BigBertha
skeletal-integrations

BigBertha es un diseño de arquitectura que demuestra cómo se pueden lograr LLMOps (Operaciones de modelos de lenguaje grandes) automatizadas en cualquier clúster de Kubernetes utilizando tecnologías nativas de contenedores de código abierto.
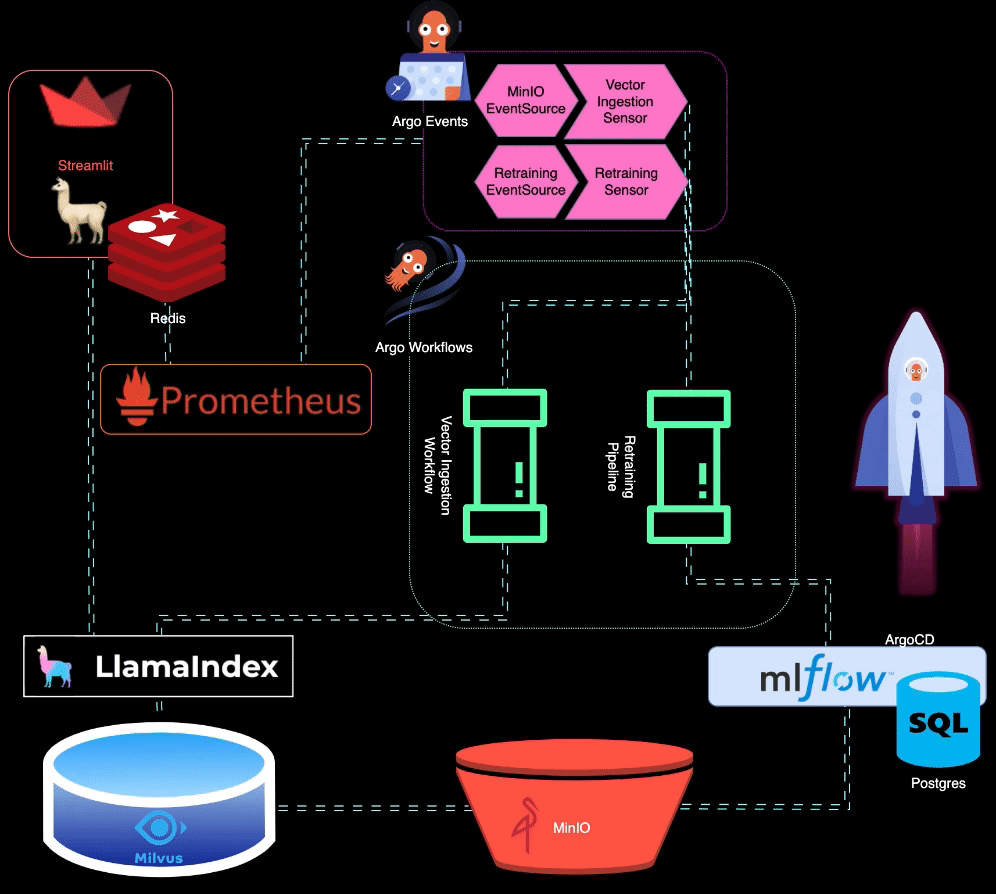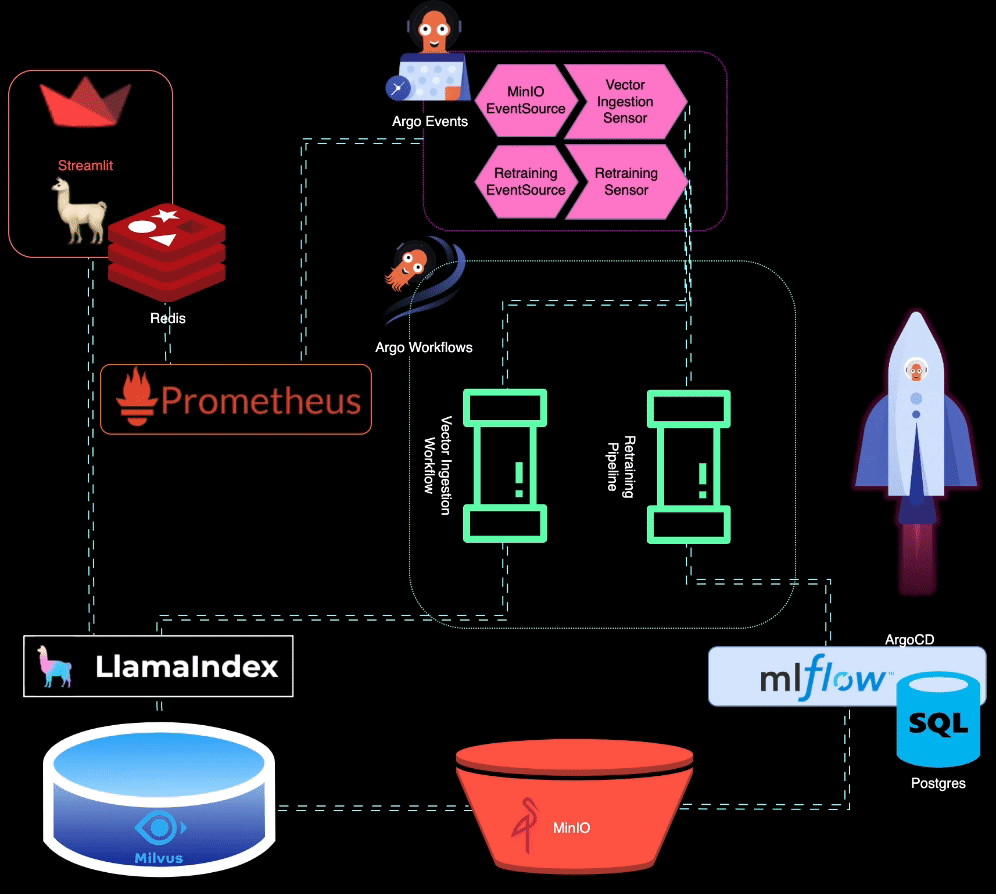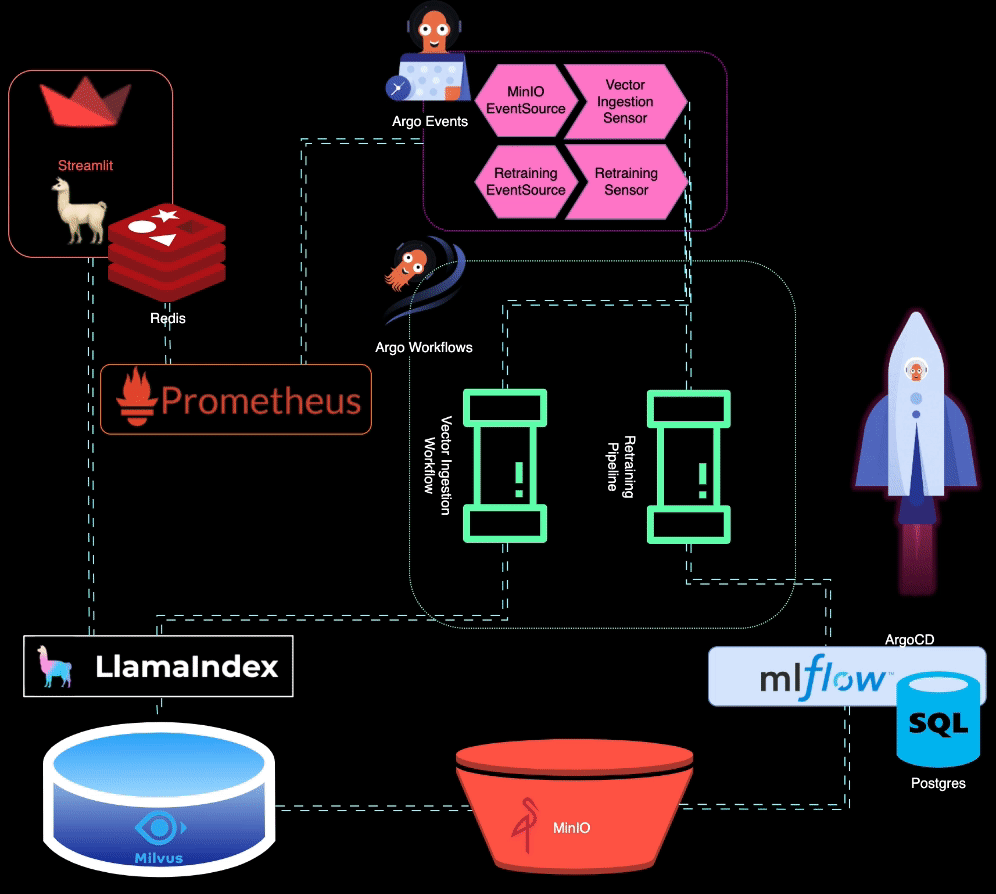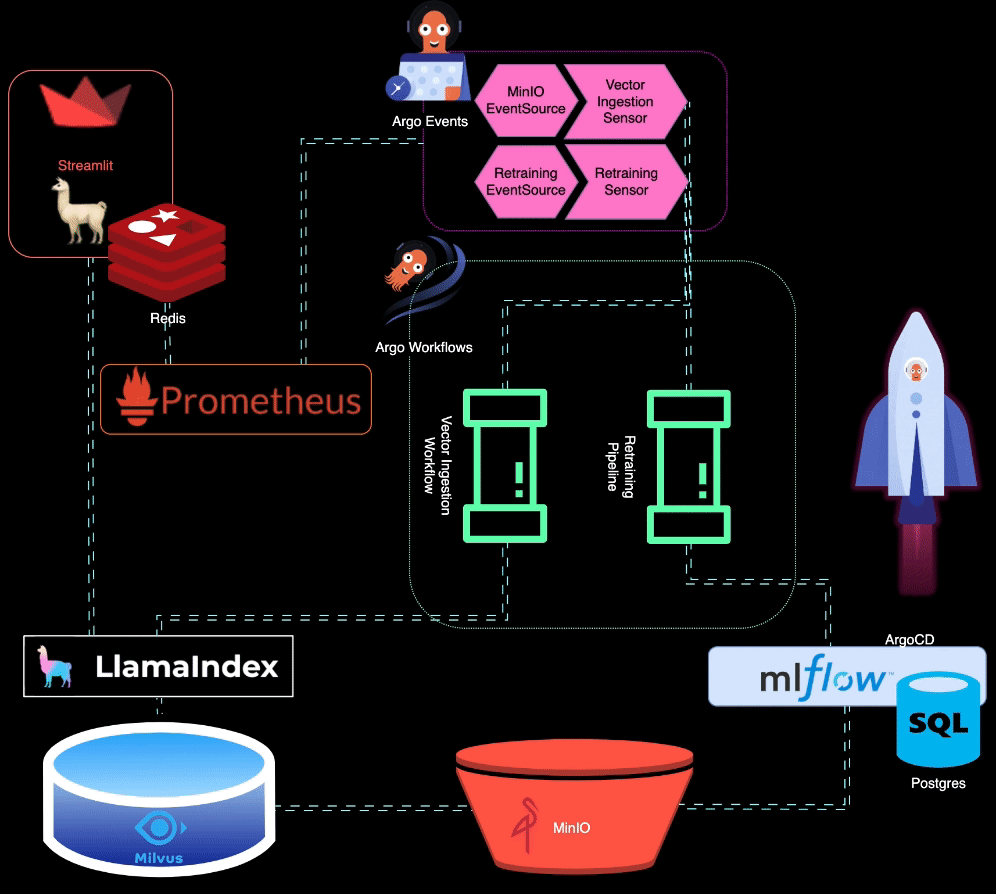
? BigBertha utiliza Prometheus para monitorear los módulos de servicio LLM (Large Language Model). Para fines de demostración, se utiliza una aplicación Streamlit para servir el LLM y Prometheus extrae métricas de ella. Las alertas se configuran para detectar la degradación del rendimiento.
Prometheus activa alertas cuando el rendimiento del modelo se degrada. Estas alertas son administradas por AlertManager, que utiliza Argo Events para activar un proceso de reentrenamiento para ajustar el modelo.
?️ El proceso de reentrenamiento se organiza mediante Argo Workflows. Este proceso se puede adaptar para realizar reentrenamiento, ajuste y seguimiento de métricas específicos de LLM. MLflow se utiliza para registrar el LLM reentrenado.
MinIO se utiliza para el almacenamiento de datos no estructurados. Argo Events está configurado para escuchar eventos de carga en MinIO, lo que activa un flujo de trabajo de ingesta de vectores cuando se cargan nuevos datos.
? Argo Workflows se utiliza para ejecutar una canalización de ingesta de vectores que utiliza LlamaIndex para generar e ingerir vectores. Estos vectores se almacenan en Milvus, que sirve como base de conocimientos para la generación de recuperación aumentada.
BigBertha se basa en varios componentes clave:
ArgoCD: una herramienta de entrega continua nativa de Kubernetes que gestiona todos los componentes de la pila BigBertha.
Argo Workflows: un motor de flujo de trabajo nativo de Kubernetes que se utiliza para ejecutar canalizaciones de ingesta de vectores y reentrenamiento de modelos.
Argo Events: un administrador de dependencias basado en eventos nativo de Kubernetes que conecta varias aplicaciones y componentes, desencadenando flujos de trabajo basados en eventos.
Prometheus + AlertManager: se utiliza para monitorear y alertar relacionados con el rendimiento del modelo.
LlamaIndex: un marco para conectar LLM y fuentes de datos, utilizado para la ingesta e indexación de datos.
Milvus: una base de datos de vectores nativa de Kubernetes para almacenar y consultar vectores.
MinIO: un sistema de almacenamiento de objetos de código abierto que se utiliza para almacenar datos no estructurados.
MLflow: una plataforma de código abierto para gestionar el ciclo de vida del aprendizaje automático, incluido el seguimiento de experimentos y la gestión de modelos.
Kubernetes: la plataforma de orquestación de contenedores que automatiza la implementación, el escalado y la gestión de aplicaciones en contenedores.
Contenedores Docker: los contenedores Docker se utilizan para empaquetar y ejecutar aplicaciones de manera consistente y reproducible.
A modo de demostración, BigBertha incluye un chatbot basado en Streamlit que sirve un modelo de chatbot cuantificado Llama2 7B. Se utiliza una aplicación Flask simple para exponer métricas y Redis actúa como intermediario entre los procesos Streamlit y Flask.
Este proyecto es de código abierto y se rige por los términos y condiciones descritos en el archivo de LICENCIA incluido en este repositorio.


