mind x
1.0.0

Este proyecto demuestra la viabilidad de los LLM (o LMM) personalizados como asistentes personales, manteniendo el rápido crecimiento de estos modelos.
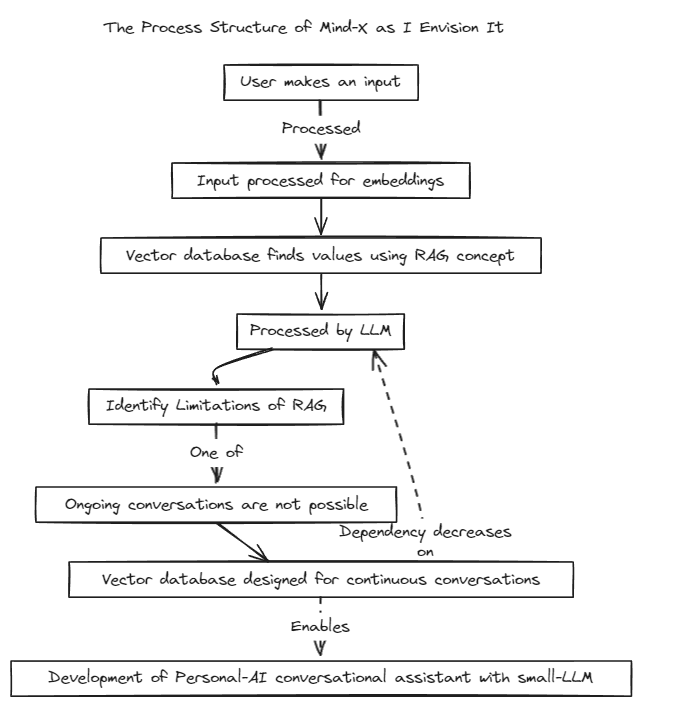
Hemos introducido un método de generación aumentada de recuperación (RAG) para superar las limitaciones del ajuste rápido tradicional, que tiene límites de contexto, y el ajuste fino, que sufre problemas con las actualizaciones de datos en tiempo real y alucinaciones.
Tradicionalmente, RAG se ha utilizado para buscar bases de datos como Chroma a través de LangChain como tienda, pero este método opera dentro de contextos fijos, lo cual es limitante.
Por lo tanto, planeamos construir nuestro propio sistema RAG. Este proceso puede implicar abordar problemas de inferencia y regresión que LangChain podría ofrecer.
Estamos comprometidos con un desarrollo rápido y pronto habilitaremos la compatibilidad multilingüe. Actualmente, el sistema es totalmente compatible con el inglés y está previsto que en breve sea compatible con el coreano, el japonés y otros idiomas. Además, próximamente también se incorporarán sistemas de regresión e inferencia.
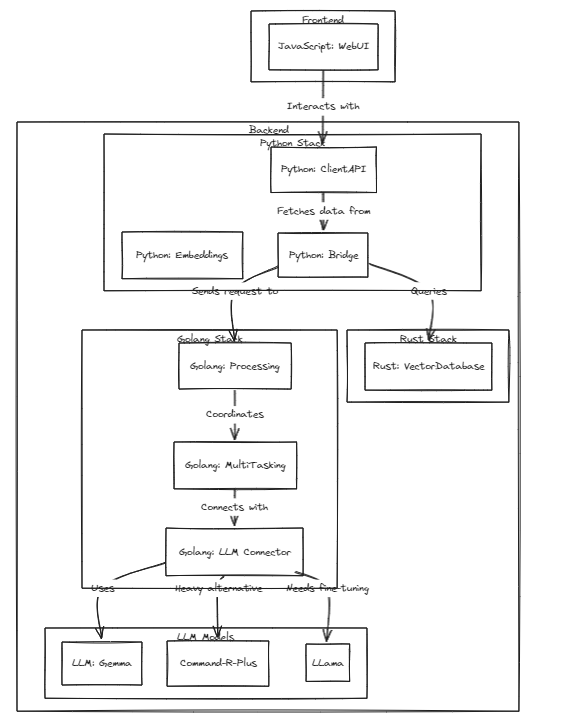
Para ejecutar pruebas, ejecute el siguiente comando
# start embeddings server
cd embd & pip install -r requirements.txt
python app.py
# start mindx-v server (vector-database)
# not using cgo, only assembly
cd mindx-v & go run cmd/mxvd/main.go
# start processor server
cd processor & go run cmd/main.go
# start demo client
cd sample_client & npm start
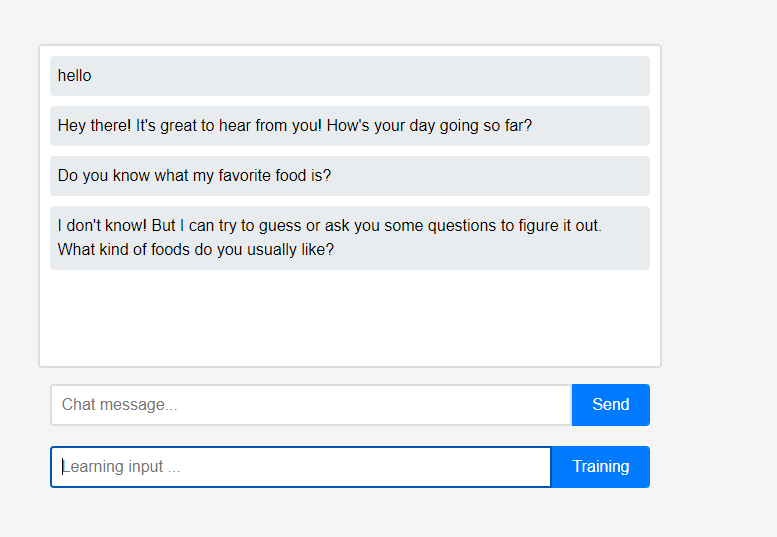 Al principio, el asistente no sabe nada sobre el usuario.
Al principio, el asistente no sabe nada sobre el usuario.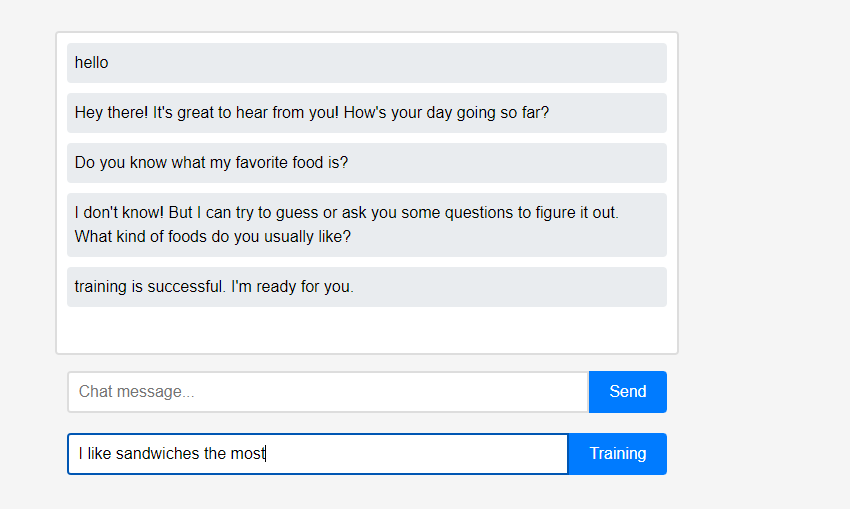 Sin embargo, los usuarios pueden enseñarle al asistente sobre ellos mismos en tiempo real.
Sin embargo, los usuarios pueden enseñarle al asistente sobre ellos mismos en tiempo real.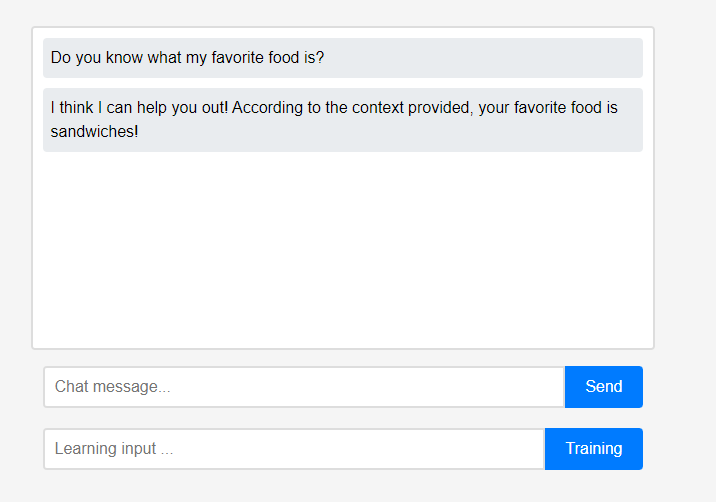 (Debido a las características de LLM, se puede malinterpretar que se recuerda como una cadena de conversación en lugar de un aprendizaje, por lo que se realizó después de la actualización). Los datos aprendidos se reflejaron inmediatamente, y esto puede verse como la primera personalización del asistente.
(Debido a las características de LLM, se puede malinterpretar que se recuerda como una cadena de conversación en lugar de un aprendizaje, por lo que se realizó después de la actualización). Los datos aprendidos se reflejaron inmediatamente, y esto puede verse como la primera personalización del asistente.
Todas estas características del proyecto pueden ser compatibles localmente sin la necesidad de una integración en la nube externa o una conexión a Internet.



query = protobuf . search_pb2 . SearchRequest (
dataset_id = dataset_id ,
query = get_image_embedding ( "./test_data/bad.png" ),
k = 1
)
results = search . Search ( query )
try :
for result in results :
print ( "Search result:" , result . id , result . metadata , result . score )
except grpc . RpcError as e :
print ( "Search failed:" , e )
query = protobuf . search_pb2 . SearchRequest (
dataset_id = dataset_id ,
query = get_image_embedding ( "./test_data/good.png" ),
k = 1
)
results = search . Search ( query )
try :
for result in results :
print ( "Search result:" , result . id , result . metadata , result . score )
except grpc . RpcError as e :
print ( "Search failed:" , e )


