmManager.
En general, los siguientes son los pasos de alto nivel para configurar la capacidad NLU:
Antes de escribir cualquier regla, debemos definir el alcance de la tarea y los parámetros de la forma estructurada. Como ejemplo de juguete, digamos que nuestra tarea es activar y desactivar funciones del teléfono como Bluetooh, Wifi y GPS. Entonces los campos son:
Un ejemplo de formulario estructurado sería:
{feature: "bluetooth", action: "enable" }
También ayuda tener algunas entradas de muestra para comprender las variaciones:
Siguiendo con el ejemplo del juguete, podemos decir que en el nivel superior tenemos una acción de configuración que debe tener una característica y una acción. Luego usamos reglas para capturar esta información:
Rule r1 = new Rule ( "$Setting" , "$Feature $Action" );
Rule r2 = new Rule ( "$Setting" , "$Action $Feature" ); Una regla contiene un LHS y un RHS como mínimo. Por convención, anteponemos un '$' a una palabra para indicar una categoría. Una categoría representa una colección de palabras u otras categorías. En las reglas anteriores, $Feature representa palabras como bluetooth, bt, wifi, etc. que capturamos usando reglas 'léxicas':
List < Rule > lexicals = Arrays . asList (
new Rule ( "$Feature" , "bluetooth" ),
new Rule ( "$Feature" , "bt" ),
new Rule ( "$Feature" , "wifi" ),
new Rule ( "$Feature" , "gps" ),
new Rule ( "$Feature" , "location" ),
); Para normalizar las variaciones en los nombres de las funciones, estructuramos $Features en subfunciones:
List < Rule > featureRules = Arrays . asList (
new Rule ( "$Feature" , "$Bluetooth" ),
new Rule ( "$Feature" , "$Wifi" ),
new Rule ( "$Feature" , "$Gps" ),
new Rule ( "$Bluetooth" , "bt" ),
new Rule ( "$Bluetooth" , "bluetooth" ),
new Rule ( "$Wifi" , "wifi" ),
new Rule ( "$Gps" , "gps" ),
new Rule ( "$Gps" , "location" )
); De manera similar para $Action :
List < Rule > actionRules = Arrays . asList (
new Rule ( "$Action" , "$EnableDisable" ),
new Rule ( "$EnableDisable" , "?$Switch $OnOff" ),
new Rule ( "$EnableDisable" , "$Enable" ),
new Rule ( "$EnableDisable" , "$Disable" ),
new Rule ( "$OnOff" , "on" ),
new Rule ( "$OnOff" , "off" ),
new Rule ( "$Switch" , "switch" ),
new Rule ( "$Switch" , "turn" ),
new Rule ( "$Enable" , "enable" ),
new Rule ( "$Disable" , "disable" ),
new Rule ( "$Disable" , "kill" )
); Tenga en cuenta el '?' en la tercera regla; esto significa que la categoría $Switch es opcional. Para determinar si un análisis es exitoso, el analizador busca una categoría especial llamada categoría raíz. Por convención se denomina $ROOT . Necesitamos agregar una regla para llegar a esta categoría:
Rule root = new Rule ( "$ROOT" , "$Setting" );Con este conjunto de reglas, nuestro analizador debería poder analizar los ejemplos anteriores, convirtiéndolos en los llamados árboles de sintaxis.
El análisis no sirve de nada si no podemos extraer el significado de la oración. Este significado lo capta la forma estructurada (forma lógica en la jerga de la PNL). En EasyNLU pasamos un tercer parámetro en la definición de la regla para definir cómo se extraerá la semántica. Usamos sintaxis JSON con marcadores especiales para hacer esto:
new Rule ( "$Action" , "$EnableDisable" , "{action:@first}" ), @first le dice al analizador que elija el valor de la primera categoría de la regla RHS. En este caso será "habilitar" o "deshabilitar" según la oración. Otros marcadores incluyen:
@identity : función de identidad@last : elige el valor de la última categoría RHS@N : elija el valor de la enésima categoría RHS, por ejemplo, @3 elegirá la tercera@merge : fusiona valores de todas las categorías. Solo se fusionarán los valores con nombre (por ejemplo {action: enable} ).@append : agrega valores de todas las categorías a una lista. Se debe nombrar la lista resultante. Sólo se permiten valores con nombreDespués de agregar marcadores semánticos nuestras reglas se convierten en:
List < Rule > rules = Arrays . asList (
new Rule ( "$ROOT" , "$Setting" , "@identity" ),
new Rule ( "$Setting" , "$Feature $Action" , "@merge" ),
new Rule ( "$Setting" , "$Action $Feature" , "@merge" ),
new Rule ( "$Feature" , "$Bluetooth" , "{feature: bluetooth}" ),
new Rule ( "$Feature" , "$Wifi" , "{feature: wifi}" ),
new Rule ( "$Feature" , "$Gps" , "{feature: gps}" ),
new Rule ( "$Bluetooth" , "bt" ),
new Rule ( "$Bluetooth" , "bluetooth" ),
new Rule ( "$Wifi" , "wifi" ),
new Rule ( "$Gps" , "gps" ),
new Rule ( "$Gps" , "location" ),
new Rule ( "$Action" , "$EnableDisable" , "{action: @first}" ),
new Rule ( "$EnableDisable" , "?$Switch $OnOff" , "@last" ),
new Rule ( "$EnableDisable" , "$Enable" , "enable" ),
new Rule ( "$EnableDisable" , "$Disable" , "disable" ),
new Rule ( "$OnOff" , "on" , "enable" ),
new Rule ( "$OnOff" , "off" , "disable" ),
new Rule ( "$Switch" , "switch" ),
new Rule ( "$Switch" , "turn" ),
new Rule ( "$Enable" , "enable" ),
new Rule ( "$Disable" , "disable" ),
new Rule ( "$Disable" , "kill" )
);Si no se proporciona el parámetro semántico, el analizador creará un valor predeterminado igual al RHS.
Para ejecutar el analizador, clone este repositorio e importe el módulo del analizador a su proyecto Android Studio/IntelliJ. El analizador EasyNLU toma un objeto Grammar que contiene las reglas, un objeto Tokenizer para convertir la oración de entrada en palabras y una lista opcional de objetos Annotator para anotar entidades como números, fechas, lugares, etc. Ejecute el siguiente código después de definir las reglas:
Grammar grammar = new Grammar ( rules , "$ROOT" );
Parser parser = new Parser ( grammar , new BasicTokenizer (), Collections . emptyList ());
System . out . println ( parser . parse ( "kill bt" ));
System . out . println ( parser . parse ( "wifi on" ));
System . out . println ( parser . parse ( "enable location" ));
System . out . println ( parser . parse ( "turn off GPS" ));Debería obtener el siguiente resultado:
23 rules
[{feature=bluetooth, action=disable}]
[{feature=wifi, action=enable}]
[{feature=gps, action=enable}]
[{feature=gps, action=disable}]
Pruebe otras variaciones. Si falla el análisis de una variante de muestra, no obtendrá ningún resultado. Luego puede agregar o modificar las reglas y repetir el proceso de ingeniería gramatical.
EasyNLU ahora admite listas en forma estructurada. Para el dominio anterior puede manejar entradas como
Desactivar ubicación bt gps
Agregue estas 3 reglas adicionales a la gramática anterior:
new Rule("$Setting", "$Action $FeatureGroup", "@merge"),
new Rule("$FeatureGroup", "$Feature $Feature", "{featureGroup: @append}"),
new Rule("$FeatureGroup", "$FeatureGroup $Feature", "{featureGroup: @append}"),
Ejecute una nueva consulta como:
System.out.println(parser.parse("disable location bt gps"));
Deberías obtener este resultado:
[{action=disable, featureGroup=[{feature=gps}, {feature=bluetooth}, {feature=gps}]}]
Tenga en cuenta que estas reglas se activan solo si hay más de una característica en la consulta.
Los anotadores facilitan tipos específicos de tokens que de otro modo serían engorrosos o absolutamente imposibles de manejar mediante reglas. Por ejemplo, tomemos la clase NumberAnnotator . Detectará y anotará todos los números como $NUMBER . Luego puede hacer referencia directamente a la categoría en sus reglas, por ejemplo:
Rule r = new Rule("$Conversion", "$Convert $NUMBER $Unit $To $Unit", "{convertFrom: {unit: @2, quantity: @1}, convertTo: {unit: @last}}"
EasyNLU actualmente viene con algunos anotadores:
NumberAnnotator : anota númerosDateTimeAnnotator : anota algunos formatos de fecha. También proporciona sus propias reglas que usted agrega usando DateTimeAnnotator.rules()TokenAnnotator : anota cada token de la entrada como $TOKENPhraseAnnotator : anota cada frase contigua de entrada como $PHRASE Para utilizar su propio anotador personalizado, implemente la interfaz Annotator y pásela al analizador. Consulte los anotadores integrados para tener una idea de cómo implementar uno.
EasyNLU admite la carga de reglas desde archivos de texto. Cada regla debe estar en una línea separada. El LHS, RHS y la semántica deben estar separados por pestañas:
$EnableDisable ?$Switch $OnOff @last
Tenga cuidado de no utilizar IDE que conviertan automáticamente pestañas en espacios
A medida que se agregan más reglas al analizador, encontrará que el analizador encuentra múltiples análisis para ciertas entradas. Esto se debe a la ambigüedad general de los lenguajes humanos. Para determinar qué tan preciso es el analizador para su tarea, debe ejecutarlo a través de ejemplos etiquetados.
Al igual que las reglas anteriores, EasyNLU toma ejemplos definidos en texto sin formato. Cada línea debe ser un ejemplo independiente y debe contener el texto sin formato y el formulario estructurado separados por una pestaña:
take my medicine at 4pm {task:"take my medicine", startTime:{hour:4, shift:"pm"}}
Es importante que cubra un número aceptable de variaciones en la entrada. Obtendrás más variedad si consigues que diferentes personas realicen esta tarea. El número de ejemplos depende de la complejidad del dominio. El conjunto de datos de muestra proporcionado en este proyecto tiene más de 100 ejemplos.
Una vez que tenga los datos, puede incluirlos en un conjunto de datos. La parte de aprendizaje está a cargo del módulo trainer ; importarlo a su proyecto. Cargue un conjunto de datos como este:
Dataset dataset = Dataset . fromText ( 'filename.txt' )Evaluamos el analizador para determinar dos tipos de precisiones.
Para ejecutar la evaluación utilizamos la clase Model :
Model model = new Model(parser);
model.evaluate(dataset, 2);
El segundo parámetro de la función de evaluación es el nivel detallado. Cuanto mayor sea el número, más detallada será la salida. La función evaluate() ejecuta el analizador a través de cada ejemplo y muestra análisis incorrectos que finalmente muestran la precisión. Si obtiene ambas precisiones en los 90, entonces la capacitación es innecesaria, probablemente pueda manejar esos pocos análisis incorrectos con el posprocesamiento. Si la precisión de Oracle es alta pero la precisión de la predicción es baja, entonces será útil entrenar el sistema. Si la precisión de Oracle es baja, entonces es necesario realizar más ingeniería gramatical.
Para obtener el análisis correcto, los calificamos y elegimos el que tiene la puntuación más alta. EasyNLU utiliza un modelo lineal simple para calcular las puntuaciones. El entrenamiento se realiza mediante el Descenso de gradiente estocástico (SGD) con una función de pérdida de bisagra. Las funciones de entrada se basan en recuentos de reglas y campos en el formulario estructurado. Luego, los pesos entrenados se guardan en un archivo de texto.
Puede ajustar algunos de los parámetros del modelo/entrenamiento para obtener una mayor precisión. Para los modelos de recordatorios se utilizaron los siguientes parámetros:
HParams hparams = HParams . hparams ()
. withLearnRate ( 0.08f )
. withL2Penalty ( 0.01f )
. set ( SVMOptimizer . CORRECT_PROB , 0.4f );Ejecute el código de entrenamiento de la siguiente manera:
Experiment experiment = new Experiment ( model , dataset , hparams , "yourdomain.weights" );
experiment . train ( 100 , false );Esto entrenará el modelo durante 100 épocas con una división de prueba de entrenamiento de 0,8. Mostrará las precisiones en el conjunto de prueba y guardará los pesos del modelo en la ruta del archivo proporcionada. Para entrenar en todo el conjunto de datos, establezca el parámetro de implementación en verdadero. Puede ejecutar un modo interactivo tomando información desde la consola:
experiement.interactive();
NOTA: no se garantiza que la capacitación produzca una alta precisión incluso con una gran cantidad de ejemplos. En determinados escenarios, las funciones proporcionadas pueden no ser lo suficientemente discriminativas. Si se queda atascado en tal caso, registre un problema y podremos encontrar funciones adicionales.
Los pesos del modelo son un archivo de texto sin formato. Para un proyecto de Android, puede colocarlo en la carpeta assets y cargarlo usando AssetManager. Consulte ReminderNlu.java para obtener más detalles. Incluso podría almacenar sus pesos y reglas en la nube y actualizar su modelo por aire (¿alguien quiere Firebase?).
Una vez que el analizador esté haciendo un buen trabajo al convertir la entrada del lenguaje natural en una forma estructurada, probablemente querrá esos datos en un objeto específico de la tarea. Para algunos dominios, como el ejemplo de juguete anterior, puede ser bastante sencillo. Para otros, es posible que tengas que resolver referencias a cosas como fechas, lugares, contactos, etc. En el ejemplo de recordatorio, las fechas suelen ser relativas (p. ej., "mañana", "después de 2 horas", etc.) y deben convertirse a valores absolutos. Consulte ArgumentResolver.java para ver cómo se realiza la resolución.
SUGERENCIA: Mantenga la lógica de resolución al mínimo al definir reglas y realice la mayor parte en el posprocesamiento. Mantendrá las reglas más simples.


