textgenrnn
T
Entrene fácilmente su propia red neuronal generadora de texto de cualquier tamaño y complejidad en cualquier conjunto de datos de texto con unas pocas líneas de código, o entrene rápidamente en un texto utilizando un modelo previamente entrenado.
textgenrnn es un módulo de Python 3 además de Keras/TensorFlow para crear char-rnns, con muchas características interesantes:
¡Puedes jugar con textgenrnn y entrenar cualquier archivo de texto con una GPU de forma gratuita en este Cuaderno de colaboración! ¡Lea esta publicación de blog o mire este video para obtener más información!
from textgenrnn import textgenrnn
textgen = textgenrnn ()
textgen . generate () [Spoiler] Anyone else find this post and their person that was a little more than I really like the Star Wars in the fire or health and posting a personal house of the 2016 Letter for the game in a report of my backyard.
El modelo incluido se puede entrenar fácilmente con textos nuevos y puede generar texto apropiado incluso después de una sola pasada de los datos de entrada .
textgen . train_from_file ( 'hacker_news_2000.txt' , num_epochs = 1 )
textgen . generate () Project State Project Firefox
Los pesos del modelo son relativamente pequeños (2 MB en disco) y se pueden guardar y cargar fácilmente en una nueva instancia de textgenrnn. Como resultado, puedes jugar con modelos que han sido entrenados en cientos de pases a través de los datos. (de hecho, textgenrnn aprende tan bien que hay que aumentar significativamente la temperatura para obtener resultados creativos).
textgen_2 = textgenrnn ( '/weights/hacker_news.hdf5' )
textgen_2 . generate ( 3 , temperature = 1.0 ) Why we got money “regular alter”
Urburg to Firefox acquires Nelf Multi Shamn
Kubernetes by Google’s Bern
También puede entrenar un nuevo modelo, con soporte para incrustaciones a nivel de palabra y capas RNN bidireccionales agregando new_model=True a cualquier función de entrenamiento.
También es posible involucrarse en cómo se desarrolla el resultado, paso a paso. El modo interactivo le sugerirá las N opciones principales para el siguiente carácter/palabra y le permitirá elegir una.
Cuando ejecute textgenrnn en la terminal, pase interactive=True y top=N para generate . N por defecto es 3.
from textgenrnn import textgenrnn
textgen = textgenrnn ()
textgen . generate ( interactive = True , top_n = 5 )
Esto puede agregar un toque humano al resultado; ¡Se siente como si fueras el escritor! (referencia)
textgenrnn se puede instalar desde pypi mediante pip :
pip3 install textgenrnnPara obtener la última versión de textgenrnn, debe tener una versión mínima de TensorFlow 2.1.0 .
Puede ver una demostración de características comunes y opciones de configuración del modelo en este Jupyter Notebook.
/datasets contiene conjuntos de datos de ejemplo que utilizan datos de Hacker News/Reddit para entrenar textgenrnn.
/weights contiene modelos previamente entrenados en los conjuntos de datos antes mencionados que se pueden cargar en textgenrnn.
/outputs contiene ejemplos de texto generado a partir de los modelos previamente entrenados anteriores.
textgenrnn se basa en el proyecto char-rnn de Andrej Karpathy con algunas optimizaciones modernas, como la capacidad de trabajar con secuencias de texto muy pequeñas.
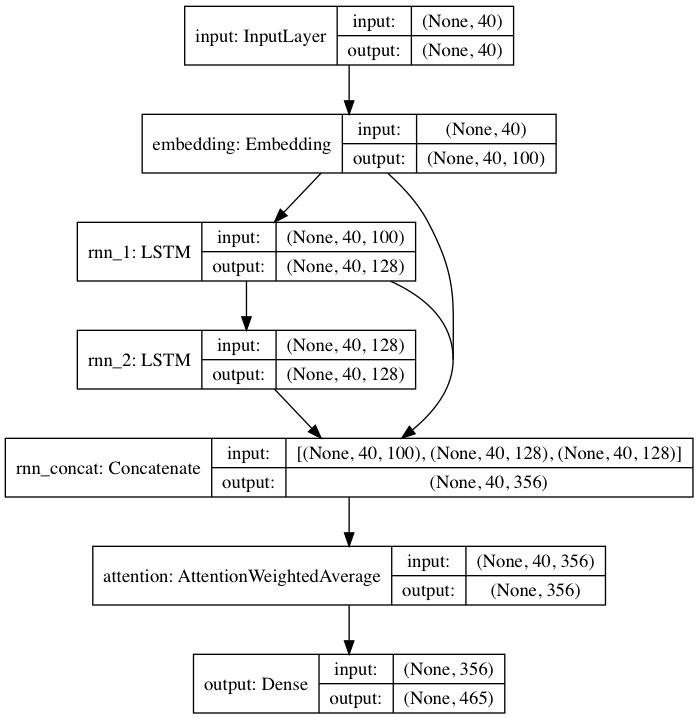
El modelo previamente entrenado incluido sigue una arquitectura de red neuronal inspirada en DeepMoji. Para el modelo predeterminado, textgenrnn toma una entrada de hasta 40 caracteres, convierte cada carácter en un vector de incrustación de caracteres 100-D y los introduce en una capa recurrente de memoria a corto plazo (LSTM) de 128 celdas. Luego, esas salidas se envían a otro LSTM de 128 celdas. Luego, las tres capas se introducen en una capa de Atención para ponderar las características temporales más importantes y promediarlas juntas (y dado que las incrustaciones + el primer LSTM están conectadas por salto a la capa de atención, las actualizaciones del modelo pueden propagarse hacia ellas más fácilmente y evitar la desaparición). gradientes). Esa salida se asigna a probabilidades de hasta 394 caracteres diferentes de que sean el siguiente carácter en la secuencia, incluidos caracteres en mayúsculas, minúsculas, puntuación y emoji. (si se entrena un nuevo modelo en un nuevo conjunto de datos, se pueden configurar todos los parámetros numéricos anteriores)
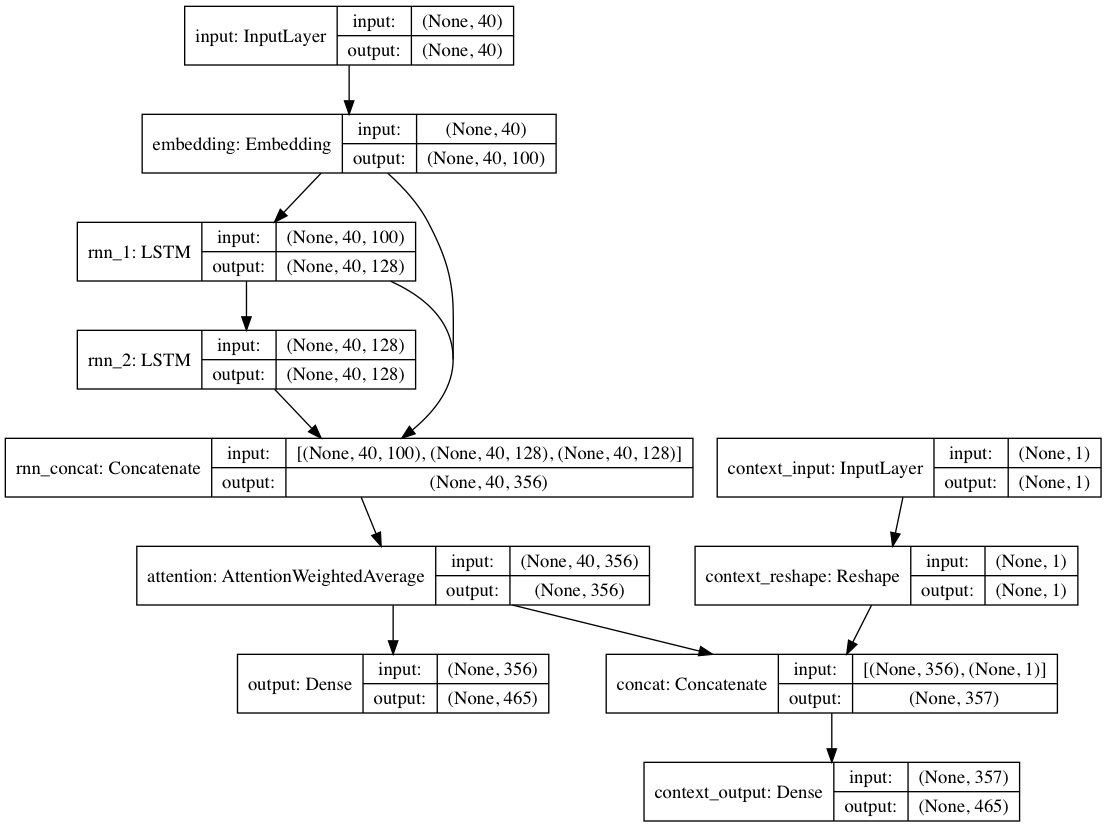
Alternativamente, si se proporcionan etiquetas de contexto con cada documento de texto, el modelo se puede entrenar en un modo contextual, donde el modelo aprende el texto dado el contexto para que las capas recurrentes aprendan el lenguaje descontextualizado . El camino de sólo texto puede aprovechar las capas descontextualizadas; En definitiva, esto da como resultado un entrenamiento mucho más rápido y un mejor rendimiento del modelo cuantitativo y cualitativo que simplemente entrenar el modelo sin tener en cuenta el texto.
Los pesos de los modelos incluidos en el paquete se entrenan en cientos de miles de documentos de texto de envíos de Reddit (a través de BigQuery), de una variedad muy diversa de subreddits. La red también se entrenó utilizando el enfoque descontextual mencionado anteriormente para mejorar el rendimiento de la capacitación y mitigar el sesgo del autor.
Al ajustar el modelo en un nuevo conjunto de datos de textos usando textgenrnn, todas las capas se vuelven a entrenar. Sin embargo, dado que la red original previamente entrenada tiene un "conocimiento" mucho más sólido inicialmente, el nuevo textgenrnn se entrena más rápido y con mayor precisión al final, y potencialmente puede aprender nuevas relaciones que no están presentes en el conjunto de datos original (por ejemplo, las incrustaciones de caracteres previamente entrenados incluyen el contexto). para el carácter para todos los tipos posibles de gramática moderna de Internet).
Además, el reentrenamiento se realiza con un optimizador basado en el impulso y una tasa de aprendizaje que decae linealmente, los cuales evitan gradientes explosivos y hacen que sea mucho menos probable que el modelo diverja después de un entrenamiento durante mucho tiempo.
No obtendrá texto generado de calidad el 100% de las veces , incluso con una red neuronal altamente entrenada. Esa es la razón principal por la que las publicaciones de blogs virales/twitts de Twitter que utilizan la generación de texto NN a menudo generan muchos textos y luego seleccionan/editan los mejores.
Los resultados variarán mucho entre conjuntos de datos . Debido a que la red neuronal previamente entrenada es relativamente pequeña, no puede almacenar tantos datos como los RNN que normalmente hacen alarde en las publicaciones de blogs. Para obtener mejores resultados, utilice un conjunto de datos con al menos entre 2000 y 5000 documentos. Si un conjunto de datos es más pequeño, necesitará entrenarlo por más tiempo estableciendo num_epochs más alto al llamar a un método de entrenamiento y/o entrenar un nuevo modelo desde cero. Incluso entonces, actualmente no existe una buena heurística para determinar un "buen" modelo.
No se requiere una GPU para volver a entrenar textgenrnn, pero llevará mucho más tiempo entrenar en una CPU. Si utiliza una GPU, le recomiendo aumentar el parámetro batch_size para una mejor utilización del hardware.
Documentación más formal
Una implementación basada en web que utiliza tensorflow.js (funciona especialmente bien debido al pequeño tamaño de la red)
Una forma de visualizar los resultados de la capa de atención para ver cómo "aprende" la red.
Un modo que permite utilizar la arquitectura del modelo para conversaciones de chatbot (puede publicarse como un proyecto independiente)
Más profundidad hacia el contexto (contexto posicional + permitir múltiples etiquetas de contexto)
Una red previamente entrenada más grande que puede acomodar secuencias de caracteres más largas y una comprensión más profunda del lenguaje, creando oraciones mejor generadas.
Activación jerárquica de softmax para modelos a nivel de palabra (una vez que Keras tenga un buen soporte para ello).
FP16 para entrenamiento súper rápido en Volta/TPU (una vez que Keras tenga un buen soporte para ello).
Max Woolf (@minimaxir)
Los proyectos de código abierto de Max cuentan con el respaldo de su Patreon. Si este proyecto le resultó útil, cualquier contribución monetaria a Patreon será apreciada y se le dará un buen uso creativo.
Andrej Karpathy por la propuesta original de char-rnn a través de la publicación del blog The Unreasonable Effectiveness of Recurrent Neural Networks.
Daniel Grijalva por aportar un modo interactivo.
MIT
Código de capa de atención utilizado de DeepMoji (con licencia MIT)


