cleanrl
v1.0.0 CleanRL Release ?
CleanRL es una biblioteca de aprendizaje por refuerzo profundo que proporciona implementación de un solo archivo de alta calidad con funciones fáciles de investigar. La implementación es limpia y simple, pero podemos escalarla para ejecutar miles de experimentos utilizando AWS Batch. Las características más destacadas de CleanRL son:
ppo_atari.py solo tiene 340 líneas de código pero contiene todos los detalles de implementación sobre cómo funciona PPO con los juegos de Atari, por lo que es una excelente implementación de referencia para aquellos que no desean leer una biblioteca modular completa .Puede leer más sobre CleanRL en nuestro documento y documentación JMLR.
Proyectos notables relacionados con CleanRL:
Soporte para Gymnasium : Farama-Foundation/Gymnasium es la próxima generación de
openai/gymque continuará manteniéndose e introduciendo nuevas características. Consulte su anuncio para obtener más detalles. Estamos migrando algymnasiumy se puede seguir el progreso en vwxyzjn/cleanrl#277.
️ NOTA : CleanRL no es una biblioteca modular y, por lo tanto, no debe importarse. A costa del código duplicado, hacemos que todos los detalles de implementación de una variante del algoritmo DRL sean fáciles de entender, por lo que CleanRL tiene sus ventajas y desventajas. Debería considerar el uso de CleanRL si desea 1) comprender todos los detalles de implementación de la variante de un algoritmo o 2) prototipos de funciones avanzadas que otras bibliotecas DRL modulares no admiten (CleanRL tiene líneas mínimas de código, por lo que le brinda una excelente experiencia de depuración y no No tengo que crear muchas subclases como a veces en las bibliotecas DRL modulares).
Requisitos previos:
Para ejecutar experimentos localmente, pruebe lo siguiente:
git clone https://github.com/vwxyzjn/cleanrl.git && cd cleanrl
poetry install
# alternatively, you could use `poetry shell` and do
# `python run cleanrl/ppo.py`
poetry run python cleanrl/ppo.py
--seed 1
--env-id CartPole-v0
--total-timesteps 50000
# open another terminal and enter `cd cleanrl/cleanrl`
tensorboard --logdir runsPara utilizar el seguimiento de experimentos con wandb, ejecute
wandb login # only required for the first time
poetry run python cleanrl/ppo.py
--seed 1
--env-id CartPole-v0
--total-timesteps 50000
--track
--wandb-project-name cleanrltest Si no estás usando poetry , puedes instalar CleanRL con requirements.txt :
# core dependencies
pip install -r requirements/requirements.txt
# optional dependencies
pip install -r requirements/requirements-atari.txt
pip install -r requirements/requirements-mujoco.txt
pip install -r requirements/requirements-mujoco_py.txt
pip install -r requirements/requirements-procgen.txt
pip install -r requirements/requirements-envpool.txt
pip install -r requirements/requirements-pettingzoo.txt
pip install -r requirements/requirements-jax.txt
pip install -r requirements/requirements-docs.txt
pip install -r requirements/requirements-cloud.txt
pip install -r requirements/requirements-memory_gym.txtPara ejecutar scripts de entrenamiento en otros juegos:
poetry shell
# classic control
python cleanrl/dqn.py --env-id CartPole-v1
python cleanrl/ppo.py --env-id CartPole-v1
python cleanrl/c51.py --env-id CartPole-v1
# atari
poetry install -E atari
python cleanrl/dqn_atari.py --env-id BreakoutNoFrameskip-v4
python cleanrl/c51_atari.py --env-id BreakoutNoFrameskip-v4
python cleanrl/ppo_atari.py --env-id BreakoutNoFrameskip-v4
python cleanrl/sac_atari.py --env-id BreakoutNoFrameskip-v4
# NEW: 3-4x side-effects free speed up with envpool's atari (only available to linux)
poetry install -E envpool
python cleanrl/ppo_atari_envpool.py --env-id BreakoutNoFrameskip-v4
# Learn Pong-v5 in ~5-10 mins
# Side effects such as lower sample efficiency might occur
poetry run python ppo_atari_envpool.py --clip-coef=0.2 --num-envs=16 --num-minibatches=8 --num-steps=128 --update-epochs=3
# procgen
poetry install -E procgen
python cleanrl/ppo_procgen.py --env-id starpilot
python cleanrl/ppg_procgen.py --env-id starpilot
# ppo + lstm
poetry install -E atari
python cleanrl/ppo_atari_lstm.py --env-id BreakoutNoFrameskip-v4
También puedes utilizar un entorno de desarrollo prediseñado alojado en Gitpod:
| Algoritmo | Variantes implementadas |
|---|---|
| ✅ Gradiente de política proximal (PPO) | ppo.py , documentos |
ppo_atari.py , documentos | |
ppo_continuous_action.py , documentos | |
ppo_atari_lstm.py , documentos | |
ppo_atari_envpool.py , documentos | |
ppo_atari_envpool_xla_jax.py , documentos | |
ppo_atari_envpool_xla_jax_scan.py , documentos) | |
ppo_procgen.py , documentos | |
ppo_atari_multigpu.py , documentos | |
ppo_pettingzoo_ma_atari.py , documentos | |
ppo_continuous_action_isaacgym.py , documentos | |
ppo_trxl.py , documentos | |
| ✅ Q-Learning profundo (DQN) | dqn.py , documentos |
dqn_atari.py , documentos | |
dqn_jax.py , documentos | |
dqn_atari_jax.py , documentos | |
| ✅ DQN categórico (C51) | c51.py , documentos |
c51_atari.py , documentos | |
c51_jax.py , documentos | |
c51_atari_jax.py , documentos | |
| ✅ Actor-crítico suave (SAC) | sac_continuous_action.py , documentos |
sac_atari.py , documentos | |
| ✅ Gradiente de política determinista profundo (DDPG) | ddpg_continuous_action.py , documentos |
ddpg_continuous_action_jax.py , documentos | |
| ✅ Doble gradiente de política determinista profundo retrasado (TD3) | td3_continuous_action.py , documentos |
td3_continuous_action_jax.py , documentos | |
| ✅ Gradiente de política fásica (PPG) | ppg_procgen.py , documentos |
| ✅ Destilación de red aleatoria (RND) | ppo_rnd_envpool.py , documentos |
| ✅ Qdaga | qdagger_dqn_atari_impalacnn.py , documentos |
qdagger_dqn_atari_jax_impalacnn.py , documentos |
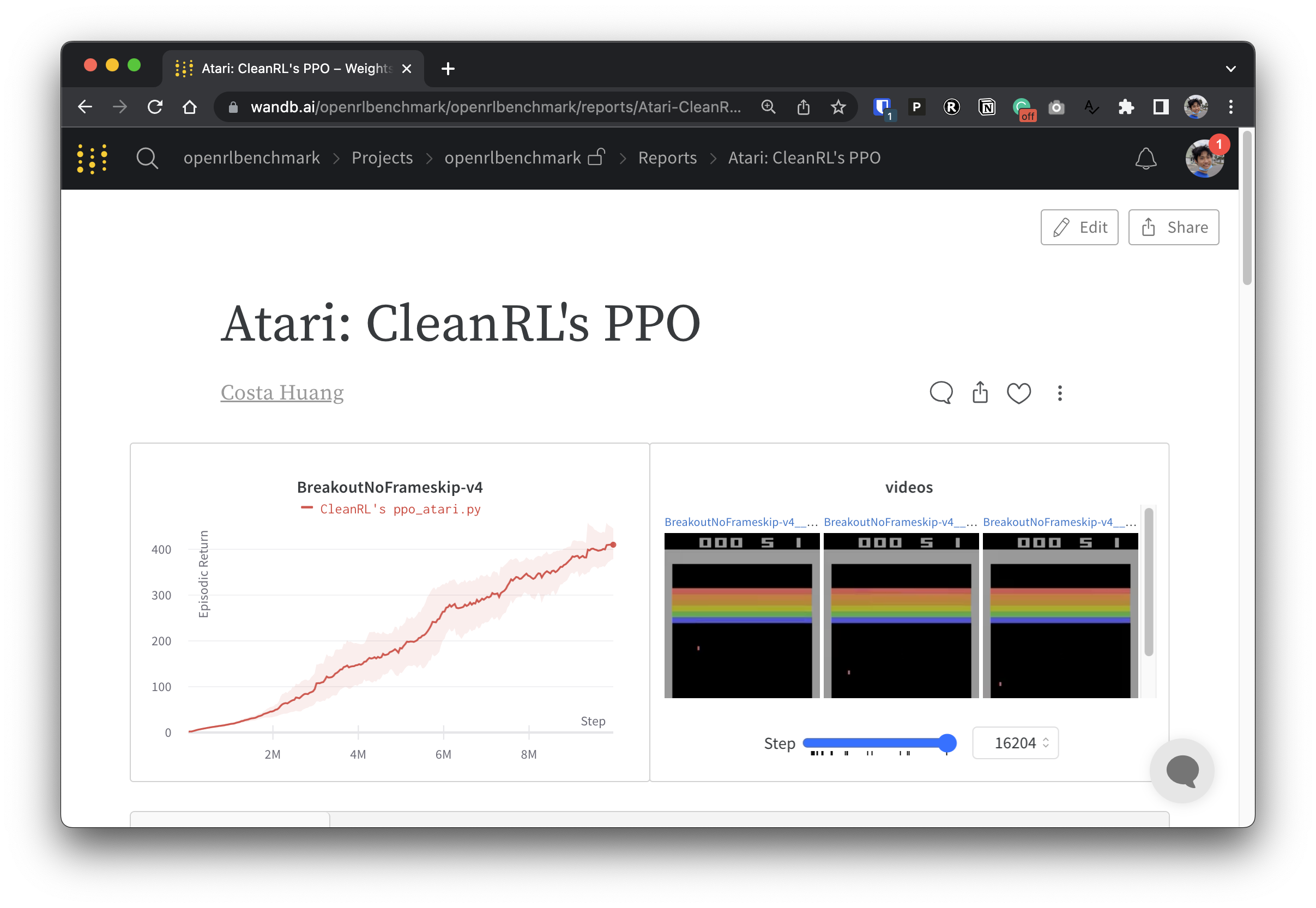
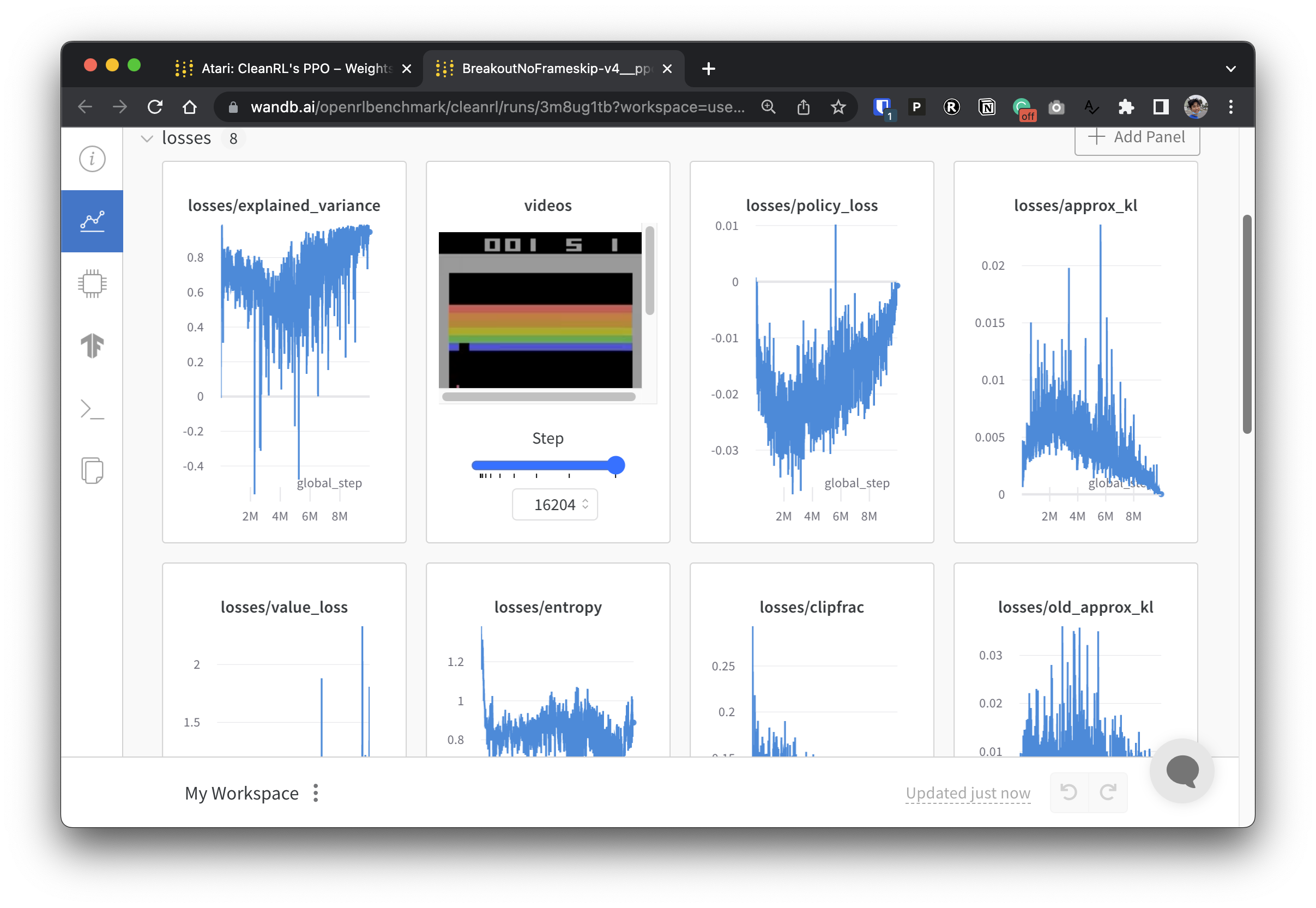
Para que nuestros datos experimentales sean transparentes, CleanRL participa en un proyecto relacionado llamado Open RL Benchmark, que contiene experimentos rastreados de bibliotecas DRL populares como la nuestra, Stable-baselines3, openai/baselines, jaxrl y otras.
Consulte https://benchmark.cleanrl.dev/ para obtener una colección de informes de ponderaciones y sesgos que muestran experimentos de DRL con seguimiento. Los informes son interactivos y los investigadores pueden consultar fácilmente información como la utilización de la GPU y videos del juego de un agente que normalmente son difíciles de adquirir en otros puntos de referencia de RL. En el futuro, Open RL Benchmark probablemente proporcionará una API de conjunto de datos para que los investigadores accedan fácilmente a los datos (ver repositorio).
Tenemos una comunidad de Discord para brindar apoyo. No dude en hacer preguntas. Publicar en Github Issues y PR también son bienvenidos. También nuestras grabaciones de vídeo anteriores están disponibles en YouTube.
Si utiliza CleanRL en su trabajo, cite nuestro documento técnico:
@article { huang2022cleanrl ,
author = { Shengyi Huang and Rousslan Fernand Julien Dossa and Chang Ye and Jeff Braga and Dipam Chakraborty and Kinal Mehta and João G.M. Araújo } ,
title = { CleanRL: High-quality Single-file Implementations of Deep Reinforcement Learning Algorithms } ,
journal = { Journal of Machine Learning Research } ,
year = { 2022 } ,
volume = { 23 } ,
number = { 274 } ,
pages = { 1--18 } ,
url = { http://jmlr.org/papers/v23/21-1342.html }
}CleanRL es un proyecto impulsado por la comunidad y nuestros contribuyentes realizan experimentos en una variedad de hardware.


