genai_robotics
1.0.0
Este repositorio contiene una configuración experimental consciente de la privacidad para aprovechar los métodos de IA generativa en el control de la robótica. Con la solución presentada aquí, un usuario puede definir libremente acciones mediante voz que se traducen en planes que un robot aspirador puede ejecutar en un entorno de mundo abierto observado por una cámara.
Las ventajas fundamentales de los métodos aquí presentados son:
El sistema se desarrolló en un hackathon de tres días como ejercicio de aprendizaje y prueba de concepto de que las herramientas modernas de inteligencia artificial pueden reducir significativamente el tiempo de desarrollo de soluciones de control robótico.
Para utilizar todas las funciones de este repositorio, esto es lo que debe tener:
Para comenzar, siga los pasos a continuación:
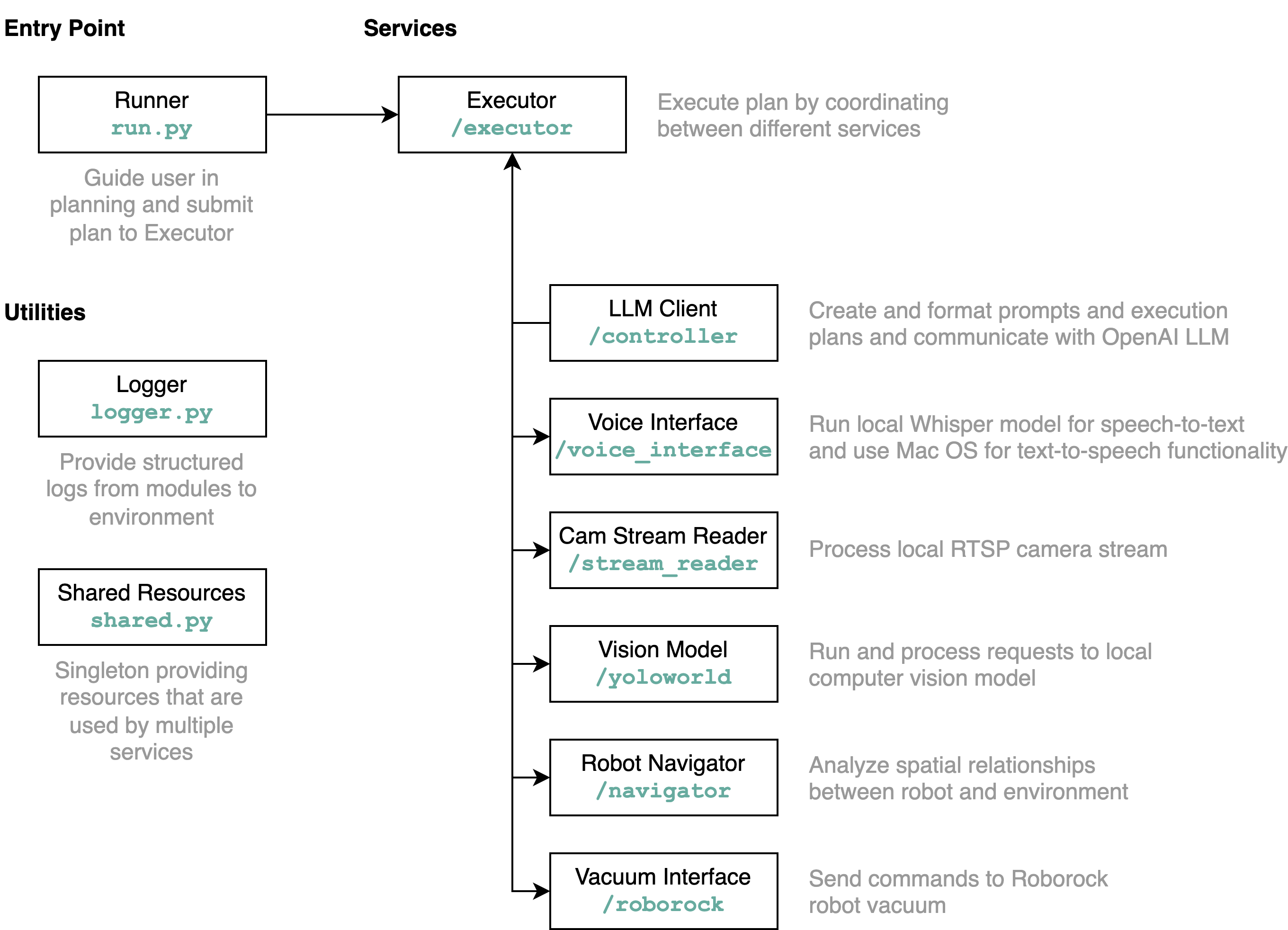
requirements.txt en un entorno Python (pruebas con Python 3.11)src/config.template.toml a config.toml . Para todos los pasos a continuación, inserte las credenciales adquiridas en config.tomlpython-roborock .src/run.py para ejecutar el flujo de trabajo. La mejor manera de comprender en detalle qué hace este repositorio y cómo interactúan los elementos es mediante un diagrama de arquitectura:
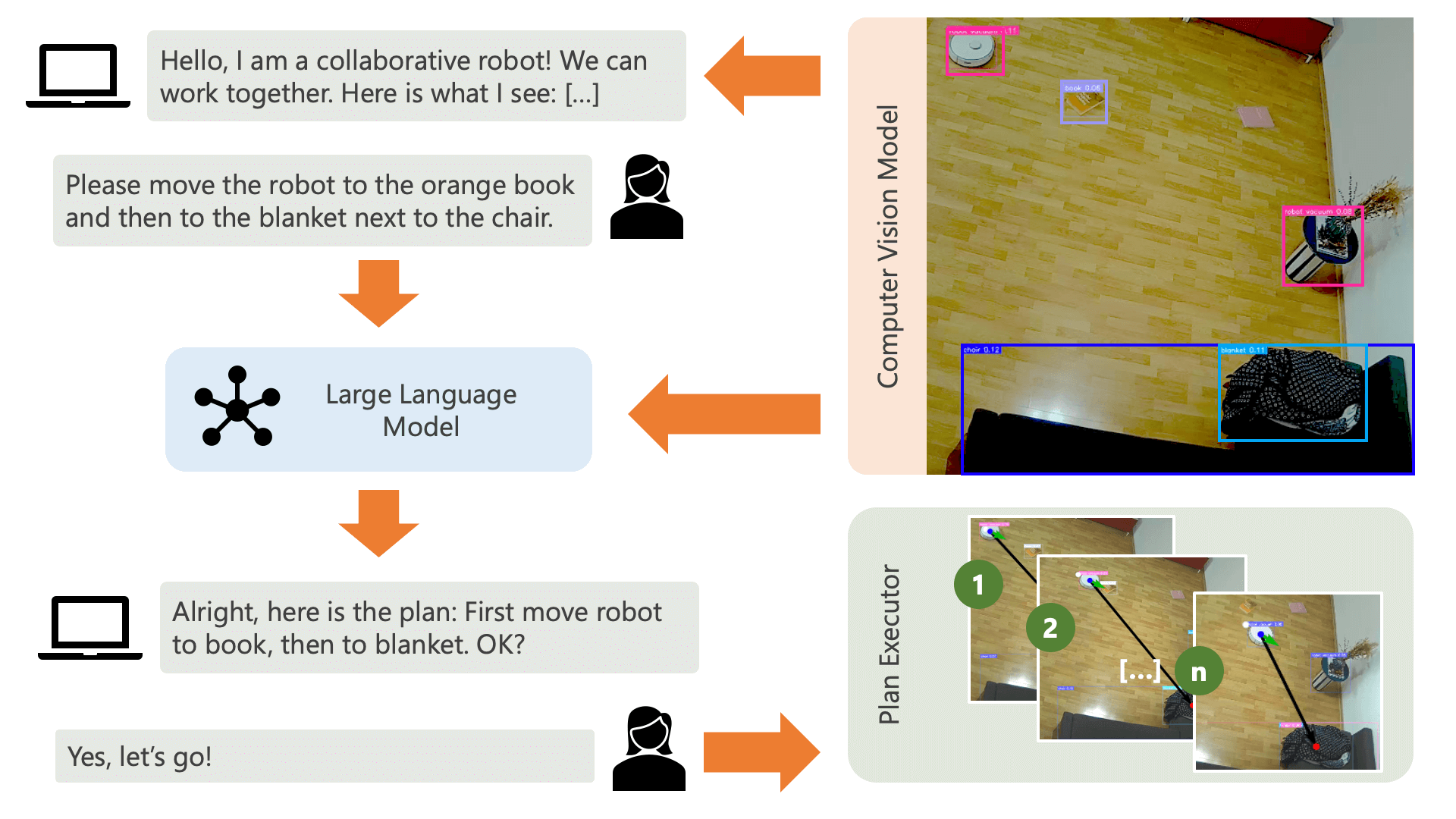
Cuando ejecuta el archivo run.py como se describe anteriormente, esto es lo que sucede y cómo funciona:
El sistema saluda al usuario con un mensaje de audio y espera que le diga al sistema lo que quiere hacer. Por ejemplo, un usuario podría querer que el robot tome un café de una persona que está sentada en una silla amarilla y lo transporte a otra persona que esté sentada en un sofá negro. Luego, el sistema crearía un plan para ejecutar estas acciones.
¿Qué necesita el sistema para entender cómo puede lograr lo que el usuario quiere hacer? El sistema necesita ser consciente de su entorno y de las acciones que se pueden ejecutar en este entorno. Aquí, utilizamos un modelo de visión por computadora con detección de objetos para proporcionar información sobre el entorno al sistema. La aspiradora en sí puede ejecutar 3 acciones simples: avanzar, girar y no hacer nada. Otra acción en el entorno está esperando que el usuario realice una determinada acción.
Para evitar confusión por parte del usuario, es importante que sepa cómo la IA percibe su entorno. Por ejemplo, si el modelo de visión por computadora no reconoce un objeto, la IA no podrá incluirlo en un plan. También es importante que el usuario sea consciente de que existe incertidumbre con respecto al reconocimiento de los modelos. Al utilizar el modelo de lenguaje grande GPT-4o de OpenAI con el mensaje de descripción, el sistema ofrece una explicación de su entorno y se la lee al usuario justo antes de preguntarle qué quiere que haga el sistema.
Dada la información del entorno y las aportaciones del usuario con respecto a lo que quieren hacer, el sistema puede elaborar un plan. Aquí, le pedimos al LLM que elabore un plan, teniendo en cuenta las aportaciones del usuario y la descripción del entorno. Puede encontrar la plantilla de aviso en el directorio controller . El truco interesante aquí es que el LLM solo conoce su entorno a través de dos tablas que se generan a partir de los resultados del modelo de visión por computadora. Aquí hay un ejemplo:
Item locations:
| id | label | position | confidence | color_rgb |
|-----:|:-------------|:----------------|-------------:|:----------------|
| 0 | robot vacuum | (122.0, 140.0) | 0.23 | [205, 206, 210] |
| 1 | blanket | (1697.0, 923.0) | 0.59 | [60, 72, 90] |
| 2 | chair | (532.5, 210.0) | 0.39 | [177, 177, 171] |
| 3 | chair | (160.0, 521.5) | 0.24 | [99, 99, 98] |
| 4 | book | (1216.5, 601.0) | 0.2 | [137, 141, 155] |
Distances:
| id | 0 | 1 | 2 | 3 | 4 |
|-----:|-----:|-----:|-----:|-----:|-----:|
| 0 | 0 | 1758 | 416 | 383 | 1187 |
| 1 | 1758 | 0 | 1365 | 1588 | 578 |
| 2 | 416 | 1365 | 0 | 485 | 787 |
| 3 | 383 | 1588 | 485 | 0 | 1059 |
| 4 | 1187 | 578 | 787 | 1059 | 0 |
Una vez que el LLM ha procesado el mensaje de planificación, genera dos cosas: el razonamiento y el plan. Antes de que el sistema proceda a ejecutar el plan, utilizará el mensaje de explicación para generar un breve resumen del plan con el fin de obtener la confirmación del usuario de que el plan coincide con lo que pidió hacer. Esto está en el espíritu de un enfoque humano en el circuito en el que operamos desde el punto de vista de que, en un entorno físico real y abierto, las personas pueden resultar potencialmente perjudicadas por las acciones de la IA, por lo que es razonable pedir ayuda humana. retroalimentación antes de que la IA proceda a ejecutar cualquier plan que se le haya ocurrido por sí misma.
Una vez que el usuario ha confirmado, el sistema procede a ejecutar el plan. Un plan de este tipo, generado por el LLM, podría verse así:
[
{ "action" : " MOVE " , "location" : [ 1216.5 , 601.0 ]},
{ "action" : " WAIT_UNTIL " , "task_fulfilled" : " Please place the book on the robot vacuum so that the robot can transport it to the chair. " },
{ "action" : " MOVE " , "location" : [ 532.5 , 210.0 ]},
{ "action" : " END " }
] Utilizando el executor , el sistema ejecuta el plan paso a paso. Para reducir el tiempo de configuración necesario, el control del robot sigue un algoritmo simple, inexacto pero eficaz:
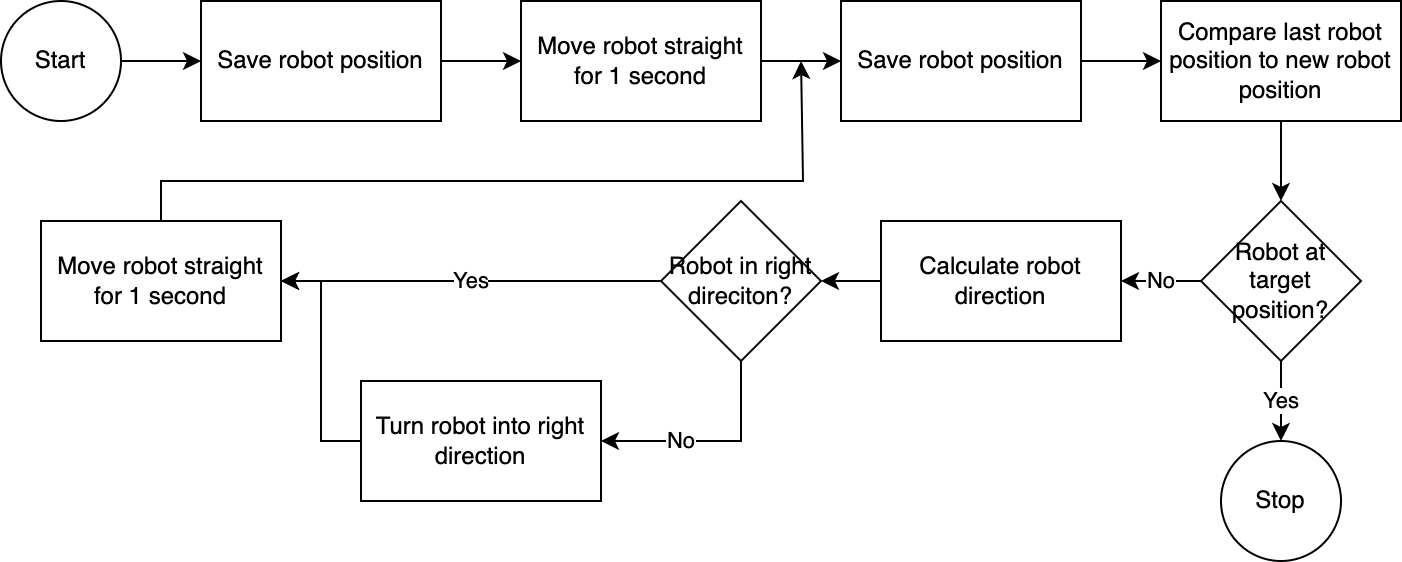
El sistema de visión por computadora evalúa la posición del robot. A través del código en el módulo navigator , se analiza y compara la posición del robot con respecto a su posición objetivo y con respecto a su última posición conocida. Este enfoque es imperfecto porque no se tienen en cuenta la posición y la distorsión de la lente de la cámara. Los ángulos medidos mediante este método son inexactos. Sin embargo, dado que el sistema es iterativo, los errores frecuentemente se compensan. Sin embargo, cabe señalar que esto tiene como coste la velocidad. El sistema es lento, ya que lleva tiempo analizar la imagen, calcular un camino e informar al robot de los próximos pasos a seguir.
Una vez que el robot ha alcanzado su posición objetivo, el ejecutor continúa con el siguiente paso del plan. Para acciones en las que está involucrada la entrada del usuario, el ejecutor utilizará la funcionalidad de texto a voz y de voz a texto para interactuar con el usuario.
En este sistema, utilizamos principalmente servicios que se ejecutan en una máquina o red local. La excepción es GPT-4o. Enviamos datos de texto al modelo de OpenAI a través de Internet. Los datos de texto incluyen entradas de usuario transcritas y una tabla de objetos reconocidos. La única razón por la que usamos GPT-4o aquí es porque es uno de los mejores modelos disponibles en el momento del hackathon; también podríamos ejecutar un LLM local y luego trabajar completamente sin conexión a Internet, preservando la privacidad entre todo el flujo de operaciones.
El modelo de visión por computadora incluido en este repositorio ha sido producido por el modelo YOLO-World en un espacio HuggingFace con el siguiente mensaje: chair, book, candle, blanket, vase, bulb, robot vacuum, mug, glass, human . Si desea reconocer objetos adicionales, ajuste el mensaje y descargue un modelo ONNX a través de este espacio. Luego puede reemplazar el modelo en el directorio src/yoloworld/models/rev0 .
Tenga en cuenta que para extraer el modelo correctamente, debe cambiar manualmente el número máximo de cuadros y los parámetros del umbral de puntuación en el espacio HuggingFace antes de exportar el modelo.
Puede obtener más información sobre el apasionante modelo YOLO-World, que se basa en avances recientes en el modelado de visión y lenguaje, en el sitio web de YOLO-World.
Este proyecto está publicado bajo la licencia MIT.
Este repositorio no está monitoreado activamente y no hay intención de ampliarlo; es ante todo un ejercicio de aprendizaje. Sin embargo, si se siente inspirado, no dude en contribuir al proyecto abriendo una incidencia de GitHub o una solicitud de extracción.


