context search engine
1.0.0

El objetivo principal de este proyecto es mostrar las capacidades de búsqueda vectorial proporcionando una interfaz fácil de usar que permita a los usuarios realizar búsquedas contextuales en un corpus de documentos de texto. Al aprovechar el poder de BERT de Hugging Face y FAISS de Facebook, devolvemos pasajes de texto altamente relevantes basados en el significado semántico de la consulta del usuario en lugar de meras coincidencias de palabras clave. Este proyecto sirve como punto de partida para desarrolladores, investigadores y entusiastas que deseen profundizar en el mundo de la búsqueda de texto contextualizado y mejorar sus aplicaciones con técnicas de PNL de última generación.
Mi objetivo es asegurarme de que comprendamos la base de datos vectorial detrás de escena desde cero.
Captura de pantalla de la aplicación:
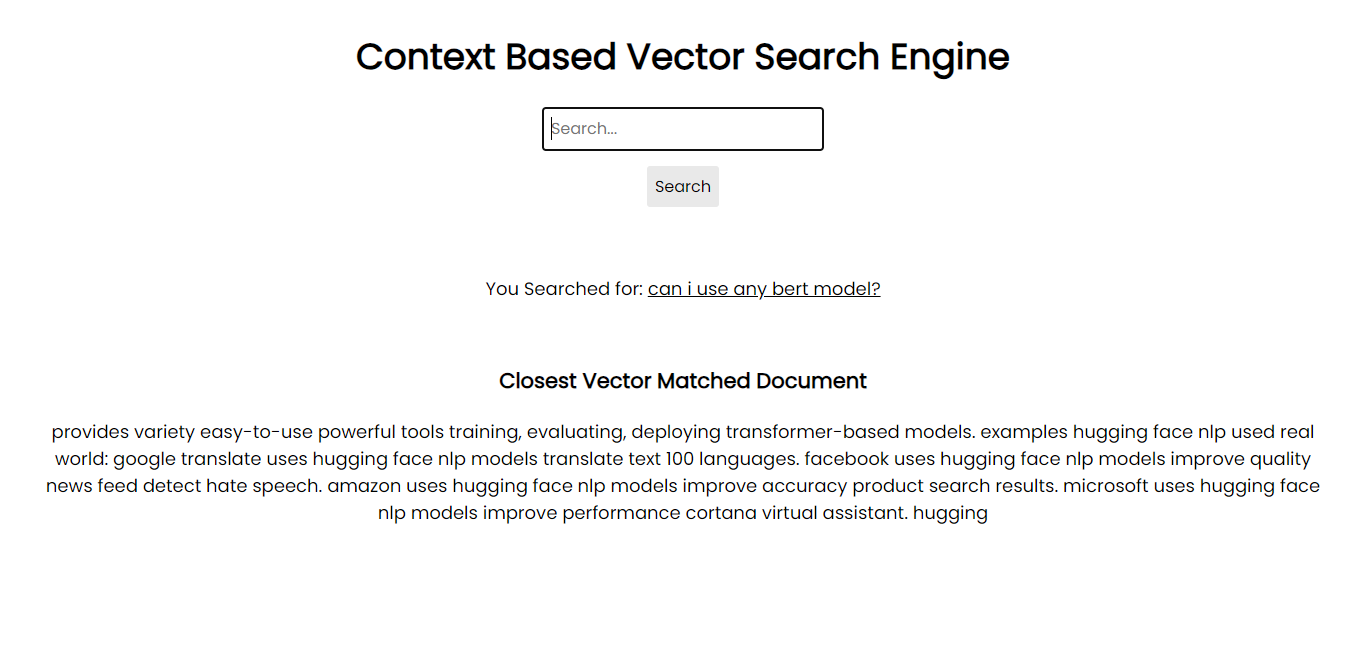
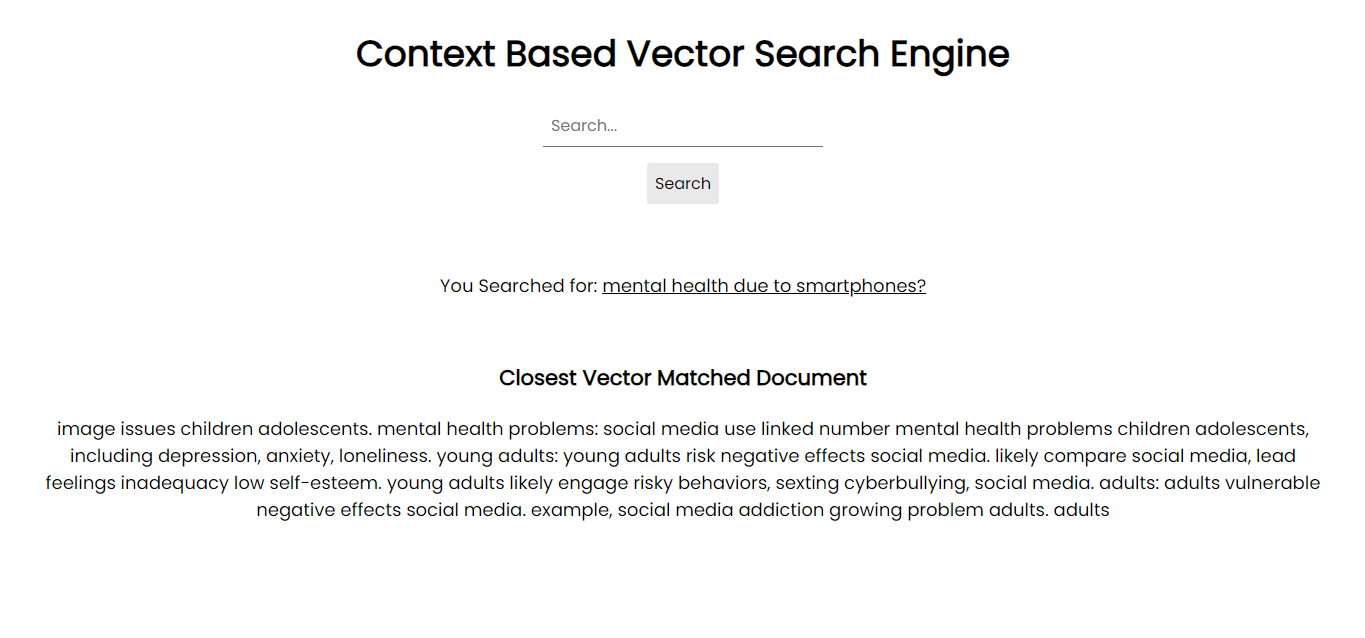
Para ejecutarlo en su sistema, puede instalar todos los paquetes necesarios a través de pip utilizando los archivos de requisitos:
pip install -r requirements.txtPara su información, estoy usando Python 3.10.1.
Sin embargo, si tiene una GPU, se le solicita que instale FAISS GPU para integraciones de bases de datos más rápidas y más grandes.
La versión actual de este proyecto abarca:
Si bien el proyecto ofrece un sistema de búsqueda contextual funcional, está diseñado para ser modular, lo que permite una posible expansión e integración en sistemas o aplicaciones más grandes.
La base de este proyecto radica en la creencia de que las técnicas modernas de PNL pueden ofrecer resultados de búsqueda mucho más precisos y contextualmente relevantes en comparación con los métodos tradicionales basados en palabras clave. Aquí hay un desglose de nuestro enfoque:
Según el enfoque, he dividido el proyecto en 2 secciones:
Sección 1: Generación de datos vectoriales con capacidad de búsqueda
En esta sección, primero leemos la entrada de los documentos, la dividimos en fragmentos más pequeños, creamos vectores usando el modelo basado en BERT y luego los almacenamos de manera eficiente usando FAISS. Aquí hay un diagrama de flujo que ilustra lo mismo.
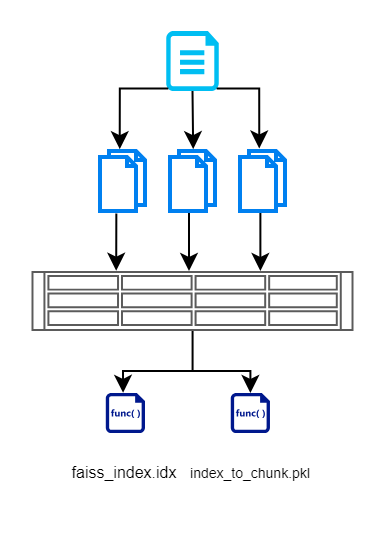
Creamos un archivo de índice FAISS que contiene una representación vectorial del documento fragmentado. También almacenamos el índice de cada fragmento. Esto se mantiene para que no tengamos que consultar la base de datos/los documentos nuevamente. Esto nos ayuda a eliminar operaciones de lectura redundantes.
Realizamos esta sección usando create_index.py. Generará los 2 archivos anteriores. Si necesita utilizar otros modelos, ¿está abierto a hacerlo desde el centro HuggingFace?
Nota: Si encuentra problemas al configurar el hiperparámetro para la dimensión, consulte el archivo config.json de modelos para encontrar detalles sobre la dimensión del modelo que está intentando utilizar.
Sección 2: Creación de una interfaz de aplicación con capacidad de búsqueda
En esta sección, mi objetivo es crear una interfaz que permita a los usuarios interactuar con los documentos. Priorizo el diseño minimalista sin causar obstáculos adicionales.
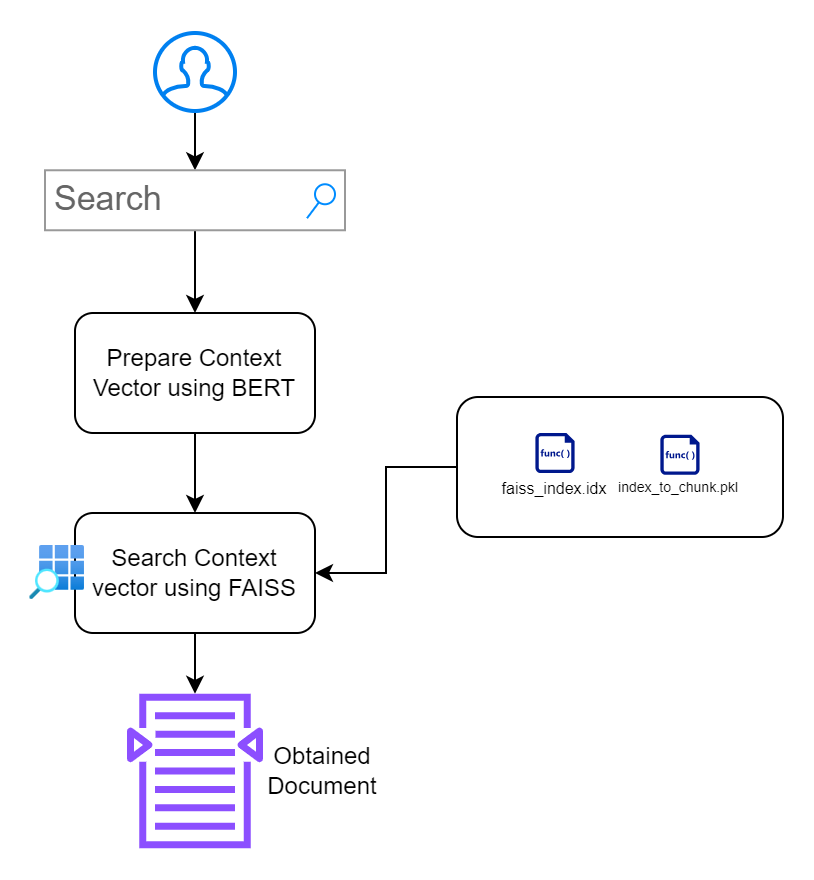
index.html : página HTML frontal para ingresar consultas de búsqueda.app.py : aplicación Flask que sirve al front-end y maneja consultas de búsqueda.search_engine.py : contiene lógica para incrustar generación, búsqueda FAISS y resaltado de palabras clave. /context_search/
- templates/
- index.html
- static/
- css/
- style.css
- images/
- img1.png
- img2.png
- Approach.png files
- app.py
- search_engine.py
- create_index.py
- index_to_chunk.pkl
- faiss_index.idxfaiss_index.idx ) y un mapeo adjunto del índice al fragmento de texto ( index_to_chunk.pkl ). python app.py
-- OR --
flask run --host=127.0.0.1 --port=5000
http://localhost:5000 .Siempre hay espacio para mejoras. A continuación se muestran algunas mejoras potenciales y características adicionales que se pueden integrar:
Este proyecto está bajo la Licencia MIT. Siéntase libre de utilizarlo, citarlo, modificarlo, distribuirlo y contribuir. Leer más.
Si estás interesado en mejorar este proyecto, ¡tus contribuciones son bienvenidas! Abra una solicitud de extracción o un problema en este repositorio. Básicamente, estoy priorizando las cosas anteriores para mejorar. También se considerarán otras solicitudes de extracción, pero con menos prioridad.
Gracias de antemano por su interés. :feliz: .


