python cheatsheet
1.0.0
Descargue un archivo de texto, compre un PDF, bifurqueme en GitHub o consulte las preguntas frecuentes.

1. Colecciones: List , Dictionary , Set , Tuple , Range , Enumerate , Iterator , Generator .
2. Tipos: Type , String , Regular_Exp , Format , Numbers , Combinatorics , Datetime .
3. Sintaxis: Args , Inline , Import , Decorator , Class , Duck_Types , Enum , Exception .
4. Sistema: Exit , Print , Input , Command_Line_Arguments , Open , Path , OS_Commands .
5. Datos: JSON , Pickle , CSV , SQLite , Bytes , Struct , Array , Memory_View , Deque .
6. Avanzado: Operator , Match_Stmt , Logging , Introspection , Threading , Coroutines .
7. Bibliotecas: Progress_Bar , Plot , Table , Console_App , GUI , Scraping , Web , Profile .
8. Multimedia: NumPy , Image , Animation , Audio , Synthesizer , Pygame , Pandas , Plotly .
if __name__ == '__main__' : # Skips next line if file was imported.
main () # Runs `def main(): ...` function. < list > = [ < el_1 > , < el_2 > , ...] # Creates new list. Also list(<collection>). < el > = < list > [ index ] # First index is 0. Last -1. Allows assignments.
< list > = < list > [ < slice > ] # Also <list>[from_inclusive : to_exclusive : ±step]. < list > . append ( < el > ) # Appends element to the end. Also <list> += [<el>].
< list > . extend ( < collection > ) # Appends elements to the end. Also <list> += <coll>. < list > . sort () # Sorts elements in ascending order.
< list > . reverse () # Reverses the list in-place.
< list > = sorted ( < collection > ) # Returns new list with sorted elements.
< iter > = reversed ( < list > ) # Returns reversed iterator of elements. < el > = max ( < collection > ) # Returns largest element. Also min(<el_1>, ...).
< num > = sum ( < collection > ) # Returns sum of elements. Also math.prod(<coll>). elementwise_sum = [ sum ( pair ) for pair in zip ( list_a , list_b )]
sorted_by_second = sorted ( < collection > , key = lambda el : el [ 1 ])
sorted_by_both = sorted ( < collection > , key = lambda el : ( el [ 1 ], el [ 0 ]))
flatter_list = list ( itertools . chain . from_iterable ( < list > )) < int > = len ( < list > ) # Returns number of items. Also works on dict, set and string.
< int > = < list > . count ( < el > ) # Returns number of occurrences. Also `if <el> in <coll>: ...`.
< int > = < list > . index ( < el > ) # Returns index of the first occurrence or raises ValueError.
< el > = < list > . pop () # Removes and returns item from the end or at index if passed.
< list > . insert ( < int > , < el > ) # Inserts item at index and moves the rest to the right.
< list > . remove ( < el > ) # Removes first occurrence of the item or raises ValueError.
< list > . clear () # Removes all items. Also works on dictionary and set. < dict > = { key_1 : val_1 , key_2 : val_2 , ...} # Use `<dict>[key]` to get or set the value. < view > = < dict > . keys () # Collection of keys that reflects changes.
< view > = < dict > . values () # Collection of values that reflects changes.
< view > = < dict > . items () # Coll. of key-value tuples that reflects chgs. value = < dict > . get ( key , default = None ) # Returns default if key is missing.
value = < dict > . setdefault ( key , default = None ) # Returns and writes default if key is missing.
< dict > = collections . defaultdict ( < type > ) # Returns a dict with default value `<type>()`.
< dict > = collections . defaultdict ( lambda : 1 ) # Returns a dict with default value 1. < dict > = dict ( < collection > ) # Creates a dict from coll. of key-value pairs.
< dict > = dict ( zip ( keys , values )) # Creates a dict from two collections.
< dict > = dict . fromkeys ( keys [, value ]) # Creates a dict from collection of keys. < dict > . update ( < dict > ) # Adds items. Replaces ones with matching keys.
value = < dict > . pop ( key ) # Removes item or raises KeyError if missing.
{ k for k , v in < dict > . items () if v == value } # Returns set of keys that point to the value.
{ k : v for k , v in < dict > . items () if k in keys } # Filters the dictionary by keys. > >> from collections import Counter
> >> counter = Counter ([ 'blue' , 'blue' , 'blue' , 'red' , 'red' ])
> >> counter [ 'yellow' ] += 1
> >> print ( counter . most_common ())
[( 'blue' , 3 ), ( 'red' , 2 ), ( 'yellow' , 1 )] < set > = { < el_1 > , < el_2 > , ...} # Use `set()` for empty set. < set > . add ( < el > ) # Or: <set> |= {<el>}
< set > . update ( < collection > [, ...]) # Or: <set> |= <set> < set > = < set > . union ( < coll . > ) # Or: <set> | <set>
< set > = < set > . intersection ( < coll . > ) # Or: <set> & <set>
< set > = < set > . difference ( < coll . > ) # Or: <set> - <set>
< set > = < set > . symmetric_difference ( < coll . > ) # Or: <set> ^ <set>
< bool > = < set > . issubset ( < coll . > ) # Or: <set> <= <set>
< bool > = < set > . issuperset ( < coll . > ) # Or: <set> >= <set> < el > = < set > . pop () # Raises KeyError if empty.
< set > . remove ( < el > ) # Raises KeyError if missing.
< set > . discard ( < el > ) # Doesn't raise an error. < frozenset > = frozenset ( < collection > )Tuple es una lista inmutable y hashable.
< tuple > = () # Empty tuple.
< tuple > = ( < el > ,) # Or: <el>,
< tuple > = ( < el_1 > , < el_2 > [, ...]) # Or: <el_1>, <el_2> [, ...]Subclase de tupla con elementos con nombre.
> >> from collections import namedtuple
> >> Point = namedtuple ( 'Point' , 'x y' )
> >> p = Point ( 1 , y = 2 ); p
Point ( x = 1 , y = 2 )
> >> p [ 0 ]
1
> >> p . x
1
> >> getattr ( p , 'y' )
2 Secuencia de números enteros inmutable y hashable.
< range > = range ( stop ) # range(to_exclusive)
< range > = range ( start , stop ) # range(from_inclusive, to_exclusive)
< range > = range ( start , stop , ± step ) # range(from_inclusive, to_exclusive, ±step_size) > >> [ i for i in range ( 3 )]
[ 0 , 1 , 2 ] for i , el in enumerate ( < coll > , start = 0 ): # Returns next element and its index on each pass.
... < iter > = iter ( < collection > ) # `iter(<iter>)` returns unmodified iterator.
< iter > = iter ( < function > , to_exclusive ) # A sequence of return values until 'to_exclusive'.
< el > = next ( < iter > [, default ]) # Raises StopIteration or returns 'default' on end.
< list > = list ( < iter > ) # Returns a list of iterator's remaining elements. import itertools as it < iter > = it . count ( start = 0 , step = 1 ) # Returns updated value endlessly. Accepts floats.
< iter > = it . repeat ( < el > [, times ]) # Returns element endlessly or 'times' times.
< iter > = it . cycle ( < collection > ) # Repeats the sequence endlessly. < iter > = it . chain ( < coll > , < coll > [, ...]) # Empties collections in order (figuratively).
< iter > = it . chain . from_iterable ( < coll > ) # Empties collections inside a collection in order. < iter > = it . islice ( < coll > , to_exclusive ) # Only returns first 'to_exclusive' elements.
< iter > = it . islice ( < coll > , from_inc , …) # `to_exclusive, +step_size`. Indices can be None. def count ( start , step ):
while True :
yield start
start += step > >> counter = count ( 10 , 2 )
> >> next ( counter ), next ( counter ), next ( counter )
( 10 , 12 , 14 ) < type > = type ( < el > ) # Or: <el>.__class__
< bool > = isinstance ( < el > , < type > ) # Or: issubclass(type(<el>), <type>) > >> type ( 'a' ), 'a' . __class__ , str
( < class 'str' > , < class 'str' > , < class 'str' > ) from types import FunctionType , MethodType , LambdaType , GeneratorType , ModuleTypeCada clase base abstracta especifica un conjunto de subclases virtuales. Estas clases son luego reconocidas por isinstance() e issubclass() como subclases del ABC, aunque en realidad no lo son. ABC también puede decidir manualmente si una clase específica es o no su subclase virtual, generalmente en función de los métodos que ha implementado la clase. Por ejemplo, Iterable ABC busca el método iter(), mientras que Collection ABC busca iter(), contains() y len().
> >> from collections . abc import Iterable , Collection , Sequence
> >> isinstance ([ 1 , 2 , 3 ], Iterable )
True +------------------+------------+------------+------------+
| | Iterable | Collection | Sequence |
+------------------+------------+------------+------------+
| list, range, str | yes | yes | yes |
| dict, set | yes | yes | |
| iter | yes | | |
+------------------+------------+------------+------------+
> >> from numbers import Number , Complex , Real , Rational , Integral
> >> isinstance ( 123 , Number )
True +--------------------+----------+----------+----------+----------+----------+
| | Number | Complex | Real | Rational | Integral |
+--------------------+----------+----------+----------+----------+----------+
| int | yes | yes | yes | yes | yes |
| fractions.Fraction | yes | yes | yes | yes | |
| float | yes | yes | yes | | |
| complex | yes | yes | | | |
| decimal.Decimal | yes | | | | |
+--------------------+----------+----------+----------+----------+----------+
Secuencia inmutable de caracteres.
< str > = < str > . strip () # Strips all whitespace characters from both ends.
< str > = < str > . strip ( '<chars>' ) # Strips passed characters. Also lstrip/rstrip(). < list > = < str > . split () # Splits on one or more whitespace characters.
< list > = < str > . split ( sep = None , maxsplit = - 1 ) # Splits on 'sep' str at most 'maxsplit' times.
< list > = < str > . splitlines ( keepends = False ) # On [nrfvx1c-x1ex85u2028u2029] and rn.
< str > = < str > . join ( < coll_of_strings > ) # Joins elements using string as a separator. < bool > = < sub_str > in < str > # Checks if string contains the substring.
< bool > = < str > . startswith ( < sub_str > ) # Pass tuple of strings for multiple options.
< int > = < str > . find ( < sub_str > ) # Returns start index of the first match or -1.
< int > = < str > . index ( < sub_str > ) # Same, but raises ValueError if there's no match. < str > = < str > . lower () # Changes the case. Also upper/capitalize/title().
< str > = < str > . replace ( old , new [, count ]) # Replaces 'old' with 'new' at most 'count' times.
< str > = < str > . translate ( < table > ) # Use `str.maketrans(<dict>)` to generate table. < str > = chr ( < int > ) # Converts int to Unicode character.
< int > = ord ( < str > ) # Converts Unicode character to int.'unicodedata.normalize("NFC", <str>)' en cadenas como 'Motörhead' antes de compararlas con otras cadenas, porque 'ö' se puede almacenar como uno o dos caracteres.'NFC' convierte dichos caracteres en un solo carácter, mientras que 'NFD' los convierte en dos. < bool > = < str > . isdecimal () # Checks for [0-9]. Also [०-९] and [٠-٩].
< bool > = < str > . isdigit () # Checks for [²³¹…] and isdecimal().
< bool > = < str > . isnumeric () # Checks for [¼½¾…], [零〇一…] and isdigit().
< bool > = < str > . isalnum () # Checks for [a-zA-Z…] and isnumeric().
< bool > = < str > . isprintable () # Checks for [ !#$%…] and isalnum().
< bool > = < str > . isspace () # Checks for [ tnrfvx1c-x1fx85xa0…]. Funciones para la coincidencia de expresiones regulares.
import re
< str > = re . sub ( r'<regex>' , new , text , count = 0 ) # Substitutes all occurrences with 'new'.
< list > = re . findall ( r'<regex>' , text ) # Returns all occurrences as strings.
< list > = re . split ( r'<regex>' , text , maxsplit = 0 ) # Add brackets around regex to keep matches.
< Match > = re . search ( r'<regex>' , text ) # First occurrence of the pattern or None.
< Match > = re . match ( r'<regex>' , text ) # Searches only at the beginning of the text.
< iter > = re . finditer ( r'<regex>' , text ) # Returns all occurrences as Match objects.'flags=re.IGNORECASE' se puede utilizar con todas las funciones.'flags=re.MULTILINE' hace que '^' y '$' coincidan con el inicio/final de cada línea.'flags=re.DOTALL' hace '.' también acepte el 'n' .'re.compile(<regex>)' devuelve un objeto Pattern con métodos sub(), findall(),… < str > = < Match > . group () # Returns the whole match. Also group(0).
< str > = < Match > . group ( 1 ) # Returns part inside the first brackets.
< tuple > = < Match > . groups () # Returns all bracketed parts.
< int > = < Match > . start () # Returns start index of the match.
< int > = < Match > . end () # Returns exclusive end index of the match. 'd' == '[0-9]' # Also [०-९…]. Matches a decimal character.
'w' == '[a-zA-Z0-9_]' # Also [ª²³…]. Matches an alphanumeric or _.
's' == '[ t n r f v ]' # Also [x1c-x1f…]. Matches a whitespace.'flags=re.ASCII' . Restringe las coincidencias de secuencias especiales a los primeros 128 caracteres Unicode y también evita que 's' acepte 'x1c' , 'x1d' , 'x1e' y 'x1f' (caracteres no imprimibles que dividen el texto en archivos, tablas, filas y campos, respectivamente).<str> = f ' {<el_1>}, {<el_2>} ' # Curly brackets can also contain expressions.
<str> = ' {}, {} ' .format(<el_1>, <el_2>) # Or: '{0}, {a}'.format(<el_1>, a=<el_2>)
<str> = ' %s, %s ' % (<el_1>, <el_2>) # Redundant and inferior C-style formatting. > >> Person = collections . namedtuple ( 'Person' , 'name height' )
> >> person = Person ( 'Jean-Luc' , 187 )
> >> f' { person . name } is { person . height / 100 } meters tall.'
'Jean-Luc is 1.87 meters tall.'{ < el > : < 10 } # '<el> '
{ < el > : ^ 10 } # ' <el> '
{ < el > : > 10 } # ' <el>'
{ < el > :. < 10 } # '<el>......'
{ < el > : 0 } # '<el>''format(<el>, "<options>")' .f'{<el>:{<str/int>}[…]}' .'=' a la expresión lo antepone a la salida: f'{1+1=}' devuelve '1+1=2' .'!r' a la expresión convierte el objeto en una cadena llamando a su método repr().{ 'abcde' : 10 } # 'abcde '
{ 'abcde' : 10.3 } # 'abc '
{ 'abcde' : .3 } # 'abc'
{ 'abcde' !r: 10 } # "'abcde' "{ 123456 : 10 } # ' 123456'
{ 123456 : 10 ,} # ' 123,456'
{ 123456 : 10_ } # ' 123_456'
{ 123456 : + 10 } # ' +123456'
{ 123456 : = + 10 } # '+ 123456'
{ 123456 : } # ' 123456'
{ - 123456 : } # '-123456'{ 1.23456 : 10.3 } # ' 1.23'
{ 1.23456 : 10.3 f } # ' 1.235'
{ 1.23456 : 10.3 e } # ' 1.235e+00'
{ 1.23456 : 10.3 % } # ' 123.456%' +--------------+----------------+----------------+----------------+----------------+
| | {<float>} | {<float>:f} | {<float>:e} | {<float>:%} |
+--------------+----------------+----------------+----------------+----------------+
| 0.000056789 | '5.6789e-05' | '0.000057' | '5.678900e-05' | '0.005679%' |
| 0.00056789 | '0.00056789' | '0.000568' | '5.678900e-04' | '0.056789%' |
| 0.0056789 | '0.0056789' | '0.005679' | '5.678900e-03' | '0.567890%' |
| 0.056789 | '0.056789' | '0.056789' | '5.678900e-02' | '5.678900%' |
| 0.56789 | '0.56789' | '0.567890' | '5.678900e-01' | '56.789000%' |
| 5.6789 | '5.6789' | '5.678900' | '5.678900e+00' | '567.890000%' |
| 56.789 | '56.789' | '56.789000' | '5.678900e+01' | '5678.900000%' |
+--------------+----------------+----------------+----------------+----------------+
+--------------+----------------+----------------+----------------+----------------+
| | {<float>:.2} | {<float>:.2f} | {<float>:.2e} | {<float>:.2%} |
+--------------+----------------+----------------+----------------+----------------+
| 0.000056789 | '5.7e-05' | '0.00' | '5.68e-05' | '0.01%' |
| 0.00056789 | '0.00057' | '0.00' | '5.68e-04' | '0.06%' |
| 0.0056789 | '0.0057' | '0.01' | '5.68e-03' | '0.57%' |
| 0.056789 | '0.057' | '0.06' | '5.68e-02' | '5.68%' |
| 0.56789 | '0.57' | '0.57' | '5.68e-01' | '56.79%' |
| 5.6789 | '5.7' | '5.68' | '5.68e+00' | '567.89%' |
| 56.789 | '5.7e+01' | '56.79' | '5.68e+01' | '5678.90%' |
+--------------+----------------+----------------+----------------+----------------+
'{<float>:g}' es '{<float>:.6}' con ceros eliminados, exponente que comienza en '1e+06' .'{6.5:.0f}' sea un '6' y '{7.5:.0f}' un '8' ..5 , .25 ,…).{ 90 : c } # 'Z'. Unicode character with value 90.
{ 90 : b } # '1011010'. Number 90 in binary.
{ 90 : X } # '5A'. Number 90 in uppercase hexadecimal. < int > = int ( < float / str / bool > ) # Or: math.trunc(<float>)
< float > = float ( < int / str / bool > ) # Or: <int/float>e±<int>
< complex > = complex ( real = 0 , imag = 0 ) # Or: <int/float> ± <int/float>j
< Fraction > = fractions . Fraction ( 0 , 1 ) # Or: Fraction(numerator=0, denominator=1)
< Decimal > = decimal . Decimal ( < str / int > ) # Or: Decimal((sign, digits, exponent))'int(<str>)' y 'float(<str>)' generan ValueError en cadenas con formato incorrecto.'1.1 + 2.2 != 3.3' .'math.isclose(<float>, <float>)' .'decimal.getcontext().prec = <int>' . < num > = pow ( < num > , < num > ) # Or: <number> ** <number>
< num > = abs ( < num > ) # <float> = abs(<complex>)
< num > = round ( < num > [, ± ndigits ]) # `round(126, -1) == 130` from math import e , pi , inf , nan , isinf , isnan # `<el> == nan` is always False.
from math import sin , cos , tan , asin , acos , atan # Also: degrees, radians.
from math import log , log10 , log2 # Log can accept base as second arg. from statistics import mean , median , variance # Also: stdev, quantiles, groupby. from random import random , randint , choice # Also: shuffle, gauss, triangular, seed.
< float > = random () # A float inside [0, 1).
< int > = randint ( from_inc , to_inc ) # An int inside [from_inc, to_inc].
< el > = choice ( < sequence > ) # Keeps the sequence intact. < int > = ± 0 b < bin > # Or: ±0x<hex>
< int > = int ( '±<bin>' , 2 ) # Or: int('±<hex>', 16)
< int > = int ( '±0b<bin>' , 0 ) # Or: int('±0x<hex>', 0)
< str > = bin ( < int > ) # Returns '[-]0b<bin>'. Also hex(). < int > = < int > & < int > # And (0b1100 & 0b1010 == 0b1000).
< int > = < int > | < int > # Or (0b1100 | 0b1010 == 0b1110).
< int > = < int > ^ < int > # Xor (0b1100 ^ 0b1010 == 0b0110).
< int > = < int > < < n_bits # Left shift. Use >> for right.
< int > = ~ < int > # Not. Also -<int> - 1. import itertools as it > >> list ( it . product ([ 0 , 1 ], repeat = 3 ))
[( 0 , 0 , 0 ), ( 0 , 0 , 1 ), ( 0 , 1 , 0 ), ( 0 , 1 , 1 ),
( 1 , 0 , 0 ), ( 1 , 0 , 1 ), ( 1 , 1 , 0 ), ( 1 , 1 , 1 )] > >> list ( it . product ( 'abc' , 'abc' )) # a b c
[( 'a' , 'a' ), ( 'a' , 'b' ), ( 'a' , 'c' ), # a x x x
( 'b' , 'a' ), ( 'b' , 'b' ), ( 'b' , 'c' ), # b x x x
( 'c' , 'a' ), ( 'c' , 'b' ), ( 'c' , 'c' )] # c x x x > >> list ( it . combinations ( 'abc' , 2 )) # a b c
[( 'a' , 'b' ), ( 'a' , 'c' ), # a . x x
( 'b' , 'c' )] # b . . x > >> list ( it . combinations_with_replacement ( 'abc' , 2 )) # a b c
[( 'a' , 'a' ), ( 'a' , 'b' ), ( 'a' , 'c' ), # a x x x
( 'b' , 'b' ), ( 'b' , 'c' ), # b . x x
( 'c' , 'c' )] # c . . x > >> list ( it . permutations ( 'abc' , 2 )) # a b c
[( 'a' , 'b' ), ( 'a' , 'c' ), # a . x x
( 'b' , 'a' ), ( 'b' , 'c' ), # b x . x
( 'c' , 'a' ), ( 'c' , 'b' )] # c x x . Proporciona clases 'fecha', 'hora', 'fechahora' y 'timedelta'. Todos son inmutables y hash.
# $ pip3 install python-dateutil
from datetime import date , time , datetime , timedelta , timezone
import zoneinfo , dateutil . tz < D > = date ( year , month , day ) # Only accepts valid dates from 1 to 9999 AD.
< T > = time ( hour = 0 , minute = 0 , second = 0 ) # Also: `microsecond=0, tzinfo=None, fold=0`.
< DT > = datetime ( year , month , day , hour = 0 ) # Also: `minute=0, second=0, microsecond=0, …`.
< TD > = timedelta ( weeks = 0 , days = 0 , hours = 0 ) # Also: `minutes=0, seconds=0, microseconds=0`.'fold=1' significa el segundo pase en caso de que el tiempo retroceda una hora.'[±D, ]H:MM:SS[.…]' y total_segundos() un valor flotante de todos los segundos.'<D/DT>.weekday()' para obtener el día de la semana como un int, siendo el lunes 0. < D / DTn > = D / DT . today () # Current local date or naive DT. Also DT.now().
< DTa > = DT . now ( < tzinfo > ) # Aware DT from current time in passed timezone.'<DTn>.time()' , '<DTa>.time()' o '<DTa>.timetz()' . < tzinfo > = timezone . utc # London without daylight saving time (DST).
< tzinfo > = timezone ( < timedelta > ) # Timezone with fixed offset from UTC.
< tzinfo > = dateutil . tz . tzlocal () # Local timezone with dynamic offset from UTC.
< tzinfo > = zoneinfo . ZoneInfo ( '<iana_key>' ) # 'Continent/City_Name' zone with dynamic offset.
< DTa > = < DT > . astimezone ([ < tzinfo > ]) # Converts DT to the passed or local fixed zone.
< Ta / DTa > = < T / DT > . replace ( tzinfo = < tzinfo > ) # Changes object's timezone without conversion.'> pip3 install tzdata' . < D / T / DT > = D / T / DT . fromisoformat ( < str > ) # Object from ISO string. Raises ValueError.
< DT > = DT . strptime ( < str > , '<format>' ) # Datetime from str, according to format.
< D / DTn > = D / DT . fromordinal ( < int > ) # D/DT from days since the Gregorian NYE 1.
< DTn > = DT . fromtimestamp ( < float > ) # Local naive DT from seconds since the Epoch.
< DTa > = DT . fromtimestamp ( < float > , < tz > ) # Aware datetime from seconds since the Epoch.'YYYY-MM-DD' , 'HH:MM:SS.mmmuuu[±HH:MM]' , o ambas separadas por un carácter arbitrario. Todas las piezas siguientes al horario son opcionales.'1970-01-01 00:00 UTC' , '1970-01-01 01:00 CET' , ... < str > = < D / T / DT > . isoformat ( sep = 'T' ) # Also `timespec='auto/hours/minutes/seconds/…'`.
< str > = < D / T / DT > . strftime ( '<format>' ) # Custom string representation of the object.
< int > = < D / DT > . toordinal () # Days since Gregorian NYE 1, ignoring time and tz.
< float > = < DTn > . timestamp () # Seconds since the Epoch, from local naive DT.
< float > = < DTa > . timestamp () # Seconds since the Epoch, from aware datetime. > >> dt = datetime . strptime ( '2025-08-14 23:39:00.00 +0200' , '%Y-%m-%d %H:%M:%S.%f %z' )
> >> dt . strftime ( "%dth of %B '%y (%a), %I:%M %p %Z" )
"14th of August '25 (Thu), 11:39 PM UTC+02:00"'%z' acepta '±HH[:]MM' y devuelve '±HHMM' o una cadena vacía si la fecha y hora es ingenua.'%Z' acepta 'UTC/GMT' y el código de la zona horaria local y devuelve el nombre de la zona horaria, 'UTC[±HH:MM]' si la zona horaria no tiene nombre, o una cadena vacía si la fecha y hora es ingenua. < bool > = < D / T / DTn > > < D / T / DTn > # Ignores time jumps (fold attribute). Also ==.
< bool > = < DTa > > < DTa > # Ignores jumps if they share tz object. Broken ==.
< TD > = < D / DTn > - < D / DTn > # Ignores jumps. Convert to UTC for actual delta.
< TD > = < DTa > - < DTa > # Ignores jumps if they share tzinfo object.
< D / DT > = < D / DT > ± < TD > # Returned datetime can fall into missing hour.
< TD > = < TD > * < float > # Also: <TD> = abs(<TD>) and <TD> = <TD> ±% <TD>.
< float > = < TD > / < TD > # E.g. how many hours are in TD. Also //, divmod(). func ( < positional_args > ) # func(0, 0)
func ( < keyword_args > ) # func(x=0, y=0)
func ( < positional_args > , < keyword_args > ) # func(0, y=0) def func ( < nondefault_args > ): ... # def func(x, y): ...
def func ( < default_args > ): ... # def func(x=0, y=0): ...
def func ( < nondefault_args > , < default_args > ): ... # def func(x, y=0): ...Splat expande una colección en argumentos posicionales, mientras que splatty-splat expande un diccionario en argumentos de palabras clave.
args = ( 1 , 2 )
kwargs = { 'x' : 3 , 'y' : 4 , 'z' : 5 }
func ( * args , ** kwargs ) func ( 1 , 2 , x = 3 , y = 4 , z = 5 )Splat combina cero o más argumentos posicionales en una tupla, mientras que splatty-splat combina cero o más argumentos de palabras clave en un diccionario.
def add ( * a ):
return sum ( a ) > >> add ( 1 , 2 , 3 )
6 def f ( * args ): ... # f(1, 2, 3)
def f ( x , * args ): ... # f(1, 2, 3)
def f ( * args , z ): ... # f(1, 2, z=3) def f ( ** kwargs ): ... # f(x=1, y=2, z=3)
def f ( x , ** kwargs ): ... # f(x=1, y=2, z=3) | f(1, y=2, z=3) def f ( * args , ** kwargs ): ... # f(x=1, y=2, z=3) | f(1, y=2, z=3) | f(1, 2, z=3) | f(1, 2, 3)
def f ( x , * args , ** kwargs ): ... # f(x=1, y=2, z=3) | f(1, y=2, z=3) | f(1, 2, z=3) | f(1, 2, 3)
def f ( * args , y , ** kwargs ): ... # f(x=1, y=2, z=3) | f(1, y=2, z=3) def f ( * , x , y , z ): ... # f(x=1, y=2, z=3)
def f ( x , * , y , z ): ... # f(x=1, y=2, z=3) | f(1, y=2, z=3)
def f ( x , y , * , z ): ... # f(x=1, y=2, z=3) | f(1, y=2, z=3) | f(1, 2, z=3) < list > = [ * < coll . > [, ...]] # Or: list(<collection>) [+ ...]
< tuple > = ( * < coll . > , [...]) # Or: tuple(<collection>) [+ ...]
< set > = { * < coll . > [, ...]} # Or: set(<collection>) [| ...]
< dict > = { ** < dict > [, ...]} # Or: <dict> | ... head , * body , tail = < coll . > # Head or tail can be omitted. < func > = lambda : < return_value > # A single statement function.
< func > = lambda < arg_1 > , < arg_2 > : < return_value > # Also allows default arguments. < list > = [ i + 1 for i in range ( 10 )] # Or: [1, 2, ..., 10]
< iter > = ( i for i in range ( 10 ) if i > 5 ) # Or: iter([6, 7, 8, 9])
< set > = { i + 5 for i in range ( 10 )} # Or: {5, 6, ..., 14}
< dict > = { i : i * 2 for i in range ( 10 )} # Or: {0: 0, 1: 2, ..., 9: 18} > >> [ l + r for l in 'abc' for r in 'abc' ] # Inner loop is on the right side.
[ 'aa' , 'ab' , 'ac' , ..., 'cc' ] from functools import reduce < iter > = map ( lambda x : x + 1 , range ( 10 )) # Or: iter([1, 2, ..., 10])
< iter > = filter ( lambda x : x > 5 , range ( 10 )) # Or: iter([6, 7, 8, 9])
< obj > = reduce ( lambda out , x : out + x , range ( 10 )) # Or: 45 < bool > = any ( < collection > ) # Is `bool(<el>)` True for any el?
< bool > = all ( < collection > ) # True for all? Also True if empty. < obj > = < exp > if < condition > else < exp > # Only one expression is evaluated. > >> [ a if a else 'zero' for a in ( 0 , 1 , 2 , 3 )] # `any([0, '', [], None]) == False`
[ 'zero' , 1 , 2 , 3 ] from collections import namedtuple
Point = namedtuple ( 'Point' , 'x y' ) # Creates a tuple's subclass.
point = Point ( 0 , 0 ) # Returns its instance. from enum import Enum
Direction = Enum ( 'Direction' , 'N E S W' ) # Creates an enum.
direction = Direction . N # Returns its member. from dataclasses import make_dataclass
Player = make_dataclass ( 'Player' , [ 'loc' , 'dir' ]) # Creates a class.
player = Player ( point , direction ) # Returns its instance. Mecanismo que hace que el código de un archivo esté disponible para otro archivo.
import < module > # Imports a built-in or '<module>.py'.
import < package > # Imports a built-in or '<package>/__init__.py'.
import < package > . < module > # Imports a built-in or '<package>/<module>.py'.'import <package>' no proporciona automáticamente acceso a los módulos del paquete a menos que se importen explícitamente en su script de inicio.'from .[…][<pkg/module>[.…]] import <obj>' . Tenemos/obtenemos un cierre en Python cuando una función anidada hace referencia a un valor de su función adjunta y luego la función adjunta devuelve la función anidada.
def get_multiplier ( a ):
def out ( b ):
return a * b
return out > >> multiply_by_3 = get_multiplier ( 3 )
> >> multiply_by_3 ( 10 )
30 from functools import partial
< function > = partial ( < function > [, < arg_1 > [, ...]]) > >> def multiply ( a , b ):
... return a * b
> >> multiply_by_3 = partial ( multiply , 3 )
> >> multiply_by_3 ( 10 )
30'defaultdict(<func>)' , 'iter(<func>, to_exc)' y 'field(default_factory=<func>)' de dataclass.Si la variable se asigna a cualquier parte del alcance, se considera una variable local, a menos que se declare como "global" o "no local".
def get_counter ():
i = 0
def out ():
nonlocal i
i += 1
return i
return out > >> counter = get_counter ()
> >> counter (), counter (), counter ()
( 1 , 2 , 3 ) @ decorator_name
def function_that_gets_passed_to_decorator ():
...Decorador que imprime el nombre de la función cada vez que se llama a la función.
from functools import wraps
def debug ( func ):
@ wraps ( func )
def out ( * args , ** kwargs ):
print ( func . __name__ )
return func ( * args , ** kwargs )
return out
@ debug
def add ( x , y ):
return x + y'add.__name__' devolvería 'out' .Decorador que almacena en caché los valores de retorno de la función. Todos los argumentos de la función deben ser hash.
from functools import cache
@ cache
def fib ( n ):
return n if n < 2 else fib ( n - 2 ) + fib ( n - 1 )'fib.cache_clear()' o utilice el decorador '@lru_cache(maxsize=<int>)' en su lugar.'sys.setrecursionlimit(<int>)' .Un decorador que acepta argumentos y devuelve un decorador normal que acepta una función.
from functools import wraps
def debug ( print_result = False ):
def decorator ( func ):
@ wraps ( func )
def out ( * args , ** kwargs ):
result = func ( * args , ** kwargs )
print ( func . __name__ , result if print_result else '' )
return result
return out
return decorator
@ debug ( print_result = True )
def add ( x , y ):
return x + y'@debug' para decorar la función add() no funcionaría aquí, porque la depuración recibiría la función add() como un argumento 'print_result'. Sin embargo, los decoradores pueden comprobar manualmente si el argumento que recibieron es una función y actuar en consecuencia. Una plantilla para crear objetos definidos por el usuario.
class MyClass :
def __init__ ( self , a ):
self . a = a
def __str__ ( self ):
return str ( self . a )
def __repr__ ( self ):
class_name = self . __class__ . __name__
return f' { class_name } ( { self . a !r } )'
@ classmethod
def get_class_name ( cls ):
return cls . __name__ > >> obj = MyClass ( 1 )
> >> obj . a , str ( obj ), repr ( obj )
( 1 , '1' , 'MyClass(1)' )'@staticmethod' no reciben 'self' ni 'cls' como primer argumento. print ( < obj > )
f' { < obj > } '
logging . warning ( < obj > )
csv . writer ( < file > ). writerow ([ < obj > ])
raise Exception ( < obj > ) print / str / repr ([ < obj > ])
print / str / repr ({ < obj > : < obj > })
f' { < obj > !r } '
Z = dataclasses . make_dataclass ( 'Z' , [ 'a' ]); print / str / repr ( Z ( < obj > ))
> >> < obj > class Person :
def __init__ ( self , name ):
self . name = name
class Employee ( Person ):
def __init__ ( self , name , staff_num ):
super (). __init__ ( name )
self . staff_num = staff_num class A : pass
class B : pass
class C ( A , B ): passMRO determina el orden en el que se atraviesan las clases principales cuando se busca un método o atributo:
> >> C . mro ()
[ < class 'C' > , < class 'A' > , < class 'B' > , < class 'object' > ]'def f() -> <type>:' ). from collections import abc
< name > : < type > [ | ...] [ = < obj > ] # `|` since 3.10.
< name > : list / set / abc . Iterable / abc . Sequence [ < type > ] [ = < obj > ] # Since 3.9.
< name > : dict / tuple [ < type > , ...] [ = < obj > ] # Since 3.9.Decorador que utiliza variables de clase para generar métodos especiales init(), repr() y eq().
from dataclasses import dataclass , field , make_dataclass
@ dataclass ( order = False , frozen = False )
class < class_name > :
< attr_name > : < type >
< attr_name > : < type > = < default_value >
< attr_name > : list / dict / set = field ( default_factory = list / dict / set )'order=True' e inmutables con 'frozen=True' .'<attr_name>: list = []' crearía una lista que se comparte entre todas las instancias. Su argumento 'default_factory' puede ser invocable.'typing.Any' . Point = make_dataclass ( 'Point' , [ 'x' , 'y' ])
Point = make_dataclass ( 'Point' , [( 'x' , float ), ( 'y' , float )])
Point = make_dataclass ( 'Point' , [( 'x' , float , 0 ), ( 'y' , float , 0 )])Forma pitónica de implementar captadores y definidores.
class Person :
@ property
def name ( self ):
return ' ' . join ( self . _name )
@ name . setter
def name ( self , value ):
self . _name = value . split () > >> person = Person ()
> >> person . name = ' t Guido van Rossum n '
> >> person . name
'Guido van Rossum'El mecanismo que restringe los objetos a los atributos enumerados en 'ranuras' reduce su huella de memoria.
class MyClassWithSlots :
__slots__ = [ 'a' ]
def __init__ ( self ):
self . a = 1 from copy import copy , deepcopy
< object > = copy / deepcopy ( < object > )Un tipo pato es un tipo implícito que prescribe un conjunto de métodos especiales. Cualquier objeto que tenga esos métodos definidos se considera miembro de ese tipo de pato.
'id(self) == id(other)' , que es lo mismo que 'self is other' . class MyComparable :
def __init__ ( self , a ):
self . a = a
def __eq__ ( self , other ):
if isinstance ( other , type ( self )):
return self . a == other . a
return NotImplemented'id(self)' no funcionará. class MyHashable :
def __init__ ( self , a ):
self . _a = a
@ property
def a ( self ):
return self . _a
def __eq__ ( self , other ):
if isinstance ( other , type ( self )):
return self . a == other . a
return NotImplemented
def __hash__ ( self ):
return hash ( self . a )'key=locale.strxfrm' a sorted() después de ejecutar 'locale.setlocale(locale.LC_COLLATE, "en_US.UTF-8")' . from functools import total_ordering
@ total_ordering
class MySortable :
def __init__ ( self , a ):
self . a = a
def __eq__ ( self , other ):
if isinstance ( other , type ( self )):
return self . a == other . a
return NotImplemented
def __lt__ ( self , other ):
if isinstance ( other , type ( self )):
return self . a < other . a
return NotImplemented class Counter :
def __init__ ( self ):
self . i = 0
def __next__ ( self ):
self . i += 1
return self . i
def __iter__ ( self ):
return self > >> counter = Counter ()
> >> next ( counter ), next ( counter ), next ( counter )
( 1 , 2 , 3 )'callable(<obj>)' o 'isinstance(<obj>, collections.abc.Callable)' para comprobar si el objeto es invocable.'<function>' como argumento, significa '<callable>' . class Counter :
def __init__ ( self ):
self . i = 0
def __call__ ( self ):
self . i += 1
return self . i > >> counter = Counter ()
> >> counter (), counter (), counter ()
( 1 , 2 , 3 ) class MyOpen :
def __init__ ( self , filename ):
self . filename = filename
def __enter__ ( self ):
self . file = open ( self . filename )
return self . file
def __exit__ ( self , exc_type , exception , traceback ):
self . file . close () > >> with open ( 'test.txt' , 'w' ) as file :
... file . write ( 'Hello World!' )
> >> with MyOpen ( 'test.txt' ) as file :
... print ( file . read ())
Hello World ! class MyIterable :
def __init__ ( self , a ):
self . a = a
def __iter__ ( self ):
return iter ( self . a )
def __contains__ ( self , el ):
return el in self . a > >> obj = MyIterable ([ 1 , 2 , 3 ])
> >> [ el for el in obj ]
[ 1 , 2 , 3 ]
> >> 1 in obj
True'<iterable>' cuando usa '<collection>' . class MyCollection :
def __init__ ( self , a ):
self . a = a
def __iter__ ( self ):
return iter ( self . a )
def __contains__ ( self , el ):
return el in self . a
def __len__ ( self ):
return len ( self . a ) class MySequence :
def __init__ ( self , a ):
self . a = a
def __iter__ ( self ):
return iter ( self . a )
def __contains__ ( self , el ):
return el in self . a
def __len__ ( self ):
return len ( self . a )
def __getitem__ ( self , i ):
return self . a [ i ]
def __reversed__ ( self ):
return reversed ( self . a )'abc.Iterable' y 'abc.Collection' , no es del tipo pato. Es por eso que 'issubclass(MySequence, abc.Sequence)' devolvería False incluso si MySequence tuviera todos los métodos definidos. Sin embargo, reconoce lista, tupla, rango, cadena, bytes, matriz de bytes, matriz, vista de memoria y deque, ya que están registrados como subclases virtuales de Sequence. from collections import abc
class MyAbcSequence ( abc . Sequence ):
def __init__ ( self , a ):
self . a = a
def __len__ ( self ):
return len ( self . a )
def __getitem__ ( self , i ):
return self . a [ i ] +------------+------------+------------+------------+--------------+
| | Iterable | Collection | Sequence | abc.Sequence |
+------------+------------+------------+------------+--------------+
| iter() | REQ | REQ | Yes | Yes |
| contains() | Yes | Yes | Yes | Yes |
| len() | | REQ | REQ | REQ |
| getitem() | | | REQ | REQ |
| reversed() | | | Yes | Yes |
| index() | | | | Yes |
| count() | | | | Yes |
+------------+------------+------------+------------+--------------+
'isinstance(<obj>, abc.Iterable)' devuelva True; sin embargo, cualquier objeto con getitem() funcionará con cualquier código que espere un iterable.'<abc>.__abstractmethods__' para obtener los nombres de los métodos requeridos. Clase de constantes nombradas llamadas miembros.
from enum import Enum , auto class < enum_name > ( Enum ):
< member_name > = auto () # Increment of the last numeric value or 1.
< member_name > = < value > # Values don't have to be hashable.
< member_name > = < el_1 > , < el_2 > # Values can be collections (this is a tuple). < member > = < enum > . < member_name > # Returns a member. Raises AttributeError.
< member > = < enum > [ '<member_name>' ] # Returns a member. Raises KeyError.
< member > = < enum > ( < value > ) # Returns a member. Raises ValueError.
< str > = < member > . name # Returns member's name.
< obj > = < member > . value # Returns member's value. < list > = list ( < enum > ) # Returns enum's members.
< list > = [ a . name for a in < enum > ] # Returns enum's member names.
< list > = [ a . value for a in < enum > ] # Returns enum's member values. < enum > = type ( < member > ) # Returns member's enum.
< iter > = itertools . cycle ( < enum > ) # Returns endless iterator of members.
< member > = random . choice ( list ( < enum > )) # Returns a random member. Cutlery = Enum ( 'Cutlery' , 'FORK KNIFE SPOON' )
Cutlery = Enum ( 'Cutlery' , [ 'FORK' , 'KNIFE' , 'SPOON' ])
Cutlery = Enum ( 'Cutlery' , { 'FORK' : 1 , 'KNIFE' : 2 , 'SPOON' : 3 }) from functools import partial
LogicOp = Enum ( 'LogicOp' , { 'AND' : partial ( lambda l , r : l and r ),
'OR' : partial ( lambda l , r : l or r )}) try :
< code >
except < exception > :
< code > try :
< code_1 >
except < exception_a > :
< code_2_a >
except < exception_b > :
< code_2_b >
else :
< code_2_c >
finally :
< code_3 >'else' solo se ejecutará si el bloque 'try' no tuvo excepciones.'finally' siempre se ejecutará (a menos que se reciba una señal).'signal.signal(signal_number, <func>)' . except < exception > : ...
except < exception > as < name > : ...
except ( < exception > , [...]): ...
except ( < exception > , [...]) as < name > : ...'traceback.print_exc()' para imprimir el mensaje de error completo en stderr.'print(<name>)' para imprimir solo la causa de la excepción (sus argumentos).'logging.exception(<str>)' para registrar el mensaje pasado, seguido del mensaje de error completo de la excepción detectada. Para obtener más información, consulte Registro.'sys.exc_info()' para obtener el tipo de excepción, el objeto y el rastreo de la excepción detectada. raise < exception >
raise < exception > ()
raise < exception > ( < obj > [, ...]) except < exception > [ as < name > ]:
...
raise arguments = < name > . args
exc_type = < name > . __class__
filename = < name > . __traceback__ . tb_frame . f_code . co_filename
func_name = < name > . __traceback__ . tb_frame . f_code . co_name
line = linecache . getline ( filename , < name > . __traceback__ . tb_lineno )
trace_str = '' . join ( traceback . format_tb ( < name > . __traceback__ ))
error_msg = '' . join ( traceback . format_exception ( type ( < name > ), < name > , < name > . __traceback__ )) BaseException
+-- SystemExit # Raised by the sys.exit() function.
+-- KeyboardInterrupt # Raised when the user hits the interrupt key (ctrl-c).
+-- Exception # User-defined exceptions should be derived from this class.
+-- ArithmeticError # Base class for arithmetic errors such as ZeroDivisionError.
+-- AssertionError # Raised by `assert <exp>` if expression returns false value.
+-- AttributeError # Raised when object doesn't have requested attribute/method.
+-- EOFError # Raised by input() when it hits an end-of-file condition.
+-- LookupError # Base class for errors when a collection can't find an item.
| +-- IndexError # Raised when a sequence index is out of range.
| +-- KeyError # Raised when a dictionary key or set element is missing.
+-- MemoryError # Out of memory. May be too late to start deleting variables.
+-- NameError # Raised when nonexistent name (variable/func/class) is used.
| +-- UnboundLocalError # Raised when local name is used before it's being defined.
+-- OSError # Errors such as FileExistsError/TimeoutError (see #Open).
| +-- ConnectionError # Errors such as BrokenPipeError/ConnectionAbortedError.
+-- RuntimeError # Raised by errors that don't fall into other categories.
| +-- NotImplementedEr… # Can be raised by abstract methods or by unfinished code.
| +-- RecursionError # Raised when the maximum recursion depth is exceeded.
+-- StopIteration # Raised when an empty iterator is passed to next().
+-- TypeError # When an argument of the wrong type is passed to function.
+-- ValueError # When argument has the right type but inappropriate value.
+-----------+------------+------------+------------+
| | List | Set | Dict |
+-----------+------------+------------+------------+
| getitem() | IndexError | | KeyError |
| pop() | IndexError | KeyError | KeyError |
| remove() | ValueError | KeyError | |
| index() | ValueError | | |
+-----------+------------+------------+------------+
raise TypeError ( 'Argument is of the wrong type!' )
raise ValueError ( 'Argument has the right type but an inappropriate value!' )
raise RuntimeError ( 'I am too lazy to define my own exception!' ) class MyError ( Exception ): pass
class MyInputError ( MyError ): pass Sale del intérprete generando la excepción SystemExit.
import sys
sys . exit () # Exits with exit code 0 (success).
sys . exit ( < int > ) # Exits with the passed exit code.
sys . exit ( < obj > ) # Prints to stderr and exits with 1. print ( < el_1 > , ..., sep = ' ' , end = ' n ' , file = sys . stdout , flush = False )'file=sys.stderr' para mensajes sobre errores.'flush=True' o el programa sale. from pprint import pprint
pprint ( < collection > , width = 80 , depth = None , compact = False , sort_dicts = True ) < str > = input ( prompt = None ) import sys
scripts_path = sys . argv [ 0 ]
arguments = sys . argv [ 1 :] from argparse import ArgumentParser , FileType
p = ArgumentParser ( description = < str > ) # Returns a parser.
p . add_argument ( '-<short_name>' , '--<name>' , action = 'store_true' ) # Flag (defaults to False).
p . add_argument ( '-<short_name>' , '--<name>' , type = < type > ) # Option (defaults to None).
p . add_argument ( '<name>' , type = < type > , nargs = 1 ) # Mandatory first argument.
p . add_argument ( '<name>' , type = < type > , nargs = '+' ) # Mandatory remaining args.
p . add_argument ( '<name>' , type = < type > , nargs = '?/*' ) # Optional argument/s.
args = p . parse_args () # Exits on parsing error.
< obj > = args . < name > # Returns `<type>(<arg>)`.'help=<str>' para establecer la descripción del argumento que se mostrará en el mensaje de ayuda.'default=<obj>' para establecer el valor predeterminado de la opción o del argumento opcional.'type=FileType(<mode>)' para archivos. Acepta 'codificación', pero 'nueva línea' es Ninguna. Abre el archivo y devuelve el objeto de archivo correspondiente.
< file > = open ( < path > , mode = 'r' , encoding = None , newline = None )'encoding=None' significa que se utiliza la codificación predeterminada, que depende de la plataforma. La mejor práctica es utilizar 'encoding="utf-8"' siempre que sea posible.'newline=None' significa que todas las combinaciones diferentes de fin de línea se convierten a 'n' al leer, mientras que al escribir todos los caracteres 'n' se convierten al separador de línea predeterminado del sistema.'newline=""' significa que no se realizan conversiones, pero readline() y readlines() aún dividen la entrada en partes en cada 'n', 'r' y 'rn'.'r' - Leer. Usado por defecto.'w' - Escribe. Elimina contenidos existentes.'x' : escribe o falla si el archivo ya existe.'a' - Agregar. Crea un nuevo archivo si no existe.'w+' - Leer y escribir. Elimina contenidos existentes.'r+' - Leer y escribir desde el principio.'a+' - Leer y escribir desde el final.'b' - Modo binario ( 'rb' , 'wb' , 'xb' ,…).'FileNotFoundError' se puede generar al leer con 'r' o 'r+' .'FileExistsError' al escribir con 'x' .'IsADirectoryError' y 'PermissionError' .'OSError' es la clase principal de todas las excepciones enumeradas. < file > . seek ( 0 ) # Moves to the start of the file.
< file > . seek ( offset ) # Moves 'offset' chars/bytes from the start.
< file > . seek ( 0 , 2 ) # Moves to the end of the file.
< bin_file > . seek (± offset , origin ) # Origin: 0 start, 1 current position, 2 end. < str / bytes > = < file > . read ( size = - 1 ) # Reads 'size' chars/bytes or until EOF.
< str / bytes > = < file > . readline () # Returns a line or empty string/bytes on EOF.
< list > = < file > . readlines () # Returns a list of remaining lines.
< str / bytes > = next ( < file > ) # Returns a line using buffer. Do not mix. < file > . write ( < str / bytes > ) # Writes a string or bytes object.
< file > . writelines ( < collection > ) # Writes a coll. of strings or bytes objects.
< file > . flush () # Flushes write buffer. Runs every 4096/8192 B.
< file > . close () # Closes the file after flushing write buffer. def read_file ( filename ):
with open ( filename , encoding = 'utf-8' ) as file :
return file . readlines () def write_to_file ( filename , text ):
with open ( filename , 'w' , encoding = 'utf-8' ) as file :
file . write ( text ) import os , glob
from pathlib import Path < str > = os . getcwd () # Returns working dir. Starts as shell's $PWD.
< str > = os . path . join ( < path > , ...) # Joins two or more pathname components.
< str > = os . path . realpath ( < path > ) # Resolves symlinks and calls path.abspath(). < str > = os . path . basename ( < path > ) # Returns final component of the path.
< str > = os . path . dirname ( < path > ) # Returns path without the final component.
< tup . > = os . path . splitext ( < path > ) # Splits on last period of the final component. < list > = os . listdir ( path = '.' ) # Returns filenames located at the path.
< list > = glob . glob ( '<pattern>' ) # Returns paths matching the wildcard pattern. < bool > = os . path . exists ( < path > ) # Or: <Path>.exists()
< bool > = os . path . isfile ( < path > ) # Or: <DirEntry/Path>.is_file()
< bool > = os . path . isdir ( < path > ) # Or: <DirEntry/Path>.is_dir() < stat > = os . stat ( < path > ) # Or: <DirEntry/Path>.stat()
< num > = < stat > . st_mtime / st_size / … # Modification time, size in bytes, etc.A diferencia de listdir(), scandir() devuelve objetos DirEntry que almacenan en caché isfile, isdir y, en Windows, también información estadística, lo que aumenta significativamente el rendimiento del código que lo requiere.
< iter > = os . scandir ( path = '.' ) # Returns DirEntry objects located at the path.
< str > = < DirEntry > . path # Returns the whole path as a string.
< str > = < DirEntry > . name # Returns final component as a string.
< file > = open ( < DirEntry > ) # Opens the file and returns a file object. < Path > = Path ( < path > [, ...]) # Accepts strings, Paths, and DirEntry objects.
< Path > = < path > / < path > [ / ...] # First or second path must be a Path object.
< Path > = < Path > . resolve () # Returns absolute path with resolved symlinks. < Path > = Path () # Returns relative CWD. Also Path('.').
< Path > = Path . cwd () # Returns absolute CWD. Also Path().resolve().
< Path > = Path . home () # Returns user's home directory (absolute).
< Path > = Path ( __file__ ). resolve () # Returns script's path if CWD wasn't changed. < Path > = < Path > . parent # Returns Path without the final component.
< str > = < Path > . name # Returns final component as a string.
< str > = < Path > . stem # Returns final component without extension.
< str > = < Path > . suffix # Returns final component's extension.
< tup . > = < Path > . parts # Returns all components as strings. < iter > = < Path > . iterdir () # Returns directory contents as Path objects.
< iter > = < Path > . glob ( '<pattern>' ) # Returns Paths matching the wildcard pattern. < str > = str ( < Path > ) # Returns path as a string.
< file > = open ( < Path > ) # Also <Path>.read/write_text/bytes(<args>). import os , shutil , subprocess os . chdir ( < path > ) # Changes the current working directory.
os . mkdir ( < path > , mode = 0o777 ) # Creates a directory. Permissions are in octal.
os . makedirs ( < path > , mode = 0o777 ) # Creates all path's dirs. Also `exist_ok=False`. shutil . copy ( from , to ) # Copies the file. 'to' can exist or be a dir.
shutil . copy2 ( from , to ) # Also copies creation and modification time.
shutil . copytree ( from , to ) # Copies the directory. 'to' must not exist. os . rename ( from , to ) # Renames/moves the file or directory.
os . replace ( from , to ) # Same, but overwrites file 'to' even on Windows.
shutil . move ( from , to ) # Rename() that moves into 'to' if it's a dir. os . remove ( < path > ) # Deletes the file.
os . rmdir ( < path > ) # Deletes the empty directory.
shutil . rmtree ( < path > ) # Deletes the directory. < pipe > = os . popen ( '<commands>' ) # Executes commands in sh/cmd. Returns combined stdout.
< str > = < pipe > . read ( size = - 1 ) # Reads 'size' chars or until EOF. Also readline/s().
< int > = < pipe > . close () # Returns None if last command exited with returncode 0. > >> subprocess . run ( 'bc' , input = '1 + 1 n ' , capture_output = True , text = True )
CompletedProcess ( args = 'bc' , returncode = 0 , stdout = '2 n ' , stderr = '' ) > >> from shlex import split
> >> os . popen ( 'echo 1 + 1 > test.in' )
> >> subprocess . run ( split ( 'bc -s' ), stdin = open ( 'test.in' ), stdout = open ( 'test.out' , 'w' ))
CompletedProcess ( args = [ 'bc' , '-s' ], returncode = 0 )
> >> open ( 'test.out' ). read ()
'2 n ' Formato de archivo de texto para almacenar colecciones de cadenas y números.
import json
< str > = json . dumps ( < list / dict > ) # Converts collection to JSON string.
< coll > = json . loads ( < str > ) # Converts JSON string to collection. def read_json_file ( filename ):
with open ( filename , encoding = 'utf-8' ) as file :
return json . load ( file ) def write_to_json_file ( filename , list_or_dict ):
with open ( filename , 'w' , encoding = 'utf-8' ) as file :
json . dump ( list_or_dict , file , ensure_ascii = False , indent = 2 )Formato de archivo binario para almacenar objetos Python.
import pickle
< bytes > = pickle . dumps ( < object > ) # Converts object to bytes object.
< object > = pickle . loads ( < bytes > ) # Converts bytes object to object. def read_pickle_file ( filename ):
with open ( filename , 'rb' ) as file :
return pickle . load ( file ) def write_to_pickle_file ( filename , an_object ):
with open ( filename , 'wb' ) as file :
pickle . dump ( an_object , file )Formato de archivo de texto para almacenar hojas de cálculo.
import csv < reader > = csv . reader ( < file > ) # Also: `dialect='excel', delimiter=','`.
< list > = next ( < reader > ) # Returns next row as a list of strings.
< list > = list ( < reader > ) # Returns a list of remaining rows.'newline=""' , o las nuevas líneas incrustadas dentro de los campos entre comillas no se interpretarán correctamente. < writer > = csv . writer ( < file > ) # Also: `dialect='excel', delimiter=','`.
< writer > . writerow ( < collection > ) # Encodes objects using `str(<el>)`.
< writer > . writerows ( < coll_of_coll > ) # Appends multiple rows.'newline=""' , o se agregará 'r' delante de cada 'n' en plataformas que usan finales de línea 'rn'.'mode="a"' para agregarlo o 'mode="w"' para sobrescribirlo.'dialect' : parámetro maestro que establece los valores predeterminados. Cadena o un objeto 'csv.Dialect'.'delimiter' : una cadena de un carácter utilizada para separar campos.'lineterminator' : cómo el escritor termina las filas. El lector está codificado en 'n', 'r', 'rn'.'quotechar' : carácter para citar campos que contienen caracteres especiales.'escapechar' : carácter para escapar de las comillas.'doublequote' : si las comillas dentro de los campos se duplican o se escapan.'quoting' - 0: Según sea necesario, 1: Todos, 2: Todos excepto los números que se leen como flotantes, 3: Ninguno.'skipinitialspace' : es el carácter de espacio al inicio del campo que el lector elimina. +------------------+--------------+--------------+--------------+
| | excel | excel-tab | unix |
+------------------+--------------+--------------+--------------+
| delimiter | ',' | 't' | ',' |
| lineterminator | 'rn' | 'rn' | 'n' |
| quotechar | '"' | '"' | '"' |
| escapechar | None | None | None |
| doublequote | True | True | True |
| quoting | 0 | 0 | 1 |
| skipinitialspace | False | False | False |
+------------------+--------------+--------------+--------------+
def read_csv_file ( filename , ** csv_params ):
with open ( filename , encoding = 'utf-8' , newline = '' ) as file :
return list ( csv . reader ( file , ** csv_params )) def write_to_csv_file ( filename , rows , mode = 'w' , ** csv_params ):
with open ( filename , mode , encoding = 'utf-8' , newline = '' ) as file :
writer = csv . writer ( file , ** csv_params )
writer . writerows ( rows )Un motor de base de datos sin servidor que almacena cada base de datos en su propio archivo.
import sqlite3
< conn > = sqlite3 . connect ( < path > ) # Opens existing or new file. Also ':memory:'.
< conn > . close () # Closes connection. Discards uncommitted data. < cursor > = < conn > . execute ( '<query>' ) # Can raise a subclass of sqlite3.Error.
< tuple > = < cursor > . fetchone () # Returns next row. Also next(<cursor>).
< list > = < cursor > . fetchall () # Returns remaining rows. Also list(<cursor>). < conn > . execute ( '<query>' ) # Can raise a subclass of sqlite3.Error.
< conn > . commit () # Saves all changes since the last commit.
< conn > . rollback () # Discards all changes since the last commit. with < conn > : # Exits the block with commit() or rollback(),
< conn > . execute ( '<query>' ) # depending on whether any exception occurred. < conn > . execute ( '<query>' , < list / tuple > ) # Replaces '?'s in query with values.
< conn > . execute ( '<query>' , < dict / namedtuple > ) # Replaces ':<key>'s with values.
< conn > . executemany ( '<query>' , < coll_of_coll > ) # Runs execute() multiple times. En realidad, los valores no se guardan en este ejemplo porque se omite 'conn.commit()' .
> >> conn = sqlite3 . connect ( 'test.db' )
> >> conn . execute ( 'CREATE TABLE person (person_id INTEGER PRIMARY KEY, name, height)' )
> >> conn . execute ( 'INSERT INTO person VALUES (NULL, ?, ?)' , ( 'Jean-Luc' , 187 )). lastrowid
1
> >> conn . execute ( 'SELECT * FROM person' ). fetchall ()
[( 1 , 'Jean-Luc' , 187 )]Biblioteca para interactuar con varios sistemas de base de datos a través de SQL, encadenamiento de métodos u ORM.
# $ pip3 install sqlalchemy
from sqlalchemy import create_engine , text
< engine > = create_engine ( '<url>' ) # Url: 'dialect://user:password@host/dbname'.
< conn > = < engine > . connect () # Creates a connection. Also <conn>.close().
< cursor > = < conn > . execute ( text ( '<query>' ), …) # `<dict>`. Replaces ':<key>'s with values.
with < conn > . begin (): ... # Exits the block with commit or rollback. +-----------------+--------------+----------------------------------+
| Dialect | pip3 install | Dependencies |
+-----------------+--------------+----------------------------------+
| mysql | mysqlclient | www.pypi.org/project/mysqlclient |
| postgresql | psycopg2 | www.pypi.org/project/psycopg2 |
| mssql | pyodbc | www.pypi.org/project/pyodbc |
| oracle+oracledb | oracledb | www.pypi.org/project/oracledb |
+-----------------+--------------+----------------------------------+
Un objeto de bytes es una secuencia inmutable de bytes individuales. La versión mutable se llama bytearray.
< bytes > = b'<str>' # Only accepts ASCII characters and x00-xff.
< int > = < bytes > [ index ] # Returns an int in range from 0 to 255.
< bytes > = < bytes > [ < slice > ] # Returns bytes even if it has only one element.
< bytes > = < bytes > . join ( < coll_of_bytes > ) # Joins elements using bytes as a separator. < bytes > = bytes ( < coll_of_ints > ) # Ints must be in range from 0 to 255.
< bytes > = bytes ( < str > , 'utf-8' ) # Encodes the string. Also <str>.encode().
< bytes > = bytes . fromhex ( '<hex>' ) # Hex pairs can be separated by whitespaces.
< bytes > = < int > . to_bytes ( n_bytes , …) # `byteorder='big/little', signed=False`. < list > = list ( < bytes > ) # Returns ints in range from 0 to 255.
< str > = str ( < bytes > , 'utf-8' ) # Returns a string. Also <bytes>.decode().
< str > = < bytes > . hex () # Returns hex pairs. Accepts `sep=<str>`.
< int > = int . from_bytes ( < bytes > , …) # `byteorder='big/little', signed=False`. def read_bytes ( filename ):
with open ( filename , 'rb' ) as file :
return file . read () def write_bytes ( filename , bytes_obj ):
with open ( filename , 'wb' ) as file :
file . write ( bytes_obj ) from struct import pack , unpack
< bytes > = pack ( '<format>' , < el_1 > [, ...]) # Packs objects according to format string.
< tuple > = unpack ( '<format>' , < bytes > ) # Use iter_unpack() to get iterator of tuples. > >> pack ( '>hhl' , 1 , 2 , 3 )
b' x00 x01 x00 x02 x00 x00 x00 x03 '
> >> unpack ( '>hhl' , b' x00 x01 x00 x02 x00 x00 x00 x03 ' )
( 1 , 2 , 3 )'=' : orden de bytes del sistema (normalmente little-endian).'<' - Little-endian (es decir, el byte menos significativo primero).'>' - Big-endian (también '!' ). 'c' : un objeto de bytes con un solo elemento. Para el byte de relleno utilice 'x' .'<n>s' : un objeto de bytes con n elementos (no afectado por el orden de bytes). 'b' - carácter (1/1)'h' - corto (2/2)'i' - entero (2/4)'l' - largo (4/4)'q' - largo, largo (8/8) 'f' - flotador (4/4)'d' - doble (8/8) Lista que solo puede contener números de un tipo predefinido. Los tipos disponibles y sus tamaños mínimos en bytes se enumeran arriba. El tamaño de los tipos y el orden de los bytes siempre los determina el sistema; sin embargo, los bytes de cada elemento se pueden revertir con el método byteswap().
from array import array < array > = array ( '<typecode>' , < coll_of_nums > ) # Creates array from collection of numbers.
< array > = array ( '<typecode>' , < bytes > ) # Writes passed bytes to array's memory.
< array > = array ( '<typecode>' , < array > ) # Treats passed array as a sequence of numbers.
< array > . fromfile ( < file > , n_items ) # Appends file's contents to array's memory. < bytes > = bytes ( < array > ) # Returns a copy of array's memory.
< file > . write ( < array > ) # Writes array's memory to the binary file. Un objeto de secuencia que apunta a la memoria de otro objeto similar a bytes. Cada elemento puede hacer referencia a uno o varios bytes consecutivos, según el formato. El orden y la cantidad de elementos se pueden cambiar cortando.
< mview > = memoryview ( < bytes / bytearray / array > ) # Immutable if bytes is passed, else mutable.
< obj > = < mview > [ index ] # Returns int or float. Bytes if format is 'c'.
< mview > = < mview > [ < slice > ] # Returns memoryview with rearranged elements.
< mview > = < mview > . cast ( '<typecode>' ) # Only works between B/b/c and other types.
< mview > . release () # Releases memory buffer of the base object. < bytes > = bytes ( < mview > ) # Returns a new bytes object. Also bytearray().
< bytes > = < bytes > . join ( < coll_of_mviews > ) # Joins memoryviews using bytes as a separator.
< array > = array ( '<typecode>' , < mview > ) # Treats memoryview as a sequence of numbers.
< file > . write ( < mview > ) # Writes `bytes(<mview>)` to the binary file. < list > = list ( < mview > ) # Returns a list of ints, floats, or bytes.
< str > = str ( < mview > , 'utf-8' ) # Treats memoryview as a bytes object.
< str > = < mview > . hex () # Returns hex pairs. Accepts `sep=<str>`. Lista con agregados y elementos emergentes eficientes desde ambos lados. Se pronuncia "cubierta".
from collections import deque < deque > = deque ( < collection > ) # Use `maxlen=<int>` to set size limit.
< deque > . appendleft ( < el > ) # Opposite element is dropped if full.
< deque > . extendleft ( < collection > ) # Passed collection gets reversed.
< deque > . rotate ( n = 1 ) # Last element becomes first.
< el > = < deque > . popleft () # Raises IndexError if deque is empty. Módulo de funciones que proporciona la funcionalidad de los operadores. Las funciones están ordenadas y agrupadas por precedencia de operadores, de menor a mayor vinculación. Los operadores lógicos y aritméticos de las filas 1, 3 y 5 están ordenados por prioridad también dentro de un grupo.
import operator as op < bool > = op . not_ ( < obj > ) # or, and, not (or/and missing)
< bool > = op . eq / ne / lt / ge / is_ / is_not / contains ( < obj > , < obj > ) # ==, !=, <, >=, is, is not, in
< obj > = op . or_ / xor / and_ ( < int / set > , < int / set > ) # |, ^, &
< int > = op . lshift / rshift ( < int > , < int > ) # <<, >>
< obj > = op . add / sub / mul / truediv / floordiv / mod ( < obj > , < obj > ) # +, -, *, /, //, %
< num > = op . neg / invert ( < num > ) # -, ~
< num > = op . pow ( < num > , < num > ) # **
< func > = op . itemgetter / attrgetter / methodcaller ( < obj > [, ...]) # [index/key], .name, .name([…]) elementwise_sum = map ( op . add , list_a , list_b )
sorted_by_second = sorted ( < coll > , key = op . itemgetter ( 1 ))
sorted_by_both = sorted ( < coll > , key = op . itemgetter ( 1 , 0 ))
first_element = op . methodcaller ( 'pop' , 0 )( < list > )'x < y < z' se convierte en '(x < y) and (y < z) '. Ejecuta el primer bloque con el patrón coincidente. Agregado en Python 3.10.
match < object / expression > :
case < pattern > [ if < condition > ]:
< code >
... < value_pattern > = 1 / 'abc' / True / None / math . pi # Matches the literal or a dotted name.
< class_pattern > = < type > () # Matches any object of that type (or ABC).
< wildcard_patt > = _ # Matches any object. Useful in last case.
< capture_patt > = < name > # Matches any object and binds it to name.
< as_pattern > = < pattern > as < name > # Binds match to name. Also <type>(<name>).
< or_pattern > = < pattern > | < pattern > [ | ...] # Matches any of the patterns.
< sequence_patt > = [ < pattern > , ...] # Matches sequence with matching items.
< mapping_patt > = { < value_pattern > : < patt > , ...} # Matches dictionary with matching items.
< class_pattern > = < type > ( < attr_name >= < patt > , ...) # Matches object with matching attributes.'*<name>' y '**<name>' en patrones de secuencia/mapeo para vincular los elementos restantes.'|' > 'as' > ',' ). > >> from pathlib import Path
> >> match Path ( '/home/gto/python-cheatsheet/README.md' ):
... case Path (
... parts = [ '/' , 'home' , user , * _ ]
... ) as p if p . name . lower (). startswith ( 'readme' ) and p . is_file ():
... print ( f' { p . name } is a readme file that belongs to user { user } .' )
'README.md is a readme file that belongs to user gto.' import logging as log log . basicConfig ( filename = < path > , level = 'DEBUG' ) # Configures the root logger (see Setup).
log . debug / info / warning / error / critical ( < str > ) # Sends message to the root logger.
< Logger > = log . getLogger ( __name__ ) # Returns logger named after the module.
< Logger > . < level > ( < str > ) # Sends message to the logger.
< Logger > . exception ( < str > ) # Error() that appends caught exception. log . basicConfig (
filename = None , # Logs to stderr or appends to file.
format = '%(levelname)s:%(name)s:%(message)s' , # Add '%(asctime)s' for local datetime.
level = log . WARNING , # Drops messages with lower priority.
handlers = [ log . StreamHandler ( sys . stderr )] # Uses FileHandler if filename is set.
) < Formatter > = log . Formatter ( '<format>' ) # Creates a Formatter.
< Handler > = log . FileHandler ( < path > , mode = 'a' ) # Creates a Handler. Also `encoding=None`.
< Handler > . setFormatter ( < Formatter > ) # Adds Formatter to the Handler.
< Handler > . setLevel ( < int / str > ) # Processes all messages by default.
< Logger > . addHandler ( < Handler > ) # Adds Handler to the Logger.
< Logger > . setLevel ( < int / str > ) # What is sent to its/ancestors' handlers.
< Logger > . propagate = < bool > # Cuts off ancestors' handlers if False.'<parent>.<name>' .'filter(<LogRecord>)' (o el método en sí) a los registradores y controladores mediante addFilter(). El mensaje se descarta si filter() devuelve un valor falso. > >> logger = log . getLogger ( 'my_module' )
> >> handler = log . FileHandler ( 'test.log' , encoding = 'utf-8' )
> >> handler . setFormatter ( log . Formatter ( '%(asctime)s %(levelname)s:%(name)s:%(message)s' ))
> >> logger . addHandler ( handler )
> >> logger . setLevel ( 'DEBUG' )
> >> log . basicConfig ()
> >> log . root . handlers [ 0 ]. setLevel ( 'WARNING' )
> >> logger . critical ( 'Running out of disk space.' )
CRITICAL : my_module : Running out of disk space .
> >> print ( open ( 'test.log' ). read ())
2023 - 02 - 07 23 : 21 : 01 , 430 CRITICAL : my_module : Running out of disk space . < list > = dir () # List of local names (variables, funcs, classes, modules).
< dict > = vars () # Dict of local names and their objects. Also locals().
< dict > = globals () # Dict of global names and their objects, e.g. __builtin__. < list > = dir ( < obj > ) # Returns names of object's attributes (including methods).
< dict > = vars ( < obj > ) # Returns dict of writable attributes. Also <obj>.__dict__.
< bool > = hasattr ( < obj > , '<name>' ) # Checks if object possesses attribute with passed name.
value = getattr ( < obj > , '<name>' ) # Returns object's attribute or raises AttributeError.
setattr ( < obj > , '<name>' , value ) # Sets attribute. Only works on objects with __dict__ attr.
delattr ( < obj > , '<name>' ) # Deletes attribute from __dict__. Also `del <obj>.<name>`. < Sig > = inspect . signature ( < func > ) # Returns a Signature object of the passed function.
< dict > = < Sig > . parameters # Returns dict of Parameters. Also <Sig>.return_annotation.
< memb > = < Param > . kind # Returns ParameterKind member (Parameter.KEYWORD_ONLY, …).
< type > = < Param > . annotation # Returns Parameter.empty if missing. Also <Param>.default. El intérprete de CPython solo puede ejecutar un hilo a la vez. El uso de varios subprocesos no dará como resultado una ejecución más rápida, a menos que al menos uno de los subprocesos contenga una operación de E/S.
from threading import Thread , Lock , RLock , Semaphore , Event , Barrier
from concurrent . futures import ThreadPoolExecutor , as_completed < Thread > = Thread ( target = < function > ) # Use `args=<collection>` to set the arguments.
< Thread > . start () # Starts the thread. Also <Thread>.is_alive().
< Thread > . join () # Waits for the thread to finish.'kwargs=<dict>' para pasar argumentos de palabras clave a la función.'daemon=True' , o el programa no podrá salir mientras el hilo esté activo. < lock > = Lock / RLock () # RLock can only be released by acquirer.
< lock > . acquire () # Waits for the lock to be available.
< lock > . release () # Makes the lock available again. with < lock > : # Enters the block by calling acquire() and
... # exits it with release(), even on error. < Semaphore > = Semaphore ( value = 1 ) # Lock that can be acquired by 'value' threads.
< Event > = Event () # Method wait() blocks until set() is called.
< Barrier > = Barrier ( n_times ) # Wait() blocks until it's called n times. < Queue > = queue . Queue ( maxsize = 0 ) # A thread-safe first-in-first-out queue.
< Queue > . put ( < el > ) # Blocks until queue stops being full.
< Queue > . put_nowait ( < el > ) # Raises queue.Full exception if full.
< el > = < Queue > . get () # Blocks until queue stops being empty.
< el > = < Queue > . get_nowait () # Raises queue.Empty exception if empty. < Exec > = ThreadPoolExecutor ( max_workers = None ) # Or: `with ThreadPoolExecutor() as <name>: ...`
< iter > = < Exec > . map ( < func > , < args_1 > , ...) # Multithreaded and non-lazy map(). Keeps order.
< Futr > = < Exec > . submit ( < func > , < arg_1 > , ...) # Creates a thread and returns its Future obj.
< Exec > . shutdown () # Blocks until all threads finish executing. < bool > = < Future > . done () # Checks if the thread has finished executing.
< obj > = < Future > . result ( timeout = None ) # Waits for thread to finish and returns result.
< bool > = < Future > . cancel () # Cancels or returns False if running/finished.
< iter > = as_completed ( < coll_of_Futures > ) # `next(<iter>)` returns next completed Future.'if __name__ == "__main__": ...' . 'async' y su llamada con 'await' .'asyncio.run(<coroutine>)' para iniciar la primera/principal corrutina. import asyncio as aio < coro > = < async_function > ( < args > ) # Creates a coroutine by calling async def function.
< obj > = await < coroutine > # Starts the coroutine and returns its result.
< task > = aio . create_task ( < coroutine > ) # Schedules the coroutine for execution.
< obj > = await < task > # Returns coroutine's result. Also <task>.cancel(). < coro > = aio . gather ( < coro / task > , ...) # Schedules coros. Returns list of results on await.
< coro > = aio . wait ( < tasks > , …) # `aio.ALL/FIRST_COMPLETED`. Returns (done, pending).
< iter > = aio . as_completed ( < coros / tasks > ) # Iterator of coros. All return next result on await. import asyncio , collections , curses , curses . textpad , enum , random
P = collections . namedtuple ( 'P' , 'x y' ) # Position
D = enum . Enum ( 'D' , 'n e s w' ) # Direction
W , H = 15 , 7 # Width, Height
def main ( screen ):
curses . curs_set ( 0 ) # Makes cursor invisible.
screen . nodelay ( True ) # Makes getch() non-blocking.
asyncio . run ( main_coroutine ( screen )) # Starts running asyncio code.
async def main_coroutine ( screen ):
moves = asyncio . Queue ()
state = { '*' : P ( 0 , 0 )} | { id_ : P ( W // 2 , H // 2 ) for id_ in range ( 10 )}
ai = [ random_controller ( id_ , moves ) for id_ in range ( 10 )]
mvc = [ human_controller ( screen , moves ), model ( moves , state ), view ( state , screen )]
tasks = [ asyncio . create_task ( coro ) for coro in ai + mvc ]
await asyncio . wait ( tasks , return_when = asyncio . FIRST_COMPLETED )
async def random_controller ( id_ , moves ):
while True :
d = random . choice ( list ( D ))
moves . put_nowait (( id_ , d ))
await asyncio . sleep ( random . triangular ( 0.01 , 0.65 ))
async def human_controller ( screen , moves ):
while True :
key_mappings = { 258 : D . s , 259 : D . n , 260 : D . w , 261 : D . e }
if d := key_mappings . get ( screen . getch ()):
moves . put_nowait (( '*' , d ))
await asyncio . sleep ( 0.005 )
async def model ( moves , state ):
while state [ '*' ] not in ( state [ id_ ] for id_ in range ( 10 )):
id_ , d = await moves . get ()
deltas = { D . n : P ( 0 , - 1 ), D . e : P ( 1 , 0 ), D . s : P ( 0 , 1 ), D . w : P ( - 1 , 0 )}
state [ id_ ] = P (( state [ id_ ]. x + deltas [ d ]. x ) % W , ( state [ id_ ]. y + deltas [ d ]. y ) % H )
async def view ( state , screen ):
offset = P ( curses . COLS // 2 - W // 2 , curses . LINES // 2 - H // 2 )
while True :
screen . erase ()
curses . textpad . rectangle ( screen , offset . y - 1 , offset . x - 1 , offset . y + H , offset . x + W )
for id_ , p in state . items ():
screen . addstr ( offset . y + ( p . y - state [ '*' ]. y + H // 2 ) % H ,
offset . x + ( p . x - state [ '*' ]. x + W // 2 ) % W , str ( id_ ))
screen . refresh ()
await asyncio . sleep ( 0.005 )
if __name__ == '__main__' :
curses . wrapper ( main ) # $ pip3 install tqdm
> >> import tqdm , time
> >> for el in tqdm . tqdm ([ 1 , 2 , 3 ], desc = 'Processing' ):
... time . sleep ( 1 )
Processing : 100 % | ████████████████████ | 3 / 3 [ 00 : 03 < 00 : 00 , 1.00 s / it ] # $ pip3 install matplotlib
import matplotlib . pyplot as plt
plt . plot / bar / scatter ( x_data , y_data [, label = < str > ]) # Also plt.plot(y_data).
plt . legend () # Adds a legend.
plt . title / xlabel / ylabel ( < str > ) # Adds a title or label.
plt . savefig ( < path > ) # Saves the plot.
plt . show () # Displays the plot.
plt . clf () # Clears the plot. # $ pip3 install tabulate
import csv , tabulate
with open ( 'test.csv' , encoding = 'utf-8' , newline = '' ) as file :
rows = list ( csv . reader ( file ))
print ( tabulate . tabulate ( rows , headers = 'firstrow' )) # $ pip3 install windows-curses
import curses , os
from curses import A_REVERSE , KEY_DOWN , KEY_UP , KEY_LEFT , KEY_RIGHT , KEY_ENTER
def main ( screen ):
ch , first , selected , paths = 0 , 0 , 0 , os . listdir ()
while ch != ord ( 'q' ):
height , width = screen . getmaxyx ()
screen . erase ()
for y , filename in enumerate ( paths [ first : first + height ]):
color = A_REVERSE if filename == paths [ selected ] else 0
screen . addnstr ( y , 0 , filename , width - 1 , color )
ch = screen . getch ()
selected += ( ch == KEY_DOWN ) - ( ch == KEY_UP )
selected = max ( 0 , min ( len ( paths ) - 1 , selected ))
first += ( selected >= first + height ) - ( selected < first )
if ch in [ KEY_LEFT , KEY_RIGHT , KEY_ENTER , ord ( ' n ' ), ord ( ' r ' )]:
new_dir = '..' if ch == KEY_LEFT else paths [ selected ]
if os . path . isdir ( new_dir ):
os . chdir ( new_dir )
first , selected , paths = 0 , 0 , os . listdir ()
if __name__ == '__main__' :
curses . wrapper ( main ) # $ pip3 install PySimpleGUI
import PySimpleGUI as sg
text_box = sg . Input ( default_text = '100' , enable_events = True , key = '-QUANTITY-' )
dropdown = sg . InputCombo ([ 'g' , 'kg' , 't' ], 'kg' , readonly = True , enable_events = True , k = '-UNIT-' )
label = sg . Text ( '100 kg is 220.462 lbs.' , key = '-OUTPUT-' )
button = sg . Button ( 'Close' )
window = sg . Window ( 'Weight Converter' , [[ text_box , dropdown ], [ label ], [ button ]])
while True :
event , values = window . read ()
if event in [ sg . WIN_CLOSED , 'Close' ]:
break
try :
quantity = float ( values [ '-QUANTITY-' ])
except ValueError :
continue
unit = values [ '-UNIT-' ]
factors = { 'g' : 0.001 , 'kg' : 1 , 't' : 1000 }
lbs = quantity * factors [ unit ] / 0.45359237
window [ '-OUTPUT-' ]. update ( value = f' { quantity } { unit } is { lbs :g } lbs.' )
window . close () # $ pip3 install requests beautifulsoup4
import requests , bs4 , os
response = requests . get ( 'https://en.wikipedia.org/wiki/Python_(programming_language)' )
document = bs4 . BeautifulSoup ( response . text , 'html.parser' )
table = document . find ( 'table' , class_ = 'infobox vevent' )
python_url = table . find ( 'th' , text = 'Website' ). next_sibling . a [ 'href' ]
logo_url = table . find ( 'img' )[ 'src' ]
logo = requests . get ( f'https: { logo_url } ' ). content
filename = os . path . basename ( logo_url )
with open ( filename , 'wb' ) as file :
file . write ( logo )
print ( f' { python_url } , file:// { os . path . abspath ( filename ) } ' )Biblioteca para scraping de sitios web con contenido dinámico.
# $ pip3 install selenium
from selenium import webdriver
< WebDrv > = webdriver . Chrome / Firefox / Safari / Edge () # Opens a browser. Also <WebDrv>.quit().
< WebDrv > . get ( '<url>' ) # Also <WebDrv>.implicitly_wait(seconds).
< El > = < WebDrv / El > . find_element ( 'css selector' , …) # '<tag>#<id>.<class>[<attr>="<val>"]…'.
< list > = < WebDrv / El > . find_elements ( 'xpath' , …) # '//<tag>[@<attr>="<val>"]…'. See XPath.
< str > = < El > . get_attribute ( < str > ) # Property if exists. Also <El>.text.
< El > . click / clear () # Also <El>.send_keys(<str>). '$x("<xpath>")' : < xpath > = // < element > [ / or // < element > ] # /<child>, //<descendant>, /../<sibling>
< xpath > = // < element > / following :: < element > # Next element. Also preceding/parent/…
< element > = < tag > < conditions > < index > # `<tag> = */a/…`, `<index> = [1/2/…]`.
< condition > = [ < sub_cond > [ and / or < sub_cond > ]] # For negation use `not(<sub_cond>)`.
< sub_cond > = @ < attr > [ = "<val>" ] # `text()=`, `.=` match (complete) text.
< sub_cond > = contains (@ < attr > , "<val>" ) # Is <val> a substring of attr's value?
< sub_cond > = [ // ] < element > # Has matching child? Descendant if //. Flask es un marco/servidor micro web. Si solo desea abrir un archivo html en un navegador web, utilice 'webbrowser.open(<path>)' en su lugar.
# $ pip3 install flask
import flask as fl app = fl . Flask ( __name__ ) # Returns the app object. Put at the top.
app . run ( host = None , port = None , debug = None ) # Or: $ flask --app FILE run [--ARG[=VAL]]…'http://localhost:5000' . Utilice 'host="0.0.0.0"' para ejecutar externamente. @ app . route ( '/img/<path:filename>' )
def serve_file ( filename ):
return fl . send_from_directory ( 'dirname/' , filename ) @ app . route ( '/<sport>' )
def serve_html ( sport ):
return fl . render_template_string ( '<h1>{{title}}</h1>' , title = sport )'fl.render_template(filename, <kwargs>)' representa un archivo ubicado en el directorio 'plantillas'.'fl.abort(<int>)' devuelve el código de error y 'return fl.redirect(<url>)' redirecciona.'fl.request.args[<str>]' devuelve el parámetro de la cadena de consulta (URL a la derecha de '?').'fl.session[<str>] = <obj>' almacena datos de la sesión. Requiere que la clave secreta se establezca al inicio con 'app.secret_key = <str>' . @ app . post ( '/<sport>/odds' )
def serve_json ( sport ):
team = fl . request . form [ 'team' ]
return { 'team' : team , 'odds' : [ 2.09 , 3.74 , 3.68 ]} # $ pip3 install requests
> >> import threading , requests
> >> threading . Thread ( target = app . run , daemon = True ). start ()
> >> url = 'http://localhost:5000/football/odds'
> >> response = requests . post ( url , data = { 'team' : 'arsenal f.c.' })
> >> response . json ()
{ 'team' : 'arsenal f.c.' , 'odds' : [ 2.09 , 3.74 , 3.68 ]} from time import perf_counter
start_time = perf_counter ()
...
duration_in_seconds = perf_counter () - start_time > >> from timeit import timeit
> >> timeit ( 'list(range(10000))' , number = 1000 , globals = globals (), setup = 'pass' )
0.19373 $ pip3 install line_profiler
$ echo '@profile
def main():
a = list(range(10000))
b = set(range(10000))
main()' > test.py
$ kernprof -lv test.py
Line # Hits Time Per Hit % Time Line Contents
==============================================================
1 @profile
2 def main():
3 1 253.4 253.4 32.2 a = list(range(10000))
4 1 534.1 534.1 67.8 b = set(range(10000))
$ apt/brew install graphviz && pip3 install gprof2dot snakeviz # Or download installer.
$ tail --lines=+2 test.py > test.py # Removes first line.
$ python3 -m cProfile -o test.prof test.py # Runs built-in profiler.
$ gprof2dot --format=pstats test.prof | dot -T png -o test.png # Generates call graph.
$ xdg-open/open test.png # Displays call graph.
$ snakeviz test.prof # Displays flame graph. +--------------+------------+-------------------------------+-------+------+
| pip3 install | Target | How to run | Lines | Live |
+--------------+------------+-------------------------------+-------+------+
| pyinstrument | CPU | pyinstrument test.py | No | No |
| py-spy | CPU | py-spy top -- python3 test.py | No | Yes |
| scalene | CPU+Memory | scalene test.py | Yes | No |
| memray | Memory | memray run --live test.py | Yes | Yes |
+--------------+------------+-------------------------------+-------+------+
Minilenguaje de manipulación de matrices. Puede ejecutarse hasta cien veces más rápido que el código Python equivalente. Una alternativa aún más rápida que se ejecuta en una GPU se llama CuPy.
# $ pip3 install numpy
import numpy as np < array > = np . array ( < list / list_of_lists / … > ) # Returns a 1d/2d/… NumPy array.
< array > = np . zeros / ones / empty ( < shape > ) # Also np.full(<shape>, <el>).
< array > = np . arange ( from_inc , to_exc , ± step ) # Also np.linspace(start, stop, len).
< array > = np . random . randint ( from_inc , to_exc , < shape > ) # Also np.random.random(<shape>). < view > = < array > . reshape ( < shape > ) # Also `<array>.shape = <shape>`.
< array > = < array > . flatten () # Also `<view> = <array>.ravel()`.
< view > = < array > . transpose () # Or: <array>.T < array > = np . copy / abs / sqrt / log / int64 ( < array > ) # Returns new array of the same shape.
< array > = < array > . sum / max / mean / argmax / all ( axis ) # Aggregates specified dimension.
< array > = np . apply_along_axis ( < func > , axis , < array > ) # Func can return a scalar or array. < array > = np . concatenate ( < list_of_arrays > , axis = 0 ) # Links arrays along first axis (rows).
< array > = np . vstack / column_stack ( < list_of_arrays > ) # Treats 1d arrays as rows or columns.
< array > = np . tile / repeat ( < array > , < int / list > [, axis ]) # Tiles array or repeats its elements.<el> = <2d>[row_index, col_index] # Or: <3d>[<int>, <int>, <int>]
<1d_view> = <2d>[row_index] # Or: <3d>[<int>, <int>, <slice>]
<1d_view> = <2d>[:, col_index] # Or: <3d>[<int>, <slice>, <int>]
<2d_view> = <2d>[from:to_row_i, from:to_col_i] # Or: <3d>[<int>, <slice>, <slice>] <1d_array> = <2d>[row_indices, col_indices] # Or: <3d>[<int/1d>, <1d>, <1d>]
<2d_array> = <2d>[row_indices] # Or: <3d>[<int/1d>, <1d>, <slice>]
<2d_array> = <2d>[:, col_indices] # Or: <3d>[<int/1d>, <slice>, <1d>]
<2d_array> = <2d>[np.ix_(row_indices, col_indices)] # Or: <3d>[<int/1d/2d>, <2d>, <2d>] <2d_bools> = <2d> > <el/1d/2d> # 1d object must have size of a row.
<1/2d_arr> = <2d>[<2d/1d_bools>] # 1d_bools must have size of a column.':' devuelve una porción de los índices de todas las dimensiones. Las dimensiones omitidas son por defecto ':' .'obj[i, j]' en 'obj[(i, j)]' !'ix_([1, 2], [3, 4])' devuelve '[[1], [2]]' y '[[3, 4]]' . Debido a las reglas de transmisión, esto es lo mismo que usar '[[1, 1], [2, 2]]' y '[[3, 4], [3, 4]]' .Un conjunto de reglas mediante las cuales las funciones NumPy operan en matrices de diferentes formas.
left = [ 0.1 , 0.6 , 0.8 ] # Shape: (3,)
right = [[ 0.1 ], [ 0.6 ], [ 0.8 ]] # Shape: (3, 1) left = [[ 0.1 , 0.6 , 0.8 ]] # Shape: (1, 3) <- !
right = [[ 0.1 ], [ 0.6 ], [ 0.8 ]] # Shape: (3, 1) left = [[ 0.1 , 0.6 , 0.8 ], # Shape: (3, 3) <- !
[ 0.1 , 0.6 , 0.8 ],
[ 0.1 , 0.6 , 0.8 ]]
right = [[ 0.1 , 0.1 , 0.1 ], # Shape: (3, 3) <- !
[ 0.6 , 0.6 , 0.6 ],
[ 0.8 , 0.8 , 0.8 ]][0.1, 0.6, 0.8] => [1, 2, 1] ): > >> points = np . array ([ 0.1 , 0.6 , 0.8 ])
[ 0.1 , 0.6 , 0.8 ]
> >> wrapped_points = points . reshape ( 3 , 1 )
[[ 0.1 ], [ 0.6 ], [ 0.8 ]]
> >> distances = points - wrapped_points
[[ 0. , 0.5 , 0.7 ],
[ - 0.5 , 0. , 0.2 ],
[ - 0.7 , - 0.2 , 0. ]]
> >> distances = np . abs ( distances )
[[ 0. , 0.5 , 0.7 ],
[ 0.5 , 0. , 0.2 ],
[ 0.7 , 0.2 , 0. ]]
> >> distances [ range ( 3 ), range ( 3 )] = np . inf
[[ inf , 0.5 , 0.7 ],
[ 0.5 , inf , 0.2 ],
[ 0.7 , 0.2 , inf ]]
> >> distances . argmin ( 1 )
[ 1 , 2 , 1 ] # $ pip3 install pillow
from PIL import Image < Image > = Image . new ( '<mode>' , ( width , height )) # Creates new image. Also `color=<int/tuple>`.
< Image > = Image . open ( < path > ) # Identifies format based on file's contents.
< Image > = < Image > . convert ( '<mode>' ) # Converts image to the new mode (see Modes).
< Image > . save ( < path > ) # Selects format based on extension (PNG/JPG…).
< Image > . show () # Displays image in default preview app. < int / tup > = < Image > . getpixel (( x , y )) # Returns pixel's value (its color).
< ImgCore > = < Image > . getdata () # Returns a flattened view of pixel values.
< Image > . putpixel (( x , y ), < int / tuple > ) # Updates pixel's value. Clips passed int/s.
< Image > . putdata ( < list / ImgCore > ) # Updates pixels with a copy of the sequence.
< Image > . paste ( < Image > , ( x , y )) # Draws passed image at the specified location. < Image > = < Image > . filter ( < Filter > ) # Use ImageFilter.<name>(<args>) for Filter.
< Image > = < Enhance > . enhance ( < float > ) # Use ImageEnhance.<name>(<Image>) for Enhance. < array > = np . array ( < Image > ) # Creates a 2d/3d NumPy array from the image.
< Image > = Image . fromarray ( np . uint8 ( < array > )) # Use <array>.clip(0, 255) to clip the values.'L' - Luminosidad (imagen en escala de grises). Cada píxel es un int entre 0 y 255.'RGB' : rojo, verde, azul (imagen en color verdadero). Cada píxel es una tupla de tres enteros.'RGBA' - RGB con alfa. Un alfa bajo (es decir, un int) hace que los píxeles sean más transparentes.'HSV' - Tono, saturación, valor. Tres entradas que representan el color en el espacio de color HSV. WIDTH , HEIGHT = 100 , 100
n_pixels = WIDTH * HEIGHT
hues = ( 255 * i / n_pixels for i in range ( n_pixels ))
img = Image . new ( 'HSV' , ( WIDTH , HEIGHT ))
img . putdata ([( int ( h ), 255 , 255 ) for h in hues ])
img . convert ( 'RGB' ). save ( 'test.png' ) from random import randint
add_noise = lambda value : max ( 0 , min ( 255 , value + randint ( - 20 , 20 )))
img = Image . open ( 'test.png' ). convert ( 'HSV' )
img . putdata ([( add_noise ( h ), s , v ) for h , s , v in img . getdata ()])
img . show () from PIL import ImageDraw
< Draw > = ImageDraw . Draw ( < Image > ) # Object for adding 2D graphics to the image.
< Draw > . point (( x , y )) # Draws a point. Truncates floats into ints.
< Draw > . line (( x1 , y1 , x2 , y2 [, ...])) # To get anti-aliasing use Image's resize().
< Draw > . arc (( x1 , y1 , x2 , y2 ), deg1 , deg2 ) # Draws in clockwise dir. Also pieslice().
< Draw > . rectangle (( x1 , y1 , x2 , y2 )) # Also rounded_rectangle(), regular_polygon().
< Draw > . polygon (( x1 , y1 , x2 , y2 , ...)) # Last point gets connected to the first.
< Draw > . ellipse (( x1 , y1 , x2 , y2 )) # To rotate use Image's rotate() and paste().
< Draw > . text (( x , y ), < str > , font = < Font > ) # `<Font> = ImageFont.truetype(<path>, size)`.'fill=<color>' para establecer el color primario.'width=<int>' para establecer el ancho de líneas o contornos.'outline=<color>' para establecer el color de los contornos.'#rrggbb[aa]' o un nombre de color. # $ pip3 install imageio
from PIL import Image , ImageDraw
import imageio
WIDTH , HEIGHT , R = 126 , 126 , 10
frames = []
for velocity in range ( 1 , 16 ):
y = sum ( range ( velocity ))
frame = Image . new ( 'L' , ( WIDTH , HEIGHT ))
draw = ImageDraw . Draw ( frame )
draw . ellipse (( WIDTH / 2 - R , y , WIDTH / 2 + R , y + R * 2 ), fill = 'white' )
frames . append ( frame )
frames += reversed ( frames [ 1 : - 1 ])
imageio . mimsave ( 'test.gif' , frames , duration = 0.03 ) import wave < Wave > = wave . open ( '<path>' ) # Opens the WAV file for reading.
< int > = < Wave > . getframerate () # Returns number of frames per second.
< int > = < Wave > . getnchannels () # Returns number of samples per frame.
< int > = < Wave > . getsampwidth () # Returns number of bytes per sample.
< tuple > = < Wave > . getparams () # Returns namedtuple of all parameters.
< bytes > = < Wave > . readframes ( nframes ) # Returns next n frames (-1 returns all). < Wave > = wave . open ( '<path>' , 'wb' ) # Creates/truncates a file for writing.
< Wave > . setframerate ( < int > ) # Pass 44100 for CD, 48000 for video.
< Wave > . setnchannels ( < int > ) # Pass 1 for mono, 2 for stereo.
< Wave > . setsampwidth ( < int > ) # Pass 2 for CD, 3 for hi-res sound.
< Wave > . setparams ( < tuple > ) # Tuple must contain all parameters.
< Wave > . writeframes ( < bytes > ) # Appends frames to the file. +-----------+-----------+------+-----------+
| sampwidth | min | zero | max |
+-----------+-----------+------+-----------+
| 1 | 0 | 128 | 255 |
| 2 | -32768 | 0 | 32767 |
| 3 | -8388608 | 0 | 8388607 |
+-----------+-----------+------+-----------+
def read_wav_file ( filename ):
def get_int ( bytes_obj ):
an_int = int . from_bytes ( bytes_obj , 'little' , signed = ( p . sampwidth != 1 ))
return an_int - 128 * ( p . sampwidth == 1 )
with wave . open ( filename ) as file :
p = file . getparams ()
frames = file . readframes ( - 1 )
bytes_samples = ( frames [ i : i + p . sampwidth ] for i in range ( 0 , len ( frames ), p . sampwidth ))
return [ get_int ( b ) / pow ( 2 , ( p . sampwidth * 8 ) - 1 ) for b in bytes_samples ], p def write_to_wav_file ( filename , samples_f , p = None , nchannels = 1 , sampwidth = 2 , framerate = 44100 ):
def get_bytes ( a_float ):
a_float = max ( - 1 , min ( 1 - 2e-16 , a_float ))
a_float += p . sampwidth == 1
a_float *= pow ( 2 , ( p . sampwidth * 8 ) - 1 )
return int ( a_float ). to_bytes ( p . sampwidth , 'little' , signed = ( p . sampwidth != 1 ))
if p is None :
p = wave . _wave_params ( nchannels , sampwidth , framerate , 0 , 'NONE' , 'not compressed' )
with wave . open ( filename , 'wb' ) as file :
file . setparams ( p )
file . writeframes ( b'' . join ( get_bytes ( f ) for f in samples_f )) from math import pi , sin
samples_f = ( sin ( i * 2 * pi * 440 / 44100 ) for i in range ( 100_000 ))
write_to_wav_file ( 'test.wav' , samples_f ) from random import uniform
samples_f , params = read_wav_file ( 'test.wav' )
samples_f = ( f + uniform ( - 0.05 , 0.05 ) for f in samples_f )
write_to_wav_file ( 'test.wav' , samples_f , params ) # $ pip3 install simpleaudio
from simpleaudio import play_buffer
with wave . open ( 'test.wav' ) as file :
p = file . getparams ()
frames = file . readframes ( - 1 )
play_buffer ( frames , p . nchannels , p . sampwidth , p . framerate ). wait_done () # $ pip3 install pyttsx3
import pyttsx3
engine = pyttsx3 . init ()
engine . say ( 'Sally sells seashells by the seashore.' )
engine . runAndWait () # $ pip3 install simpleaudio
import array , itertools as it , math , simpleaudio
F = 44100
P1 = '71♩,69♪,,71♩,66♪,,62♩,66♪,,59♩,,,71♩,69♪,,71♩,66♪,,62♩,66♪,,59♩,,,'
P2 = '71♩,73♪,,74♩,73♪,,74♪,,71♪,,73♩,71♪,,73♪,,69♪,,71♩,69♪,,71♪,,67♪,,71♩,,,'
get_pause = lambda seconds : it . repeat ( 0 , int ( seconds * F ))
sin_f = lambda i , hz : math . sin ( i * 2 * math . pi * hz / F )
get_wave = lambda hz , seconds : ( sin_f ( i , hz ) for i in range ( int ( seconds * F )))
get_hz = lambda note : 440 * 2 ** (( int ( note [: 2 ]) - 69 ) / 12 )
get_sec = lambda note : 1 / 4 if '♩' in note else 1 / 8
get_samples = lambda note : get_wave ( get_hz ( note ), get_sec ( note )) if note else get_pause ( 1 / 8 )
samples_f = it . chain . from_iterable ( get_samples ( n ) for n in ( P1 + P2 ). split ( ',' ))
samples_i = array . array ( 'h' , ( int ( f * 30000 ) for f in samples_f ))
simpleaudio . play_buffer ( samples_i , 1 , 2 , F ). wait_done () # $ pip3 install pygame
import pygame as pg
pg . init ()
screen = pg . display . set_mode (( 500 , 500 ))
rect = pg . Rect ( 240 , 240 , 20 , 20 )
while not pg . event . get ( pg . QUIT ):
deltas = { pg . K_UP : ( 0 , - 20 ), pg . K_RIGHT : ( 20 , 0 ), pg . K_DOWN : ( 0 , 20 ), pg . K_LEFT : ( - 20 , 0 )}
for event in pg . event . get ( pg . KEYDOWN ):
dx , dy = deltas . get ( event . key , ( 0 , 0 ))
rect = rect . move (( dx , dy ))
screen . fill ( pg . Color ( 'black' ))
pg . draw . rect ( screen , pg . Color ( 'white' ), rect )
pg . display . flip ()Objeto para almacenar coordenadas rectangulares.
< Rect > = pg . Rect ( x , y , width , height ) # Creates Rect object. Truncates passed floats.
< int > = < Rect > . x / y / centerx / centery / … # Top, right, bottom, left. Allows assignments.
< tup . > = < Rect > . topleft / center / … # Topright, bottomright, bottomleft. Same.
< Rect > = < Rect > . move (( delta_x , delta_y )) # Use move_ip() to move in-place. < bool > = < Rect > . collidepoint (( x , y )) # Checks if rectangle contains the point.
< bool > = < Rect > . colliderect ( < Rect > ) # Checks if the two rectangles overlap.
< int > = < Rect > . collidelist ( < list_of_Rect > ) # Returns index of first colliding Rect or -1.
< list > = < Rect > . collidelistall ( < list_of_Rect > ) # Returns indices of all colliding rectangles.Objeto para representar imágenes.
< Surf > = pg . display . set_mode (( width , height )) # Opens new window and returns its surface.
< Surf > = pg . Surface (( width , height )) # New RGB surface. RGBA if `flags=pg.SRCALPHA`.
< Surf > = pg . image . load ( < path / file > ) # Loads the image. Format depends on source.
< Surf > = pg . surfarray . make_surface ( < np_array > ) # Also `<np_arr> = surfarray.pixels3d(<Surf>)`.
< Surf > = < Surf > . subsurface ( < Rect > ) # Creates a new surface from the cutout. < Surf > . fill ( color ) # Tuple, Color('#rrggbb[aa]') or Color(<name>).
< Surf > . set_at (( x , y ), color ) # Updates pixel. Also <Surf>.get_at((x, y)).
< Surf > . blit ( < Surf > , ( x , y )) # Draws passed surface at specified location. from pygame . transform import scale , ...
< Surf > = scale ( < Surf > , ( width , height )) # Returns scaled surface.
< Surf > = rotate ( < Surf > , anticlock_degrees ) # Returns rotated and scaled surface.
< Surf > = flip ( < Surf > , x_bool , y_bool ) # Returns flipped surface. from pygame . draw import line , ...
line ( < Surf > , color , ( x1 , y1 ), ( x2 , y2 ), width ) # Draws a line to the surface.
arc ( < Surf > , color , < Rect > , from_rad , to_rad ) # Also ellipse(<Surf>, color, <Rect>, width=0).
rect ( < Surf > , color , < Rect > , width = 0 ) # Also polygon(<Surf>, color, points, width=0). < Font > = pg . font . Font ( < path / file > , size ) # Loads TTF file. Pass None for default font.
< Surf > = < Font > . render ( text , antialias , color ) # Background color can be specified at the end. < Sound > = pg . mixer . Sound ( < path / file / bytes > ) # WAV file or bytes/array of signed shorts.
< Sound > . play / stop () # Also set_volume(<float>), fadeout(msec). import collections , dataclasses , enum , io , itertools as it , pygame as pg , urllib . request
from random import randint
P = collections . namedtuple ( 'P' , 'x y' ) # Position
D = enum . Enum ( 'D' , 'n e s w' ) # Direction
W , H , MAX_S = 50 , 50 , P ( 5 , 10 ) # Width, Height, Max speed
def main ():
def get_screen ():
pg . init ()
return pg . display . set_mode (( W * 16 , H * 16 ))
def get_images ():
url = 'https://gto76.github.io/python-cheatsheet/web/mario_bros.png'
img = pg . image . load ( io . BytesIO ( urllib . request . urlopen ( url ). read ()))
return [ img . subsurface ( get_rect ( x , 0 )) for x in range ( img . get_width () // 16 )]
def get_mario ():
Mario = dataclasses . make_dataclass ( 'Mario' , 'rect spd facing_left frame_cycle' . split ())
return Mario ( get_rect ( 1 , 1 ), P ( 0 , 0 ), False , it . cycle ( range ( 3 )))
def get_tiles ():
border = [( x , y ) for x in range ( W ) for y in range ( H ) if x in [ 0 , W - 1 ] or y in [ 0 , H - 1 ]]
platforms = [( randint ( 1 , W - 2 ), randint ( 2 , H - 2 )) for _ in range ( W * H // 10 )]
return [ get_rect ( x , y ) for x , y in border + platforms ]
def get_rect ( x , y ):
return pg . Rect ( x * 16 , y * 16 , 16 , 16 )
run ( get_screen (), get_images (), get_mario (), get_tiles ())
def run ( screen , images , mario , tiles ):
clock = pg . time . Clock ()
pressed = set ()
while not pg . event . get ( pg . QUIT ) and clock . tick ( 28 ):
keys = { pg . K_UP : D . n , pg . K_RIGHT : D . e , pg . K_DOWN : D . s , pg . K_LEFT : D . w }
pressed |= { keys . get ( e . key ) for e in pg . event . get ( pg . KEYDOWN )}
pressed -= { keys . get ( e . key ) for e in pg . event . get ( pg . KEYUP )}
update_speed ( mario , tiles , pressed )
update_position ( mario , tiles )
draw ( screen , images , mario , tiles )
def update_speed ( mario , tiles , pressed ):
x , y = mario . spd
x += 2 * (( D . e in pressed ) - ( D . w in pressed ))
x += ( x < 0 ) - ( x > 0 )
y += 1 if D . s not in get_boundaries ( mario . rect , tiles ) else ( D . n in pressed ) * - 10
mario . spd = P ( x = max ( - MAX_S . x , min ( MAX_S . x , x )), y = max ( - MAX_S . y , min ( MAX_S . y , y )))
def update_position ( mario , tiles ):
x , y = mario . rect . topleft
n_steps = max ( abs ( s ) for s in mario . spd )
for _ in range ( n_steps ):
mario . spd = stop_on_collision ( mario . spd , get_boundaries ( mario . rect , tiles ))
x , y = x + ( mario . spd . x / n_steps ), y + ( mario . spd . y / n_steps )
mario . rect . topleft = x , y
def get_boundaries ( rect , tiles ):
deltas = { D . n : P ( 0 , - 1 ), D . e : P ( 1 , 0 ), D . s : P ( 0 , 1 ), D . w : P ( - 1 , 0 )}
return { d for d , delta in deltas . items () if rect . move ( delta ). collidelist ( tiles ) != - 1 }
def stop_on_collision ( spd , bounds ):
return P ( x = 0 if ( D . w in bounds and spd . x < 0 ) or ( D . e in bounds and spd . x > 0 ) else spd . x ,
y = 0 if ( D . n in bounds and spd . y < 0 ) or ( D . s in bounds and spd . y > 0 ) else spd . y )
def draw ( screen , images , mario , tiles ):
screen . fill (( 85 , 168 , 255 ))
mario . facing_left = mario . spd . x < 0 if mario . spd . x else mario . facing_left
is_airborne = D . s not in get_boundaries ( mario . rect , tiles )
image_index = 4 if is_airborne else ( next ( mario . frame_cycle ) if mario . spd . x else 6 )
screen . blit ( images [ image_index + ( mario . facing_left * 9 )], mario . rect )
for t in tiles :
is_border = t . x in [ 0 , ( W - 1 ) * 16 ] or t . y in [ 0 , ( H - 1 ) * 16 ]
screen . blit ( images [ 18 if is_border else 19 ], t )
pg . display . flip ()
if __name__ == '__main__' :
main ()Biblioteca de análisis de datos. Para ver ejemplos, consulte Trama.
# $ pip3 install pandas matplotlib
import pandas as pd , matplotlib . pyplot as pltDiccionario ordenado con un nombre.
> >> s = pd . Series ([ 1 , 2 ], index = [ 'x' , 'y' ], name = 'a' ); s
x 1
y 2
Name : a , dtype : int64 < S > = pd . Series ( < list > ) # Uses list's indices for 'index'.
< S > = pd . Series ( < dict > ) # Uses dictionary's keys for 'index'. < el > = < S > . loc [ key ] # Or: <S>.iloc[i]
< S > = < S > . loc [ coll_of_keys ] # Or: <S>.iloc[coll_of_i]
< S > = < S > . loc [ from_key : to_key_inc ] # Or: <S>.iloc[from_i : to_i_exc] < el > = < S > [ key / i ] # Or: <S>.<key>
< S > = < S > [ coll_of_keys / coll_of_i ] # Or: <S>[key/i : key/i]
< S > = < S > [ bools ] # Or: <S>.loc/iloc[bools] < S > = < S > > < el / S > # Returns S of bools. Pairs items by keys.
< S > = < S > + < el / S > # Items with non-matching keys get value NaN. < S > = pd . concat ( < coll_of_S > ) # Concats multiple series into one long Series.
< S > = < S > . combine_first ( < S > ) # Adds items that are not yet present.
< S > . update ( < S > ) # Updates items that are already present. < S > . plot . line / area / bar / pie / hist () # Generates a plot. `plt.show()` displays it.'obj[x, y]' se convierte en 'obj[(x, y)]' .'np.int64' . La serie se convierte a 'float64' si asignamos np.nan a cualquier elemento. Utilice '<S>.astype(<str/type>)' para convertir la serie.'pd.Series([100], dtype="int8") + 100' . < el > = < S > . sum / max / mean / idxmax / all () # Or: <S>.agg(lambda <S>: <el>)
< S > = < S > . rank / diff / cumsum / ffill / interpol …() # Or: <S>.agg/transform(lambda <S>: <S>)
< S > = < S > . isna / fillna / isin ([ < el / coll > ]) # Or: <S>.agg/transform/map(lambda <el>: <el>) +--------------+-------------+-------------+---------------+
| | 'sum' | ['sum'] | {'s': 'sum'} |
+--------------+-------------+-------------+---------------+
| s.apply(…) | 3 | sum 3 | s 3 |
| s.agg(…) | | | |
+--------------+-------------+-------------+---------------+
+--------------+-------------+-------------+---------------+
| | 'rank' | ['rank'] | {'r': 'rank'} |
+--------------+-------------+-------------+---------------+
| s.apply(…) | | rank | |
| s.agg(…) | x 1.0 | x 1.0 | r x 1.0 |
| | y 2.0 | y 2.0 | y 2.0 |
+--------------+-------------+-------------+---------------+
'inplace=True' .'<S>[key_1, key_2]' para obtener sus valores.Tabla con filas y columnas etiquetadas.
> >> df = pd . DataFrame ([[ 1 , 2 ], [ 3 , 4 ]], index = [ 'a' , 'b' ], columns = [ 'x' , 'y' ]); df
x y
a 1 2
b 3 4 < DF > = pd . DataFrame ( < list_of_rows > ) # Rows can be either lists, dicts or series.
< DF > = pd . DataFrame ( < dict_of_columns > ) # Columns can be either lists, dicts or series. < el > = < DF > . loc [ row_key , col_key ] # Or: <DF>.iloc[row_i, col_i]
< S / DF > = < DF > . loc [ row_key / s ] # Or: <DF>.iloc[row_i/s]
< S / DF > = < DF > . loc [:, col_key / s ] # Or: <DF>.iloc[:, col_i/s]
< DF > = < DF > . loc [ row_bools , col_bools ] # Or: <DF>.iloc[row_bools, col_bools] < S / DF > = < DF > [ col_key / s ] # Or: <DF>.<col_key>
< DF > = < DF > [ < S_of_bools > ] # Filters rows. For example `df[df.x > 1]`.
< DF > = < DF > [ < DF_of_bools > ] # Assigns NaN to items that are False in bools. < DF > = < DF > > < el / S / DF > # Returns DF of bools. S is treated as a row.
< DF > = < DF > + < el / S / DF > # Items with non-matching keys get value NaN. < DF > = < DF > . set_index ( col_key ) # Replaces row keys with column's values.
< DF > = < DF > . reset_index ( drop = False ) # Drops or moves row keys to column named index.
< DF > = < DF > . sort_index ( ascending = True ) # Sorts rows by row keys. Use `axis=1` for cols.
< DF > = < DF > . sort_values ( col_key / s ) # Sorts rows by passed column/s. Also `axis=1`. < DF > = < DF > . head / tail / sample ( < int > ) # Returns first, last, or random n rows.
< DF > = < DF > . describe () # Describes columns. Also info(), corr(), shape.
< DF > = < DF > . query ( '<query>' ) # Filters rows. For example `df.query('x > 1')`. < DF > . plot . line / area / bar / scatter ( x = col_key , …) # `y=col_key/s`. Also hist/box(by=col_key).
plt . show () # Displays the plot. Also plt.savefig(<path>). > >> df_2 = pd . DataFrame ([[ 4 , 5 ], [ 6 , 7 ]], index = [ 'b' , 'c' ], columns = [ 'y' , 'z' ]); df_2
y z
b 4 5
c 6 7 +-----------------------+---------------+------------+------------+---------------------------+
| | 'outer' | 'inner' | 'left' | Description |
+-----------------------+---------------+------------+------------+---------------------------+
| df.merge(df_2, | x y z | x y z | x y z | Merges on column if 'on' |
| on='y', | 0 1 2 . | 3 4 5 | 1 2 . | or 'left_on/right_on' are |
| how=…) | 1 3 4 5 | | 3 4 5 | set, else on shared cols. |
| | 2 . 6 7 | | | Uses 'inner' by default. |
+-----------------------+---------------+------------+------------+---------------------------+
| df.join(df_2, | x yl yr z | | x yl yr z | Merges on row keys. |
| lsuffix='l', | a 1 2 . . | x yl yr z | 1 2 . . | Uses 'left' by default. |
| rsuffix='r', | b 3 4 4 5 | 3 4 4 5 | 3 4 4 5 | If Series is passed, it |
| how=…) | c . . 6 7 | | | is treated as a column. |
+-----------------------+---------------+------------+------------+---------------------------+
| pd.concat([df, df_2], | x y z | y | | Adds rows at the bottom. |
| axis=0, | a 1 2 . | 2 | | Uses 'outer' by default. |
| join=…) | b 3 4 . | 4 | | A Series is treated as a |
| | b . 4 5 | 4 | | column. To add a row use |
| | c . 6 7 | 6 | | pd.concat([df, DF([s])]). |
+-----------------------+---------------+------------+------------+---------------------------+
| pd.concat([df, df_2], | x y y z | | | Adds columns at the |
| axis=1, | a 1 2 . . | x y y z | | right end. Uses 'outer' |
| join=…) | b 3 4 4 5 | 3 4 4 5 | | by default. A Series is |
| | c . . 6 7 | | | treated as a column. |
+-----------------------+---------------+------------+------------+---------------------------+
< S > = < DF > . sum / max / mean / idxmax / all () # Or: <DF>.apply/agg(lambda <S>: <el>)
< DF > = < DF > . rank / diff / cumsum / ffill / interpo …() # Or: <DF>.apply/agg/transform(lambda <S>: <S>)
< DF > = < DF > . isna / fillna / isin ([ < el / coll > ]) # Or: <DF>.applymap(lambda <el>: <el>) +-----------------+---------------+---------------+---------------+
| | 'sum' | ['sum'] | {'x': 'sum'} |
+-----------------+---------------+---------------+---------------+
| df.apply(…) | x 4 | x y | x 4 |
| df.agg(…) | y 6 | sum 4 6 | |
+-----------------+---------------+---------------+---------------+
+-----------------+---------------+---------------+---------------+
| | 'rank' | ['rank'] | {'x': 'rank'} |
+-----------------+---------------+---------------+---------------+
| df.apply(…) | | x y | |
| df.agg(…) | x y | rank rank | x |
| df.transform(…) | a 1.0 1.0 | a 1.0 1.0 | a 1.0 |
| | b 2.0 2.0 | b 2.0 2.0 | b 2.0 |
+-----------------+---------------+---------------+---------------+
'axis=1' para procesar las filas.'<DF>.loc[row_key, (col_key_1, col_key_2)]' . < DF > = < DF > . xs ( row_key , level = < int > ) # Rows with key on passed level of multi-index.
< DF > = < DF > . xs ( row_keys , level = < ints > ) # Rows that have first key on first level, etc.
< DF > = < DF > . set_index ( col_keys ) # Combines multiple columns into a multi-index.
< S / DF > = < DF > . stack / unstack ( level = - 1 ) # Combines col keys with row keys or vice versa.
< DF > = < DF > . pivot_table ( index = col_key / s ) # `columns=key/s, values=key/s, aggfunc='mean'`. < DF > = pd . read_json / html ( '<str/path/url>' ) # Run `$ pip3 install beautifulsoup4 lxml`.
< DF > = pd . read_csv ( '<path/url>' ) # `header/index_col/dtype/usecols/…=<obj>`.
< DF > = pd . read_pickle / excel ( '<path/url>' ) # Use `sheet_name=None` to get all Excel sheets.
< DF > = pd . read_sql ( '<table/query>' , < conn . > ) # SQLite3/SQLAlchemy connection (see #SQLite). < dict > = < DF > . to_dict ( 'd/l/s/…' ) # Returns columns as dicts, lists or series.
< str > = < DF > . to_json / html / csv / latex () # Saves output to a file if path is passed.
< DF > . to_pickle / excel ( < path > ) # Run `$ pip3 install "pandas[excel]" odfpy`.
< DF > . to_sql ( '<table_name>' , < connection > ) # Also `if_exists='fail/replace/append'`.'<S> = pd.to_datetime(<S>, errors="coerce")' , que usa pd.nat.'<S>.dt.year/date/…' .OBJETA que agrupa las filas de un marcado de datos en función del valor de la columna pasada.
< GB > = < DF > . groupby ( col_key / s ) # Splits DF into groups based on passed column.
< DF > = < GB > . apply ( < func > ) # Maps each group. Func can return DF, S or el.
< DF > = < GB > . filter ( < func > ) # Drops a group if function returns False.
< DF > = < GB > . get_group ( < el > ) # Selects a group by grouping column's value.
< S > = < GB > . size () # S of group sizes. Same keys as get_group().
< GB > = < GB > [ col_key ] # Single column GB. All operations return S. < DF > = < GB > . sum / max / mean / idxmax / all () # Or: <GB>.agg(lambda <S>: <el>)
< DF > = < GB > . rank / diff / cumsum / ffill () # Or: <GB>.transform(lambda <S>: <S>)
< DF > = < GB > . fillna ( < el > ) # Or: <GB>.transform(lambda <S>: <S>) 'z' en RESET_INDEX ():: > >> df = pd . DataFrame ([[ 1 , 2 , 3 ], [ 4 , 5 , 6 ], [ 7 , 8 , 6 ]], list ( 'abc' ), list ( 'xyz' ))
> >> gb = df . groupby ( 'z' ); gb . apply ( print )
x y z
a 1 2 3
x y z
b 4 5 6
c 7 8 6
>> > gb . sum ()
x y
z
3 1 2
6 11 13Objeto para los cálculos de la ventana.
< RS / RDF / RGB > = < S / DF / GB > . rolling ( win_size ) # Also: `min_periods=None, center=False`.
< RS / RDF / RGB > = < RDF / RGB > [ col_key / s ] # Or: <RDF/RGB>.col_key
< S / DF > = < R > . mean / sum / max () # Or: <R>.apply/agg(<agg_func/str>) # $ pip3 install plotly kaleido pandas
import plotly . express as px , pandas as pd < Fig > = px . line ( < DF > , x = col_key , y = col_key ) # Or: px.line(x=<list>, y=<list>)
< Fig > . update_layout ( margin = dict ( t = 0 , r = 0 , b = 0 , l = 0 )) # Also `paper_bgcolor='rgb(0, 0, 0)'`.
< Fig > . write_html / json / image ( '<path>' ) # <Fig>.show() displays the plot. < Fig > = px . area / bar / box ( < DF > , x = col_key , y = col_key ) # Also `color=col_key`.
< Fig > = px . scatter ( < DF > , x = col_key , y = col_key ) # Also `color/size/symbol=col_key`.
< Fig > = px . scatter_3d ( < DF > , x = col_key , y = col_key , …) # `z=col_key`. Also color/size/symbol.
< Fig > = px . histogram ( < DF > , x = col_key [, nbins = < int > ]) # Number of bins depends on DF size. 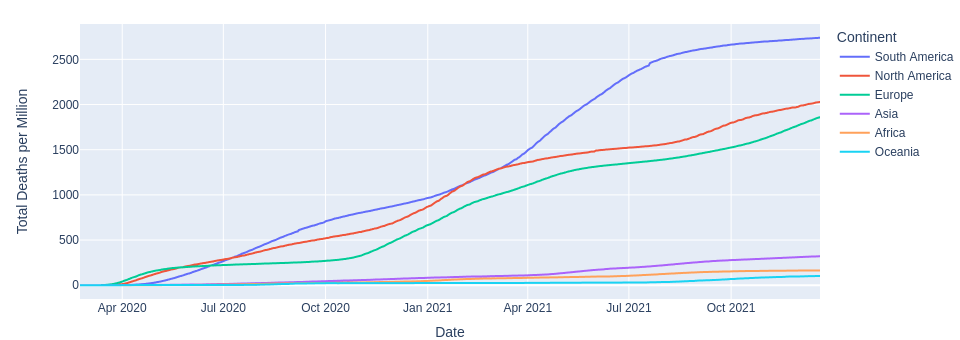
covid = pd . read_csv ( 'https://raw.githubusercontent.com/owid/covid-19-data/8dde8ca49b'
'6e648c17dd420b2726ca0779402651/public/data/owid-covid-data.csv' ,
usecols = [ 'iso_code' , 'date' , 'total_deaths' , 'population' ])
continents = pd . read_csv ( 'https://gto76.github.io/python-cheatsheet/web/continents.csv' ,
usecols = [ 'Three_Letter_Country_Code' , 'Continent_Name' ])
df = pd . merge ( covid , continents , left_on = 'iso_code' , right_on = 'Three_Letter_Country_Code' )
df = df . groupby ([ 'Continent_Name' , 'date' ]). sum (). reset_index ()
df [ 'Total Deaths per Million' ] = df . total_deaths * 1e6 / df . population
df = df [ df . date > '2020-03-14' ]
df = df . rename ({ 'date' : 'Date' , 'Continent_Name' : 'Continent' }, axis = 'columns' )
px . line ( df , x = 'Date' , y = 'Total Deaths per Million' , color = 'Continent' ). show ()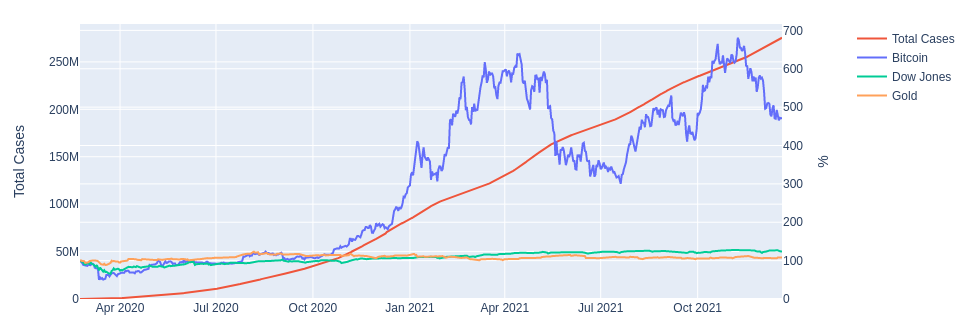
import pandas as pd , plotly . graph_objects as go
def main ():
covid , bitcoin , gold , dow = scrape_data ()
df = wrangle_data ( covid , bitcoin , gold , dow )
display_data ( df )
def scrape_data ():
def get_covid_cases ():
url = 'https://covid.ourworldindata.org/data/owid-covid-data.csv'
df = pd . read_csv ( url , usecols = [ 'location' , 'date' , 'total_cases' ])
df = df [ df . location == 'World' ]
return df . set_index ( 'date' ). total_cases
def get_ticker ( symbol ):
url = ( f'https://query1.finance.yahoo.com/v7/finance/download/ { symbol } ?'
'period1=1579651200&period2=9999999999&interval=1d&events=history' )
df = pd . read_csv ( url , usecols = [ 'Date' , 'Close' ])
return df . set_index ( 'Date' ). Close
out = get_covid_cases (), get_ticker ( 'BTC-USD' ), get_ticker ( 'GC=F' ), get_ticker ( '^DJI' )
names = [ 'Total Cases' , 'Bitcoin' , 'Gold' , 'Dow Jones' ]
return map ( pd . Series . rename , out , names )
def wrangle_data ( covid , bitcoin , gold , dow ):
df = pd . concat ([ bitcoin , gold , dow ], axis = 1 ) # Creates table by joining columns on dates.
df = df . sort_index (). interpolate () # Sorts rows by date and interpolates NaN-s.
df = df . loc [ '2020-02-23' :] # Discards rows before '2020-02-23'.
df = ( df / df . iloc [ 0 ]) * 100 # Calculates percentages relative to day 1.
df = df . join ( covid ) # Adds column with covid cases.
return df . sort_values ( df . index [ - 1 ], axis = 1 ) # Sorts columns by last day's value.
def display_data ( df ):
figure = go . Figure ()
for col_name in reversed ( df . columns ):
yaxis = 'y1' if col_name == 'Total Cases' else 'y2'
trace = go . Scatter ( x = df . index , y = df [ col_name ], name = col_name , yaxis = yaxis )
figure . add_trace ( trace )
figure . update_layout (
yaxis1 = dict ( title = 'Total Cases' , rangemode = 'tozero' ),
yaxis2 = dict ( title = '%' , rangemode = 'tozero' , overlaying = 'y' , side = 'right' ),
legend = dict ( x = 1.08 ),
width = 944 ,
height = 423
)
figure . show ()
if __name__ == '__main__' :
main ()Biblioteca que compila el código similar a Python en C.
# $ pip3 install cython
import pyximport ; pyximport . install () # Module that runs imported Cython scripts.
import < cython_script > # Script needs a '.pyx' extension.
< cython_script > . main () # Main() isn't automatically executed. 'cdef' son opcionales, pero contribuyen a la aceleración.'*' y '&' , estructuras, sindicatos y enumines. cdef < ctype / type > < var_name > [ = < obj > ]
cdef < ctype > [ n_elements ] < var_name > [ = < coll_of_nums > ]
cdef < ctype / type / void > < func_name > ( < ctype / type > < arg_name > ): ... cdef class < class_name > :
cdef public < ctype / type > < attr_name >
def __init__ ( self , < ctype / type > < arg_name > ):
self . < attr_name > = < arg_name >Sistema para instalar bibliotecas directamente en el directorio del proyecto.
$ python3 -m venv NAME # Creates virtual environment in current directory.
$ source NAME/bin/activate # Activates env. On Windows run `NAMEScriptsactivate`.
$ pip3 install LIBRARY # Installs the library into active environment.
$ python3 FILE # Runs the script in active environment. Also `./FILE`.
$ deactivate # Deactivates the active virtual environment. Ejecute el script con '$ python3 FILE' o '$ chmod u+x FILE; ./FILE' . Para iniciar automáticamente el depurador cuando se produce la excepción no captura, ejecute '$ python3 -m pdb -cc FILE' .
#!/usr/bin/env python3
#
# Usage: .py
#
from sys import argv , exit
from collections import defaultdict , namedtuple
from dataclasses import make_dataclass
from enum import Enum
import functools as ft , itertools as it , operator as op , re
def main ():
pass
###
## UTIL
#
def read_file ( filename ):
with open ( filename , encoding = 'utf-8' ) as file :
return file . readlines ()
if __name__ == '__main__' :
main ()'#<title>' en la página web limitará la búsqueda a los títulos.'?' Para obtener un enlace a su sección.

