content dicovery platform gcp
1.0.0
Este repositorio contiene el código y la automatización necesarios para crear una plataforma de descubrimiento de contenido simple impulsada por los modelos fundamentales de VertexAI. Esta plataforma debe ser capaz de capturar el contenido de documentos (inicialmente Google Docs), y con ese contenido generar vectores incrustados para ser almacenados en una base de datos de vectores impulsada por VertexAI Matching Engine, posteriormente estas incrustaciones se pueden utilizar para contextualizar una pregunta general de un consumidor externo y con ese contexto solicita una respuesta a un modelo fundamental de VertexAI para obtener una respuesta.
La plataforma se puede separar en 4 componentes principales: capa de servicio de acceso, canal de captura de contenido, almacenamiento de contenido y LLM. La capa de servicios permite a los consumidores externos enviar solicitudes de ingesta de documentos y luego enviar consultas sobre el contenido incluido en los documentos previamente ingeridos. El canal de captura de contenido se encarga de capturar el contenido del documento en NRT, extraer incrustaciones y mapear esas incrustaciones con contenido real que luego puede usarse para contextualizar las preguntas de los usuarios externos a un LLM. El almacenamiento de contenido se divide en 3 propósitos diferentes, ajuste fino de LLM, emparejamiento de incrustaciones en línea y contenido fragmentado, cada uno de ellos manejado por un sistema de almacenamiento especializado y con el propósito general de almacenar la información que necesitan los componentes de la plataforma para implementar la ingesta y consulta. casos de uso. Por último, pero no menos importante, la plataforma hace uso de 2 LLM especializados para crear incrustaciones en tiempo real a partir del contenido del documento ingerido y otro encargado de generar las respuestas solicitadas por los usuarios de la plataforma.
Todos los componentes descritos anteriormente se implementan utilizando servicios GCP disponibles públicamente. Para enumerarlos: Cloud Build, Cloud Run, Cloud Dataflow, Cloud Pubsub, Cloud Storage, Cloud Bigtable, Vertex AI Matching Engine, modelos Vertex AI Fundational (incrustaciones y text-bison), junto con Google Docs y Google Drive como información de contenido. fuentes.
La siguiente imagen muestra cómo interactúan entre sí los diferentes componentes de la arquitectura y las tecnologías.
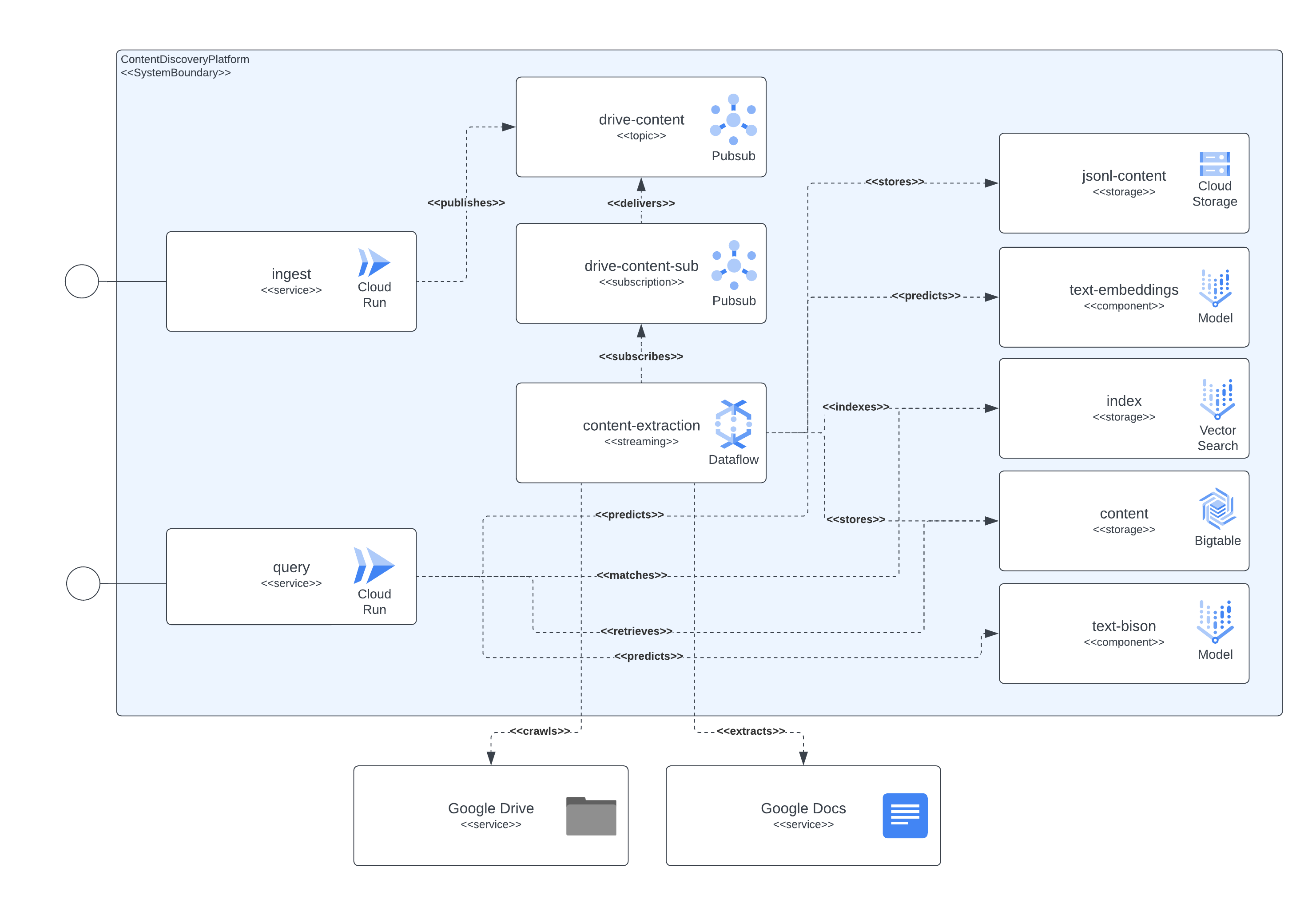
Esta plataforma utiliza Terraform para la configuración de todos sus componentes. Para aquellos que actualmente no tienen soporte nativo, hemos creado contenedores null_resource, estas son buenas soluciones, pero tienden a tener aspectos muy difíciles, así que tenga cuidado con los posibles errores.
La implementación completa a partir de hoy (junio de 2023) puede tardar hasta 90 minutos en completarse, siendo el mayor culpable los componentes relacionados con Matching Engine que tardan la mayor parte de ese tiempo en crearse y estar disponibles. Con el tiempo, estos tiempos de ejecución extendidos solo mejorarán.
La configuración debe ser ejecutable desde los scripts incluidos en el repositorio.
Se deben cumplir algunos requisitos para implementar esta plataforma, siendo estos:
Para tener todos los componentes implementados en GCP, necesitamos construir, crear infraestructura y luego implementar los servicios y canalizaciones.
Para lograr esto, incluimos el script start.sh que básicamente organiza los otros scripts incluidos para lograr el objetivo de implementación completa.
También hemos incluido un script cleanup.sh encargado de destruir la infraestructura y limpiar los datos recopilados.
En casos normales, los documentos de Google Workspace se crearán en la misma organización que aloja el proyecto donde se ejecuta la canalización de ingesta de contenido, por lo que para otorgar permisos a esos documentos se agrega la cuenta de servicio que ejecuta la canalización a los documentos o carpeta de documentos. , debería ser suficiente.
En caso de necesitar acceder a documentos o carpetas existentes fuera de la organización del proyecto se deberá realizar un paso adicional. Una vez configurada la infraestructura, el proceso de implementación imprimirá instrucciones para otorgar permisos a la cuenta de servicio que ejecuta el canal de extracción de contenido para hacerse pasar por el acceso a documentos de Google Workspace a través de la delegación de todo el dominio. La información para completar los pasos se puede ver aquí: https://developers.google.com/workspace/guides/create-credentials#optional_set_up_domain-wide_delegation_for_a_service_account
La solución expone un par de recursos a través de GCP CloudRun y API Gateway, que se pueden usar para interactuar para consultas de ingesta y descubrimiento de contenido. En todos los ejemplos utilizamos la cadena simbólica <service-address> , que debe reemplazarse por la URL proporcionada por CloudRun ( backend_service_url de la salida de Terraform) o API Gateway ( sevice_url de la salida de Terraform) una vez completada la implementación del servicio.
Cuando se necesitan interacciones CORS, se pueden usar los puntos finales de API Gateway para completar un protocolo de verificación previa. CloudRun actualmente no admite comandos OPTIONS no autenticados, pero las rutas expuestas a través de API Gateway sí los admiten.
Este servicio es capaz de ingerir datos de documentos alojados en Google Drive o solicitudes independientes de varias partes que contienen un identificador de documento y el contenido del documento codificado como binario.
La ingesta de Google Drive se realiza enviando una solicitud HTTP similar al siguiente ejemplo.
$ > curl -X POST -H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /ingest/content/gdrive
-d $' {"url":"https://docs.google.com/document/d/somevalid-googledocid"} ' Esta solicitud indicará a la plataforma que tome el documento de la url proporcionada y, en caso de que la cuenta de servicio que ejecuta la ingesta tenga permisos de acceso al documento, extraerá el contenido del mismo y almacenará la información para su indexación, su posterior descubrimiento y recuperación.
La solicitud puede contener la URL de un documento de Google o una carpeta de Google Drive; en el último caso, la ingesta rastreará la carpeta para procesar los documentos. Además, es posible utilizar las urls de propiedad que esperan un JSONArray de valores string , cada uno de ellos una URL válida de un documento de Google.
En el caso de querer incluir el contenido de un artículo, documento o página a la que el cliente de ingesta puede acceder localmente, usar el punto final multiparte debería ser suficiente para ingerir el documento. Vea el siguiente comando curl como ejemplo, el servicio espera que el campo del formulario documentId esté configurado para identificar e indexar de forma unívoca el contenido:
$ > curl -H " Authorization: Bearer $( gcloud auth print-identity-token ) "
-F documentId= < somedocid >
-F documentContent=@ < /some/local/directory/file/to/upload >
https:// < service-address > /ingest/content/multipartEste servicio expone la capacidad de consulta a los usuarios de la plataforma, enviando consultas de texto natural a los servicios y dado que ya hay índices de contenido después de la ingestión en la plataforma, el servicio regresará con información resumida por el modelo LLM.
La interacción con el servicio se puede realizar a través de un intercambio REST, similar a los de la parte de ingesta, como se ve en el siguiente ejemplo.
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"summarize the benefits of using VertexAI foundational models for Generative AI applications?", "sessionId": ""} '
| jq .
# response from service
{
"content": "VertexAI foundational models are a set of pre-trained models that can be used to build and deploy machine learning applications. They are available in a variety of languages and frameworks, and can be used for a variety of tasks, including natural language processing, computer vision, and recommendation systems.nnVertexAI foundational models are a good choice for Generative AI applications because they provide a starting point for building these types of applications. They can be used to quickly and easily create models that can generate text, images, and other types of content.nnIn addition, VertexAI foundational models are scalable and can be used to process large amounts of data. They are also reliable and can be used to create applications that are available 24/7.nnOverall, VertexAI foundational models are a powerful tool for building Generative AI applications. They provide a starting point for building these types of applications, and they can be used to quickly and easily create models that can generate text, images, and other types of content.",
" sourceLinks " : [
]
}Hay un caso especial aquí, donde aún no hay información almacenada para un tema en particular; si ese tema cae en el panorama de GCP, entonces el modelo actuará como un experto ya que configuramos un mensaje que lo indica a la solicitud del modelo.
En caso de querer tener un tipo de intercambio más consciente del contexto con el servicio, se debe proporcionar un identificador de sesión (propiedad sessionId en la solicitud JSON) para que el servicio lo use como clave de intercambio de conversación. Esta clave de conversación se utilizará para configurar el contexto adecuado para el modelo (resumiendo los intercambios anteriores) y realizando un seguimiento de los últimos 5 intercambios (al menos). También vale la pena señalar que el historial de intercambio se mantendrá durante 24 horas; esto se puede cambiar como parte de las políticas de gc del almacenamiento de BigTable en la plataforma.
A continuación, un ejemplo de una conversación contextual:
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"summarize the benefits of using VertexAI foundational models for Generative AI applications?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " VertexAI Foundational Models are a suite of pre-trained models that can be used to accelerate the development of Generative AI applications. These models are available in a variety of languages and domains, and they can be used to generate text, images, audio, and other types of content.nnUsing VertexAI Foundational Models can help you to:nn* Reduce the time and effort required to develop Generative AI applicationsn* Improve the accuracy and quality of your modelsn* Access the latest research and development in Generative AInnVertexAI Foundational Models are a powerful tool for developers who want to create innovative and engaging Generative AI applications. " ,
" sourceLinks " : [
]
}
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"describe the available LLM models?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " The VertexAI Foundational Models suite includes a variety of LLM models, including:nn* Text-to-text LLMs: These models can generate text based on a given prompt. They can be used for tasks such as summarization, translation, and question answering.n* Image-to-text LLMs: These models can generate text based on an image. They can be used for tasks such as image captioning and description generation.n* Audio-to-text LLMs: These models can generate text based on an audio clip. They can be used for tasks such as speech recognition and transcription.nnThese models are available in a variety of languages, including English, Spanish, French, German, and Japanese. They can be used to create a wide range of Generative AI applications, such as chatbots, customer service applications, and creative writing tools. " ,
" sourceLinks " : [
]
}
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"do rate limit apply for those LLMs?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " Yes, there are rate limits for the VertexAI Foundational Models. The rate limits are based on the number of requests per second and the total number of requests per day. For more information, please see the [VertexAI Foundational Models documentation](https://cloud.google.com/vertex-ai/docs/foundational-models#rate-limits). " ,
" sourceLinks " : [
]
}
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"care to share the price?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " The VertexAI Foundational Models are priced based on the number of requests per second and the total number of requests per day. For more information, please see the [VertexAI Foundational Models pricing page](https://cloud.google.com/vertex-ai/pricing#foundational-models). " ,
" sourceLinks " : [
]
}

