TASE (motor de búsqueda de audio de Telegram)
Un motor de búsqueda de texto completo de audio ultrarrápido además de Telegram
Permite a los usuarios encontrar rápida y fácilmente información de interés o valor genuino, sin la necesidad de recorrer numerosos canales irrelevantes. Proporciona a los usuarios resultados de búsqueda que conducen a información relevante sobre archivos de audio de alta calidad.
Contenido
- ¿Qué hace que TASE sea especial?
- Cómo instalar y ejecutar
- Características
- Pila de tecnología
- Convocatoria de contribuciones
- Licencia y personas
¿Qué hace que TASE sea especial?
TASE es una plataforma de motor de búsqueda de audio de texto completo de código abierto en crecimiento que atiende solicitudes de gran volumen de los usuarios. Basada en Python y Telegram, la última actualización importante presenta muchas características nuevas, entre las que se incluye un patrón de diseño modular y altamente abstracto impulsado por Elasticsearch y ArangoDB con soporte para clústeres paralelos en diferentes servidores ubicados en diferentes partes del mundo.
TASE de un vistazo
- Motor de búsqueda avanzado de texto completo para archivos de audio
- Indexador de archivos de audio extremadamente rápido (punto de referencia: mínimo 4 millones de canciones por día por cliente)
- Soporte para múltiples clientes paralelos como indexador.
- Soporte para clústeres paralelos distribuidos en múltiples servidores (búsqueda e indexación) (todos los archivos de audio, modelos de gráficos y documentos)
- Gráfico de usuarios y artículos.
- URL dinámicas
- Asincrónico
- Llegar a las herramientas de administración
- Plurilingüe
- Almacenamiento en caché de archivos de audio
- Fácil configuración y personalización
- Aspecto y sensación amigables
TASE es gratis y siempre lo será. Ayúdanos... Si te encantan las cosas gratuitas y el software fantástico, ¡danos una estrella! :estrella::estrella2:
Cómo instalar y ejecutar
* Nota: asegúrese de leer la sección de configuración y personalización antes de ejecutar el proyecto Hay dos formas diferentes de utilizar TASE
(*nota: antes de ejecutar el proyecto, asegúrese de configurar los archivos tase.json y .env) Clonar el repositorio
Configuración de servicios:
Instalar manualmente las dependencias.
- Instale Elasticsearch (v8.3) (instrucciones)
- Instalar ArangoDB (v3.9.1) (instrucciones)
- Instalar RabbitMQ (instrucciones)
- Instalar Redis (instrucciones)
Ejecutar usando Docker Compose
El método más sencillo (recomendado) (*nota: antes de ejecutar el proyecto, asegúrese de configurar el archivo tase.json) ventana acoplable componer -d
* instale Docker Compose si aún no lo ha hecho (instrucciones)
- * instala poesía si aún no lo has hecho (instrucciones)
- Ejecute el archivo tase_client.py ubicado en el paquete tase
Configuración y personalización
Antes de ejecutar su proyecto, debe personalizar el archivo tase.json en el directorio raíz que TASE utiliza como archivo de configuración.
Para ejecutar el proyecto, debes proporcionar información básica con la que trabaja el bot. Por ejemplo, debe proporcionar el token del bot de Telegram y la información de autenticación de su cliente de Telegram para ejecutar sus propios clientes.
Características
Funciones para desarrolladores
- Agregue nuevos idiomas en las configuraciones regionales (recomendamos usar Poedit)
- Agregue fácilmente nuevos botones y funcionalidades (consulta y en línea) implementando los métodos abstractos en la clase de botón base.
- Visualizaciones en tiempo real para modelos gráficos y archivos de audio (Kibana, ArangoDB)
- Patrón de diseño de abstracción y fachada.
Amplia gama de características
motor de búsqueda
- Busque archivos de audio a través de la búsqueda directa del bot
- Busque archivos de audio de grupos y chats privados usando la mención @bot_name y envíelos directamente al chat
- Búsqueda en tiempo real utilizando la mención @bot_name, mostrando una lista de resultados en línea
- Búsqueda en tiempo real directamente en los chats privados y grupales.
- Búsqueda basada en nombre de archivo, nombre de intérprete y nombre de audio
- Muestra los 10 resultados más relevantes en un mensaje e ilimitados en más resultados; devuelto como una lista en línea
- Reproduzca las canciones en las listas en línea antes de descargarlas.
- Caché de archivos de audio buscados para evitar solicitudes de base de datos redundantes e innecesarias
- URL dinámica para los resultados.
- Permite al propietario rastrear los archivos de audio descargados.
- Alta precisión y relevancia
- Buscar en una amplia variedad de idiomas
- Mostrar el nombre del canal de origen y el enlace al archivo.
- Ordenar resultados en modo inverso (para hacer resultados más relevantes en la parte inferior)
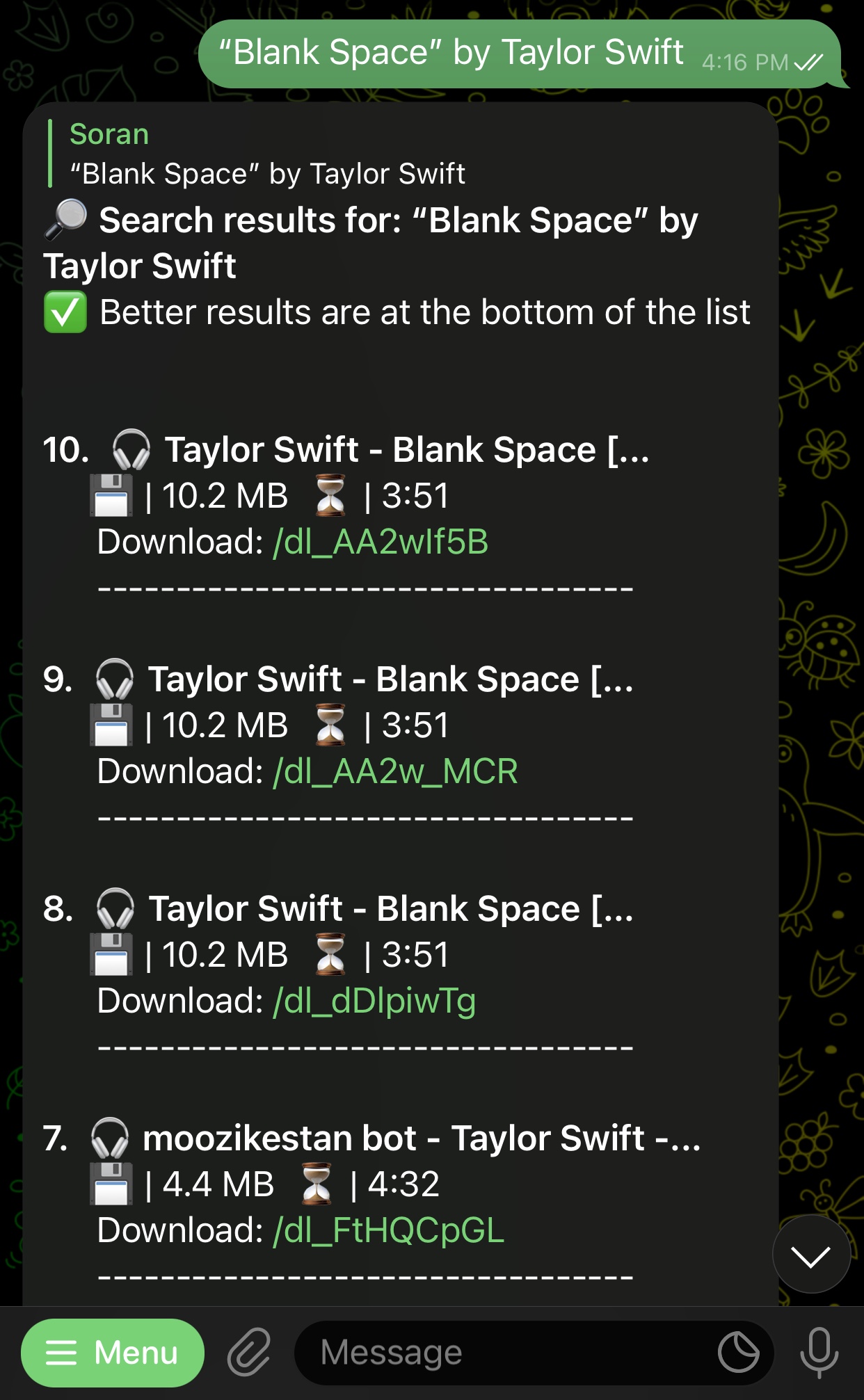 Captura de pantalla de ejemplo de búsqueda
Captura de pantalla de ejemplo de búsqueda
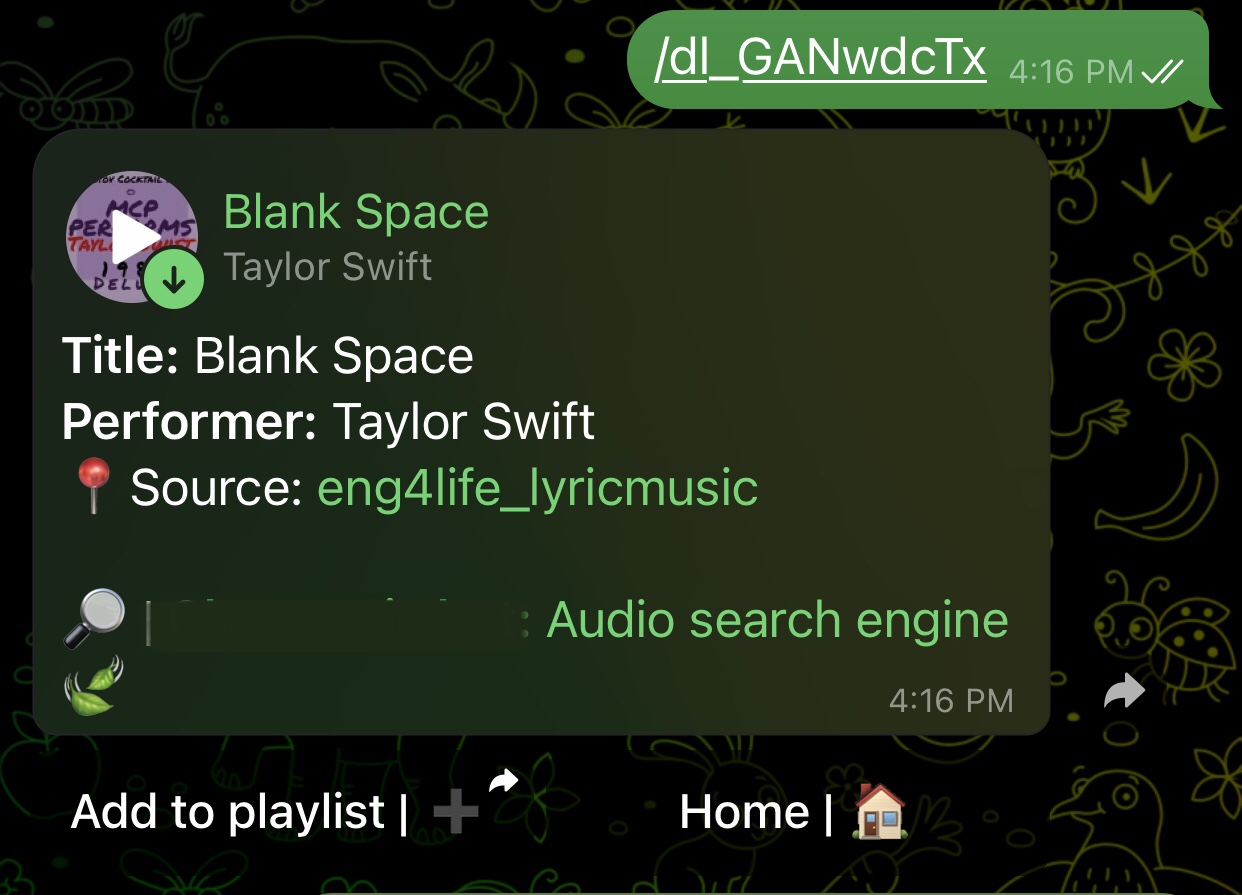 Captura de pantalla de ejemplo de audio del resultado
Captura de pantalla de ejemplo de audio del resultado
Funciones de indexación
- Encuentra automáticamente nuevos canales de forma optimista (primero asume que es un canal válido y lo valida después antes de comenzar a indexar)
- Extracto de textos y leyendas.
- Extracto de "mención reenviada"
- Extracto de enlaces
- Indexa automáticamente nuevos canales
- Itera a través de canales anteriores y reanuda la indexación desde el punto de control anterior.
- Indexación extremadamente rápida (mínimo 4 millones de canciones por día por cliente
- Analiza canales y calcula una puntuación (0-5) en función de su
- Densidad de archivos de audio (proporción de archivos de audio
- Actividad del canal (con qué frecuencia comparte archivos nuevos)
- Número de miembros
- Evita ser baneado por los servidores de Telegram.
- Soporte para indexación paralela usando múltiples clientes de Telegram
- Realiza un hash de los ID de los archivos de una forma específica que evita conflictos en gran medida y aún así los mantiene tan cortos como ocho caracteres.
- Los usuarios y propietarios de canales pueden enviar solicitudes para indexar un canal específico usando "/index nombre_canal"
- Construye un gráfico para usuarios y archivos de audio en tiempo real que puede usarse para sistemas de recomendación y tareas de predicción de enlaces.
Funciones de limitación/control del usuario
- Gestione la membresía de los usuarios en sus canales casi en tiempo real
- Establecer limitaciones para los usuarios según su estado de membresía
- Limita a los usuarios que no son miembros a buscar 5 archivos de audio libremente y luego deben esperar un minuto hasta recibir los archivos de audio buscados.
- Los no miembros tienen limitaciones con las búsquedas directas en el chat.
Interfaz de usuario
- guía de usuario
- Múltiples menús (inicio, ayuda, lista de reproducción, etc.)
- Un teclado para cada parte para facilitar el proceso a los usuarios
- Bot multilingüe (actualmente compatible):
- ?? Inglés
- ?? Español
- ?? ruso
- ?? árabe
- ?? portugués
- ?? hindi
- ?? Alemán
- ?? Kurdo (sorani)
- ?? Kurdo (Kurmanji)
- ?? Holandés
- ?? italiano
- ?? persa
- Mensajes de saludo a los usuarios según su actividad si no han estado activos durante más de una semana o más de dos semanas
- Muestra el historial de búsqueda de cada usuario a través de una lista en línea desplazable presionando el botón de historial en el teclado de inicio.
- Hermosa y vibrante interfaz de usuario (mensajes y emojis)
Listas de reproducción
- Los usuarios pueden tener listas de reproducción ilimitadas y guardar archivos de audio ilimitados en cada una.
- Los usuarios pueden editar los metadatos de la lista de reproducción.
- Los usuarios pueden editar archivos de audio guardados.
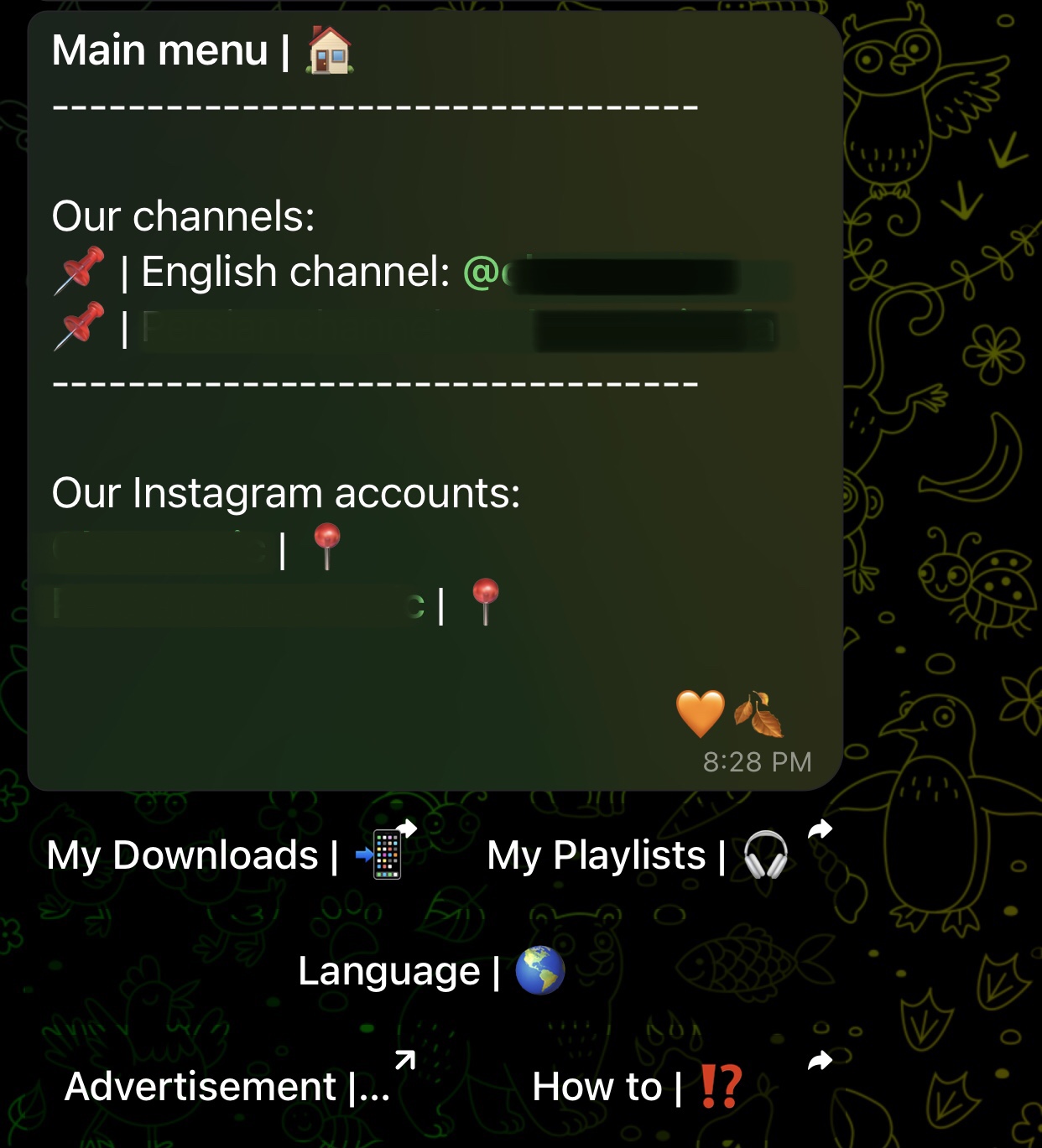 Captura de pantalla del menú principal
Captura de pantalla del menú principal
Funciones de administrador
- Visualización de gráficos en tiempo real (compatible con el panel de ArangoDB)
- Visualización de archivos de audio indexados en tiempo real (compatible con el panel de Kibana)
* Kibana es una herramienta de exploración y visualización de datos que se utiliza para análisis de registros y series temporales, monitoreo de aplicaciones y casos de uso de inteligencia operativa. Ofrece funciones potentes y fáciles de usar, como histogramas, gráficos de líneas, gráficos circulares, mapas de calor y soporte geoespacial integrado.
Otro
- Extremadamente rápido
- La documentación se proporciona en los códigos (cadena de documentos)
- Maneja excepciones relacionadas con la base de datos
- Búsqueda multiproceso (busca múltiples solicitudes de forma asincrónica)
- Maneja perfectamente los textos RTL
Pila de tecnología
Las principales herramientas y tecnologías utilizadas en el desarrollo de TASE son las siguientes:
- búsqueda elástica
- ArangoDB
- Pirograma
- Python get_texto
- Apio
- ConejoMQ
- Redis
- pidántico
- Jinja
Convocatoria de contribuciones
¡Agradecemos su experiencia y entusiasmo!
Formas de contribuir al motor de búsqueda de audio de Telegram:
- Escribir código
- Revisar solicitudes de extracción
- Desarrollar tutoriales, presentaciones, documentación y otros materiales educativos.
- Traducir documentación y contenidos Léame
Nos encantan sus contribuciones y hacemos todo lo posible para brindarle tutoría y apoyo. Si está buscando un problema que abordar, eche un vistazo a los problemas.
Asuntos
Si encuentra algún problema con los códigos, infórmelo aquí. Una mejor manera es bifurcar el repositorio en Github y/o crear una solicitud de extracción.
Trabajo futuro
Si te resultó útil, por favor danos un
Licencia
TASE tiene la licencia Apache, versión 2.0. Consulte LICENCIA para obtener el texto completo de la licencia.
Copyright © 2020-2022
- Soran Ghaderi ([email protected])
- Sitio web personal: soran-ghaderi.github.io
- Linkedin: Soran-Ghaderi
- Gorjeo: SoranGhadri
- Taleb Zarhesh ([email protected])
- Linkedin: Taleb Zarhesh
- Twitter: Taleb Zarhesh


