GeoGuesser GenAI
Adivina el nombre del país a partir de los resultados generados por la IA
Este proyecto es una versión diferente del popular juego GeoGuessr en el que te ubican en una ubicación mundial aleatoria en Google Maps y tienes que adivinar la ubicación durante una cuenta regresiva. Aquí tendrás que adivinar el nombre del país basándose en sugerencias multimodales generadas por modelos de IA, puedes elegir entre 3 modalidades, texto que te brinda una descripción textual del país, imagen que te brinda una imagen que se asemeja al país y audio que te brinda una muestra de audio relacionada con el país.
Puede consultar una demostración en línea de esta aplicación en sus espacios HuggingFace. Esta demostración se limitó a generar solo sugerencias de imágenes por razones de rendimiento.
Si desea aprender un poco más sobre cómo funciona este proyecto y cómo se creó, consulte el artículo "Construcción de un GeoGuesser generativo basado en IA".
Flujo de trabajo
- Elija las modalidades de pistas deseadas.
- Elige el número de pistas para cada modalidad.
- Haz clic en el botón "Iniciar juego".
- Mire todas las sugerencias y escriba su conjetura en el campo "Conjetura de país".
- Haga clic en el botón "Adivinar".
Manifestación
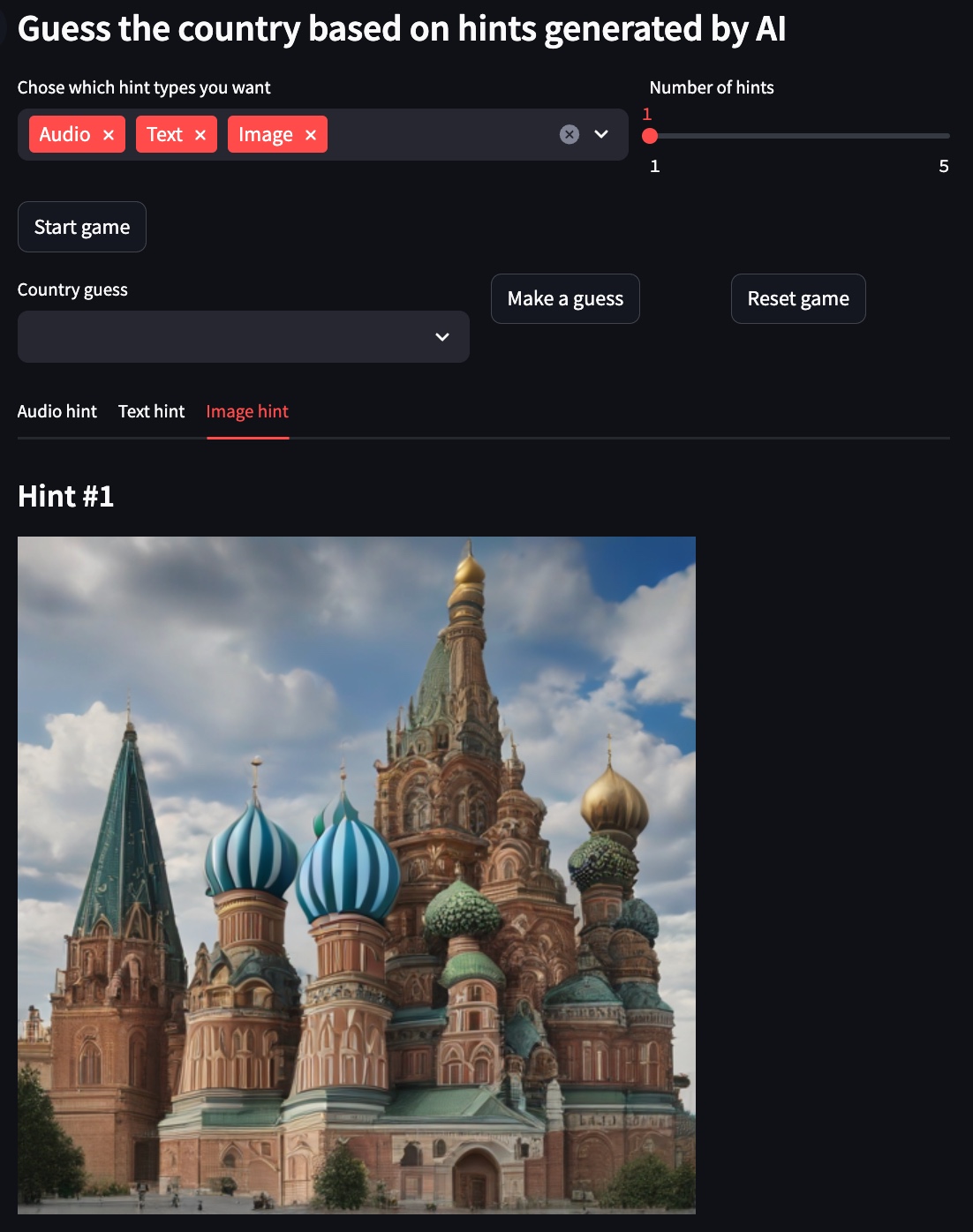
Para los ejemplos siguientes, el país elegido es Rusia .
Sugerencia de texto
Sugerencia de imagen
Pista de audio
Uso
El enfoque recomendado para usar este repositorio es con Docker, pero también puedes usar un venv personalizado, solo asegúrate de instalar todas las dependencias.
Configuraciones
local:
to_use: true
text:
model_id: google/gemma-1.1-2b-it
device: cpu
max_output_tokens: 50
temperature: 1
top_p: 0.95
top_k: 32
image:
model_id: stabilityai/sdxl-turbo
device: mps
num_inference_steps: 1
guidance_scale: 0.0
audio:
model_id: cvssp/audioldm2-music
device: cpu
num_inference_steps: 200
audio_length_in_s: 10
vertex:
to_use: false
project: {VERTEX_AI_PROJECT}
location: {VERTEX_AI_LOCALTION}
text:
model_id: gemini-1.5-pro-preview-0409
max_output_tokens: 50
temperature: 1
top_p: 0.95
top_k: 32
- local
- to_use: si el proyecto debe usar esta configuración de instalación
- texto
- model_id: modelo utilizado para crear las sugerencias de texto.
- dispositivo: Dispositivo utilizado por el modelo, generalmente uno de (cpu, cuda, mps)
- max_output_tokens: número máximo de tokens generados por el modelo
- temperatura: La temperatura controla el grado de aleatoriedad en la selección de tokens. Las temperaturas más bajas son buenas para indicaciones que esperan una respuesta verdadera o correcta, mientras que las temperaturas más altas pueden generar resultados más diversos o inesperados. Con una temperatura de 0, siempre se selecciona el token de mayor probabilidad.
- top_p: Top-p cambia la forma en que el modelo selecciona tokens para la salida. Los tokens se seleccionan del más probable al menos hasta que la suma de sus probabilidades sea igual al valor p superior. Por ejemplo, si los tokens A, B y C tienen una probabilidad de 0,3, 0,2 y 0,1 y el valor p superior es 0,5, entonces el modelo seleccionará A o B como el siguiente token (usando la temperatura). )
- top_k: Top-k cambia la forma en que el modelo selecciona tokens para la salida. Un top-k de 1 significa que el token seleccionado es el más probable entre todos los tokens en el vocabulario del modelo (también llamado decodificación codiciosa), mientras que un top-k de 3 significa que el siguiente token se selecciona entre los 3 tokens más probables ( usando temperatura)
- imagen
- model_id: modelo utilizado para crear las sugerencias de imagen.
- dispositivo: Dispositivo utilizado por el modelo, generalmente uno de (cpu, cuda, mps)
- num_inference_steps: número de pasos de inferencia para el modelo
- Guia_escala: obliga a la generación a coincidir mejor con el mensaje potencialmente a costa de la calidad o diversidad de la imagen.
- audio
- model_id: modelo utilizado para crear las sugerencias de audio.
- dispositivo: Dispositivo utilizado por el modelo, generalmente uno de (cpu, cuda, mps)
- num_inference_steps: número de pasos de inferencia para el modelo
- audio_length_in_s: duración de la pista de audio
- vértice
- to_use: si el proyecto debe usar esta configuración de instalación
- proyecto: nombre del proyecto utilizado por Vertex AI
- ubicación: ubicación del proyecto utilizada por Vertex AI
- texto
- model_id: modelo utilizado para crear las sugerencias de texto.
- max_output_tokens: número máximo de tokens generados por el modelo
- temperatura: La temperatura controla el grado de aleatoriedad en la selección de tokens. Las temperaturas más bajas son buenas para indicaciones que esperan una respuesta verdadera o correcta, mientras que las temperaturas más altas pueden generar resultados más diversos o inesperados. Con una temperatura de 0, siempre se selecciona el token de mayor probabilidad.
- top_p: Top-p cambia la forma en que el modelo selecciona tokens para la salida. Los tokens se seleccionan del más probable al menos hasta que la suma de sus probabilidades sea igual al valor p superior. Por ejemplo, si los tokens A, B y C tienen una probabilidad de 0,3, 0,2 y 0,1 y el valor p superior es 0,5, entonces el modelo seleccionará A o B como el siguiente token (usando la temperatura). )
- top_k: Top-k cambia la forma en que el modelo selecciona tokens para la salida. Un top-k de 1 significa que el token seleccionado es el más probable entre todos los tokens en el vocabulario del modelo (también llamado decodificación codiciosa), mientras que un top-k de 3 significa que el siguiente token se selecciona entre los 3 tokens más probables ( usando temperatura)
Comandos
Inicie la aplicación del juego.
Construya la imagen de Docker.
Aplique pelusa y formato al código (solo es necesario para el desarrollo).


