cassandra lucene index
2.1.20.0
Cassandra Lucene Index de Stratio, derivado de Stratio Cassandra, es un complemento para Apache Cassandra que amplía su funcionalidad de índice para proporcionar búsquedas casi en tiempo real, como ElasticSearch o Solr, incluidas capacidades de búsqueda de texto completo y búsqueda multivariable, geoespacial y bitemporal gratuita. Se logra mediante una implementación basada en Apache Lucene de índices secundarios de Cassandra, donde cada nodo del clúster indexa sus propios datos. Los índices Cassandra de Stratio son uno de los módulos principales en los que se basa la plataforma BigData de Stratio.
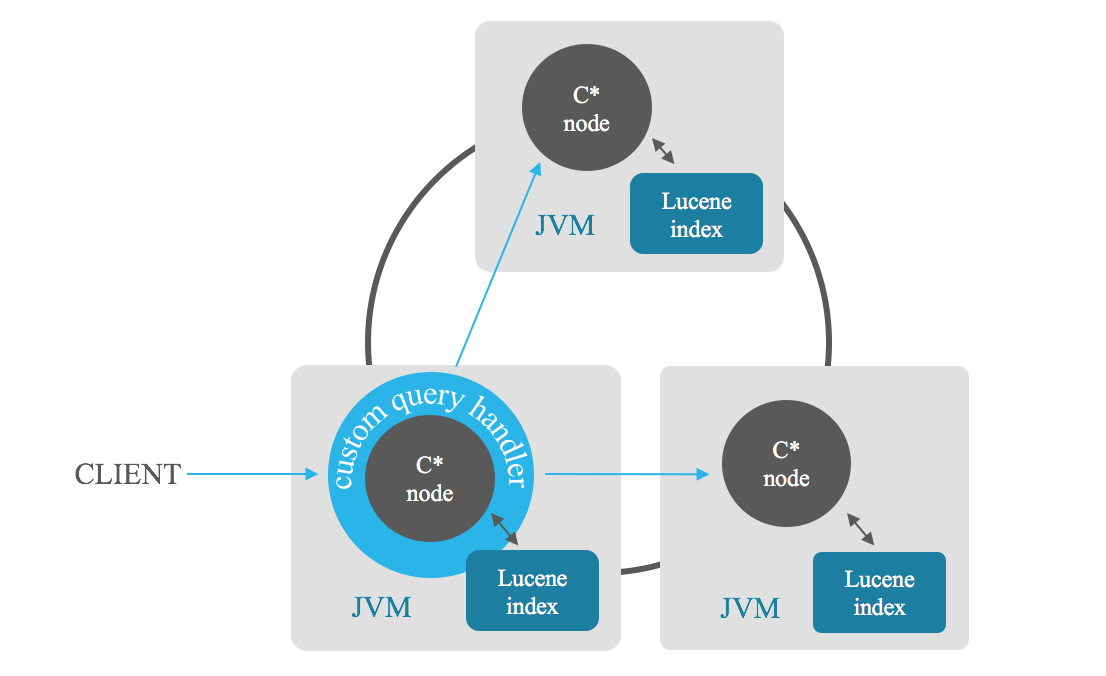
Las búsquedas de relevancia del índice le permiten recuperar los n resultados más relevantes que satisfacen una búsqueda. El nodo coordinador envía la búsqueda a cada nodo del clúster, cada nodo devuelve sus n mejores resultados y luego el coordinador combina estos resultados parciales y le brinda los n mejores, evitando el escaneo completo. También puedes basar la clasificación en una combinación de campos.
Se puede indexar cualquier celda de las tablas, incluidas las de la clave principal y las colecciones. También se admiten filas anchas. Puede escanear rangos de tokens/claves, aplicar cláusulas CQL3 adicionales y consultar los resultados filtrados.
Las búsquedas filtradas por índice son una poderosa ayuda a la hora de analizar los datos almacenados en Cassandra con frameworks MapReduce como Apache Hadoop o, mejor aún, Apache Spark. Agregar filtros de Lucene en la entrada de trabajos puede reducir drásticamente la cantidad de datos a procesar, evitando un análisis completo.
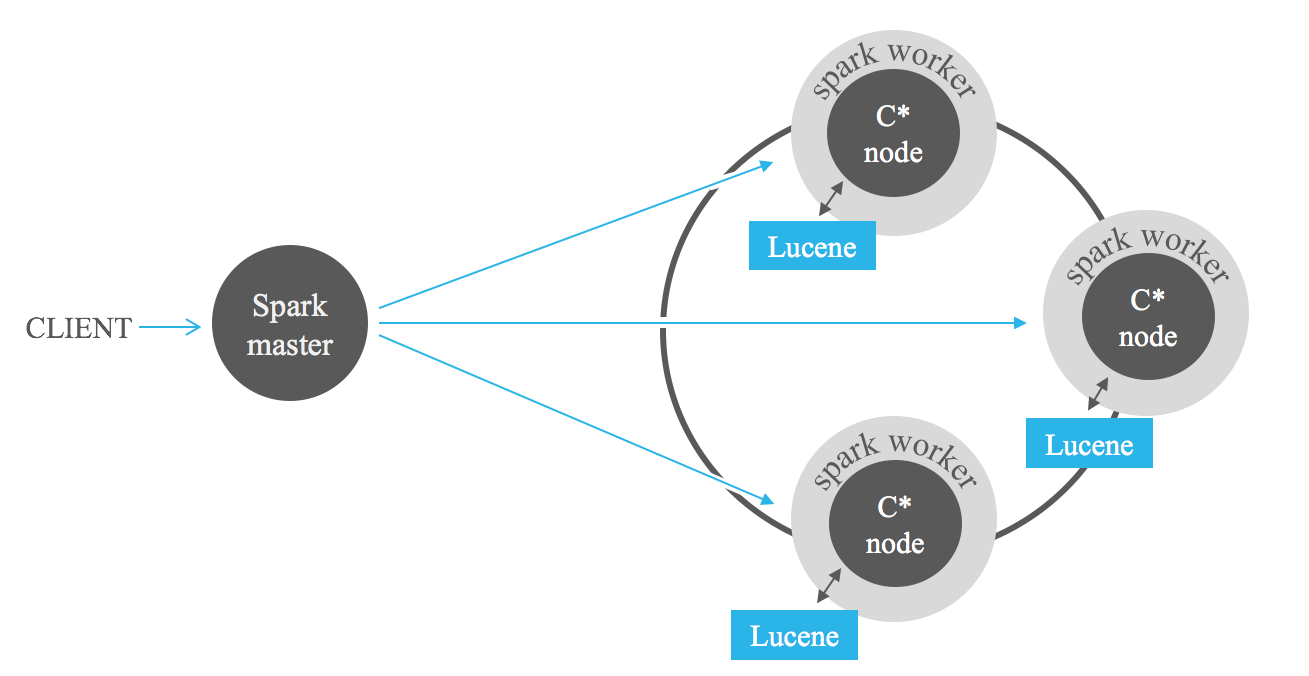
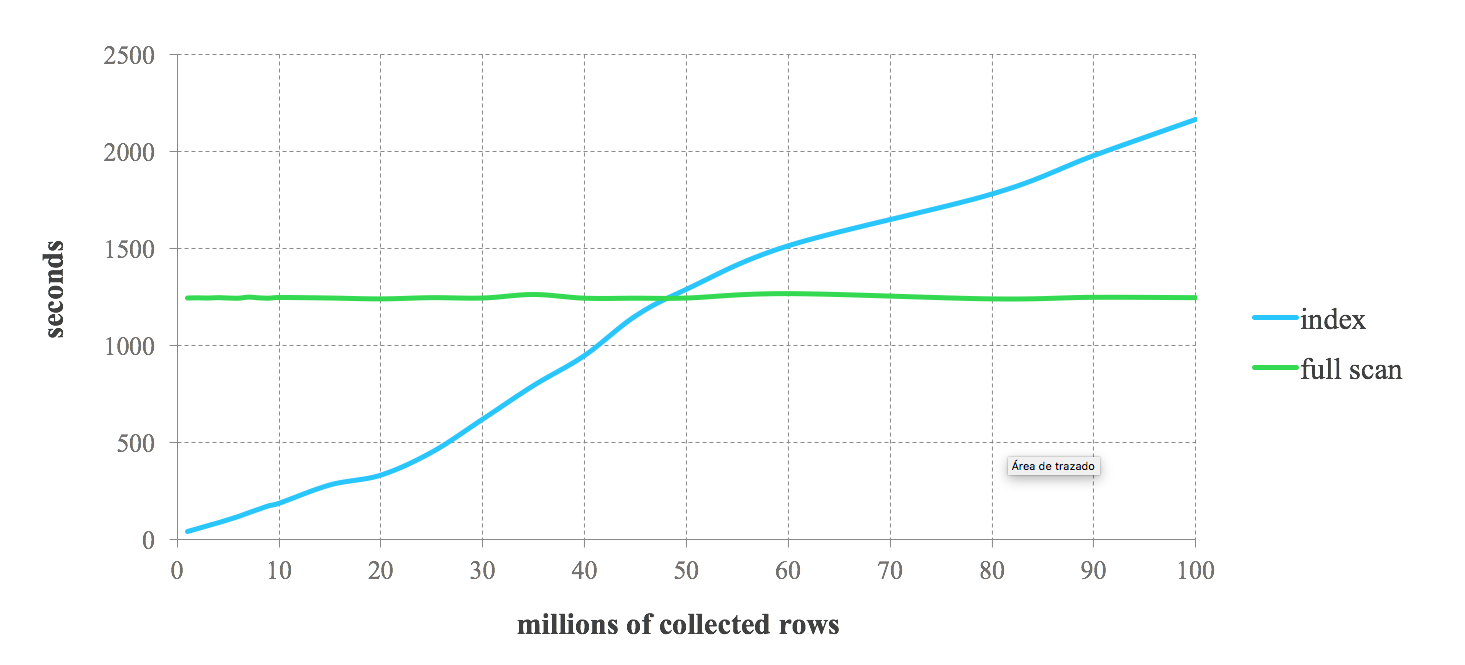
El siguiente resultado comparativo puede darle una idea sobre el rendimiento esperado al combinar índices de Lucene con Spark. Realizamos consultas sucesivas solicitando desde el 1% hasta el 100% de los datos almacenados. Podemos ver un alto rendimiento del índice para las consultas que solicitan datos fuertemente filtrados. Sin embargo, el rendimiento decae en consultas menos restrictivas. A medida que aumenta el número de registros devueltos por la consulta, llegamos a un punto en el que el índice se vuelve más lento que el análisis completo. Por lo tanto, la decisión de utilizar índices en sus trabajos de Spark depende de la selectividad de la consulta. La compensación entre ambos enfoques depende del caso de uso particular. Generalmente, se recomienda combinar índices de Lucene con Spark para trabajos que no recuperen más del 25% de los datos almacenados.
Este proyecto no pretende reemplazar las tablas desnormalizadas, los índices invertidos y/o los índices secundarios de Apache Cassandra. Es solo una herramienta para realizar algún tipo de consultas que son realmente difíciles de abordar utilizando las funciones listas para usar de Apache Cassandra, llenando el vacío entre el tiempo real y el análisis.
Hay información más detallada disponible en la documentación del índice Cassandra Lucene de Stratio.
La integración de la tecnología de búsqueda de Lucene en Cassandra proporciona:
El índice Cassandra Lucene de Stratio y su integración con la tecnología de búsqueda Lucene proporciona:
Aún no compatible:
counter de indexaciónCassandra Lucene Index de Stratio se distribuye como un complemento para Apache Cassandra. Por lo tanto, sólo necesita crear un JAR que contenga el complemento y agregarlo al classpath de Cassandra:
git clone http://github.com/Stratio/cassandra-lucene-indexcd cassandra-lucene-indexgit checkout ABCXmvn clean packagecp plugin/target/cassandra-lucene-index-plugin-*.jar <CASSANDRA_HOME>/lib/Las versiones específicas del índice Cassandra Lucene están dirigidas a versiones específicas de Apache Cassandra. Por lo tanto, cassandra-lucene-index ABCX está destinado a usarse con Apache Cassandra ABC, por ejemplo, cassandra-lucene-index:3.0.7.1 para cassandra:3.0.7. Tenga en cuenta que las versiones listas para producción son etiquetas de versión (por ejemplo, 3.0.6.3), no utilice rama-X ni ramas maestras en producción.
Alternativamente, la aplicación de parches también se puede realizar con este perfil de Maven, especificando la ruta de instalación de Cassandra. Esta tarea también elimina las versiones JAR del complemento anterior en el directorio CASSANDRA_HOME/lib/:
mvn clean package -Ppatch -Dcassandra_home= < CASSANDRA_HOME >Si no tiene una versión instalada de Cassandra, también hay un perfil alternativo para permitir que Maven descargue y parchee la versión adecuada de Apache Cassandra:
mvn clean package -Pdownload_and_patch -Dcassandra_home= < CASSANDRA_HOME >Ahora puede ejecutar Cassandra y realizar algunas pruebas utilizando Cassandra Query Language:
< CASSANDRA_HOME > /bin/cassandra -f
< CASSANDRA_HOME > /bin/cqlsh Los archivos de índice de Lucene se almacenarán en los mismos directorios donde estarán los de Cassandra. El directorio de datos predeterminado es /var/lib/cassandra/data y cada índice se coloca junto a las SSTables de su familia de columnas indexadas.
Recuerde que si utiliza la búsqueda de formas geográficas, debe incluir el archivo JTS.
Para obtener más detalles sobre Apache Cassandra, consulte su documentación.
Crearemos la siguiente tabla para almacenar tweets:
CREATE KEYSPACE demo
WITH REPLICATION = { ' class ' : ' SimpleStrategy ' , ' replication_factor ' : 1 };
USE demo;
CREATE TABLE tweets (
id INT PRIMARY KEY ,
user TEXT ,
body TEXT ,
time TIMESTAMP ,
latitude FLOAT,
longitude FLOAT
);Ahora puede crear un índice Lucene personalizado con la siguiente declaración:
CREATE CUSTOM INDEX tweets_index ON tweets ()
USING ' com.stratio.cassandra.lucene.Index '
WITH OPTIONS = {
' refresh_seconds ' : ' 1 ' ,
' schema ' : ' {
fields: {
id: {type: "integer"},
user: {type: "string"},
body: {type: "text", analyzer: "english"},
time: {type: "date", pattern: "yyyy/MM/dd"},
place: {type: "geo_point", latitude: "latitude", longitude: "longitude"}
}
} '
}; Esto indexará todas las columnas de la tabla con los tipos especificados y se actualizará una vez por segundo. Alternativamente, puede actualizar explícitamente todos los fragmentos de índice con una búsqueda vacía con coherencia ALL :
CONSISTENCY ALL
SELECT * FROM tweets WHERE expr(tweets_index, ' {refresh:true} ' );
CONSISTENCY QUORUMAhora, para buscar tweets dentro de un rango de fechas determinado:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: {type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"}
} ' );Se puede realizar la misma búsqueda forzando una actualización explícita de los fragmentos de índice involucrados:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: {type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
refresh: true
} ' ) limit 100 ;Ahora, para buscar los 100 tweets más relevantes donde el campo del cuerpo contiene la frase "big data brinda a las organizaciones" dentro del rango de fechas antes mencionado:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: {type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1}
} ' ) LIMIT 100 ;Para refinar la búsqueda para obtener solo los tweets escritos por usuarios cuyos nombres comienzan con "a":
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1}
} ' ) LIMIT 100 ;Para obtener los 100 resultados filtrados más recientes, puede utilizar la opción de clasificación :
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: {field: "time", reverse: true}
} ' ) limit 100 ;La búsqueda anterior se puede restringir a tweets creados cerca de una posición geográfica:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"},
{type: "geo_distance", field: "place", latitude: 40.3930, longitude: -3.7328, max_distance: "1km"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: {field: "time", reverse: true}
} ' ) limit 100 ;También es posible ordenar los resultados por distancia a una posición geográfica:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"},
{type: "geo_distance", field: "place", latitude: 40.3930, longitude: -3.7328, max_distance: "1km"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: [
{field: "time", reverse: true},
{field: "place", type: "geo_distance", latitude: 40.3930, longitude: -3.7328}
]
} ' ) limit 100 ;Por último, pero no menos importante, puede enrutar cualquier búsqueda a un cierto rango de token o partición, de tal manera que solo se alcanzará un subconjunto de los nodos del clúster, ahorrando recursos valiosos:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"},
{type: "geo_distance", field: "place", latitude: 40.3930, longitude: -3.7328, max_distance: "1km"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: [
{field: "time", reverse: true},
{field: "place", type: "geo_distance", latitude: 40.3930, longitude: -3.7328}
]
} ' ) AND TOKEN(id) >= TOKEN( 0 ) AND TOKEN(id) < TOKEN( 10000000 ) limit 100 ;Este último es la base para el soporte de Hadoop, Spark y otros marcos de MapReduce.
Consulte la documentación completa del índice Cassandra Lucene de Stratio.


