inverted_index
1.0.0
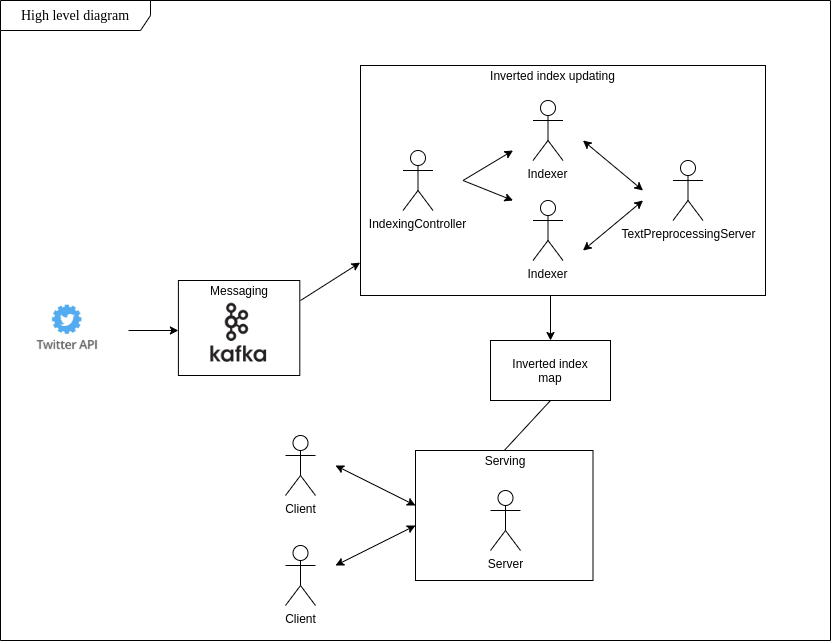
Buscar frases que diga la gente a tu alrededor puede resultar complicado. ¿Qué pasa con las actualizaciones dinámicas de este conjunto de datos? ¿Almacenamiento escalable y baja latencia? Mi principal objetivo en este proyecto es construir un sistema que cumpla con estos requisitos y permita estar actualizado con las tendencias presentes en los tweets en tiempo real.
Siguiendo la idea del índice invertido, implementé la aplicación que en tiempo real encuentra tweets con contenido específico, los almacena en un sistema de archivos local y permite realizar búsquedas basadas en palabras inmediatamente después de inicializar la conexión del cliente.
Para ejecutar la aplicación necesitas:
git clone https://github.com/cyberpunk317/inverted_index.git TWITTER_APP_KEY = 'YOUR APP KEY'
TWITTER_APP_SECRET = 'YOUR APP SECRET'
TWITTER_KEY = 'YOUR KEY'
TWITTER_SECRET = 'YOUR SECRET' Cree Dockerfiles para cliente y servidor:
./gradlew clean build createClientDockerfile createMainDockerfile
Esto producirá app_server.Dockerfile y app_client.Dockerfile en el directorio raíz.
Iniciar solicitud:
docker-compose up
Inicie una sesión de cliente:
docker build -f app_client.Dockerfile -t client:latest . && docker run -it --rm --network=host client:latest bash
Empiece a escribir palabras de interés. El servidor devolverá la ubicación de los tweets en el formato 'dataset_v2//tweet_N.txt'. Por ejemplo:
You entered: war
Server response: [dataset_v2/Veeresh Dambal/tweet_30.txt, dataset_v2/pedro schliesser/tweet_1.txt]
Consulte los problemas abiertos para obtener una lista de funciones propuestas (y problemas conocidos).
Distribuido bajo la licencia MIT. Consulte LICENSE para obtener más información.


