full stack on prem cv mlops
1.0.0
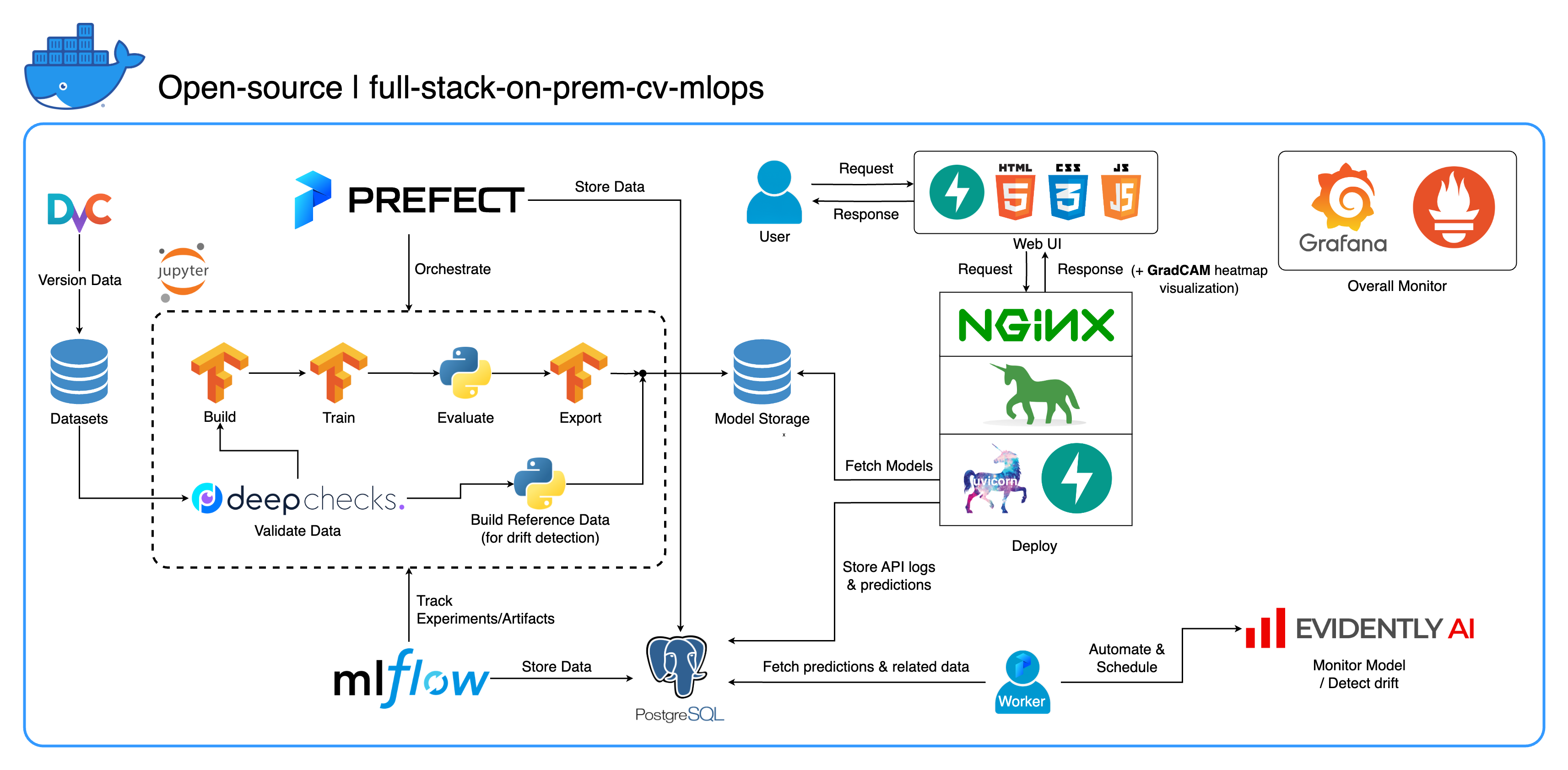
Bienvenido a nuestro completo ecosistema MLOps local diseñado específicamente para tareas de visión por computadora, con un enfoque principal en la clasificación de imágenes. Este repositorio le proporciona todo lo que necesita, desde un espacio de trabajo de desarrollo en Jupyter Lab/Notebook hasta servicios de nivel de producción. ¿La mejor parte? ¡Solo se necesita "1 configuración y 1 comando" para ejecutar todo el sistema desde la construcción del modelo hasta la implementación! Hemos integrado numerosas mejores prácticas para garantizar la escalabilidad y la confiabilidad manteniendo la flexibilidad. Si bien nuestro caso de uso principal gira en torno a la clasificación de imágenes, la estructura de nuestro proyecto puede adaptarse fácilmente a una amplia gama de desarrollos de ML/DL, ¡incluso pasando de las instalaciones a la nube!
Otro objetivo es mostrar cómo integrar todas estas herramientas y hacer que funcionen juntas en un sistema completo. Si está interesado en componentes o herramientas específicos, no dude en elegir lo que se adapte a las necesidades de su proyecto.
Todo el sistema está contenedorizado en un único archivo Docker Compose. Para configurarlo, ¡todo lo que tienes que hacer es ejecutar docker-compose up ! Este es un sistema completamente local, lo que significa que no es necesario tener una cuenta en la nube, ¡y no le costará ni un centavo usar todo el sistema!
Recomendamos encarecidamente ver los vídeos de demostración en la sección Vídeos de demostración para obtener una descripción general completa y comprender cómo aplicar este sistema a sus proyectos. Estos videos contienen detalles importantes que pueden ser demasiado largos y no lo suficientemente claros como para cubrirlos aquí.
Demostración: https://youtu.be/NKil4uzmmQc
Tutorial técnico detallado: https://youtu.be/l1S5tHuGBA8
Recursos en el vídeo:
Para utilizar este repositorio, solo necesitas Docker. Como referencia, utilizamos Docker versión 24.0.6, compilación ed223bc y Docker Compose versión v2.21.0-desktop.1 en Mac M1.
Hemos implementado varias mejores prácticas en este proyecto:
tf.data para TensorFlowimgaug lib para una mayor flexibilidad en las opciones de aumento que las funciones principales de TensorFlowos.env para configuraciones importantes o de nivel de serviciologging en lugar de print.env para variables en docker-compose.ymldefault.conf.template para que Nginx aplique elegantemente variables de entorno en la configuración de Nginx (nueva característica en Nginx 1.19)La mayoría de los puertos se pueden personalizar en el archivo .env en la raíz de este repositorio. Aquí están los valores predeterminados:
123456789 )[email protected] , contraseña: SuperSecurePwdHere )admin , contraseña: admin ) Debe considerar comentar esas líneas platform: linux/arm64 en docker-compose.yml si no usa una computadora basada en ARM (estamos usando Mac M1 para el desarrollo). De lo contrario, este sistema no funcionará.
--recurse-submodules en su comando: git clone --recurse-submodules https://github.com/jomariya23156/full-stack-on-prem-cv-mlopsdeploy en el servicio jupyter en docker-compose.yml y cambiar la imagen base en services/jupyter/Dockerfile de ubuntu:18.04 a nvidia/cuda:11.4.3-cudnn8-devel-ubuntu20.04 (el texto está en el archivo, solo necesitas comentar y descomentar) para aprovechar su(s) GPU(s). Es posible que también necesites instalar nvidia-container-toolkit en la máquina host para que funcione. Para los usuarios de Windows/WSL2, este artículo nos parece muy útil.docker-compose up o docker-compose up -d para desconectar el terminal.datasets/animals10-dvc y siga los pasos de la sección Cómo utilizar . http://localhost:8888/labcd ~/workspace/docker-compose.yml ) conda activate computer-viz-dlpython run_flow.py --config configs/full_flow_config.yamltasks .flows .run_flow.py en la raíz del repositorio.start(config) en su archivo de flujo. Esta función acepta la configuración como un dictado de Python y luego básicamente llama al flujo específico en ese archivo.datasets y todos deben tener la misma estructura de directorio que el que está dentro de este repositorio.central_storage en ~/ariya/ debe contener al menos 2 subdirectorios llamados models y ref_data . Este central_storage cumple con el propósito de almacenamiento de objetos de almacenar todos los archivos preparados para su uso en entornos de desarrollo e implementación. (Esta es una de las cosas que podría considerar cambiar a un servicio de almacenamiento en la nube en caso de que desee implementarlo en la nube y hacerlo más escalable)Convenciones IMPORTANTES que deben tener SÚPER CUIDADO si desea cambiar (porque estas cosas están vinculadas y utilizadas en diferentes partes del sistema):
central_storage -> Dentro debe haber models/ ref_data/ subdirectorios<model_name>.yaml , <model_name>_uae , <model_name>_bbsd , <model_name>_ref_data.parquetcurrent_model_metadata_file y monitor_pool_namecomputer-viz-dl (valor predeterminado), con todos los paquetes necesarios para este repositorio. Se supone que todos los comandos/códigos de Python se ejecutan dentro de este Jupyter.central_storage actúa como almacenamiento de archivos central utilizado durante el desarrollo y la implementación. Contiene principalmente archivos de modelo (incluidos detectores de deriva) y datos de referencia en formato Parquet. Al final del paso de entrenamiento del modelo, los nuevos modelos se guardan aquí y el servicio de implementación extrae los modelos de esta ubicación. ( Nota : este es un lugar ideal para reemplazarlo con servicios de almacenamiento en la nube para lograr escalabilidad).model en la configuración para crear un modelo de clasificador. El modelo está construido con TensorFlow y su arquitectura está codificada en tasks/model.py:build_model .dataset en la configuración para preparar un conjunto de datos para el entrenamiento. DvC se utiliza en este paso para verificar la coherencia de los datos en el disco en comparación con la versión especificada en la configuración. Si hay cambios, lo convierte nuevamente a la versión especificada mediante programación. Si desea conservar los cambios, en caso de que esté experimentando con el conjunto de datos, puede configurar el campo dvc_checkout en la configuración en falso para que DvC no haga sus cosas.train en la configuración para crear un cargador de datos e iniciar el proceso de capacitación. La información y los artefactos del experimento se rastrean y registran con MLflow . Nota: el informe de resultados (en un archivo .html ) de DeepChecks también se carga en el experimento de capacitación en MLflow para la convención.model en la configuración.central_storage (en este caso, solo se trata de hacer una copia en la ubicación de central_storage . Este es el paso que puede cambiar para cargar archivos en el almacenamiento en la nube)model/drift_detection en la configuración.central_storage .central_storage .central_storage . (Esta es una preocupación que se analiza en el vídeo de demostración del tutorial; mírelo para obtener más detalles)current_model_metadata_file que almacena el nombre del archivo de metadatos del modelo terminado en .yaml y monitor_pool_name que almacena el nombre del grupo de trabajo para implementar flujos y trabajadores de Prefect.cd en deployments/prefect-deployments y ejecute prefect --no-prompt deploy --name {deploy_name} usando entradas de la sección deploy/prefect en la configuración. Dado que todo ya está acoplado y contenedorizado en este repositorio, convertir el servicio de local a en la nube es bastante sencillo. Cuando termine de desarrollar y probar la API de su servicio, puede simplemente crear servicios/dl_service construyendo el contenedor desde su Dockerfile y enviarlo a un servicio de registro de contenedores en la nube (AWS ECR, por ejemplo). ¡Eso es todo!
Nota: Existe un problema potencial en el código de servicio si desea utilizarlo en un entorno de producción real. Lo he abordado en el vídeo en profundidad y te recomiendo que dediques un rato a ver el vídeo completo. 
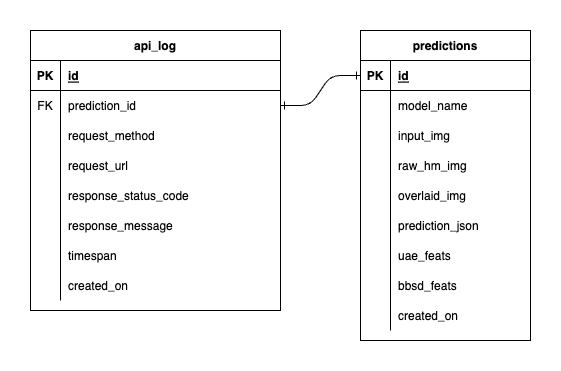
Tenemos tres bases de datos dentro de PostgreSQL: una para MLflow, otra para Prefect y una que hemos creado para nuestro servicio de modelo ML. No profundizaremos en los dos primeros, ya que son autogestionados por dichas herramientas. La base de datos para nuestro servicio de modelo ML es la que hemos diseñado nosotros mismos.
Para evitar una complejidad abrumadora, lo hemos mantenido simple con solo dos tablas. Las relaciones y atributos se muestran en el ERD a continuación. Básicamente, nuestro objetivo es almacenar detalles esenciales sobre las solicitudes entrantes y las respuestas de nuestro servicio. Todas estas tablas se crean y manipulan automáticamente, por lo que no necesita preocuparse por la configuración manual.
Cabe destacar: input_img , raw_hm_img y overlaid_img son imágenes codificadas en base64 almacenadas como cadenas. uae_feats y bbsd_feats son conjuntos de funciones integradas para nuestros algoritmos de detección de deriva.
ImportError: /lib/aarch64-linux-gnu/libGLdispatch.so.0: cannot allocate memory in static TLS block , intente export LD_PRELOAD=/lib/aarch64-linux-gnu/libGLdispatch.so.0 y luego vuelva a ejecutar su guion.

