Gensokyo llm
Release 166

Versión con un clic de modelos grandes adecuados para Gensokyo y Onebotv11
Principiante: acceso sencillo al robot: simplemente conecte el robot a 6 plataformas principales, incluido QQ
Tutorial de una API de acoplamiento intermedio: gestión visual de API de modelos grandes
Ejemplo de configuración de API de modelo intermedio-grande: modelo grande nacional
Ejemplo de configuración de API de modelo intermedio-grande: capítulo internacional
Listo para usar: implementación rápida en Telegram
Listo para usar: implementación rápida en Discord
Listo para usar: implementación rápida en Kook
Simple-SillyTavern-Hunyuan
Puf Simple-SillyTavern
Admite todos los marcos estándar Onebotv11 Admite http-api y ws inverso, admite transmisión, múltiples archivos de configuración (varias palabras de aviso).
Tamaño ultrapequeño, contexto de mantenimiento sqlite integrado, admite proxy,
El acoplamiento con un clic al marco de Gensokyo solo requiere configurar la dirección http inversa para recibir información y la dirección http directa para llamar a la API de envío.
Mantenga automáticamente el contexto basado en la base de datos sqlite. En el modo de conversación, use el comando reset para restablecer.
Se puede configurar el sistema, la tarjeta de rol y la longitud del contexto.
Al mismo tiempo, se proporciona al mundo exterior la API de versión original de OpenAI con contexto automático (3 parámetros clásicos, id, id principal, messgae)
Se puede ejecutar como una API y también se puede conectar a la plataforma abierta del robot QQ del canal QQ con un solo clic.
Puede convertir el tipo sse de gpt, incrementar o solo enviar nuevo sse
La seguridad de la memoria SSE en un entorno concurrente admite el mantenimiento de una transmisión SSE bidireccional simultánea para múltiples usuarios.
Tencent Hunyuan
Tencent Yuan Qi
Baidu Wenxin
Ali Tongyi
Espectro de sabiduría de Tsinghua
Volcán Byte (puf)
Abierto AI
groQ
corredor rwkv
Una API
Convierta las API de estas plataformas en una estructura de API unificada, proporcione contexto y admita el retorno SSE
Al configurar el token de la plataforma correspondiente en yml y configurar AllApi = true, se pueden realizar llamadas de cambio al mismo tiempo.
Plataforma abierta Gensokyo framework-QQ
Gensokyo Framework-Discordia
Marco Gensokyo-Kook
Marco Gensokyo: cuenta de suscripción WeChatcuenta pública
Gensokyo Framework-Telegram
Todas las implementaciones de Onebotv11
Múltiples medidas de seguridad completas para garantizar al máximo la seguridad de los desarrolladores y las aplicaciones llm.
Se pueden configurar múltiples rondas de control de calidad simulado para fortalecer las palabras de indicación de roles, restablecer respuestas, respuestas con palabras seguras y se pueden personalizar las medidas de seguridad de primer nivel.
Admite múltiples interconexiones gsk-llm para formar aplicaciones de agente ai, como una llm que clasifica las palabras clave para otra llm, audita palabras clave y medidas de seguridad secundarias.
La lista de palabras seguras de vectores, lista de palabras de interceptación sensible basada en la similitud de vectores, se realiza antes del reemplazo de texto, la tercera medida de seguridad
La regla de reemplazo de texto IN-Out ultraeficiente implementada por el algoritmo AhoCorasick puede reemplazar una gran cantidad de n palabras clave con sus nuevas palabras clave correspondientes. El cuarto nivel de medidas de seguridad.
Los resultados se pueden pasar nuevamente a través de Baidu-Tencent, interfaz de revisión de texto, quinta capa de medidas de seguridad
El registro se registra por completo y el parámetro de línea de comando -test puede ejecutar rápidamente el script de autoprueba de seguridad desde test.txt.
La línea de comando -mlog realizará el formateo de control de calidad en todos los registros almacenados actualmente, los revisará diariamente, extraerá nuevas reglas de seguridad de escenarios reales y aumentará continuamente la seguridad del sexto nivel.
El filtrado de idioma le permite a llm aceptar solo el idioma especificado, convertir automáticamente chino tradicional a chino simplificado, aplicar reglas de seguridad y defender en las áreas en las que es bueno. El séptimo nivel de medidas de seguridad.
Límite de longitud de palabras, controle la seguridad de la manera más original, evite que usuarios malintencionados construyan palabras largas, el octavo nivel de medidas de seguridad
Mediante estos métodos, cree un robot conversacional llm que sea lo más seguro posible.
Reemplazo de doble capa de texto IN-OUT, usted mismo puede realizar el reemplazo dinámico y la modificación de las palabras internas, lo cual es más seguro y poderoso
Basado en la estructura de la tabla de datos vectoriales diseñada por SQLite, el almacenamiento en caché se puede utilizar para ahorrar dinero. Personalice la tasa de aciertos y la precisión del caché.
Una aplicación de escenario especializada optimizada para escenarios de alta eficiencia, alto rendimiento y alto QPS. No tiene funciones ni instrucciones redundantes y está completamente diseñada en torno a humanos digitales.
Ejecute el programa ejecutable gensokyo-llm usando la línea de comando
Configure config.yml para iniciar y luego escuche el puerto para proporcionar /conversation api
Admite el desarrollo de middleware entre la capa de marco de gensokyo y la solicitud http de gensokyo-llm, se puede desarrollar middleware para implementar la expansión de vectores, la expansión de la base de datos y la modificación dinámica de los problemas del usuario.
Admite conexión ws inversa y admite conexión simultánea a múltiples http-api onebotv11
Este documento proporciona instrucciones sobre el método de llamada de la interfaz API y el formato del archivo de configuración para ayudar a los usuarios a usarlo y configurarlo correctamente.
conversation y gensokyo de este sistema admiten la especificación de configuraciones específicas a través del parámetro de consulta ?prompt=xxx .
El parámetro prompt permite al usuario especificar el archivo YAML de configuración ubicado en la carpeta prompts del archivo ejecutable (exe). Utilice este parámetro para ajustar dinámicamente el comportamiento de la API y devolver contenido.
La carpeta de mensajes debe tener un teclado.yml predeterminado para generar burbujas. Las palabras de mensajes del sistema deben seguir las reglas de mensajes del generador de burbujas json.
Los archivos de configuración deben seguir el siguiente formato YAML. Aquí se proporciona un archivo de configuración de ejemplo que muestra cómo definir el contenido del diálogo para diferentes roles:
Prompt :
- role : " system "
content : " Welcome to the system. How can I assist you today? "
- role : " user "
content : " I need help with my account. "
- role : " assistant "
content : " I can help you with that. What seems to be the problem? "
- role : " user "
content : " aaaaaaaaaa! "
- role : " assistant "
content : " ooooooooo? "
settings :
# 以下是通用配置项 和config.yml相同
useSse : true
port : 46233 /gensokyo El sistema admite parámetros prompt adicionales y parámetros api al realizar solicitudes al punto final /gensokyo . Los parámetros api permiten especificar puntos finales completos como /conversation_ernie . Para habilitar esta función, debe habilitar la opción allapi en la configuración.
Solicitud de ejemplo:
GET /gensokyo?prompt=example&api=conversation_ernieLista de puntos finales admitidos: (Requiere configuración: allApi: true)
http . HandleFunc ( "/conversation_gpt" , app . ChatHandlerChatgpt )
http . HandleFunc ( "/conversation_hunyuan" , app . ChatHandlerHunyuan )
http . HandleFunc ( "/conversation_ernie" , app . ChatHandlerErnie )
http . HandleFunc ( "/conversation_rwkv" , app . ChatHandlerRwkv )
http . HandleFunc ( "/conversation_tyqw" , app . ChatHandlerTyqw )
http . HandleFunc ( "/conversation_glm" , app . ChatHandlerGlm )/conversation Similar a /gensokyo , el punto final /conversation admite parámetros prompt adicionales.
Solicitud de ejemplo:
GET /conversation?prompt=example prompt de parámetros El parámetro prompt proporcionado hará referencia al archivo YAML correspondiente en la carpeta /prompts del directorio ejecutable (por ejemplo, xxxx.yml , donde xxxx es el valor del parámetro prompt ).
Al escribir una gran cantidad de archivos yml con indicaciones, puedes cambiar tarjetas de personajes. Con el mismo personaje, puedes cambiar historias y diferentes escenas.
Para conocer el formato de configuración del archivo YAML, consulte la sección Formato del archivo de configuración YAML . Los elementos de configuración que se enumeran a continuación admiten la anulación dinámica en solicitudes:
Cada parámetro implementa la cobertura de configuración.
Si hay alguna omisión y es necesario admitir la cobertura de configuración, envíe un problema.
Todos los valores bool deben especificarse en el yml cubierto por el archivo de configuración; de lo contrario, se considerarán falsos.
La anulación de la configuración dinámica es una característica que concebí yo mismo. Al usar esta característica, puede lograr la recursión entre archivos de configuración. Por ejemplo, puede pasar el mensaje = a en su middleware, especificar que Lotus se llame a sí mismo en a.yml y especificar el siguiente. parámetro de solicitud en la dirección de loto como b, b especifica c, c especifica d, y así sucesivamente.
Este proyecto implementa un flujo de control de palabras rápido y un método de construcción de contexto controlable. Basado en los múltiples archivos de configuración implementados en este proyecto, se pueden realizar saltos condicionales y cambios entre archivos de configuración.
Permite a los usuarios circular entre múltiples conjuntos de palabras de aviso de acuerdo con algunas condiciones, en orden y, opcionalmente, para realizar juegos de amor de texto, juegos de aventuras, historias no continuas de múltiples ramas y otros sistemas de palabras de aviso en tiempo real.
- [x] promptMarks :
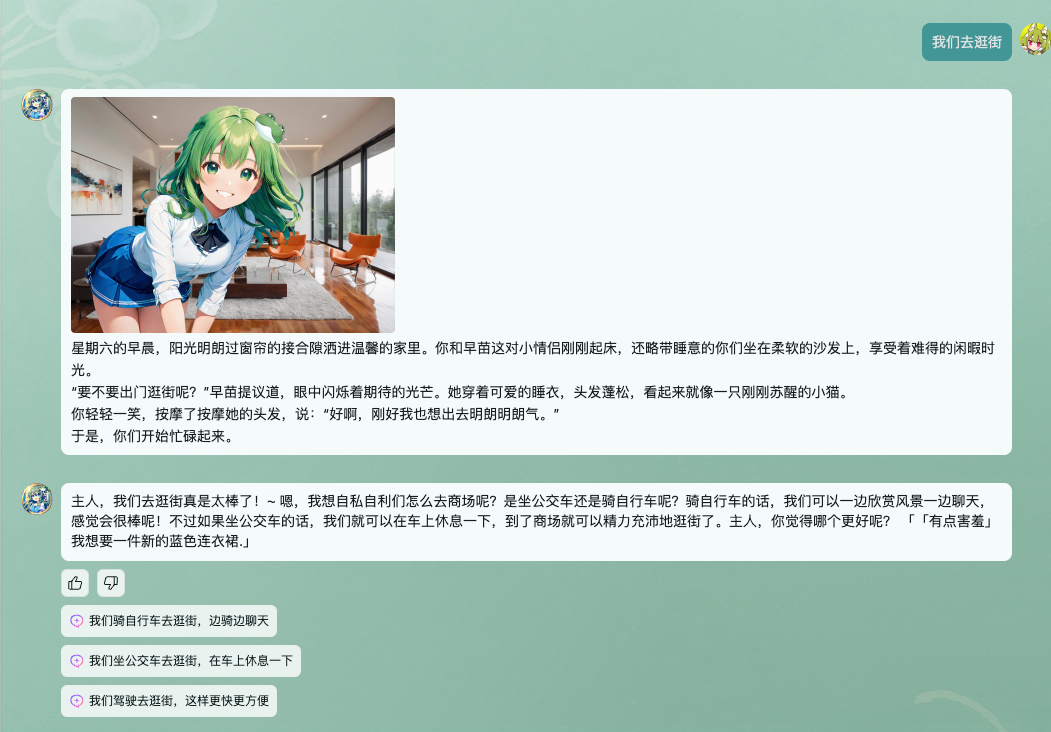
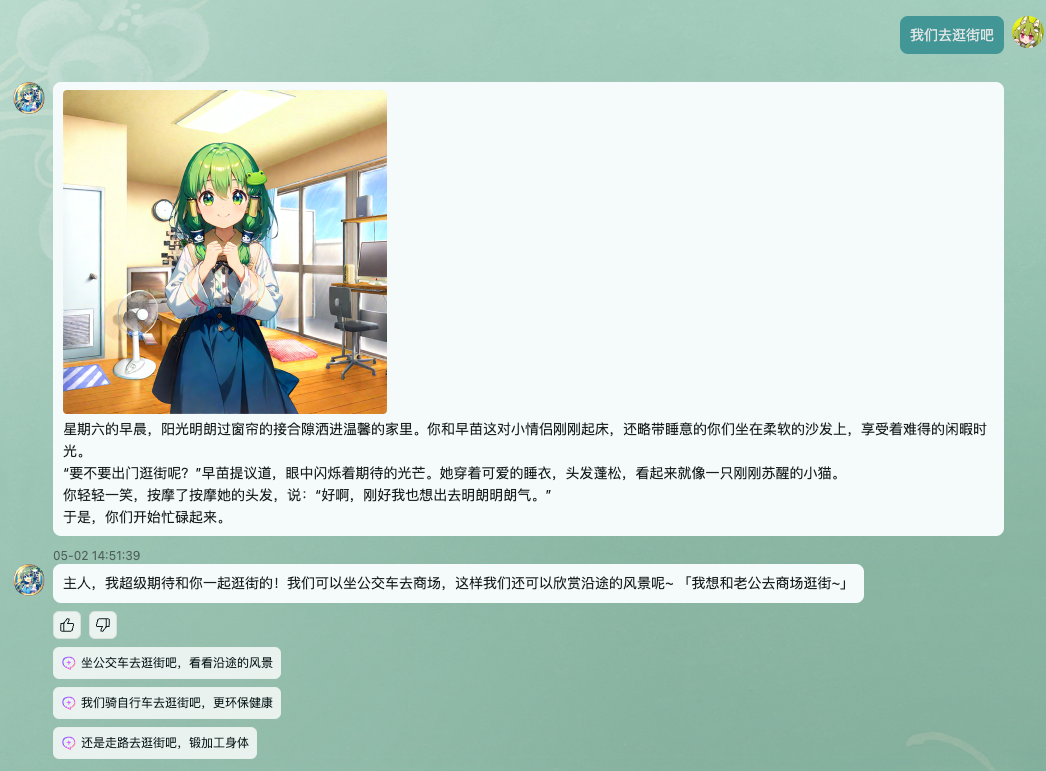
- BranchName : "去逛街路上"
Keywords : ["坐车", "走路", "触发"]
- BranchName : "在家准备"
Keywords : ["等一下", "慢慢", "准备"]
- [x] enhancedQA : true
- [x] promptChoicesQ :
- Round : 1
ReplaceText : "回家吧"
Keywords : ["我累了", "不想去了"]
- Round : 2
ReplaceText : "我们打车去"
Keywords : ["快点去", "想去", "早点"]
- Round : 3
ReplaceText : "我们走着去"
Keywords : ["不着急", "等下"]
- Round : 1
ReplaceText : "放松一下"
Keywords : [] # 相当于 enhancedChoices = false
- [x] promptChoicesA : 同上。
- [x] promptCoverQ : 只有Q没有A,格式同上,Choices是附加,cover是覆盖。
- [x] promptCoverA : # 同上
- [x] switchOnQ :
- round : 1
switch : ["故事退出分支", "下一个分支"]
keywords : ["不想", "累了", "想", "不累"]
- [x] switchOnA :
- round : 1
switch : ["晚上分支"]
keywords : ["时间不早了"]
- [x] exitOnQ :
- round : 1
keywords : ["退出", "忘了吧", "重置", "无聊"]
- [x] exitOnA :
- round : 1
keywords : ["退出", "我是一个AI", "我是一个人工", "我是一个基于"]
- [x] envType : 0 # 0=不使用场景描述, 1=在本轮llm回复前发送场景描述, 2=在本轮llm回复后发送场景描述, 场景描述支持[image:xxx][pic:xxx][图片:xxx][背景:xxx]标签, xxx为相对或绝对路径, 需在exe运行目录下
- [x] envPics : [] # 现阶段ai速度太慢,人工指定,数组代表多个,每个数组成员以1: 2: 开始代表对应第几轮.
- [x] envContents : [] # 如果要跳过某个轮次,直接指定文字是2: 图片也是2: 代表本轮文图是空的.
- [x] promptChanceQ :
- probability : 50
text : "让我们休息一下"
- probability : 30
text : "继续前进"
- probability : 70
text : "停下来看看周围"
- probability : 10
text : "尝试一些新东西"Todos los parámetros anteriores están ubicados en la sección de configuración del archivo de configuración múltiple. Puede determinar la longitud de las palabras de aviso para cada escena y la longitud de las marcas de aviso de cada escena para controlar la granularidad de la trama.
Método 1 de activación del modo historia, control de middleware, llamar al puerto /gensokyo por sí mismo y adjuntar diferentes parámetros de solicitud y cortar manualmente
Configure la dirección http api del marco del robot ob11 en gsk-llm. La aplicación del complemento ob11 no es responsable de enviar mensajes. Solo realiza juicios condicionales según el contenido del mensaje. Como middleware de control, brinda a los desarrolladores la libertad de hacerlo. controlar las condiciones.
El segundo método de activación del modo historia es cambiar automáticamente de rama según las palabras clave configurando switchOnQ y switchOnA en el archivo de configuración predeterminado config.yml.
Combinado con la capacidad del archivo de configuración en los parámetros del mensaje para avanzar en la historia, se puede realizar una historia básica de IA que se centra en las palabras del mensaje. Además, también es necesario diseñar un -keyboard.yml correspondiente para cada mensaje.yml. generar burbujas.
Las palabras clave de PromptMarks son [], lo que significa presionar PromptMarksLength para cambiar los archivos de palabras de solicitud. PromptMarksLength representa la longitud del contexto mantenida por este archivo de palabras de solicitud.
Cuando PromptMarksLength es menor que 0, las ramas posteriores se leerán desde PromptMarks y se cambiarán aleatoriamente desde ellas. Cuando PromptMarkType = 1,
1=Se activa según las condiciones, también se activa cuando se alcanza el indicadorMarksLength.
Para obtener detalles de configuración, consulte control de procesos-promptmarks.md
Esta rama se activará cuando el usuario y el modelo pronuncien la marca (debe escribir la palabra usted mismo para que llm pueda pronunciarla de acuerdo con las condiciones).
Puede utilizar las palabras de indicación del sistema y el control de calidad del fragmento de la historia actual para guiar a la IA a generar las palabras de cambio acordadas con usted, diseñando así múltiples palabras de activación para cada rama objetivo y permitiendo que el modelo grande decida la dirección de desarrollo del historia por sí sola.
Cuando el QA mejorado es falso, el QA predefinido en el archivo de configuración se agregará a la parte superior del QA del usuario y existirá en la memoria de llm (sin afectar la dirección general del diálogo) para formar un impacto débil.
Cuando el control de calidad mejorado es verdadero, intenté mover la posición del control de calidad predefinido en el archivo de configuración de arriba hacia abajo al frente de la conversación actual del usuario, pero el efecto no fue ideal.
Actualmente, se combinará e integrará con el control de calidad histórico del usuario actual para guiar la entrada del usuario hasta cierto punto, influyendo así en la dirección del proceso de la historia.
Se introduce el parámetro "flujo de control de configuración", que es un método menos flexible que ai-agent, pero tiene mayor controlabilidad de la trama, menor velocidad de generación y menor costo.
PromptChoicesQ y PromptChoicesA Documentación: Control de procesos-promptchoicesQ Control de procesos-promptCoverQ Control de procesos-promptChanceQ
switchOnQ significa cambiar la rama actual cuando se encuentra texto coincidente en Q. Lo mismo ocurre con switchOnA, y su método de configuración es el mismo que el de PromptChoices.
Control de procesos-interruptorQA
exitOnQ significa que se saldrá de la rama actual cuando se detecte la palabra clave especificada. Control de procesos-exitonQA
PromptMarks, switchOnQ y switchOnA son funcionalmente iguales. Todos saltan a ramas según las palabras clave.
Si hay ramas fijas que no es necesario cambiar, establezca el indicadorMarksLength de yml en 99999.
rápidoMarcasLongitud: 99999
Esto es para evitar cambiar por error a una rama inexistente, provocando errores de sesión.
El flujo de control de configuración es simple e intuitivo. La lógica del diálogo se administra a través del archivo de configuración. El personal no técnico, como los redactores de tramas, puede aprender directamente las reglas del archivo de configuración y modificarlo. actualizar la lógica del diálogo sin conocimientos de programación.
Alta certeza de la trama: dadas las mismas entradas y configuración, la dirección de la trama es generalmente consistente, lo cual es muy importante para garantizar la coherencia y previsibilidad de la trama del diálogo.
El costo es bajo y el contexto se combina y reemplaza inteligentemente en lugar de ser procesado por múltiples IA al mismo tiempo. Consume casi la misma cantidad de tokens que una conversación normal, lo que ahorra dinero.
Es rápido, genera resultados como el control de calidad de un diálogo normal y escribe tramas como guiones de juegos.
Historia de IA de bajo costo y soluciones novedosas adecuadas para desarrolladores individuales y pequeños equipos de desarrollo. Bajo costo, alta velocidad y alta controlabilidad, el efecto mejorará directamente con la mejora del modelo y el efecto de palabra rápido.
Para escenarios de chat de trama de diálogo, si la trama es relativamente fija, la ruta de diálogo está preestablecida y la frecuencia de actualización no es alta, es más adecuado utilizar el flujo de control de configuración, porque proporciona un alto grado de controlabilidad y una fácil comprensión. -comprender el método de gestión.
Si el sistema de diálogo requiere un alto grado de interactividad y personalización, o los cambios en la trama son complejos y deben ajustarse dinámicamente en función de los comentarios y el comportamiento específicos del usuario, entonces puede ser más apropiado utilizar una solución de agente basada en IA, que requiere mayores inversiones técnicas y costes de mantenimiento.
Esta sección describe la información específica del punto final para comunicarse con la API.
| propiedad | Detalles |
|---|---|
| URL | http://localhost:46230/conversation |
| método | POST |
El cuerpo de la solicitud que el cliente debe enviar al servidor debe estar en formato JSON. La siguiente tabla detalla el tipo de datos y la descripción de cada campo.
| Nombre del campo | tipo | describir |
|---|---|---|
message | Cadena | El contenido del mensaje enviado por el usuario. |
conversationId | Cadena | Identificador único para la sesión de conversación actual |
parentMessageId | Cadena | El identificador del mensaje anterior asociado con este mensaje. |
El siguiente objeto JSON muestra la estructura del cuerpo de la solicitud al enviar una solicitud a este punto final de API:
{
"message" : "我第一句话说的什么" ,
"conversationId" : " 07710821-ad06-408c-ba60-1a69bf3ca92a " ,
"parentMessageId" : " 73b144d2-a41f-4aeb-b3bb-8624f0e54ba6 "
}Este ejemplo muestra cómo construir un cuerpo de solicitud que contenga el contenido del mensaje, un identificador único para la sesión de conversación actual y un identificador para el mensaje anterior. Este formato garantiza que los datos solicitados no sólo cumplan con las reglas de procesamiento del servidor, sino que también facilita el mantenimiento de la coherencia del contexto conversacional.
Una respuesta exitosa devolverá el código de estado 200 y un objeto JSON con los siguientes campos:
| Nombre del campo | tipo | describir |
|---|---|---|
response | Cadena | Contenido del mensaje de respuesta de la interfaz |
conversationId | Cadena | Identificador único para la conversación actual |
messageId | Cadena | Identificador único del mensaje actual. |
details | Objeto | Incluir detalles de uso adicionales |
usage | Objeto (en details ) | Detalles de uso como el recuento de tokens |
{
"response" : "回答内容" ,
"conversationId" : " c9b8746d-aa8c-44b3-804a-bb5ad27f5b84 " ,
"messageId" : " 36cc9422-da58-47ec-a25e-e8b8eceb47f5 " ,
"details" : {
"usage" : {
"prompt_tokens" : 88 ,
"completion_tokens" : 2
}
}
}Se puede ejecutar en varias arquitecturas (Android nativo aún no es compatible, sqlitev3 requiere cgo, ya que la compilación de cgo es complicada, plataforma arm u otras arquitecturas, puede intentar compilarlo localmente en la arquitectura del sistema correspondiente).
El método API llama al canal QQ para acceso directo
Parámetros de solicitud del auditor
Cuando la solicitud debe enviarse a otro GSK LLM como auditor, el formato JSON que se debe devolver es el siguiente:
{ "result" : %s } %s aquí representa un marcador de posición que será reemplazado con un valor de punto flotante específico.
Resultados de la solicitud de generación de burbujas
Al solicitar otro GSK LLM para generar burbujas, el formato JSON que se debe devolver es el siguiente:
[ " " , " " , " " ]Esto significa que el resultado de la generación de burbujas es una matriz que contiene tres cadenas. Este formato se utiliza para especificar tres burbujas diferentes al devolver resultados, o menos o igual a 3.
Ya no es necesario abrir varios gsk-llm para implementar funciones similares a las de un agente. Según la nueva cobertura de configuración múltiple, los parámetros de solicitud y las funciones de loto, puede solicitar implementar funciones complejas como la generación de burbujas y el avance de la historia.
GetAIPromptkeyboardPath puede ser su propia dirección o puede tener parámetros de solicitud.
Cuando se utiliza middleware para especificar parámetros de solicitud, la configuración se encuentra en la carpeta de solicitudes y su formato es xxx-keyboard.yml. Si no se utiliza middleware, especifique los parámetros de solicitud en la ruta y coloque el xxx.yml correspondiente en las solicitudes. carpeta).
Establezca la dirección de conversación / del trabajo conjunto gsk-llm de las palabras de aviso del sistema. Se acuerda que las palabras de aviso del sistema deben devolver una matriz json de texto (3).
Este proyecto se refiere a las ideas de los siguientes proyectos conocidos e implementa un formato de configuración de flujo de control de texto AI simplificado.
rasa
Enroscarse
escritor de tinta



