bean searcher
v4.3.5

Inglés | 中文
Documentación: https://bs.zhxu.cn
Primera página : https://www.aliyun.com/minisite/goods?userCode=zugtbi5w
Blogs de JueJin:
Solo una línea de código para lograr:
Pensamiento de diseño: el pensamiento de Bean Searcher
Arquitectura:
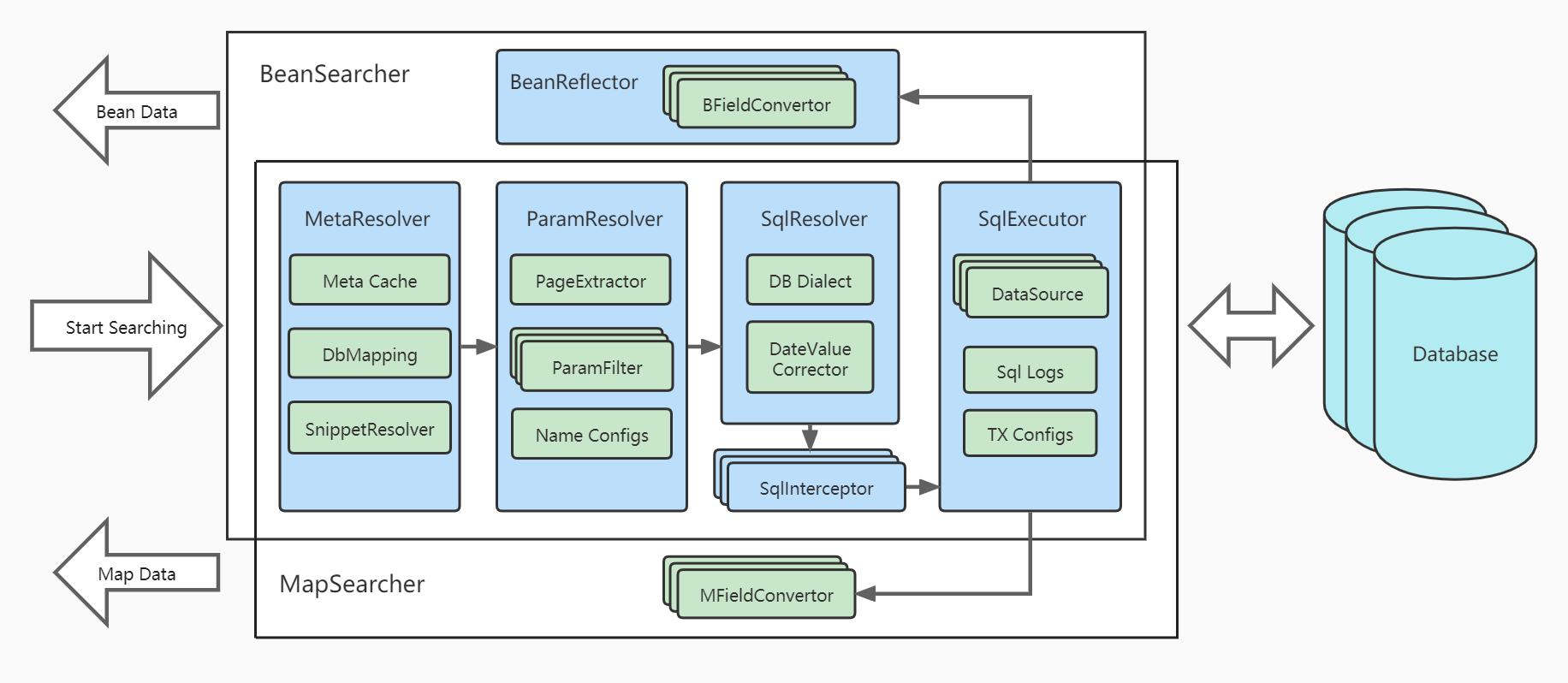
Aunque CREAR/ACTUALIZAR/ELIMINAR son los puntos fuertes de Hibernate, MyBatis, DataJDBC y otros ORM, las consultas, especialmente las consultas de listas complejas con múltiples condiciones , múltiples tablas , paginación y clasificación , siempre han sido sus debilidades.
Es difícil que el ORM tradicional realice una recuperación de lista compleja con menos código, pero Bean Searcher ha hecho grandes esfuerzos en este sentido. Estas consultas complejas se pueden resolver en casi una línea de código.
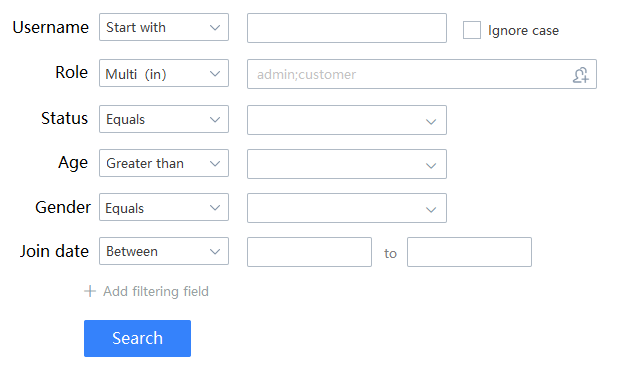
El back-end necesita escribir una API de recuperación y, si se escribe con ORM tradicional, la complejidad del código es muy alta.
Pero Bean Searcher puede:
Primero, tienes una clase de Entidad:
@ SearchBean ( tables = "user u, role r" , joinCond = "u.role_id = r.id" , autoMapTo = "u" )
public class User {
private long id ;
private String username ;
private int status ;
private int age ;
private String gender ;
private Date joinDate ;
private int roleId ;
@ DbField ( "r.name" )
private String roleName ;
// Getters and setters...
}Luego puedes completar la API con una línea de código:
@ RestController
@ RequestMapping ( "/user" )
public class UserController {
@ Autowired
private BeanSearcher beanSearcher ; // Inject BeanSearcher
@ GetMapping ( "/index" )
public SearchResult < User > index ( HttpServletRequest request ) {
// Only one line of code written here
return beanSearcher . search ( User . class , MapUtils . flat ( request . getParameterMap ()), new String []{ "age" });
}
}Esta línea de código puede lograr:
agePor ejemplo, esta API se puede solicitar de la siguiente manera:
GET: /user/index
Recuperando la paginación por defecto:
{
"dataList" : [
{
"id" : 1 ,
"username" : " Jack " ,
"status" : 1 ,
"age" : 25 ,
"gender" : " Male " ,
"joinDate" : " 2021-10-01 " ,
"roleId" : 1 ,
"roleName" : " User "
},
... // 15 records default
],
"totalCount" : 100 ,
"summaries" : [
2500 // age statistics
]
} GET: /user/index? page=1 & size=10
Recuperación por paginación especificada
GET: /user/index? status=1
Recuperación con status = 1 por paginación predeterminada
GET: /user/index? name=Jac & name-op=sw
Recuperación con name que comienza con Jac por paginación predeterminada
GET: /user/index? name=Jack & name-ic=true
Recuperación con name = Jack (caso ignorado) por paginación predeterminada
GET: /user/index? sort=age & order=desc
Clasificación de recuperación por age descendente y paginación predeterminada
GET: /user/index? onlySelect=username,age
Recuperación de username,age solo por paginación predeterminada:
{
"dataList" : [
{
"username" : " Jack " ,
"age" : 25 ,
},
... // 15 records default
],
"totalCount" : 100 ,
"summaries" : [
2500 // age statistics
]
} GET: /user/index? selectExclude=joinDate
Recuperando la paginación predeterminada excluida joinDate
Map < String , Object > params = MapUtils . builder ()
. selectExclude ( User :: getJoinDate ) // Exclude joinDate field
. field ( User :: getStatus , 1 ) // Filter:status = 1
. field ( User :: getName , "Jack" ). ic () // Filter:name = 'Jack' (case ignored)
. field ( User :: getAge , 20 , 30 ). op ( Opetator . Between ) // Filter:age between 20 and 30
. orderBy ( User :: getAge , "asc" ) // Sorting by age ascending
. page ( 0 , 15 ) // Pagination: page=0 and size=15
. build ();
List < User > users = beanSearcher . searchList ( User . class , params );Demostraciones :
¡Usar Bean Searcher puede ahorrar enormemente el tiempo de desarrollo de las complejas API de recuperación de listas!
domain original, sin definir una nueva EntityBean Searcher puede funcionar con cualquier marco JavaWeb, como: SpringBoot, SpringMVC, Grails, Jfinal, etc.
Todo lo que necesitas es agregar una dependencia:
implementation ' cn.zhxu:bean-searcher-boot-stater:4.3.4 ' y luego puedes inyectar Searcher en un Controller o Service :
/**
* Inject a MapSearcher, which retrieved data is Map objects
*/
@Autowired
private MapSearcher mapSearcher;
/**
* Inject a BeanSearcher, which retrieved data is generic objects
*/
@Autowired
private BeanSearcher beanSearcher;Todo lo que necesitas es agregar una dependencia:
implementation ' cn.zhxu:bean-searcher-solon-plugin:4.3.4 ' y luego puedes inyectar Searcher en un Controller o Service :
/**
* Inject a MapSearcher, which retrieved data is Map objects
*/
@Inject
private MapSearcher mapSearcher;
/**
* Inject a BeanSearcher, which retrieved data is generic objects
*/
@Inject
private BeanSearcher beanSearcher;Añadiendo esta dependencia:
implementation ' cn.zhxu:bean-searcher:4.3.4 ' entonces puedes crear un Searcher con SearcherBuilder :
DataSource dataSource = ... // Get the dataSource of the application
// DefaultSqlExecutor suports multi datasources
SqlExecutor sqlExecutor = new DefaultSqlExecutor ( dataSource );
// build a MapSearcher
MapSearcher mapSearcher = SearcherBuilder . mapSearcher ()
. sqlExecutor ( sqlExecutor )
. build ();
// build a BeanSearcher
BeanSearcher beanSearcher = SearcherBuilder . beanSearcher ()
. sqlExecutor ( sqlExecutor )
. build ();Puede personalizar y ampliar cualquier componente en Bean Searcher.
Por ejemplo:
FieldOp para admitir a otros operadores de campoDbMapping para admitir anotaciones de otros ORMParamResolver para admitir parámetros de consulta JSONFieldConvertor para admitir cualquier tipo de campoDialect para admitir más bases de datosReferencia: https://bs.zhxu.cn
[ Sa-Token ]一个轻量级 Java 权限认证框架,让鉴权变得简单、优雅!
[ Fluent MyBatis ] MyBatis 语法增强框架, 综合了 MyBatisPlus, DynamicSql,Jpa 等框架的特性和优点,利用注解处理器生成代码
[ OkHttps ]轻量却强大的 HTTP 客户端,前后端通用,支持 WebSocket o Stomp 协议
[ hrun4j ]接口自动化测试解决方案 --工具选得好,下班回家早;测试用得对,半夜安心睡
[ JsonKit ]超轻量级 JSON 门面工具,用法简单,不依赖具体实现,让业务代码与 Jackson、Gson、Fastjson 等解耦!
[UI gratuita]基于 Vue3 + TypeScript,一个非常轻量炫酷的 UI 组件库!
git checkout -b feat/xxxxgit commit -am 'feat(function): add xxxxx'git push origin feat/xxxxpull request

