dstoolkit km solution accelerator
V1.6

Acelerador de soluciones de Minería del Conocimiento
Este repositorio contiene todo el código para implementar una solución de minería de conocimientos de un extremo a otro basada en Azure Cognitive Search.
Está construido sobre los servicios estándar de Azure como Functions, Web App Services, Congitive Services y Cognitive Search. Proporciona una canalización de implementación que permite una configuración rápida y sencilla de canalizaciones de CI/CD para sus proyectos.
Para obtener documentación detallada, consulte la sección de documentos del repositorio que contiene la wiki de la solución.
Para configurar correctamente su solución, necesitará tener acceso o aprovisionar lo siguiente:
Se asume un rol de propietario o colaborador en la suscripción de Azure o en el grupo de recursos de destino.
Consulte el archivo README para implementar este acelerador de soluciones.
Las instrucciones proporcionadas en todas las guías suponen que tiene conocimientos prácticos fundamentales de Azure Portal, Azure Functions, Azure Cognitive Search, Functions, Storage y Azure Cognitives Services.
Para obtener capacitación y soporte adicionales, consulte:
La minería de conocimientos (KM) es una disciplina emergente en inteligencia artificial (IA) que utiliza una combinación de servicios inteligentes para aprender rápidamente a partir de grandes cantidades de información. Permite a las organizaciones comprender en profundidad y explorar fácilmente información, descubrir conocimientos ocultos y encontrar relaciones y patrones a escala.
Minería de conocimiento en Azure
Este acelerador de soluciones KM tiene como objetivo brindarle una solución viable de minería de conocimientos de extremo a extremo compuesta por:
Con este acelerador basado en la nube obtendrá una solución de extremo a extremo con las herramientas para implementar, ampliar, operar y monitorear.
En ese sentido, la solución proporciona
Este acelerador de soluciones de Knowledge Mining está inspirado en otro acelerador, Knowledge Mining Solution Accelerator.
Con base en nuestra experiencia en el campo, creamos funciones/habilidades para abordar los desafíos comunes de los datos no estructurados, enfocándonos en la usabilidad y la experiencia de exploración de datos.
A continuación se muestra una lista no exhaustiva de los aspectos más destacados:
Indexación de imágenes incrustadas
Normalización de imagen :
Metadatos
Conversión HTML
Extracción de tablas : la información tabular es común en corpus de datos no estructurados. La solución extraerá, indexará y proyectará tablas en un almacén de conocimientos dedicado (opcional).
Traducción ": hay dos funciones de traducción en esta solución
Análisis de texto : extraiga entidades (nombradas, vinculadas) de cualquier documento y texto de imagen con OCR.
Exportar a Excel : pregunta popular al explorar datos no estructurados.
Interfaz de usuario configurable : crear una interfaz de usuario requiere mucho tiempo; queríamos ofrecer una gran capacidad de configuración de la interfaz de usuario para que pudieras dar vida a nuevas soluciones de KM de manera oportuna.
Este espíritu acelerador de soluciones es un escenario de KM de investigación de contenidos.
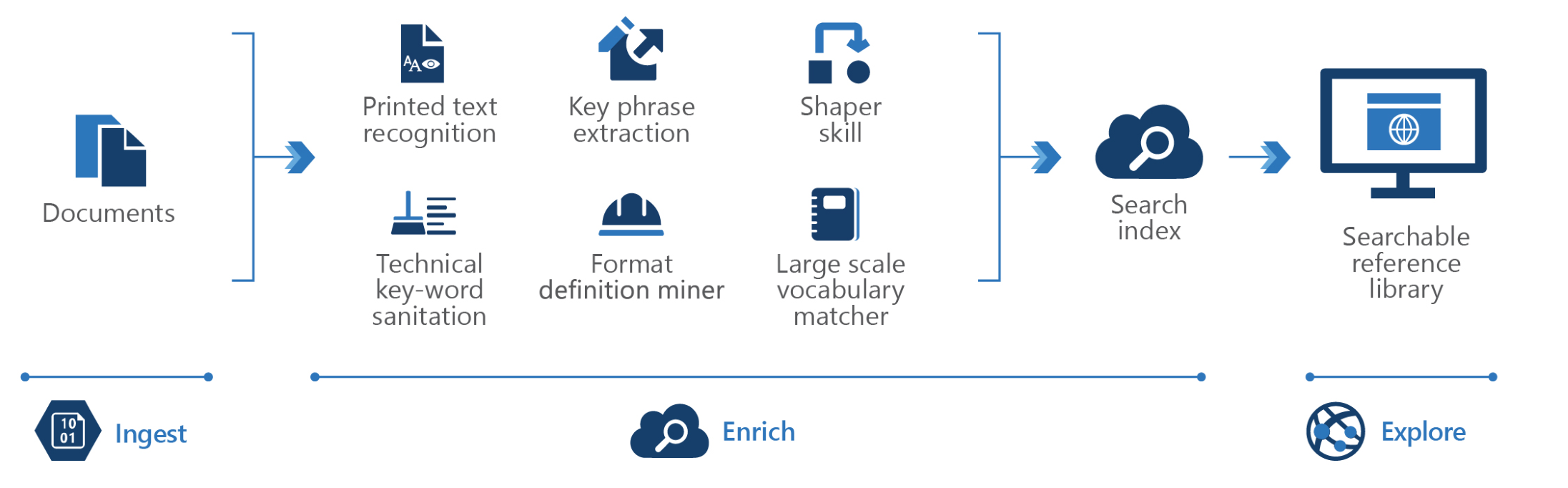
Sin embargo, dado que su arquitectura es abierta, podría utilizarla como base para escenarios de KM más especializados.
Este acelerador de soluciones no está dirigido a ningún dominio, aunque su extensibilidad le brindará las herramientas para hacerlo específico para un dominio.
Algunos casos de uso inspiradores
Quizás piense en la productización como acelerador para su organización.
Este acelerador de soluciones se dirige a quienes necesitan
El propósito de este acelerador de soluciones también es facilitar la integración de módulos de ciencia de datos en su solución de minería de conocimientos.
El equipo de Data Science Toolkit ha creado aceleradores para su carga de trabajo de ciencia de datos.
| Solución | Descripción |
|---|---|
| Versagilidad | Verseagility es un conjunto de herramientas basado en Python para acelerar su tarea personalizada de procesamiento del lenguaje natural (NLP), permitiéndole traer sus propios datos, utilizar sus marcos preferidos y llevar modelos a producción. Es un componente central del kit de herramientas de ciencia de datos de Microsoft. |
| Base de operaciones MLO | Este repositorio contiene la estructura de repositorio básica para proyectos de aprendizaje automático basados en tecnologías de Azure (Azure ML y Azure DevOps). Los nombres de las carpetas y los archivos se eligen según la experiencia personal. Puede encontrar los principios e ideas detrás de la estructura, que recomendamos seguir al personalizar su propio proyecto y proceso MLOps. Además, esperamos que los usuarios estén familiarizados con los conceptos de aprendizaje automático de Azure y cómo utilizar la tecnología. |
| MLOps para DataBricks | Este repositorio contiene el marco de desarrollo de Databricks para entregar cualquier proyecto de ingeniería de datos y proyectos de aprendizaje automático basados en tecnologías Azure. |
| Acelerador de soluciones de clasificación | Este repositorio contiene la estructura de repositorio básica para ofrecer soluciones de clasificación para proyectos de aprendizaje automático (ML) basados en tecnologías de Azure (Azure ML y Azure DevOps). |
| Acelerador de soluciones de detección de objetos | Este repositorio contiene todo el código para entrenar modelos de detección de objetos de TensorFlow dentro de Azure Machine Learning (AML) con configuraciones para entrenar en computación de Azure, monitoreo de experimentos e implementación de puntos finales como un servicio web. Se basa en MLOps Accelerator y proporciona canales de capacitación e implementación de extremo a extremo, lo que permite una configuración rápida y sencilla de canales de CI/CD para sus proyectos. |
Puede consultar la documentación del acelerador de soluciones de la siguiente manera:
| Tema | Descripción | Enlace de documentación |
|---|---|---|
| Requisitos previos | ¿Qué necesita para implementar y operar la solución? | LÉAME |
| Arquitectura | Cómo se diseña la solución | LÉAME |
| Despliegue | Cómo implementar este acelerador de soluciones | LÉAME |
| Configuración | Todo lo que necesita saber sobre la configuración del acelerador de soluciones | LÉAME |
| Ciencia de datos | Integración con la ciencia de datos | LÉAME |
| Despliegue | Ho para comenzar implementando la solución | LÉAME |
| Escucha | Cómo monitorear la solución | LÉAME |
| Buscar | Cómo se configura y gestiona la búsqueda | LÉAME |
| Buscar y explorar (UI) | Interfaz de usuario para buscar y explorar | LÉAME |
La estructura del repositorio de este acelerador es la siguiente
Clone o descargue este repositorio y luego navegue hasta la carpeta Implementación, siguiendo los pasos descritos en la guía de implementación.
Cuando complete todos los pasos, tendrá una solución funcional de minería de conocimientos de un extremo a otro que combina la ingesta de fuentes de datos con habilidades de enriquecimiento de datos y una aplicación web con tecnología de Azure Cognitive Search.
Esta solución está inspirada en el trabajo original del
Los principales contribuyentes a este acelerador de soluciones son
El equipo de patrocinio del kit de herramientas de ciencia de datos
Por la gran conversación sobre Minería de Conocimiento y Datos No Estructurados
Este proyecto agradece contribuciones y sugerencias. La mayoría de las contribuciones requieren que usted acepte un Acuerdo de licencia de colaborador (CLA) que declara que tiene derecho a otorgarnos, y de hecho lo hace, los derechos para usar su contribución. Para obtener más detalles, visite https://cla.opensource.microsoft.com.
Cuando envía una solicitud de extracción, un bot CLA determinará automáticamente si necesita proporcionar un CLA y decorar el PR de manera adecuada (por ejemplo, verificación de estado, comentario). Simplemente siga las instrucciones proporcionadas por el bot. Solo necesitarás hacer esto una vez en todos los repositorios que utilicen nuestro CLA.
Este proyecto ha adoptado el Código de conducta de código abierto de Microsoft. Para obtener más información, consulte las preguntas frecuentes sobre el Código de conducta o comuníquese con [email protected] si tiene alguna pregunta o comentario adicional.
Este proyecto puede contener marcas comerciales o logotipos de proyectos, productos o servicios. El uso autorizado de las marcas comerciales o logotipos de Microsoft está sujeto y debe seguir las Pautas de marcas y marcas comerciales de Microsoft. El uso de marcas comerciales o logotipos de Microsoft en versiones modificadas de este proyecto no debe causar confusión ni implicar patrocinio de Microsoft. Cualquier uso de marcas comerciales o logotipos de terceros está sujeto a las políticas de dichos terceros.


