Motor de recuperación de memes
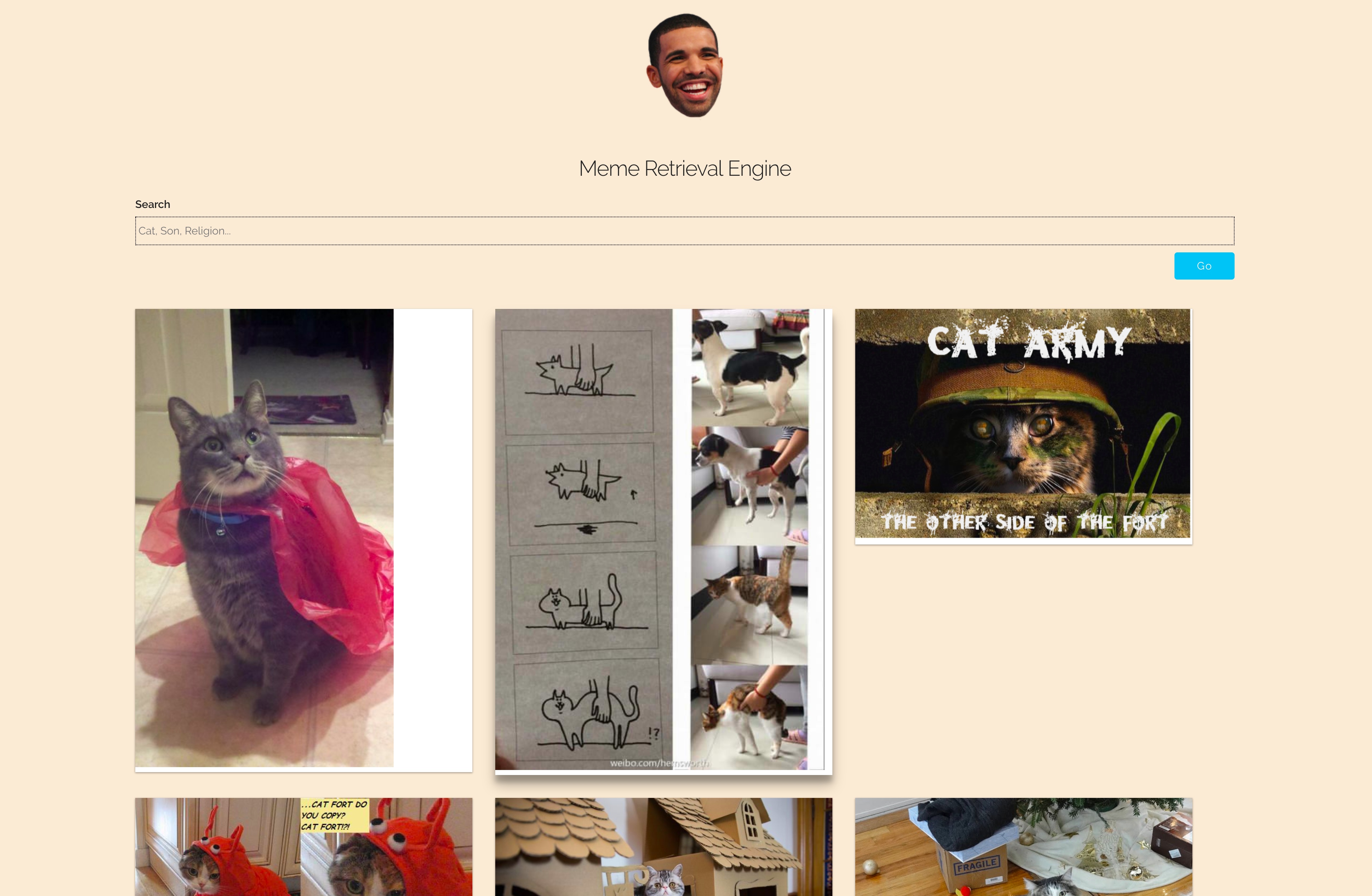
Descripción del proyecto
Tecnologías empleadas
- Procesamiento de imágenes
- Aprendizaje automático
- Procesamiento del lenguaje natural
- Secuencias de comandos de shell
Recopilación
Los memes se recopilan de subreddits populares utilizando un script scraper scrape/scraper.py
Normalización
- Los memes recopilados se colocan en una carpeta
raw y se ejecuta el script standard.py - Cada nombre de archivo se extrae y almacena en un archivo de texto junto al nuevo nombre de archivo hexadecimal generado para la imagen.
- Las imágenes estandarizadas se almacenan en la carpeta
processed .
Extracción de consultas
- La consulta ingresada se divide en palabras y se agregan sinónimos para cada palabra a la lista de
related queries usando la biblioteca nltk. - Escaneamos la base de datos para hacer coincidir palabras con las palabras en
related queries - Esto amplía el área de búsqueda y minimiza los escenarios de salida cero.
Relevancia para la consulta
- Los memes están ordenados según su relevancia para la consulta de búsqueda.
- Esto se hace asignando una puntuación a cada meme presente en la base de datos y luego ordenándolos en orden descendente de puntuaciones.
Reconocimiento óptico de caracteres
- El OCR se realiza utilizando Tesseract para extraer texto de los memes, lo cual es una parte esencial del proyecto.
- El texto extraído no es perfectamente preciso, por lo que el resultado de ocr se introduce en el corrector ortográfico de la biblioteca
autocorrect de Python. - El corrector ortográfico hace que la conversión sea más precisa
Prueba rápida
Para ejecutar la GUI y probar las funcionalidades, simplemente escriba
Recoger y ejecutar
- Para recopilar los memes de los subreddits.
- El script bash prepara la base de datos que permite que Meme Engine funcione correctamente
- Para ejecutar el tipo Meme Retrieval Engine (Meme Finder)
- Ingrese la consulta en el campo de texto y haga clic en
Go - Los memes están ordenados según su relevancia.
- Los memes seleccionados se pueden explorar usando los botones
Next y Previous .
Agregar nuevos subreddits a la lista
Requisitos
- cv2 (OpenCV)
- pytesseract
- ntk
- PILA
- hashlib
- callar
- autocorrección
- pimongo
Mejoras futuras
- Agregar funcionalidad a la barra de progreso
- Corregir la escala de tamaño de los memes para mostrarlos en el lienzo.
- Agregar función para vaciar los memes almacenados
- Almacenar plantillas de memes populares y verificar imágenes en busca de similitudes y asociar palabras clave especiales
Documentación
Documentación de MemeFinder


