T5Elasticsearch
1.0.0
A continuación se muestra un ejemplo de búsqueda de empleo:
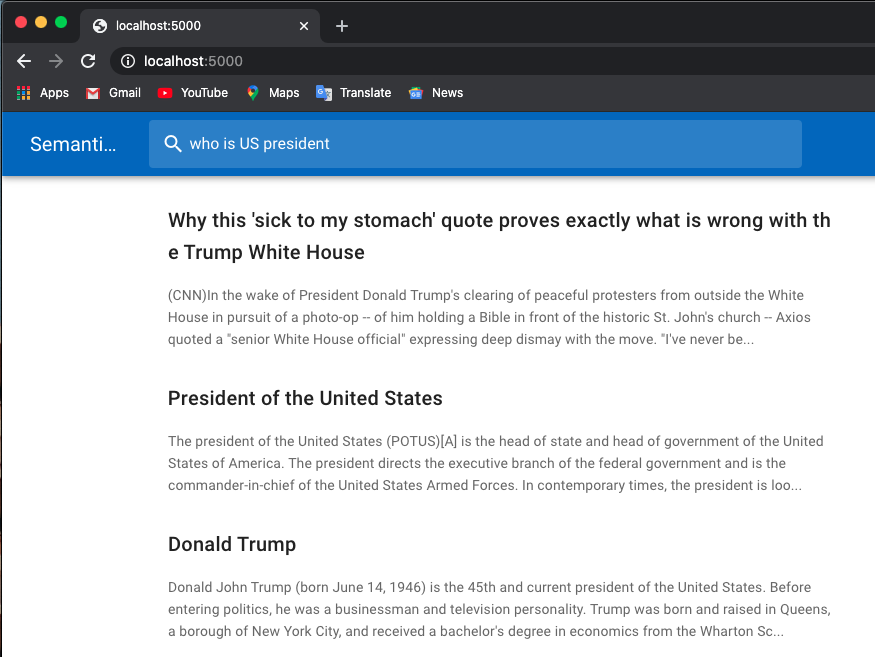
Utilizo modelos previamente entrenados de Huggingface Transformers.
Descargue manualmente el tokenizador previamente entrenado y el modelo t5/bert en los directorios locales. Puede consultar los modelos aquí.
Utilizo el modelo 't5-small', marque aquí y haga clic en List all files in model para descargar archivos. 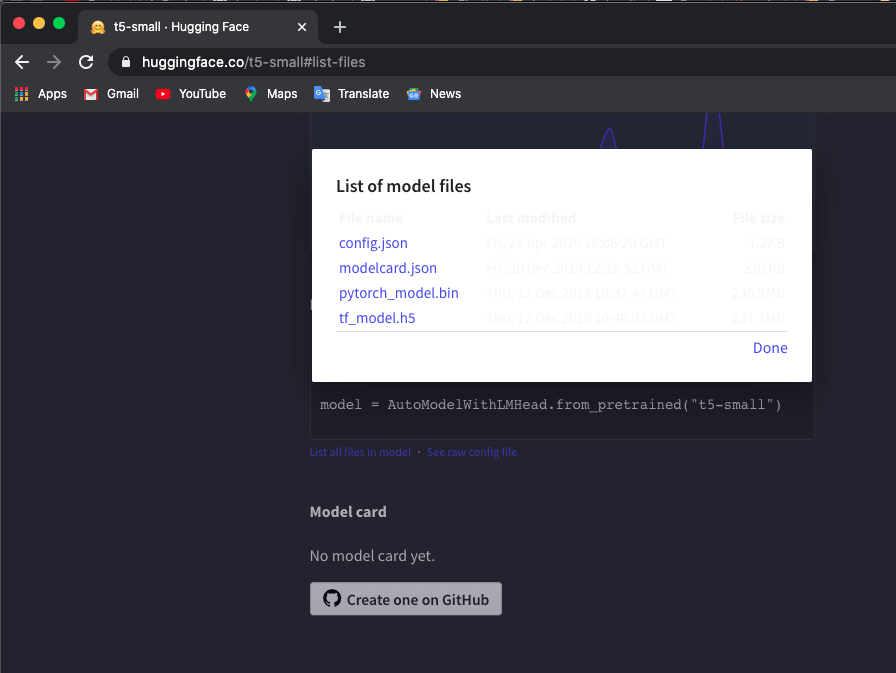
Tenga en cuenta la estructura del directorio de archivos descargados manualmente.
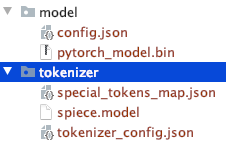
Podrías utilizar otros modelos T5 o Bert.
Si descarga otros modelos, consulte la lista de modelos previamente rastreados de los transformadores hugaface para verificar el nombre del modelo.
$ export TOKEN_DIR=path_to_your_tokenizer_directory/tokenizer
$ export MODEL_DIR=path_to_your_model_directory/model
$ export MODEL_NAME=t5-small # or other model you downloaded
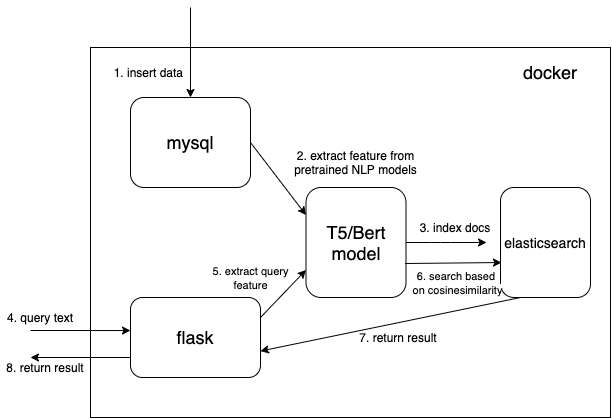
$ export INDEX_NAME=docsearch$ docker-compose up --build También utilizo docker system prune para eliminar todos los contenedores, redes e imágenes no utilizados para obtener más memoria. Aumente la memoria de su ventana acoplable (yo uso 8GB ) si encuentra Container exits with non-zero exit code 137 .
Usamos un tipo de datos vectorial denso para guardar las características extraídas de los modelos de PNL previamente entrenados (t5 o bert aquí, pero usted mismo puede agregar los modelos previamente entrenados que le interesen)
{
...
"text_vector" : {
"type" : " dense_vector " ,
"dims" : 512
}
...
} Dimensiones dims:512 es para modelos T5. Cambie dims a 768 si usa modelos Bert.
Lea el documento de mysql y convierta el documento al formato json correcto para masivamente en elasticsearch.
$ cd index_files
$ pip install -r requirements.txt
$ python indexing_files.py
# or you can customize your parameters
# $ python indexing_files.py --index_file='index.json' --index_name='docsearch' --data='documents.jsonl'Vaya a http://127.0.0.1:5000.
El código clave para usar el modelo previamente entrenado para extraer características es la función get_emb en los archivos ./index_files/indexing_files.py y ./web/app.py .
def get_emb ( inputs_list , model_name , max_length = 512 ):
if 't5' in model_name : #T5 models, written in pytorch
tokenizer = T5Tokenizer . from_pretrained ( TOKEN_DIR )
model = T5Model . from_pretrained ( MODEL_DIR )
inputs = tokenizer . batch_encode_plus ( inputs_list , max_length = max_length , pad_to_max_length = True , return_tensors = "pt" )
outputs = model ( input_ids = inputs [ 'input_ids' ], decoder_input_ids = inputs [ 'input_ids' ])
last_hidden_states = torch . mean ( outputs [ 0 ], dim = 1 )
return last_hidden_states . tolist ()
elif 'bert' in model_name : #Bert models, written in tensorlow
tokenizer = BertTokenizer . from_pretrained ( 'bert-base-multilingual-cased' )
model = TFBertModel . from_pretrained ( 'bert-base-multilingual-cased' )
batch_encoding = tokenizer . batch_encode_plus ([ "this is" , "the second" , "the thrid" ], max_length = max_length , pad_to_max_length = True )
outputs = model ( tf . convert_to_tensor ( batch_encoding [ 'input_ids' ]))
embeddings = tf . reduce_mean ( outputs [ 0 ], 1 )
return embeddings . numpy (). tolist ()Puedes cambiar el código y usar tu modelo previamente entrenado favorito. Por ejemplo, puede utilizar el modelo GPT2.
También puede personalizar su elasticsearch utilizando su propia función de puntuación en lugar de cosineSimilarity en .webapp.py .
Este representante se modifica en función de Hironsan/bertsearch, que utiliza paquetes bert-serving para extraer características de bert. Se limita a TF1.x


