idt
1.0.0

La herramienta de conjunto de datos de imágenes (IDT) es una aplicación CLI desarrollada para facilitar y acelerar la creación de conjuntos de datos de imágenes que se utilizarán en el aprendizaje profundo. La herramienta logra esto extrayendo imágenes de varios motores de búsqueda como duckgo, bing y deviantart. IDT también optimiza el conjunto de datos de imágenes; aunque esta característica es opcional, el usuario puede reducir la escala y comprimir las imágenes para obtener un tamaño y dimensiones de archivo óptimos. Un conjunto de datos de muestra creado con idt que contiene una cantidad total de 23.688 archivos de imagen pesa solo 559,2 megabytes.
¡Estoy orgulloso de anunciar nuestra versión más nueva! ??
que cambio
Puedes instalarlo mediante pip o clonando este repositorio.
user@admin:~ $ pip3 install idt
O
user@admin:~ $ git clone https://github.com/deliton/idt.git && cd idt
user@admin:~/idt $ sudo python3 setup.py install
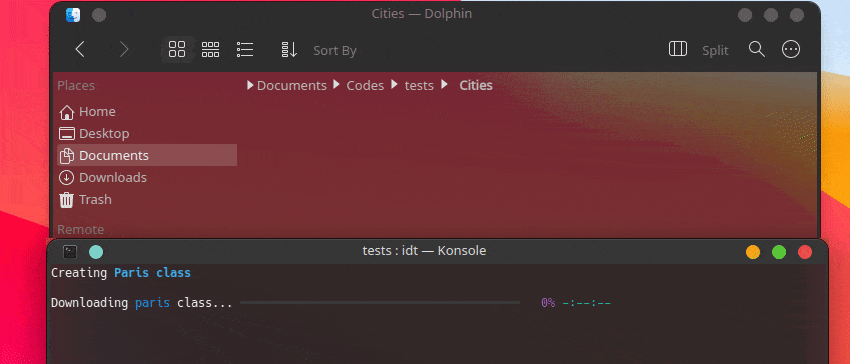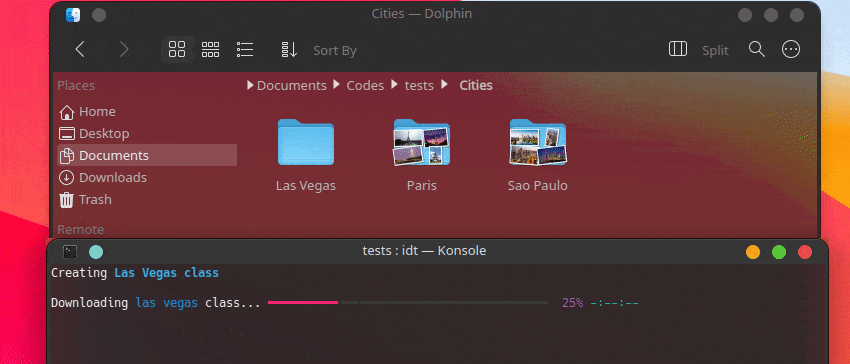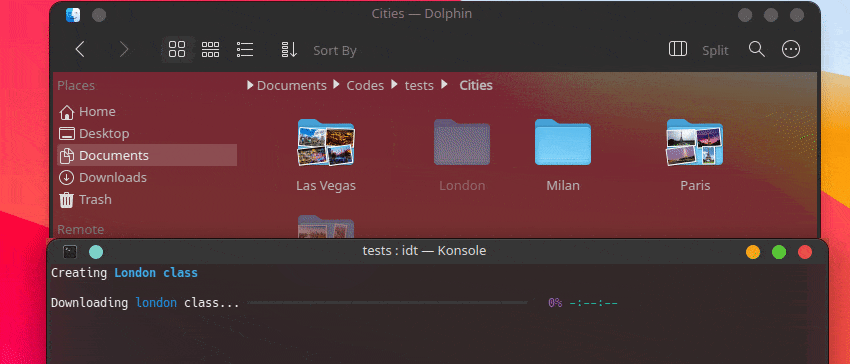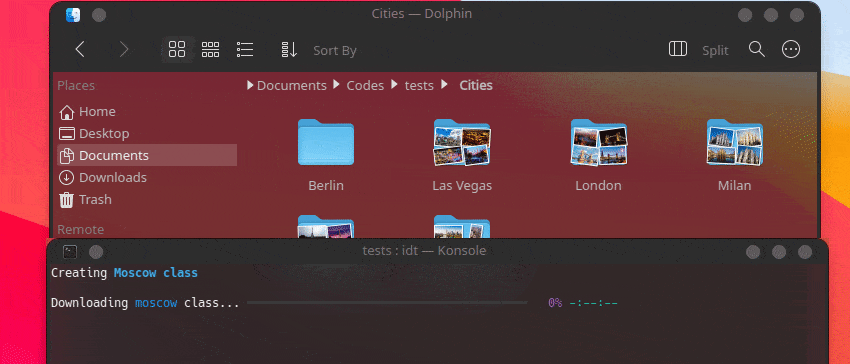
La forma más rápida de comenzar con IDT es ejecutar el simple comando "ejecutar". Simplemente escribe en tu consola favorita algo como:
user@admin:~ $ idt run -i apples Esto descargará rápidamente 50 imágenes de manzanas. Por defecto utiliza el motor de búsqueda duckgo para hacerlo. El comando ejecutar acepta las siguientes opciones:
| Opción | Descripción |
|---|---|
| -yo o --entrada | la palabra clave para encontrar las imágenes deseadas. |
| -s o --tamaño | la cantidad de imágenes a descargar. |
| -e o --motor | el motor de búsqueda deseado (opciones: duckgo, bing, bing_api y flickr_api) |
| --redimensionar-método | Elija un método de cambio de tamaño de las imágenes. (opciones: lado_más largo, lado_más corto y smartcrop) |
| -is o --tamaño-imagen | opción para establecer la relación de tamaño de imagen deseada. predeterminado = 512 |
| -ak o --api-key | Si está utilizando un motor de búsqueda que requiere una clave API, esta opción es obligatoria |
IDT requiere un archivo de configuración que le indique cómo se debe organizar su conjunto de datos. Puedes crearlo usando el siguiente comando:
user@admin:~ $ idt initEste comando activará el creador del archivo de configuración y solicitará los parámetros del conjunto de datos deseados. En este ejemplo, creemos un conjunto de datos que contenga imágenes de sus autos favoritos. El primer parámetro que preguntará este comando es ¿qué nombre debe tener su conjunto de datos? En este ejemplo, llamemos a nuestro conjunto de datos "Mis autos favoritos".
Insert a name for your dataset: : My favorite carsLuego, la herramienta le preguntará cuántas muestras por búsqueda se requieren para montar su conjunto de datos. Para crear un buen conjunto de datos para el aprendizaje profundo, se requieren muchas imágenes y, dado que utilizamos un motor de búsqueda para extraer imágenes, se requieren muchas búsquedas con diferentes palabras clave para montar un conjunto de datos de buen tamaño. Este valor corresponderá a cuántas imágenes se deben descargar en cada búsqueda. En este ejemplo necesitamos un conjunto de datos con 250 imágenes en cada clase y usaremos 5 palabras clave para montar cada clase. Entonces, si escribimos el número 50 aquí, IDT descargará 50 imágenes de cada palabra clave proporcionada. Si proporcionamos 5 palabras clave, deberíamos obtener las 250 imágenes requeridas.
How many samples per search will be necessary? : 50La herramienta ahora solicitará una relación de tamaño de imagen. Dado que el uso de imágenes grandes para entrenar redes neuronales no es viable, opcionalmente podemos elegir una de las siguientes proporciones de tamaño de imagen y reducir nuestras imágenes a ese tamaño. En este ejemplo, elegiremos 512x512, aunque 256x256 sería una opción aún mejor para esta tarea.
Choose images resolution:
[1] 512 pixels / 512 pixels (recommended)
[2] 1024 pixels / 1024 pixels
[3] 256 pixels / 256 pixels
[4] 128 pixels / 128 pixels
[5] Keep original image size
ps: note that the aspect ratio of the image will not be changed,
so possibly the images received will have slightly different size
What is the desired image size ratio: 1Y luego elija "longer_side" para el método de cambio de tamaño.
[1] Resize image based on longer side
[2] Resize image based on shorter side
[3] Smartcrop
ps: note that the aspect ratio of the image will not be changed,
so possibly the images received will have slightly different size
Desired Image resize method: : longer_side
Ahora debes elegir cuántas clases/carpetas debe tener tu conjunto de datos. En este ejemplo, esta parte puede ser muy personal, pero mis autos favoritos son: Chevrolet Impala, Range Rover Evoque, Tesla Model X y (por qué no) AvtoVAZ Lada. Entonces en este caso tenemos 4 clases, una para cada favorito.
How many image classes are required? : 4Luego, se le pedirá que elija entre uno de los motores de búsqueda disponibles. En este ejemplo, usaremos DuckGO para buscar imágenes por nosotros.
Choose a search engine:
[1] Duck GO (recommended)
[2] Bing
[3] Bing API
[4] Flickr API
Select option:: 1Ahora tenemos que completar algunos formularios repetitivos. Debemos nombrar cada clase y todas las palabras clave que se utilizarán para encontrar las imágenes. Tenga en cuenta que esta parte puede cambiarse posteriormente mediante su propio código, para generar más clases y palabras clave.
Class 1 name: : Chevrolet ImpalaDespués de escribir el nombre de la primera clase, se nos pedirá que proporcionemos todas las palabras clave para encontrar el conjunto de datos. Recuerde que le dijimos al programa que descargara 50 imágenes de cada palabra clave, por lo que debemos proporcionar 5 palabras clave en este caso para obtener las 250 imágenes. Cada palabra clave DEBE estar separada por comas (,)
In order to achieve better results, choose several keywords that will
be provided to the search engine to find your class in different settings.
Example:
Class Name: Pineapple
keywords: pineapple, pineapple fruit, ananas, abacaxi, pineapple drawing
Type in all keywords used to find your desired class, separated by commas: Chevrolet Impala 1967 car photos,
chevrolet impala on the road, chevrolet impala vintage car, chevrolet impala convertible 1961, chevrolet impala 1964 lowrider
Luego repita el proceso de completar el nombre de la clase y sus palabras clave hasta completar las 4 clases requeridas.
Dataset YAML file has been created successfully. Now run idt build to mount your dataset!Se ha creado el archivo de configuración de su conjunto de datos. Ahora simplemente oxida el siguiente comando y observa cómo sucede la magia:
user@admin:~ $ idt buildY espere mientras se monta el conjunto de datos:
Creating Chevrolet Impala class
Downloading Chevrolet Impala 1967 car photos [#########################-----------] 72% 00:00:12
Al final, todas sus imágenes estarán disponibles en una carpeta con el nombre del conjunto de datos. Además, también se incluye un archivo csv con las estadísticas del conjunto de datos en la carpeta raíz del conjunto de datos.
Dado que el aprendizaje profundo a menudo requiere que divida su conjunto de datos en un subconjunto de carpetas de capacitación/validación, ¡este proyecto también puede hacer esto por usted! Simplemente ejecuta:
user@admin:~ $ idt splitAhora debes elegir un tren/proporción válida. En este ejemplo he elegido que el 70% de las imágenes se reserven para entrenamiento, mientras que el resto se reservará para validación:
Choose the desired proportion of images of each class to be distributed in train/valid folders.
What percentage of images should be distributed towards training?
(0-100): 70
70 percent of the images will be moved to a train folder, while 30 percent of the remaining images
will be stored in a validation folder.
Is that ok? [Y/n]: y¡Y eso es todo! La división del conjunto de datos ahora debería encontrarse con los subdirectorios train/valid correspondientes.
Este proyecto se está desarrollando en mi tiempo libre y todavía necesita mucho esfuerzo para estar libre de errores. Las solicitudes de extracción y los contribuyentes son realmente apreciados, ¡siéntete libre de contribuir en todo lo que puedas!


