PersonalAIserver
1.0.0
Instale un servidor GenAI en su propio hardware disponible. Este proyecto proporciona una interfaz web para interactuar con modelos LLaMA y Difusión Estable (entre otros) para generación de texto, imágenes, video y 3D.
Mucha gente tiene una buena GPU a mano y está dispuesta a usarla en lugar de pagar suscripciones de OpenAI, Anthropic, etc. Aquí, puede alojar sus propios modelos de IA, aunque con muchas limitaciones en comparación con esos excelentes servicios. Luego, podrás acceder a él desde cualquier lugar con un navegador web, como tu teléfono u otra computadora.
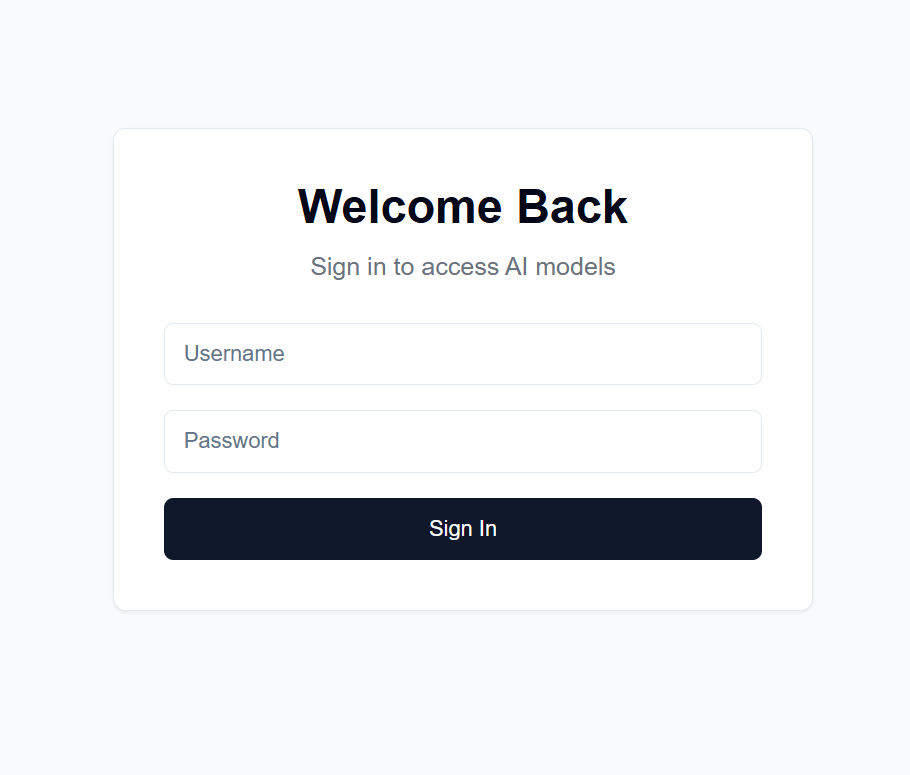
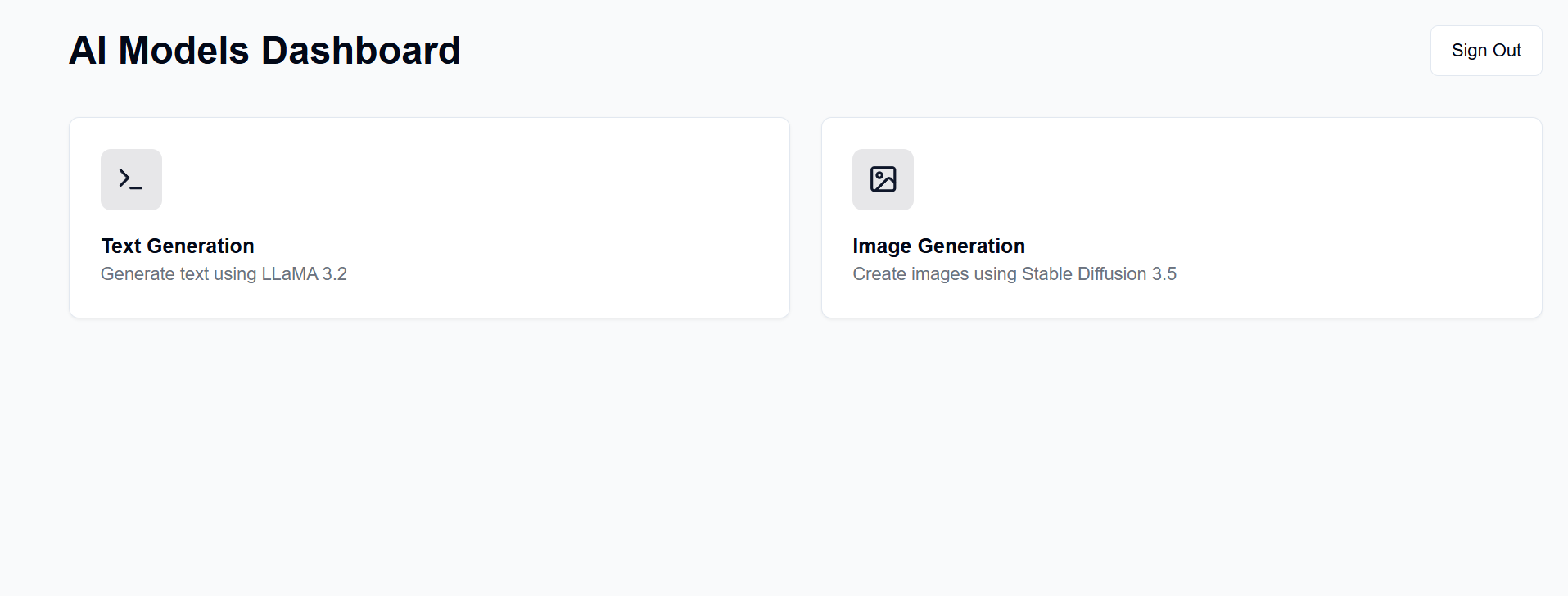
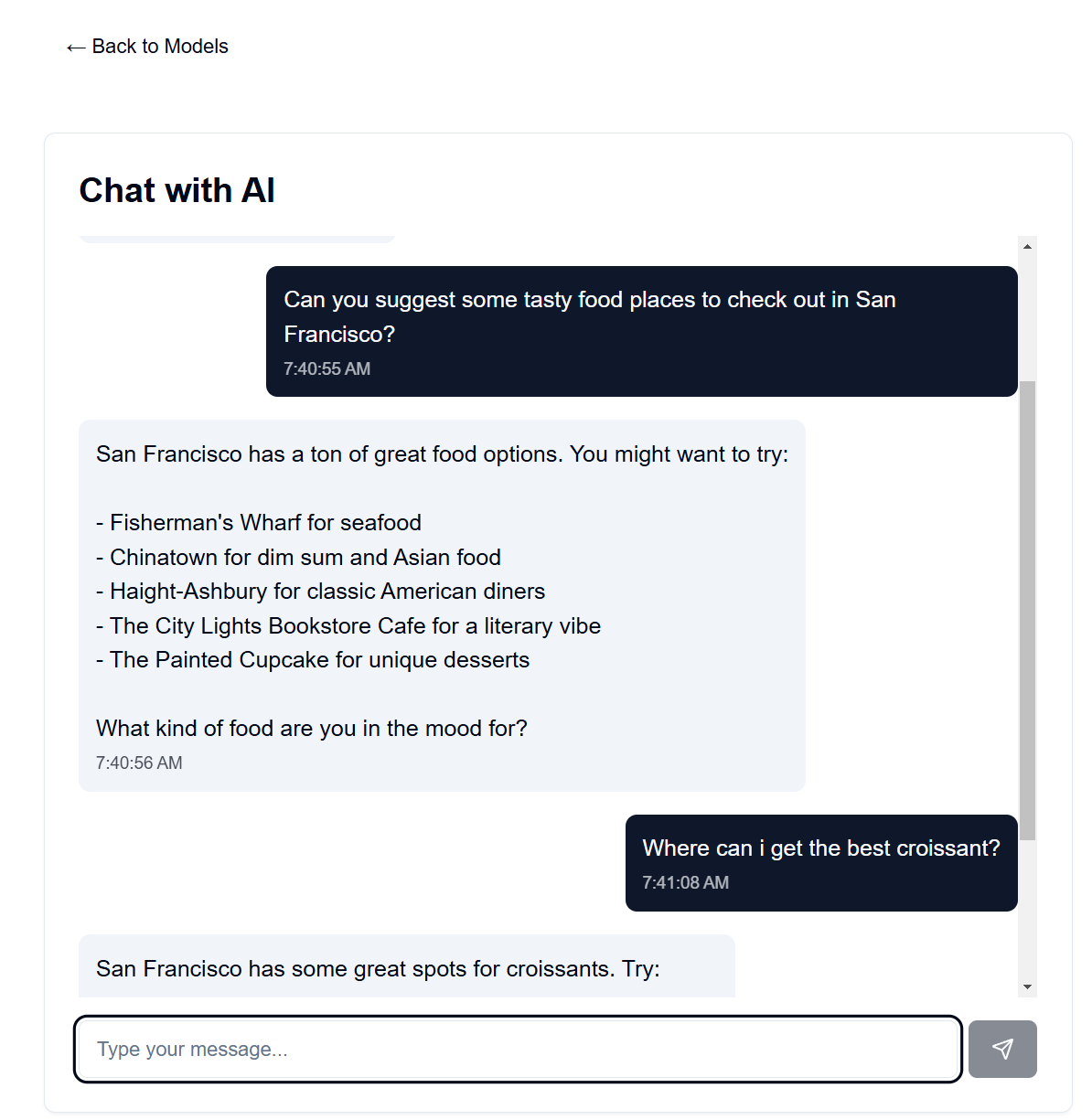
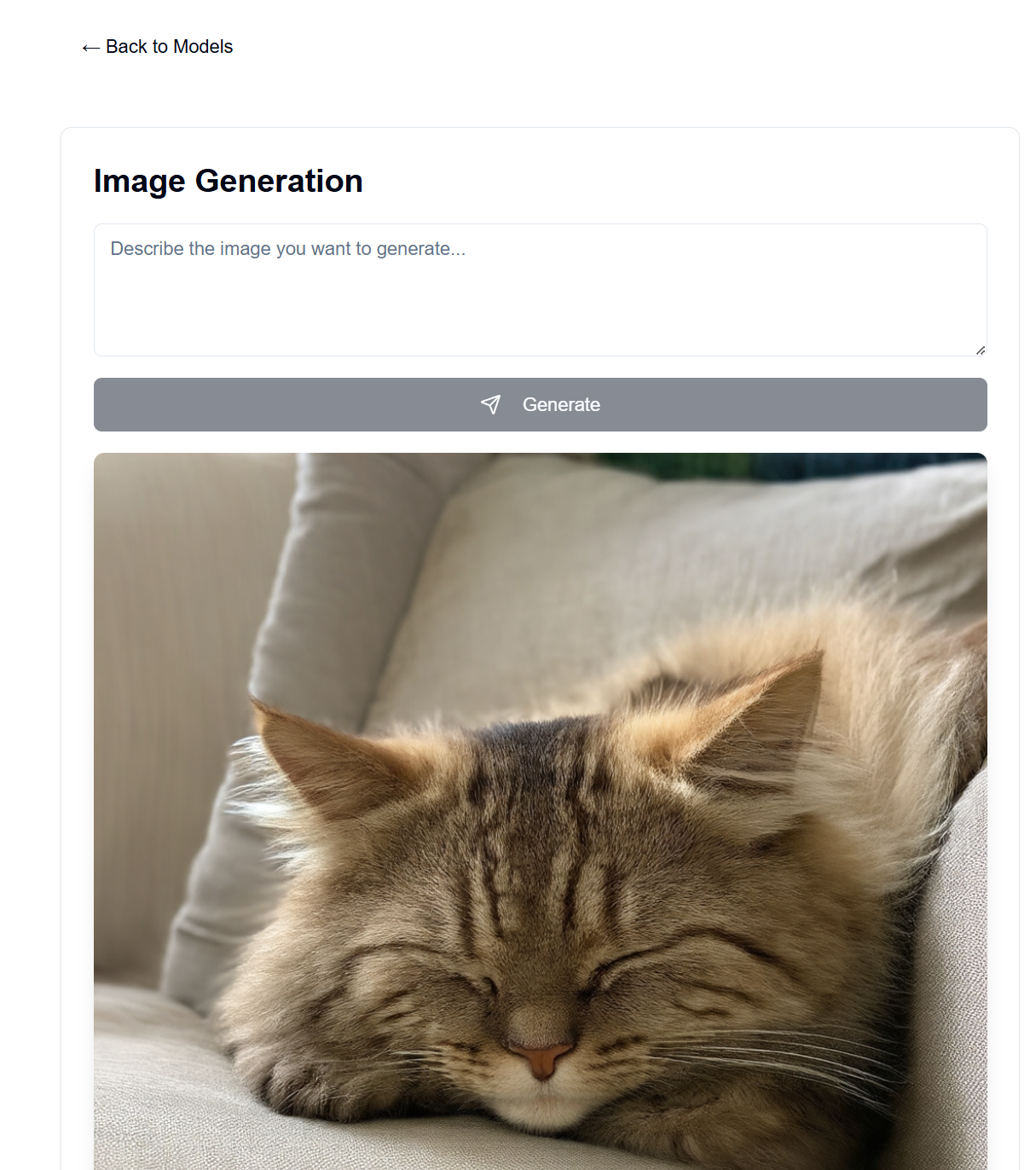
La interfaz para esto está alojada en GitHub Pages, mientras que el backend está alojado en su máquina servidor disponible.
Después de la configuración, la interfaz estará disponible en https://[username].github.io/PersonalAIserver . Siga las instrucciones a continuación para configurar el backend.
Para la interfaz, solo es necesario configurar una acción de GitHub para crear la página del proyecto. En su repositorio bifurcado, navegue hasta Settings -> Pages -> Source y configúrelo en "Acciones de GitHub". La compilación se ejecutará automáticamente cuando ingrese al repositorio, gracias al archivo .github/workflows/main.yml .
En caso de que desee ejecutar la interfaz localmente, siga las instrucciones a continuación. Requiere Node.js, instalable desde el administrador de versiones de nodo (nvm).
nvm install 20
npm install -D @shadcn/ui
npx shadcn@latest init # Select default style, any color, and dont use css variables.
npx shadcn@latest add alert button card input textarea # Accept defaults
npm install lucide-react
npm install -D @tailwindcss/typography
npm install clsx tailwind-merge
npm install
npm install sharp
npm run dev
Esto debería servir a la interfaz en http://localhost:3000 , a la que puede acceder con un navegador web.
Esto usa conda para la administración de paquetes, pero no dude en usar cualquier otro administrador de paquetes.
En su terminal en el directorio backend, ejecute los siguientes comandos:
conda create -n personalai python=3.11
conda activate personalai
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
pip install -r requirements.txt
users.json en el directorio backend con el siguiente formato: {
"username1": {
"username": "username1",
"password": "password1",
"disabled": false
},
"username2": {
"username": "username2",
"password": "password2",
"disabled": false
}
...
}
.secret en el directorio backend con una cadena aleatoria de su elección. Esto se utiliza para cifrar el token JWT. Recomiendo generar uno con: import secrets
secret_key = secrets.token_hex(32)
print(secret_key)
y luego copiar la salida.
Settings -> Secrets and variables -> Actions en su repositorio bifurcadoNEXT_PUBLIC_API_URL y el valor sea la URL del servidor backend (más detalles a continuación). Ejemplo: https://api.example.com .backend/backend.py , ajuste CORSMiddleware cerca de la línea 40 para incluir las URL de su interfaz.huggingface-cli login y use su token de acceso personal creado anteriormente como contraseña.python backend/backend.py --public o elimine --public si desea ejecutar el servidor solo en localhost. Localhost también requiere que ejecute la interfaz localmente.Existen muchas opciones para alojar el backend en una URL pública, pero recomiendo usar Cloudflare Tunnel. Cloudflare Tunnel enruta el tráfico de Internet a su servidor sin exponer un puerto o su IP local. También admite HTTPS, cifrado SSL y protección DDoS, entre otras características de seguridad que de otro modo necesitaría configurar y mantener usted mismo.
Otras opciones incluyen:
Para Cloudflare Tunnel, necesitará un nombre de dominio y una cuenta de Cloudflare.
cloudflared tunnel login . Este paso abre una ventana del navegador para iniciar sesión con su cuenta de Cloudflare.cloudflared tunnel create genai-api . Este paso genera una ID de túnel; tenga en cuenta esto para los próximos pasos. tunnel: <your-tunnel-id>
credentials-file: /home/user/.cloudflared/<tunnel-id>.json
ingress:
- hostname: <your-api-url>
service: http://localhost:8000
- service: http_status:404
<your-api-url> debe ser el nombre de dominio que ha registrado en los servidores de nombres de Cloudflare y puede ser un subdominio. Por ejemplo, si posee example.com , puede usar genai.example.com o api.example.com . 5. Cree un registro DNS cloudflared tunnel route dns <tunnel-id> <your-api-url> . Esto crea el túnel para que Cloudflare enrute el tráfico de Internet a su servidor sin exponer un puerto o su IP local.
En backend/backend.py , puede cambiar los modelos utilizados. Busque el modelo en Hugging Face que le gustaría usar para la generación de texto/imagen y ajuste las configuraciones del modelo ModelManager (línea ~127). De forma predeterminada, esto utiliza el modelo LLaMA 3.2-1B-Instruct para la generación de texto y el modelo medio Stable Diffusion 3.5 para la generación de imágenes. A continuación se detallan los requisitos de VRAM para cada modelo probado.
| Tipo de modelo | Nombre del modelo | Uso de VRAM (GB) | Notas |
|---|---|---|---|
| Texto | meta-llama/Llama-3.2-1B-Instruir | ~8 | Modelo base para generación de texto. |
| Imagen | estabilidadai/difusión-estable-3.5-medio | ~13 | Funciona bien en RTX 4090 |
| Imagen | estabilidadai/difusión-estable-3.5-grande | ~20-30 | Supera los 4090 VRAM para indicaciones largas |
Nota: El uso de VRAM puede variar según la resolución de la imagen, la longitud de las indicaciones de texto y otros parámetros. Los valores mostrados son aproximados para la configuración predeterminada. Se admiten modelos de transformadores cuantificados para reducir aún más el uso de VRAM, pero no se utilizan de forma predeterminada (consulte backend/backend.py líneas 178-192). El gran modelo de difusión estable apenas cabe en la VRAM de mi 4090 con cuantificación. Las velocidades del chatbot son extremadamente rápidas en mi 4090, y la generación de imágenes tarda hasta 30 segundos en 100 pasos para imágenes de 1024x1024.
El mensaje del sistema para el modelo de lenguaje se puede encontrar en backend/system_prompt.txt . Por el momento, es una versión del modelo Claude 3.5 Sonnet de Anthropic, lanzado el 22 de octubre de 2024. https://docs.anthropic.com/en/release-notes/system-prompts#claude-3-5-sonnet


